一种基于语义分割网络的动态场景视觉SLAM优化方法
一种基于语义分割网络的动态场景视觉slam优化方法
技术领域
1.本发明涉及视觉slam定位与建图技术领域,更具体地说,涉及一种基于语义分割网络的动态场景视觉slam优化方法。
背景技术:
2.slam(simultaneous localization and mapping)技术作为移动机器人实现真正自主的核心技术之一。现有常用的slam系统根据使用的传感器的不同,可分为激光slam和视觉slam。其中,视觉slam主要依靠摄像机传感器数据,融合计算机视觉、深度学习等技术来更好的解决问题,并且具有简易便携、硬件成本低且定位精度高的优势,已逐步成为slam研究的主流趋势,并日益成熟。使用特征点法跟踪的orb-slam、使用直接法追踪的lsd-slam和使用视觉+惯性传感器融合的vins-slam等,均在相应的场景中取得令人满意的表现。
3.但传统slam框架具有一个共同的问题,即采用了一个刚性假设:静态环境。所以在一些具有挑战性的动态环境中,动态物体上特征点会影响特征匹配结果,系统鲁棒性和定位精度明显下降。客观世界中,在同步定位和建图时,存在行人、动物、车辆等的动态环境是不可避免的,这就限制了传统算法的应用。
4.近些年,卷积神经网络在图像的语义分割任务上蓬勃发展,为解决动态环境下的slam建图问题,提供了新的解决方案。卷积神经网络可以提供物体的语义标签,帮助slam系统更好的理解周围环境,完成一些高级任务,并提高系统的鲁棒性。但是许多学者提出解决动态环境影响的方案存在一个共同问题,即只能够得到先验动态物体的信息,对于非先验动态物体的鲁棒性较差。现有技术中存在一种使用rgb-d相机的slam系统,能很好的解决非先验动态物体的识别问题,但是由于采用了点云分割和区域生长算法,计算量较大,系统无法实时运行。
技术实现要素:
5.1.发明要解决的技术问题
6.为了解决上述slam系统动态环境下建图的实时性和有效性差的问题,本发明提供了一种基于语义分割网络的动态场景视觉slam优化方法;本发明基于orb-slam3提出了一种可用于动态环境下的视觉slam系统:segment-slam,相比其他的经典动态slam,segment-slam的定位精度具有显著提升。特别在高动态场景中,相比orb-slam,定位精度相对提升了80%以上,并能实现实际场景的八叉树地图创建。
7.2.技术方案
8.为达到上述目的,本发明提供的技术方案为:
9.本发明的一种基于语义分割网络的动态场景视觉slam优化方法,包括以下步骤:
10.步骤1:通过单目rgb-d相机获取图像数据,包括rgb图像和深度图像;
11.步骤2:为了保证实时性和分割效果,rgb图像通过语义分割网络去除图像中先验动态物体的影响;
12.步骤3:步骤2所得图像通过轻量化追踪模块估计当前帧位姿;
13.步骤4:通过改进的多视角几何算法滤除步骤3所得图像中非先验动态物体和先验动态物体;
14.步骤5:利用跟踪线程产生关键帧;
15.步骤6:根据关键帧的相关数据构建动态场景下的八叉树地图。
16.更进一步地,步骤2中通过lr-aspp语义分割网络对图像进行处理,该lr-aspp语义分割网络以轻量型卷积网络mobilenetv3为主干网络,rgb图像经过lr-aspp语义分割网络处理,获得像素级的语义信息,利用该语义信息,剔除图像中先验动态物体上的特征点。
17.更进一步地,步骤3中,剔除图像中先验动态物体上的特征点后,剩余特征点通过轻量化追踪模块获得当前帧位姿。
18.更进一步地,轻量化追踪模块只估计当前帧位姿,不参与后续建图。
19.更进一步地,步骤4中利用改进的多视角几何法滤除非先验动态物体的具体方法为:
20.多视角几何对于每一个输入图像帧,从距离当前最近的20个关键帧中选择与当前帧重叠度最高的5个关键帧;
21.检测关键帧中动态点;
22.当动态点被检测出来后,根据语义分割的结果,获取动态点的标签,将动态点分为两类,一类是拥有语义信息的动态点,另一类是没有语义信息的动态点;
