线程管理方法、装置、电子设备、计算机可读存储介质
1.本发明属于线程管理技术领域,尤其涉及一种线程管理方法、装置、电子设备、计算机可读存储介质。
背景技术:
2.现代网页由html(hyper text markup language,超文本标记语言)、css(cascading style sheets,层叠样式表)和javascript构成。html用来定义网页的内容,例如标题、正文、图像等,css用来控制网页的外观,例如颜色、字体、背景等,javascript用来在网页中添加一些动态效果与交互功能,为用户提供更流畅美观的浏览效果。
3.javascript是单线程语言,同一时间只能做一件事情。为了实现并发操作,html5提出了web worker标准,允许javascript创建多线程。
4.本发明申请人在实施上述技术方案中发现,上述技术方案至少存在以下缺陷:web worker不能跨域加载javascript,需要开启服务器才能访问本地文件。
技术实现要素:
5.本发明实施例的目的在于提供一种线程管理方法,旨在解决背景技术中所提到的问题。
6.本发明实施例是这样实现的,一种线程管理方法,包括以下步骤:创建主线程,并设置主线程数量自增n,n为整数且大于等于1;将javascript代码片段打包为blob对象,根据所述blob对象创建相应域名的url,web worker类基于所述url创建n个子线程;创建主线程和子线程之间的数据交换接口。
7.优选的,所述方法还包括以下步骤:绑定n个子线程的参数信息和标志位信息,并监听n个子线程。
8.优选的,当所述标志位信息为假时,回调接收数据或者销毁url和web worker对象;所述web worker对象由web worker类构造得到。
9.优选的,所述方法还包括以下步骤:检测所述主线程是自发运行结束还是人为关闭;当所述主线程是自发运行结束,进行数据反馈;当所述主线程是人为关闭,判断为异常结束。
10.优选的,超过预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb。
11.本发明实施例的另一目的在于提供一种线程管理装置,包括:主线程创建模块,用于创建主线程,并设置主线程数量自增n,n为整数且大于等于1;子线程创建模块,用于将javascript代码片段打包为blob对象,根据所述blob对
象创建相应域名的url,web worker类基于所述url创建n个子线程;数据接口创建模块,用于创建主线程和子线程之间的数据交换接口。
12.优选的,所述装置还包括:监听模块,用于绑定n个子线程的参数信息和标志位信息,并监听n个子线程。
13.本发明实施例的另一目的在于提供一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现上述中任一项所述的线程管理方法。
14.本发明实施例的另一目的在于提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述中任一项所述的线程管理方法。
15.本发明实施例提供的一种线程管理方法,通过将javascript代码片段打包为blob对象,再根据blob对象创建相应域名的url,web worker类基于url创建子线程,从而解决web worker不能跨域加载javascript,需要开启服务器才能访问本地文件的问题。
附图说明
16.图1为实施例1提供的一种线程管理方法的流程图;图2为实施例2提供的一种线程管理装置的结构框图;图3为实施例3提供的一种线程管理方法的流程图;图4为实施例4提供的一种线程管理装置的结构框图;图5为线程生命周期的框图;图6为实施例5提供的一种电子设备的结构示意图。
具体实施方式
17.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
18.以下结合具体实施例对本发明的具体实现进行详细描述。
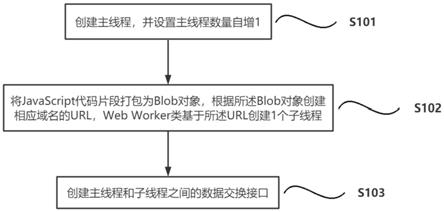
19.实施例1如附图1和5所示,为本发明一个实施例提供的一种线程管理方法,包括以下步骤:s101,创建主线程,并设置主线程数量自增1;s102,将javascript代码片段打包为blob对象,根据所述blob对象创建相应域名的url(uniform resource locator,统一资源定位器),web worker类基于所述url创建1个子线程;s103,创建主线程和子线程之间的数据交换接口。
