基于SAS数据统计过程的电影票房预测方法
基于sas数据统计过程的电影票房预测方法
技术领域
1.本实用型属于电影数据分析领域,具体涉及一种基于sas数据统计过程的电影票房预测方法。
背景技术:
2.随着社会经济的发展和人民生活水平的提高,电影行业迎来了前所未有的繁荣发展。据统计,我国总观影人数早已破亿,在观影人数稳定增长的同时,我国年度票房逾100亿元,可见我国电影行业巨大的发展活力和经济潜力。在这种情况下,由于电影评价网站提供的电影信息由于具有能够直接、实时地反映消费者观影感受的特点,可以作为判断电影未来票房的重要依据之一。
3.综合用户数量、电影评价指标和网站口碑等因素,使用豆瓣和imdb两大电影评分网站的数据用于分析和电影最终实际票房预测具有较强权威性。通过获取电影评分网站提供的电影评分、评分人数、短评和影评数量并进行有效的数据分析,量化影响电影最终实际票房的最重要的两项指标:观影人数和电影口碑,从而建立电影最终实际票房与电影网站数据间的关系。在电影的点映、首映和放映等过程中就可以实时对电影的最终票房进行预测。于是,在如今影片量不断增长,但质量参差不齐的电影行业,提出一种有效的基于电影评分网站数据的票房预测方法对于帮助影院调整排片量,优化影院收益并为电影投资方提供投资意见方面均有重要的实用价值和应用前景。
技术实现要素:
4.发明目的:针对上述电影市场提出的需求,本发明提出了一种基于sas数据统计过程的电影票房预测方法,以用于对仍未下映的电影最终票房进行准确预测。
5.上述的目的通过以下技术方案实现:
6.一种基于sas数据统计过程的电影票房预测方法,该预测方法包括以下步骤:
7.步骤1:通过电影网站采集电影样本数据并构造电影训练集和测试集,其中训练集的电影样本包括电影名、豆瓣评分、豆瓣评分人数、短评数量、影评数量、imdb评分、imdb评分人数和实际票房8个数据变量;测试集的电影样本包括电影名、豆瓣评分、豆瓣评分人数、短评数量、影评数量、imdb评分和imdb评分人数7个数据变量;
8.步骤2:基于实际票房这一数据变量对训练集的电影样本使用谱系聚类法进行聚类;
9.步骤3:利用参数估计方法为主成分法的因子分析,对训练集中电影样本的豆瓣评分、豆瓣评分人数、短评数量、影评数量、imdb评分和imdb评分人数这6项数据变量进行降维,得到公共因子;
10.步骤4:在步骤3得到的公共因子的基础上进行回归分析,得到步骤2聚类的不同类别下电影实际票房和公共因子之间的线性回归模型;
11.步骤5:利用先验概率按比例分配的bayes判别基于电影样本的豆瓣评分、豆瓣评
分人数、短评数量、影评数量、imdb评分和imdb评分人数对测试集电影进行分类,分类到步骤2所得不同电影类别内;
12.步骤6:在步骤5的基础上,已知任意测试集电影样本所属的类别,代入步骤4得到的相应类别下的线性回归模型,即可对电影票房进行预测。
13.进一步地,步骤1所述电影数据采集过程具体包括:
14.采集豆瓣和imdb电影评分网站的电影相关信息,构建用于建立电影票房预测模型的训练集和检验模型可靠性的实际票房待预测的测试集:
15.(1)建立电影数据训练集:
16.训练集数据集变量包括电影的电影名,来源于豆瓣和imdb两大电影评分网站的豆瓣评分、豆瓣评分人数、短评数量、影评数量、imdb评分和imdb评分人数,进一步采集训练集电影的实际票房;
17.(2)建立电影数据测试集:
18.测试集数据集变量包括电影的电影名,来源于豆瓣和imdb两大电影评分网站的豆瓣评分、豆瓣评分人数、短评数量、影评数量、imdb评分和imdb评分人数。
