基于模型预测的碳控排企业能量优化调度方法
1.本发明涉及能量调度领域,更具体涉及基于模型预测的碳控排企业能量优化调度方法。
背景技术:
2.为承担解决气候变化问题中的大国责任、推动我国生态文明建设与高质量发展,我国提出了“二氧化碳排放力争于2030年前达到峰值,努力争取2060年前实现碳中和”的“双碳”目标。重点碳控排企业是碳排放的重要来源,目前,我国重点碳控排企业能量调度方案不明确,同时缺乏合理碳排放策略,生产利润无法实现最大化,经济效益与生态效益无法实现两全其美。
3.中国专利公开号cn114139837a,公开了一种考虑双层碳排放优化分配模型的区域多系统双层分散优化调度方法,构建了一种区域多能源系统双层碳排放优化分配模型,上层区域多能源主系统主要考虑了配电网、配气网和配热网系统,基于实时环境监测而制定其实时碳排放约束,按照下层区域内各多能源子系统的历史碳排放量实时分解给下层区域内各多能源子系统,并且下层区域内各多能源子系统在优化的同时需满足其实时碳排放约束;最后采用改进的目标级联分析法来求解上层和下层之间区域多能源系统的双层分散优化调度模型。该专利申请既能降低区域多能源系统上层配网系统的总网络损耗,又能减少下层区域内各能源子系统的运行成本,同时确定区域多能源系统整体碳排放量的最优分配方案。但是其主要侧重点在于降低配网系统的网络损耗和运行成本,并不能实现碳控排企业的能量优化调度,从而提高企业生产效益并减小碳排放。
技术实现要素:
4.本发明所要解决的技术问题在于如何实现碳控排企业的能量优化调度,提高企业生产效益并减小碳排放。
5.本发明通过以下技术手段实现解决上述技术问题的:基于模型预测的碳控排企业能量优化调度方法,所述方法包括:
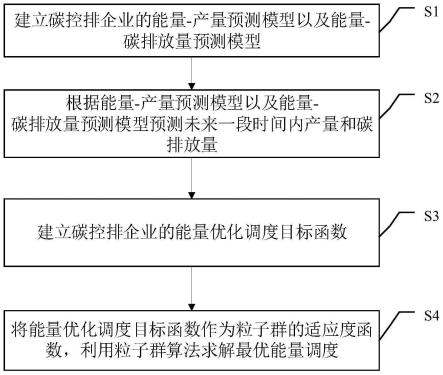
6.步骤一:建立碳控排企业的能量-产量预测模型以及能量-碳排放量预测模型;
7.步骤二:根据能量-产量预测模型以及能量-碳排放量预测模型预测未来一段时间内产量和碳排放量;
8.步骤三:建立碳控排企业的能量优化调度目标函数;
9.步骤四:将能量优化调度目标函数作为粒子群的适应度函数,利用粒子群算法求解最优能量调度。
10.本发明建立碳控排企业的能量-产量预测模型以及能量-碳排放量预测模型,并利用模型预测控制方法,对未来一段时间产量和碳排放量进行预测,然后建立能量优化调度函数,利用粒子群算法求解最优能量调度方案,能够使得企业生产在存在碳排放约束的情况下,通过优化能源调度方案,提高企业生产效益并减小碳排放。
11.进一步地,所述步骤一包括:
12.步骤101:基于历史数据建立能量输入u、碳排放量c和产量y的一阶时间差分方程;
13.步骤102:通过第一神经网络建立能量输入差分δu与产量差分δy之间的关系,通过第二神经网络建立能量输入差分δu与碳排放量差分δc之间的关系,并对第一神经网络进行训练得到能量输入差分δu和产量差分δy之间的第一神经网络模型以及对第二神经网络进行训练得到能量输入差分δu和碳排放量差分δc之间的第二神经网络模型;
14.步骤103:利用第一神经网络模型建立能量-产量预测模型,通过第二神经网络模型建立能量-碳排放量预测模型。
15.更进一步地,所述步骤101包括:
16.能量输入u、碳排放量c和产量y的一阶时间差分方程为
17.δu(k-1)=u(k-1)-u(k-2)
18.δc(k-1)=c(k-1)-c(k-2)
19.δy(k-1)=y(k-1)-y(k-2)
20.其中,u(k-1)是k-1时刻的能量,1时刻的能量,表示nu维的向量;c(k-1)是k-1时刻的碳排放量,y(k-1)是k-1时刻的产量,
21.更进一步地,所述步骤102包括:
22.所述第一神经网络和第二神经网络均包含输入层、隐含层、输出层;输入层包含ni个节点,输出层包含no个节点,隐含层包含nh个节点;ni、no、nh在[1,10000]之间取值;第一神经网络的输入层输入的数据为δu(k-ni),δu(k-ni+1),
…