20.blob(binary large object)表示二进制类型的大对象。blob 对象表示一个不可变、原始数据的类文件对象。
21.数据交换接口包括postmessage,onmessage。
22.在本实施例中,通过将javascript代码片段打包为blob对象,再根据blob对象创建相应域名的url,web worker类基于url创建子线程,从而解决web worker不能跨域加载javascript,需要开启服务器才能访问本地文件的问题。
23.需要注意的是,javascript代码片段通常是函数文件,因此,通常先将函数文件封装为自调用函数再打包为blob对象。
24.在本实施例的一种情况中,所述方法还包括以下步骤:绑定1个子线程的参数信息和标志位信息,并监听1个子线程。
25.在本实施例中,对子线程进行实时监听,从而时刻掌握web worker类的运行状况。
26.在本实施例的一种情况中,当所述标志位信息为假时,回调接收数据或者销毁url和web worker对象;所述web worker对象由web worker类构造得到。
27.在本实施例中,当主线程、子线程和数据交换接口创建完成后,子线程即开始运行。子线程运行时接收到数据后会自动触发javascript代码片段(函数),然后在此处获取标志位信息,当标志位信息为假时,子线程会回调接收数据(通常由接收数据回调函数完成)以指向相关操作并继续进行,或者销毁url和web worker对象。web worker对象由web worker类基于url创建子线程时得到。
28.在本实施例的一种情况中,所述方法还包括以下步骤:检测所述主线程是自发运行结束还是人为关闭;当所述主线程是自发运行结束,进行数据反馈;当所述主线程是人为关闭,判断为异常结束。
29.在本实施例中,在上述步骤之后,再检测主线程是自发运行结束还是人为关闭。当主线程是自发运行结束,通过相应的函数(通常为resolve函数)进行数据计算并将计算结果进行反馈;当主线程是人为关闭,判断为异常结束(后续由调用异常结束回调函数实现)。
30.在本实施例的一种情况中,超过预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb。
31.现有技术还存在的问题是:在进行性能测试的过程中,发现web worker与主线程交互时,会将数据进行拷贝后再发送,从而导致时间延迟以及内存浪费。
32.在本实施例中,通过将预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb以获得操作数据,而不是靠主线程发送,从而不会出现时间延迟以及内存浪费的问题。
33.实施例2结合附图2和5,在另一个实施例中,提供了一种线程管理装置,包括:主线程创建模块101,用于创建主线程,并设置主线程数量自增1;子线程创建模块102,用于将javascript代码片段打包为blob对象,根据所述blob对象创建相应域名的url,web worker类基于所述url创建1个子线程;数据接口创建模块103,用于创建主线程和子线程之间的数据交换接口。
34.blob(binary large object)表示二进制类型的大对象。blob 对象表示一个不可变、原始数据的类文件对象。
35.数据交换接口包括postmessage,onmessage。
36.在本实施例中,采取子线程创建模块102将javascript代码片段打包为blob对象,再根据blob对象创建相应域名的url,web worker类基于url创建子线程,从而解决web worker不能跨域加载javascript,需要开启服务器才能访问本地文件的问题。
37.需要注意的是,javascript代码片段通常是函数文件,因此,通常先将函数文件封
装为自调用函数再打包为blob对象。
38.在本实施例的一种情况中,所述装置还包括:监听模块,用于绑定1个子线程的参数信息和标志位信息,并监听1个子线程。
39.在本实施例中,对子线程进行实时监听,从而时刻掌握web worker类的运行状况。
40.在本实施例的一种情况中,当所述标志位信息为假时,回调接收数据或者销毁url和web worker对象;所述web worker对象由web worker类构造得到。
41.在本实施例中,当主线程、子线程和数据交换接口创建完成后,子线程即开始运行。子线程运行时接收到数据后会自动触发javascript代码片段(函数),然后在此处获取标志位信息,当标志位信息为假时,子线程会回调接收数据(通常由接收数据回调函数完成)以指向相关操作并继续进行,或者销毁url和web worker对象。web worker对象由web worker类基于url创建子线程时得到。