19.进一步地,步骤2所述聚类分析过程具体包括:
20.利用谱系聚类以电影实际票房为聚类准则对训练集电影样本进行聚类,故通过票房定义的相似系数便是确定分类的依据,此处采用欧式距离作为票房的相似性度量依据,将两个电影样本i与j的票房表示为xi和xj,则两者间的距离用欧氏距离d(xi,xj)来进行表示,其计算公式为:
[0021][0022]
按照此式计算所有电影样本间基于电影票房的欧式距离,得到距离矩阵d=(d
ij
)n×n:
[0023][0024]
式中,n表示电影样本的总数;
[0025]
将每个电影样本作为单独的一类,距离矩阵d中的d
ij
表示电影样本i与电影样本j之间的相似度,将相似度较高的电影样本进行合并,由此得到新的类别,当几个类别归为一类时,度量有多个个体的类的相似程度便通过类间的相似性进行衡量,此处以d
pq
表示两个不同电影分类类别类g
p
与类gq的直接类间距离,n
p
,nq,nr表示类g
p
,类gq的电影样本个数和总的电影样本个数,类平均距离法计算类间距离的定义:
[0026][0027]
进一步地,为了实现谱系聚类,由g
p
,gq与其他类gk(k≠p,q)的距离计算g
p
和gq的类间距离,即递推公式:
[0028]
[0029]
式中,d
pk
,d
qk
分别表示目标类g
p
,gq与其他类gk的直接类间距离;
[0030]
按照上式对类间距离进行计算并由此将相似度较高的电样本影归类,逐渐将较小的电影样本分类合并为较大的电影样本分类,扩大已有类,重复计算比较,直到所有电影样本都被归为一类;
[0031]
此过程会形成具有亲疏关系的谱系图,可根据此谱系图对所有电影样本进行分类,得到所需要的结果;
[0032]
以上聚类过程通过sas proc cluster实现。
[0033]
进一步地,步骤3所述因子分析过程具体包括:
[0034]
设训练集中每个电影样本包含p个数据变量,由这p个数据变量构成的向量即为可观测随机向量,则训练集中任意电影样本i的可观测随机向量用xi表示,xi中的任一元素x
ic
(1≤c≤p)表示该电影的第c个数据变量:
[0035]
xi=(x
i1
,x
i2
,...,x
ip
),i=1,2,...,n
[0036]
由此得到训练集的所有电影样本构成的n个p元可观测随机向量,n为电影样本总数,记为可观测随机矩阵向量:
[0037][0038][0039]
式中,表示的数学期望,构成的矩阵记为μ;表示的协方差矩阵,记为矩阵∑;上标t表示矩阵的转置;
[0040]
同理,设不可观测随机向量f
[0041]
f=(f1,f2,
…
,fm)
t
,m<p
[0042]
e(f)=0,cov(f)=im[0043]
式中,m表示不可观测随机向量f的维数;e(f)表示f的数学期望,其数值为0;cov(f)表示f的协方差矩阵,记为矩阵im;
[0044]
又设特殊因子矩阵ε=(ε1,ε2,...,ε
p
)
t
与f互不相关,其维数大小与xi相同,同记为p,且
[0045]
e(ε)=0,cov(ε)=q
[0046]
式中,ε表示特殊因子;e(ε)表示求解ε的数学期望,其数值为0;cov(ε)表示求解ε的协方差矩阵,,记为矩阵q;,
[0047]
假定训练集的所有电影样本的可观测随机向量xi(1≤i≤p)满足以下正交因子模型:
[0048][0049]
即用这m个不可观测的互不相关的公共因子f1,f2,
…
,fm和一个特殊因子εi(1≤i≤p)来描述可观测随机向量的x1,x2,