23.对拥有语义信息的动态点进行语义轮廓搜索,对没有语义信息的动态点则在深度图中进行区域生长,使能充分利用语义信息,减少区域生长种子点的数量;
24.最后结合没有语义的动态物体掩膜和拥有语义信息的动态物体掩膜,获得完整的动态物体掩膜。
25.更进一步地,步骤4中检测关键帧动态点的过程为:
26.假设x是被挑选出的关键帧上的关键点,x
′
是x投影到当前帧坐标系下的点,x对应的三维点为x,计算x,x
′
,x之间角度α和投影深度l
proj
;当角度α大于某一阈值时,判断该关键点可能为动态点;再通过深度图计算,获得当前帧中x
′
关键点的深度l
′
,并将其与l
proj
比较如果差值δl=l
proj-l
′
超过阈值τz即认定其为动态点。
27.更进一步地,所述的角度阈值和投影深度阈值,取α=30
°
和τz=0.2m。
28.更进一步地,步骤4中将多视角几何检测结果与lr-aspp的检测结果进行相互验证,得到完整的动态区域,过滤掉动态区域上的orb特征点,再经过特征点提取模块提取掩模之外的特征点,从而达到剔除动态物体的效果。
29.更进一步地,步骤6的具体过程为:
30.设y∈r为概率对数值,x为节点被占据的概率,那么x和y之间的变换由logit变换描述:
[0031][0032]
存储y来表达节点是否被占据,当不断观测到“占据”时,让y增加一个值,否则就让y减小一个值;
[0033]
设某节点为n,观测数据为z,从开始到t时刻的某节点的概率对数值为l(n|z
1:t-1
),
t+1时刻为:
[0034]
l(n|z
1:t+1
)=l(n|z
1:t-1
)+l(n|z
t
)
[0035]
当某个节点被反复观察到时,其y值会不断增加,当超过设定阈值时,该节点就会被占用,并将在八叉树图中可视化。
[0036]
3.有益效果
[0037]
采用本发明提供的技术方案,与已有的公知技术相比,具有如下显著效果:
[0038]
(1)本发明的一种基于语义分割网络的动态场景视觉slam优化方法,提出了一种用于动态环境的slam系统,克服了动态物体对传统slam系统的干扰,并构建了一个可复用的八叉树地图。
[0039]
(2)本发明的一种基于语义分割网络的动态场景视觉slam优化方法,使用lr-aspp语义分割网络剔除先验动态物体,通过轻量化追踪模式得到粗略的位姿估计。改进的多视角几何用来处理非先验动态物体,使用轮廓检索充分利用卷积神经网络的语义信息,在轻量化追踪模式的基础上得到更准确的位姿估计,并提高系统在动态环境下的鲁棒性。实验证明,系统具有良好的实时性和更加准确的位姿精度。特别是在高动态的环境中,依然保持较高的slam定位精度。
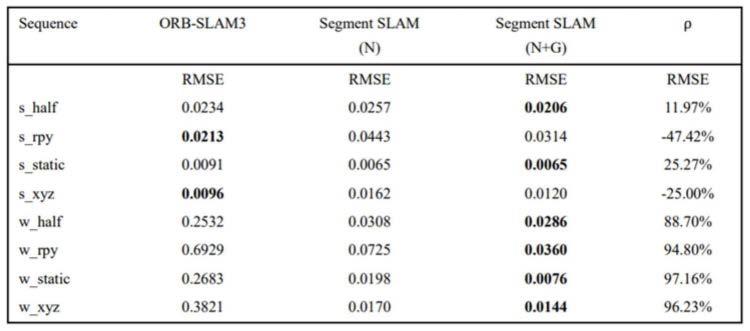
[0040]
(3)本发明的一种基于语义分割网络的动态场景视觉slam优化方法,在orb-slam3框架基础上增加了一个使用语义分割网络和改进的多视角几何方法剔除动态物体上特征点的前端,在充分利用语义分割网络输出的语义信息基础上,减少了区域生长算法的使用,提高了系统的运行速度,并且根据关键帧构建可复用的八叉树地图,减小内存占用,提高了地图查找效率。
附图说明
[0041]
图1是本发明的系统框架图;
[0042]
图2是本发明的lr-aspp网络结构图;
[0043]
图3是本发明的多视角几何算法流程图;
[0044]
图4是本发明的多视角几何检测动态点原理图;
[0045]
图5是segment-slam与orb-slam3轨迹误差对比图;
[0046]
图6是八叉树建图测试结果图。
具体实施方式
[0047]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明,显然所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的保护的范围。
[0048]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0049]
实施例1
[0050]