42.在本实施例的一种情况中,还包括以下内容:检测所述主线程是自发运行结束还是人为关闭;当所述主线程是自发运行结束,进行数据反馈;当所述主线程是人为关闭,判断为异常结束。
43.在本实施例中,在上述步骤之后,再检测主线程是自发运行结束还是人为关闭。当主线程是自发运行结束,通过相应的函数(通常为resolve函数)进行数据计算并将计算结果进行反馈;当主线程是人为关闭,判断为异常结束(后续由调用异常结束回调函数实现)。
44.在本实施例的一种情况中,超过预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb。
45.现有技术还存在的问题是:在进行性能测试的过程中,发现web worker与主线程交互时,会将数据进行拷贝后再发送,从而导致时间延迟以及内存浪费。
46.在本实施例中,通过将预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb以获得操作数据,而不是靠主线程发送,从而不会出现时间延迟以及内存浪费的问题。
47.实施例3结合附图3和5,在另一个实施例中,提供了一种线程管理方法,包括以下步骤:s201,创建主线程,并设置主线程数量自增n,n为整数且大于1;s202,将javascript代码片段打包为blob对象,根据所述blob对象创建相应域名的url,web worker类基于所述url创建n个子线程;s203,创建主线程和子线程之间的数据交换接口。
48.实施例1通过涉及多线程处理模式,从而相比传统的单线程处理模式,提高了数据处理效率。本实施例在实施例1的基础上进一步改进,设计了分布式线程处理模式。
49.blob(binary large object)表示二进制类型的大对象。blob 对象表示一个不可变、原始数据的类文件对象。
50.数据交换接口包括postmessage,onmessage。
51.在本实施例中,通过将javascript代码片段打包为blob对象,再根据blob对象创建相应域名的url,web worker类基于url创建子线程,从而解决web worker不能跨域加载javascript,需要开启服务器才能访问本地文件的问题。
52.需要注意的是,javascript代码片段通常是函数文件,因此,通常先将函数文件封装为自调用函数再打包为blob对象。
53.在本实施例的一种情况中,所述方法还包括以下步骤:绑定n个子线程的参数信息和标志位信息,并监听n个子线程,n为整数且大于1。
54.在本实施例中,通过监听多个子线程,从而时刻掌握每个子线程的运行情况。
55.在本实施例的一种情况中,当所述标志位信息为假时,回调接收数据或者销毁url和web worker对象;所述web worker对象由web worker类构造得到。
56.在本实施例中,当主线程、子线程和数据交换接口创建完成后,子线程即开始运行。子线程运行时接收到数据后会自动触发javascript代码片段(函数),然后在此处获取标志位信息,当标志位信息为假时,子线程会回调接收数据(通常由接收数据回调函数完成)以指向相关操作并继续进行,或者销毁url和web worker对象。web worker对象由web worker类基于url创建子线程时得到。
57.在本实施例的一种情况中,所述方法还包括以下步骤:检测所述主线程是自发运行结束还是人为关闭;当所述主线程是自发运行结束,进行数据反馈;当所述主线程是人为关闭,判断为异常结束。
58.在本实施例中,在上述步骤之后,再检测主线程是自发运行结束还是人为关闭。当主线程是自发运行结束,通过相应的函数(通常为resolve函数)进行数据计算并将计算结果进行反馈;当主线程是人为关闭,判断为异常结束(后续由调用异常结束回调函数实现)。
59.在本实施例的一种情况中,超过预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb。
60.现有技术还存在的问题是:在进行性能测试的过程中,发现web worker与主线程交互时,会将数据进行拷贝后再发送,从而导致时间延迟以及内存浪费。
61.在本实施例中,通过将预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb以获得操作数据,而不是靠主线程发送,从而不会出现时间延迟以及内存浪费的问题。