…
,x
p
,可观测随机矩阵表示为
[0050][0051]
其中不可观测随机向量f=(f1,f2,...,fm)
t
即为我们所要求的公共因子矩阵,m为
公共因子个数,在数值上等于不可观测随机向量f的维数,ε为特殊因子,a为待估的因子载荷矩阵,其中的元素a
11
,a
12
,
…a1m
;
…
;a
p1
,
…apm
即为因子载荷;
[0052]
在正交因子模型中,假设公共因子彼此不相关,且具有单位方差,即cov(f)=im,有
[0053][0054]
由此,可利用电影样本的协方差矩阵∑估计因子载荷矩阵a和公共因子个数m;
[0055]
为方便利用得到的公共因子矩阵f进行过程3的回归分析,需要把公共因子矩阵f表示成可观测随机矩阵的线性组合,并对每一电影样本计算公共因子的估计值,称为因子得分,常用回归法估计因子得分,设中的可观测向量x1,x2,
…
,x
p
均为标准化的,公共因子矩阵f也标准化,设公共因子矩阵对可观测随机向量满足回归方程
[0056]
f=b
j1
x1+b
j2
x2+
…
+b
jp
x
p
+εj,j=1,2,
…
,m
[0057]
需要估计回归系数b
(j)
=(b
j1
,b
j2
,...,b
jp
)
t
。,可以证明,利用回归法所建立的公共因子对变量的回归方程为
[0058][0059]
其中a为因子载荷矩阵,j为样本相关矩阵,为可观测随机矩阵,根据计算可以得到各电影样本对应的因子得分;
[0060]
以上因子分析过程可以通过sas数据统计分析过程proc factor实现。
[0061]
进一步地,步骤4所述回归分析过程具体包括:
[0062]
根据步骤2因子分析的结果,训练集中的每个电影样本有m个公共因子,即为步骤2因子分析所得的不可观测的互不相关的公共因子f1,f2…
,fm,由于训练集中所有的电影样本的实际票房变量构成一个可观测的随机变量y=[y1,y2,
…
,yn]
t
,它受到不可观测的互不相关的公共因子f1,f2…
,fm和随机误差δ的影响,利用线性回归模型,对n组电影样本数据进行分析,则满足
[0063][0064]
式中,n表示电影样本总数;f
k1
,f
k2
,
…
,f
km
是第k个电影样本的m个公共因子;β0,β1,
…
,βm是待估的线性回归模型系数;随机误差δ1,δ2,
…
,δn相互独立且均服从n(0,σ2)分布,化简为矩阵形式:
[0065]
y=fβ+δ
[0066]
其中
[0067][0068]
利用最小二乘法,求解待估的线性回归模型系数β使得随机误差项的平方和s(β)最小,其中随机误差项的平方和s(β)满足
[0069][0070]
分别对待估的线性回归模型系数β0,β1,
…
,βm求偏导并令其等于0,得
[0071][0072]
计算结果化简为矩阵形式为
[0073]ft
fβ=f
ty[0074]
由于f
t
f存在逆矩阵,则得到关于待估的线性回归模型系数β的最小二乘估计为为
[0075][0076]
得到回归方程:
[0077][0078]
其中y
*
表示电影票房的线性拟合预测值;
[0079]
已知任意电影样本的豆瓣评分、豆瓣评分人数、短评数量、影评数量、imdb评分和imdb评分人数这6项数据变量,便可由此构造该电影样本的可观测随机向量,即为步骤4中矩阵中的任意可观测随机向量xi,记为x,根据步骤4的因子分析结果得到该电影样本的不可观测的互不相关的公共因子f1,f2…
,fm:
[0080][0081]
代入回归方程可得:
[0082][0083]