结合图1,本实施例的系统采用四线程并行:跟踪,局部建图,回环检测与构建八叉
树地图,其中跟踪线程包括lr-aspp网络,轻量化追踪模块,改进的多视角几何算法模块,特征点提取模块,初始化和重定位或地图重建模块,局部跟踪模块。
[0051]
本实施例首先通过rgb-d相机获取彩色图像和深度图像,为lr-aspp提供图像帧。
[0052]
如图2所示是lr-aspp网络结构图。为了保证实时性和分割效果,本实施例采用轻量级卷积网络mobilenetv3-large作为lr-aspp的主干网络。彩色图像先经过lr-aspp语义分割网络处理,从而获得像素语义信息。利用语义信息,剔除图像中先验动态物体上的特征点。
[0053]
该lr-aspp模型在coco train2017的子数据集上进行了训练,可以区分20类的物体。lr-aspp模型的mean iou(intersection over union)为57.9,global pixelwise acc为91.2,在满足实时性的需求下,分割效果良好。
[0054]
mobilenetv3-large网络使用nas技术并提出h-swish激活函数,同时加入se模块,有效减少了计算量和网络精度并提高了网络性能。
[0055]
将mobilenetv3作为lr-aspp的主干网络提取的不同分辨率的特征图作为语义分割头的输入,因此lr-aspp可以很好的剔除先验动态物体上的特征点。
[0056]
经过语义分割处理后的图像经过轻量化追踪模块,即简化版的局部跟踪模块,只产生位姿,不产生关键帧。获得当前帧位姿后,便于得到特征点深度。进一步通过改进的多视角几何处理非先验动态物体。如图3是多视角几何算法流程图:
[0057]
首先,多视角几何对于每一个输入帧,从距离当前最近的20个关键帧中选择与当前帧重叠度最高的5个关键帧。通过改进的多视角几何算法得到动态点,如图4是多视角几何检测动态点原理图:
[0058]
假设x是被挑选出的关键帧上的关键点,x
′
是x投影到当前帧坐标系下的点。x对应的三维点为x,计算x,x
′
,x之间的角度α和投影深度l
proj
。当角度α大于某一阈值时,判断该关键点可能为动态点,需进一步判断深度变化。在考虑到重投影误差的情况下,直接通过深度图计算,获得当前帧中x
′
关键点的深度l
′
,并将其与l
proj
比较。如果差值δl=l
proj-l
′
超过阈值τz即认定其为动态点。经过在tum数据集上的实验测试,取α=30
°
和τz=0.2m,能够很好的区分动态物体和静态物体。
[0059]
当动态点被检测出来后,根据语义分割的结果,获取动态点的标签,将动态点分为两类,一类是拥有语义信息的动态点,另一类是没有语义信息的动态点。
[0060]
继续对拥有语义信息的特征点进行语义轮廓搜索得到拥有语义信息的动态物体掩模,对没有语义信息的动态点则在深度图进行区域生长得到没有语义的动态物体掩膜。使得能够充分利用语义信息,减少区域生长种子点的数量,提高运行效率。
[0061]
最后没有语义的动态物体掩膜和拥有语义信息的动态物体掩膜结合,获得完整的动态物体掩膜。
[0062]
同时,通过改进的多视角几何算法检测结果和lr-aspp的检测结果进行相互验证,得到完整的动态区域,过滤掉动态区域上的orb特征点。再经过特征点提取模块提取掩模之外的特征点,从而达到剔除动态物体的效果。再经过初始化和重定位或地图重建模块后进入局部跟踪模块。
[0063]
此时经过整个跟踪线程中的局部跟踪模块将会产生关键帧。接下来八叉树建图会利用关键帧数据构建动态场景下的八叉树地图。
[0064]
八叉树是一种灵活的,压缩的,又能实时更新的地图。一个大立方体不断地均匀分成八块,直到变成最小的方块为止。整个大方块可以看成是根节点,而最小的块可以看作是“叶子节点”。于是,在八叉树中,当由下一层节点往上走一层时,地图的体积就能扩大八倍。某个方块的所有子节点都被占据或都不被占据时,就没必要展开这个节点。
[0065]