62.在本实施例的一种情况中,在子线程开启后,在完成一次计算周期时是直接进行数据包上报,而是进行随机时延等待。
63.在多线程处理模式转为分布式线程处理模式时中存在以下问题:web worker不能在线程中实现数据库的存储以及进行图形学渲染,会统一将运算结果上报。由于数据包的分布是等大小的分布,在分派到线程之后,运算时延基本相同,此时主线程的数据包的接收会周期性密集与稀疏,而主线程是只能依次处理,短时间的上报高峰会使得cpu占用突然拉高,阻塞主线程渲染,造成界面卡顿。
64.因此,在本实施例中,在子线程开启后,在完成一次计算周期时是直接进行数据包上报,而是进行随机时延等待。通过该操作稍微拉长了整个任务的运行周期,同时也将线程的执行均匀分散,扰乱密集型周期,抑制主线程阻塞,从而在大型任务中显著地提升效率。
65.在本实施例的一种情况中,所述随机时延等待的时延因子与子线程数目成正比。
66.在分布式的计算任务中,每个线程运行时长不同,任务刚注册时单个任务的线程数量是最多的,此时的时延因子可以显著将任务分散开,但在运行过程中,线程数量在变
小,此时的时延因子又会使得线程的计算周期变得很长,导致任务的运算后期的速率显著下降,效率显著降低。
67.在本实施例中,对时延因子进行了重新设计,不再是常数,而是与任务的子线程数目直接成正比,经过了这一步优化之后,分布式线程的质量、效率、稳定性和与系统的契合度都有了显著提升。
68.实施例4结合附图4和5,在另一个实施例中,提供了一种线程管理装置,包括:主线程创建模块201,用于创建主线程,并设置主线程数量自增n,n为整数且大于1;子线程创建模块202,用于将javascript代码片段打包为blob对象,根据所述blob对象创建相应域名的url,web worker类基于所述url创建1个子线程;数据接口创建模块203,用于创建主线程和子线程之间的数据交换接口。
69.实施例2通过涉及多线程处理模式,从而相比传统的单线程处理模式,提高了数据处理效率。本实施例在实施例2的基础上进一步改进,设计了分布式线程处理模式。
70.blob(binary large object)表示二进制类型的大对象。blob 对象表示一个不可变、原始数据的类文件对象。
71.数据交换接口包括postmessage,onmessage。
72.在本实施例中,采取子线程创建模块202将javascript代码片段打包为blob对象,再根据blob对象创建相应域名的url,web worker类基于url创建子线程,从而解决web worker不能跨域加载javascript,需要开启服务器才能访问本地文件的问题。
73.需要注意的是,javascript代码片段通常是函数文件,因此,通常先将函数文件封装为自调用函数再打包为blob对象。
74.在本实施例的一种情况中,所述装置还包括:监听模块,用于绑定n个子线程的参数信息和标志位信息,并监听n个子线程,n为整数且大于1。
75.在本实施例中,通过监听多个子线程,从而时刻掌握每个子线程的运行情况。
76.在本实施例的一种情况中,当所述标志位信息为假时,回调接收数据或者销毁url和web worker对象;所述web worker对象由web worker类构造得到。
77.在本实施例中,当主线程、子线程和数据交换接口创建完成后,子线程即开始运行。子线程运行时接收到数据后会自动触发javascript代码片段(函数),然后在此处获取标志位信息,当标志位信息为假时,子线程会回调接收数据(通常由接收数据回调函数完成)以指向相关操作并继续进行,或者销毁url和web worker对象。web worker对象由web worker类基于url创建子线程时得到。
78.在本实施例的一种情况中,还包括以下内容:检测所述主线程是自发运行结束还是人为关闭;当所述主线程是自发运行结束,进行数据反馈;当所述主线程是人为关闭,判断为异常结束。
79.在本实施例中,在上述步骤之后,再检测主线程是自发运行结束还是人为关闭。当主线程是自发运行结束,通过相应的函数(通常为resolve函数)进行数据计算并将计算结
果进行反馈;当主线程是人为关闭,判断为异常结束(后续由调用异常结束回调函数实现)。
80.在本实施例的一种情况中,超过预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb。
81.现有技术还存在的问题是:在进行性能测试的过程中,发现web worker与主线程交互时,会将数据进行拷贝后再发送,从而导致时间延迟以及内存浪费。