即电影票房的线性拟合预测值y
*
与电影样本的可观测随机向量x之间的线性回归方程,其中α是线性回归方程系数矩阵;
[0084]
针对步骤1所分类的不同的电影类别gk,分别求此类别下的电影票房的线性回归方程:
[0085]y*
(gk)=α(gk)x
[0086]
以上回归分析的过程可以通过sas数据统计分析过程proc reg实现。
[0087]
进一步地,步骤5所述bayes判别过程具体包括:
[0088]
根据步骤2聚类分析的结果,训练集电影聚类分类后共有k个类别总体g1,g2,
…
,gk,其中,电影样本分类为类gj的概率密度为fj(x),j=1,2,
…
,k.各总体出现的先验概率
[0089]
pj=p(gj),j=1,2,
…
,k
[0090]
满足
[0091]
式中,pj表示先验概率,p(gj)表示求电影样本分类为gj的概率;
[0092]
基于sas数据分析过程的电影票房预测方法的一个判别准则是对电影训练集的一个不相重叠的划分r1,r2,
…
,rk,满足
[0093][0094]
这一划分记为r=(r1,r2,
…
,rk),r代表一个判别准则;
[0095]
在判别准则r=(r1,r2,
…
,rk)下,将来自gi类别总体的电影误判为来自gj的概率
[0096][0097]
设来自gi类别总体的电影误判为来自gj的损失记为c(j|i).我们总约定c(i|i)=0.c(j|i)构成一个损失矩阵
[0098][0099]
在对测试集进行bayes判别时,设先验概率按比例分布,则当gj出现的先验概率是pj,j=1,2,
…
,k时,误判的平均概率是
[0100][0101]
一个最优划分r=(r1,r2,
…
,rk)应使p
*
达到最小;
[0102]
在损失函数c(j|i)的一般情况下,将来自gi类别总体的电影误判为来自其它类别总体的平均损失是
[0103][0104]
当gj出现的先验概率是pj,j=1,2,
…
,k时,误判的平均损失是
[0105][0106][0107]
一个最优划分应使l达到最小;
[0108]
记
[0109][0110]
则误判的平均损失
[0111][0112]
取划分r=(r1,r2,
…
,rk)为
[0113][0114]
此划分使误判的平均损失l达到最小,故它是最优划分;
[0115]
因p(gi|x)
∝
p
ifi
(x),若记
[0116][0117]
h(gj|x)表示出现电影样本x后,将x判定来自类别总体gj造成的后验平均误判损失;
[0118]
使误判的平均损失l达到最小的最优划分rj可表为
[0119][0120]
这表明当出现测试集中电影x时,应判定x来自后验平均误判损失达到最小的那个总体gj,以上bayes判别过程可以通过sas数据统计分过程procdiscrim实现。
[0121]
进一步地,当得到测试集中任意电影样本x在步骤5的bayes分类下的电影分类结果,记为gk后。将该电影样本的可观测随机向量x代入步骤3所得的对应类别的线性回归模型:
[0122]y*
(gk)=α(gk)x
[0123]
所得的结果y
*
即为电影样本x的电影票房预测值,从而实现电影票房的预测。
[0124]
有益效果:
[0125]
1.本发明的基于sas数据统计分析过程的电影票房预测方法,其数据来源于电影
评分网站公开的实时电影数据,建立训练集和测试集用于数据分析,且仅需要电影评分、评分人数、评论数量等6项指标,相较于现有的电影票房预测方法,具有分析数据公开易得,分析指标简单实时,适用性强等优势;