,δu(k-1),输出层的数据为δy(k-no),δy(k-no+1),
…
,δy(k-1);第二神经网络的输入层输入的数据为δu(k-ni),δu(k-n
i-1),
…
,δu(k-1),输出层的数据为δc(k-no),δc(k-no+1),
…
,δc(k-1);
[0023]
采集nm组历史“能量-碳排放量-产量”数据采用梯度下降法对神经网络进行训练,训练出输入差分δu和产量差分δy之间的第一神经网络模型
[0024]
δy=f(δu)
[0025]
训练出能量输入差分δu和碳排放量差分δc之间的第二神经网络模型
[0026]
δc=h(δu)。
[0027]
更进一步地,所述步骤103包括:
[0028]
利用第一神经网络模型建立能量-产量预测模型以及利用第二神经网络模型建立能量-碳排放量预测模型如下
[0029][0030][0031]
其中,是k时刻的预测产量;是k时刻的预测碳排放量;u(k)是待求解的k时刻最优能量调度。
[0032]
更进一步地,所述步骤二包括:
[0033]
根据能量-产量预测模型预测未来一段时间内产量如下
[0034][0035]
根据能量-碳排放量预测模型预测未来一段时间内碳排放量如下
[0036][0037]
其中,p是预测时域;y(k+m|k)表示在k时刻预测的k+m时刻产量;c(k+m|k)表示在k时刻预测的k+m时刻碳排放量;u(k+(m-1))是待求解的k+(m-1)时刻最优能量调度,m=1,2,
…
,p。
[0038]
更进一步地,所述步骤三包括:
[0039]
通过公式
[0040][0041]umin
≤u(k+i)≤u
max
[0042]
0≤c(k+i)≤c
max
[0043]
建立碳控排企业的能量优化调度目标函数;
[0044]
其中,r(i)是i时刻的期望产出,是在k时刻对i时刻的预测产出,与u(i|k)相对应,i=k,k+1,
…
,k+p-1;
[0045]
uk={u(k|k),u(k+1|k),
…
u(k+p-1|k)}。
[0046]
更进一步地,所述步骤四包括:
[0047]
步骤401:将待求解的uk作为粒子群算法中粒子的位置向量,初始化粒子群的参数;
[0048]
步骤402:将初始位置向量代入能量-产量预测模型以及能量-碳排放量预测模型并预测未来一段时间内产量和碳排放量得到当前目标函数值;
[0049]
步骤403:如果每个粒子的当前目标函数值ji小于自身最优目标值j
ibest
,则将当前目标函数值ji作为自身最优目标值j
ibest
,更新自身最优目标值j
ibest
,此时对应的位置向量为粒子i的历史最好位置li且li=[l
i0
,l
i1
,
…
,l
i(p-1)
],l
i(p-1)
表示
p-1时刻粒子i的历史最好位置;如果自身最优目标值j
ibest
小于全局最优目标值j
global
,则将自身最优目标值j
ibest
作
为全局最优目标值j
global
,更新全局最优目标值j
global
,此时对应的位置向量为全局最好位置g,其中,g=(g0,g1,
…
,g
(p-1
)),g
(p-1)
表示p-1时刻全局最好位置;
[0050]
步骤404:更新粒子的速度、位置和惯性权重;
[0051]
步骤405:将粒子更新后的位置作为初始位置向量,返回执行步骤402至404,判断是否达到最大迭代次数,如果达到最大迭代次数则结束,最终得到的全局最好位置g为待求解的uk。
[0052]
更进一步地,所述步骤401包括:
[0053]
粒子表示为popi=[qi,vi,li,j
ibest
,ji],其中,qi为粒子i的位置向量且为粒子i的位置向量且表示p-1时刻粒子i的位置,vi为粒子i的速度;
[0054]
将初始设置的能量u
k0
作为粒子群算法中粒子的初始位置向量,粒子种群个数设为l并且初始化粒子群的速度,从而完成粒子群的参数初始化。
[0055]
更进一步地,所述步骤404包括:
[0056]
通过公式
[0057][0058][0059][0060][0061]