八叉树地图是通过概率更新地图。八叉树的节点存储了它是否被占据的信息。可以用0表示空白,1表示占据。为了方便表示,采用浮点数x∈[0,1]来表达某节点是否被占据。通常x开始取0.5。如果不断观测到它被占掘,那么让这个值不断增加,反之如果不断观测到它是空白,那就让它不断减小。这样可以动态地建模了地图中的障碍物信息。x不断减小或增加可能会超出[0.1]的范围,因此采用概率对数值来描述:设y∈r为概率对数值,那么x和y之间的变换由logit变换描述:
[0066][0067]
因此y很好的表达节点是否被占据,当不断观测到占据时,让y增加一个值,否则就减小一个值。用数学形式来说,设某节点为n,观测数据为z。那么从开始到t时刻的某节点的概率对数值为:l(n|z
1:n-1
),那么t+1时刻为:
[0068]
l(n|z
1:t+1
)=l(n|z
1:t-1
)+l(n|z
t
)
[0069]
当某个节点被反复观察到时,其y值会不断增加,当超过设定阈值时,该节点就会被占用,并将在八叉树图中可视化。通过这种方法,可以很好的构建动态环境的地图。
[0070]
下面使用公开的tum rgb-d数据集中关于动态物体的子数据集对本实施例方案进行评估。
[0071]
所有实验均运行在一台pc上,cpu为amd ryzen 3700,内存为16g,gpu为rtx 2080,显存为8g。系统环境为ubuntu18.04,采用cuda10.2,模型训练使用的深度学习框架为pytorch1.10.0,部署推理模型使用libtorch1.10.0库。
[0072]
利用tum rgb-d数据集进行位姿估计实验,位姿误差估计时将segment-slam所估计的相机位姿和数据集中的真实位姿进行对比。测试指标采用绝对轨迹误差ate(absolute trajectory error)。
[0073]
实验中采用均方根误差(rmse),误差平均值来评价系统。其中均方根误差易受到较大或偶发错误的影响,所以能够很好的反应系统的鲁棒性。平均值则更能够反映系统的稳定性。
[0074]
首先将segment-slam在高动态和低动态的8个数据集上进行测试,在w_half和s_half上进行定量分析。实验均进行了5次,结果取平均值。提升率的计算公式为:
[0075][0076]
其中α代表待测slam系统的测试结果,β代表segment-slam系统的测试结果,ρ代表相对提升率。
[0077]
图5中的(a)和(b)展示了在w_half数据中,segment-slam和orb-slam3的轨迹误差对比图,图5中的(c)和(d)展示了轨迹在xyz方向上的误差对比图,图5中的(e)和(f)展示了轨迹在rpy角度上的误差对比图。其中cameratrajectory代表segment-slam,orbcameratrajectory代表orb-slam3。从图5可以看出在高动态的环境中,orb-slam3的表
slam和基于光流的mr-slam,从结果可以看出segment-slam在精度方面实现了全面领先。
[0088]
进一步的,segment-slam在s_static序列和真实场景下的八叉树进图进行了测试。
[0089]
如图6,其中图6中的(a)为数据集拍摄的真实场景,其中两个人一直坐在椅子上交谈;图6中的(b)为实验室的真实环境,其中一个人一直在场景中移动;图6中的(c)为根据s_static序列生成八叉树地图,从中可以看出坐在椅子上的人的部分已经基本被移除了,图6中的(d)为在真实场景下的建图实验,其中人的部分被完全消除了。
[0090]
s_static一共为707帧图像,根据图片序列生成的点云地图的磁盘文件为55.6mb,而八叉树地图的磁盘文件仅为3.1mb,是点云文件的5.64%,因此八叉树地图可以有效的建模大规模场景,便于后续维护和更新。
[0091]
通过测试结果可知,本发明系统具有良好的实时性和更加准确的位姿精度。特别是在高动态的环境中,依然保持较高的slam定位精度。
[0092]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1