[0126]
2.本发明的基于sas数据统计分析过程的电影票房预测方法,其数据分析过程
[0127]
综合聚类分析、因子分析、建立回归模型和bayes判别等多种数据统计方法,与其它电影票房预测方法相比,确保了分析过程的科学性和电影票房预测结果的准确性;
[0128]
3.本发明的基于sas数据统计分析过程的电影票房预测方法,其数据分析完全基于sas数据分析过程实现,因而相较于其它电影票房的预测方法,其算法实现过程简单明了,可移植性强,计算效率高。
附图说明
[0129]
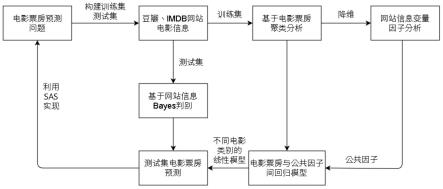
图1为本发明的总体框图;
[0130]
图2为本发明的整体程序流程图;
[0131]
图3为本发明基于proc cluster过程的电影数据聚类分析结果,其中图3(a)为类平均距离法聚类过程,图3(b)为聚类谱系图;
[0132]
图4为本发明基于proc factor过程的电影数据因子分析结果,其中图4(a)是因子分析相关矩阵特征值,图4(b)是因子模式,图4(c)是因子分析旋转矩阵结果;
[0133]
图5为本发明基于proc reg过程的电影数据回归分析结果,其中图5(a)是回归分析的线性模型参数,图5(b)是电影票房预测值与残差之间的拟合诊断,图5(c)是电影票房预测值与学生化残差之间的拟合诊断,图5(d)线性回归拟合杠杆率与student残差之间的拟合诊断,图5(e)线性回归分位数与残差之间的拟合诊断,图5(f)电影票房预测值与实际票房之间的拟合诊断,图5(g)线性拟合观测和学生化残差和之间的拟合诊断,图5(h)线性拟合残差与百分比之间的拟合诊断,图5(i)是公共因子f1与线性回归拟合残差之间的样本分布,图5(j)是公共因子f2与线性回归拟合残差之间的样本分布,图5(k)是公共因子f3与线性回归拟合残差之间的样本分布;
[0134]
图6为本发明基于proc discrim过程的电影数据回归分析结果,其中图6(a)为合并分类内的协方差矩阵,图6(b)为bayes判别(回判法)的后验概率,图6(c)为bayes判别(交叉确认法)的后验概率,图6(d)为测试集bayes判别结果及后验概率。
具体实施方式
[0135]
下面对本发明方法和系统进行详细的阐述。
[0136]
本发明是一类基于sas数据统计过程的电影票房预测方法,其特征在于,包括以下步骤:
[0137]
步骤1:采集豆瓣和imdb电影评分网站的电影相关信息,构建用于建立电影票房预测模型的训练集和检验模型可靠性的实际票房待预测的测试集:
[0138]
(1)建立电影数据训练集:
[0139]
设电影数据训练集的样本总数为n,每个电影样本在训练集中的序号为i.
[0140]
训练集数据集变量包括电影的电影名(x
i0
),来源于豆瓣和imdb两大电影评分网站的豆瓣评分(x
i1
)、豆瓣评分人数(x
i2
)、短评数量(x
i3
)、影评数量(x
i4
)、imdb评分(x
i5
)和
imdb评分人数(x
i6
),进一步采集训练集电影的实际票房(y).建立实际电影数据训练集sasdata.train用于测试方法有效性并附图说明。
[0141]
(2)建立电影数据测试集:
[0142]
测试集数据集变量包括电影的电影名(x
i0
),来源于豆瓣和imdb两大电影评分网站的豆瓣评分(x
i1
)、豆瓣评分人数(x
i2
)、短评数量(x
i3
)、影评数量(x
i4
)、imdb评分(x
i5
)和imdb评分人数(x
i6
).