更新粒子的速度、位置和惯性权重;
[0062]
其中,为t+1时刻粒子i的速度,为t+1时刻粒子i的位置,c1,c2为加速因子;ω为惯性权重,ω
min
为惯性权重的取值下限,ω
max
为惯性权重的取值上限;r1,r2为[0,1]之间的随机数,c3为调节系数;j
avg
和j
min
为当前所有粒子的平均目标值和最小目标值。
[0063]
本发明的优点在于:
[0064]
(1)本发明建立碳控排企业的能量-产量预测模型以及能量-碳排放量预测模型,并利用模型预测控制方法,对未来一段时间产量和碳排放量进行预测,然后建立能量优化调度函数,利用粒子群算法求解最优能量调度方案,能够使得企业生产在存在碳排放约束的情况下,通过优化能源调度方案,提高企业生产效益并减小碳排放。
[0065]
(2)传统粒子群算法依赖自身经验和粒子经验更新速度,导致后期粒子搜索缺乏多样性,出现早熟也即粒子群在没有找到全局最优信息之前就陷入停顿状态,而本发明采用动态变化的惯性权重加入粒子群速度和位置的更新,粒子更新速度不依赖经验,搜索过程存在多样性,避免出现早熟。
附图说明
[0066]
图1为本发明实施例所提供的基于模型预测的碳控排企业能量优化调度方法的流程图。
具体实施方式
[0067]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0068]
如图1所示,基于模型预测的碳控排企业能量优化调度方法,所述方法包括:
[0069]
s1:建立碳控排企业的能量-产量预测模型以及能量-碳排放量预测模型;具体过程为:
[0070]
建立基于历史数据建立能量输入u、碳排放量c和产量y的一阶时间差分方程为
[0071]
δu(k-1)=u(k-1)-u(k-2)
[0072]
δc(k-1)=c(k-1)-c(k-2)
[0073]
δy(k-1)=y(k-1)-y(k-2)
[0074]
其中,u(k-1)是k-1时刻的能量,1时刻的能量,表示nu维的向量;c(k-1)是k-1时刻的碳排放量,y(k-1)是k-1时刻的产量,
[0075]
然后,通过第一神经网络建立能量输入差分δu与产量差分δy之间的关系,通过第二神经网络建立能量输入差分δu与碳排放量差分δc之间的关系,并对第一神经网络进行训练得到能量输入差分δu和产量差分δy之间的第一神经网络模型以及对第二神经网络进行训练得到能量输入差分δu和碳排放量差分δc之间的第二神经网络模型;
[0076]
所述第一神经网络和第二神经网络均包含输入层、隐含层、输出层;输入层包含ni个节点,输出层包含no个节点,隐含层包含nh个节点;ni、no、nh在[1,10000]之间取值;第一神经网络的输入层输入的数据为δu(k-ni),δu(k-ni+1),
…
,δu(k-1),输出层的数据为δy(k-no),δy(k-no+1),
…
,δy(k-1);第二神经网络的输入层输入的数据为δu(k-ni),δu(k-n
i-1),
…
,δu(k-1),输出层的数据为δc(k-no),δc(k-no+1),
…
,δc(k-1);
[0077]
采集nm组历史“能量-碳排放量-产量”数据采用梯度下降法对神经网络进行训练,nm取值范围为[1,100000];训练出输入差分δu和产量差分δy之间的第一神经网络模型
[0078]
δy=f(δu)
[0079]
训练出能量输入差分δu和碳排放量差分δc之间的第二神经网络模型
[0080]
δc=h(δu)。
[0081]
最后,利用第一神经网络模型建立能量-产量预测模型以及利用第二神经网络模型建立能量-碳排放量预测模型如下
[0082][0083][0084]
其中,是k时刻的预测产量;是k时刻的预测碳排放量;u(k)是待求解的k时刻最优能量调度。
[0085]
s2:根据能量-产量预测模型以及能量-碳排放量预测模型预测未来一段时间内产量和碳排放量;具体过程为:
[0086]
根据能量-产量预测模型预测未来一段时间内产量如下