82.在本实施例中,通过将预设体积的结构化数据存储在indexeddb中,web worker类能够直接访问indexeddb以获得操作数据,而不是靠主线程发送,从而不会出现时间延迟以及内存浪费的问题。
83.在本实施例的一种情况中,在子线程开启后,在完成一次计算周期时是直接进行数据包上报,而是进行随机时延等待。
84.在多线程处理模式转为分布式线程处理模式时中存在以下问题:web worker不能在线程中实现数据库的存储以及进行图形学渲染,会统一将运算结果上报。由于数据包的分布是等大小的分布,在分派到线程之后,运算时延基本相同,此时主线程的数据包的接收会周期性密集与稀疏,而主线程是只能依次处理,短时间的上报高峰会使得cpu占用突然拉高,阻塞主线程渲染,造成界面卡顿。
85.因此,在本实施例中,在子线程开启后,在完成一次计算周期时是直接进行数据包上报,而是进行随机时延等待。通过该操作稍微拉长了整个任务的运行周期,同时也将线程的执行均匀分散,扰乱密集型周期,抑制主线程阻塞,从而在大型任务中显著地提升效率。
86.在本实施例的一种情况中,所述随机时延等待的时延因子与子线程数目成正比。
87.在分布式的计算任务中,每个线程运行时长不同,任务刚注册时单个任务的线程数量是最多的,此时的时延因子可以显著将任务分散开,但在运行过程中,线程数量在变小,此时的时延因子又会使得线程的计算周期变得很长,导致任务的运算后期的速率显著下降,效率显著降低。
88.在本实施例中,对时延因子进行了重新设计,不再是常数,而是与任务的子线程数目直接成正比,经过了这一步优化之后,分布式线程的质量、效率、稳定性和与系统的契合度都有了显著提升。
89.实施例5结合附图6,在另一个实施例中,提供了一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如实施例1或实施例3中任一项所述的线程管理方法。
90.在本实施例中,存储器与处理器之间通过通信接口实现数据传输。存储器可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。处理器,用于执行计算机程序时实现实施例1或实施例3中任一项所述的线程管理方法。如果存储器、处理器和通信接口独立实现,则通信接口、存储器和处理器可以通过总线相互连接并完成相互间的通信。所述总线可以是工业标准体系结构(industry standard architecture,简称为isa)总线、外部设备互连(peripheral component,简称为pci)总线或扩展工业标准体系结构(extended industry standard architecture,简称为eisa)总线等。所述总线可以分为地址总线、数据总线、控制总线等。为便于表示,图6中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
91.可选的,在具体实现上,如果存储器、处理器及通信接口,集成在一块芯片上实现,则存储器、处理器及通信接口可以通过内部接口完成相互间的通信。
92.处理器可能是一个中央处理器(central processing unit,简称为cpu),或者是特定集成电路(application specific integrated circuit,简称为asic),或者是被配置成实施本实施例的一个或多个集成电路。
93.在本实施例中,通过将javascript代码片段打包为blob对象,再根据blob对象创建相应域名的url,web worker类基于url创建子线程,从而解决web worker不能跨域加载javascript,需要开启服务器才能访问本地文件的问题。
94.实施例6在另一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现实施例1或实施例3中任一项所述的线程管理方法。
95.在本实施例中,计算机可读存储介质可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。
96.在本实施例中,通过将javascript代码片段打包为blob对象,再根据blob对象创建相应域名的url,web worker类基于url创建子线程,从而解决web worker不能跨域加载javascript,需要开启服务器才能访问本地文件的问题。
97.以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1