[0087][0088]
根据能量-碳排放量预测模型预测未来一段时间内碳排放量如下
[0089][0090]
其中,p是预测时域;y(k+m|k)表示在k时刻预测的k+m时刻产量;c(k+m|k)表示在k时刻预测的k+m时刻碳排放量;u(k+(m-1))是待求解的k+(m-1)时刻最优能量调度,m=1,2,
…
,p。
[0091]
s3:建立碳控排企业的能量优化调度目标函数;具体过程为:通过公式
[0092][0093]umin
≤u(k+i)≤u
max
[0094]
0≤c(k+i)≤c
max
[0095]
建立碳控排企业的能量优化调度目标函数;
[0096]
其中,是能量优化调度模型的目标函数,u
min
≤u(k+i)≤u
max
是能量约束,表示能量输入限制;0≤c(k+i)≤c
max
是碳排放量约束,表示最大碳排放量限制。
[0097]
r(i)是i时刻的期望产出,是在k时刻对i时刻的预测产出,与u(i|k)相对应,i=k,k+1,
…
,k+p-1;
[0098]
uk={u(k|k),u(k+1|k),
…
u(k+p-1|k)}。
[0099]
s4:将能量优化调度目标函数作为粒子群的适应度函数,利用粒子群算法求解最优能量调度,具体过程为:
[0100]
步骤401:粒子表示为popi=[qi,vi,li,j
ibest
,ji],其中,qi为粒子i的位置向量且为粒子i的位置向量且表示p-1时刻粒子i的位置,vi为粒子i的速度;j
ibest
为粒子i
的自身最优目标值,ji为粒子i的当前目标函数值。
[0101]
将待求解的uk作为粒子群算法中粒子的位置向量,将初始设置的能量u
k0
作为粒子群算法中粒子的初始位置向量,粒子种群个数设为l并且初始化粒子群的速度,从而完成粒子群的参数初始化。
[0102]
步骤402:将初始位置向量代入能量-产量预测模型以及能量-碳排放量预测模型并预测未来一段时间内产量和碳排放量得到当前目标函数值;
[0103]
步骤403:如果每个粒子的当前目标函数值ji小于自身最优目标值j
ibest
,则将当前目标函数值ji作为自身最优目标值j
ibest
,更新自身最优目标值j
ibest
,此时对应的位置向量为粒子i的历史最好位置li且li=[l
i0
,l
i1
,
…
,l
i(p-1)
],l
i(p-1)
表示p-1时刻粒子i的历史最好位置;如果自身最优目标值j
ibest
小于全局最优目标值j
global
,则将自身最优目标值j
ibest
作为全局最优目标值j
global
,更新全局最优目标值j
global
,此时对应的位置向量为全局最好位置g,其中,g=(g0,g1,
…
,g
(p-1)
),g
(p-1)
表示p-1时刻全局最好位置;
[0104]
步骤404:通过公式
[0105][0106][0107][0108][0109]
更新粒子的速度、位置和惯性权重;
[0110]
其中,为t+1时刻粒子i的速度,为t+1时刻粒子i的位置,c1,c2为加速因子;ω为惯性权重,ω
min
为惯性权重的取值下限,ω
max
为惯性权重的取值上限;r1,r2为[0,1]之间的随机数,c3为调节系数;j
avg
和j
min
为当前所有粒子的平均目标值和最小目标值。
[0111]
步骤405:将粒子更新后的位置作为初始位置向量,返回执行步骤402至404,判断是否达到最大迭代次数,如果达到最大迭代次数则结束,最终得到的全局最好位置g为待求解的uk。
[0112]
通过以上技术方案,本发明建立碳控排企业的能量-产量预测模型以及能量一碳排放量预测模型,并利用模型预测控制方法,对未来一段时间产量和碳排放量进行预测,然后建立能量优化调度函数,利用粒子群算法求解最优能量调度方案,能够使得企业生产在存在碳排放约束的情况下,通过优化能源调度方案,提高企业生产效益并减小碳排放。
[0113]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1