[0143]
建立实际电影数据测试集sasdata.test用于测试方法有效性并附图说明。
[0144]
步骤2:合理设置sas中proccluster过程的参数,实现利用谱系聚类以电影实际票房(y)为聚类准则对训练集电影样本进行聚类:
[0145]
首先,将每个电影样本作为单独的一类,采用欧式距离:
[0146][0147]
作为两个电影样本i与j的票房xi和xj的相似性度量依据。
[0148]
按照此式计算所有电影样本间基于电影票房的欧式距离,得到距离矩阵d=(d
ij
)n×n:
[0149][0150]
式中,n表示电影样本的总数;
[0151]
比较距离矩阵d中各个d
ij
,合并具有最小d
ij
的两类,由此得到新的类别。合并训练集sasdata.train中小类得到较大类别的部分聚类过程如图3(a)所示。
[0152]
当几个类别归为一类时,度量有多个个体的类的相似程度便通过类间的相似性进行衡量,此处以d
pq
表示两个不同电影分类类别类g
p
与类gq的直接类间距离,n
p
,nq,nr表示类g
p
,类gq的电影样本个数和总的电影样本个数,类平均距离法计算类间距离的定义:
[0153][0154]
进一步地,为了实现谱系聚类,由g
p
,gq与其他类gk(k≠p,q)的距离计算g
p
和gq的类间距离,即递推公式:
[0155][0156]
式中,d
pk
,d
qk
分别表示目标类g
p
,gq与其他类gk的直接类间距离;
[0157]
按照上式对类间距离进行计算并由此将相似度较高的电样本影归类,逐渐将较小的电影样本分类合并为较大的电影样本分类,扩大已有类,重复计算比较,直到所有电影样本都被归为一类;
[0158]
将该过程利用sas的proctree过程绘制成谱系图,如图3(b)所示,并按照所需将电影分成三类,记为g1,g2,g3,记三个类别的电影样本数为n1,n2,n3.最终得到聚类结果,
[0159]
步骤3:合理设置sas中proc factor过程的参数对训练集电影进行因子分析:
[0160]
已知训练集中每个电影样本包含p=6个数据变量,即豆瓣评分(x
i1
)、豆瓣评分人
数(x
i2
)、短评数量(x
i3
)、影评数量(x
i4
)、imdb评分(x
i5
)和imdb评分人数(x
i6
),由这p个数据变量构成的向量即为可观测随机向量,则训练集中任意电影样本i的可观测随机向量用xi表示:
[0161]
xi=(x
i1
,x
i2
,...,x
ip
),i=1,2,...,n
[0162]
由此得到训练集的所有电影样本构成的n个p元可观测随机向量,n为电影样本总数,记为可观测随机矩阵向量:
[0163][0164][0165]
式中,表示的数学期望,构成的矩阵记为μ;表示的协方差矩阵,记为矩阵∑;上标t表示矩阵的转置;
[0166]
同理,设不可观测随机向量f
[0167]
f=(f1,f2,
…
,fm)
t
,m<p
[0168]
e(f)=0,cov(f)=im[0169]
式中,m表示不可观测随机向量f的维数;e(f)表示f的数学期望,其数值为0;cov(f)表示f的协方差矩阵,记为矩阵im;
[0170]
又设特殊因子矩阵ε=(ε1,ε2,...,ε
p
)
t
与f互不相关,其维数大小与xi相同,同记为p,且
[0171]
e(ε)=0,cov(ε)=q
[0172]
式中,ε表示特殊因子;e(ε)表示求解ε的数学期望,其数值为0;cov(ε)表示求解ε的协方差矩阵,,记为矩阵q;,
[0173]
假定训练集的所有电影样本的可观测随机向量xi(1≤i≤p)满足以下正交因子模型:
[0174][0175]
即用这m个不可观测的互不相关的公共因子f1,f2,
…
,fm和一个特殊因子εi(1≤i≤p)来描述可观测随机向量的x1,x2,
…
,x
p
,可观测随机矩阵表示为
[0176][0177]
其中不可观测随机向量f=(f1,f2,...,fm)
t
即为我们所要求的公共因子矩阵,m为公共因子个数,在数值上等于不可观测随机向量f的维数,ε为特殊因子,a为待估的因子载荷矩阵,其中的元素a
11
,a
12
,
…a1m
;
…
;a
p1
,
…apm
即为因子载荷;
[0178]
在正交因子模型中,假设公共因子彼此不相关,且具有单位方差,即cov(f)=im,有
[0179][0180]
由此,可利用电影样本的协方差矩阵∑估计因子载荷矩阵a和公共因子个数m;
[0181]
为了估计公共因子的个数m、因子载荷矩阵a及特殊因子ε,使得满足∑=aa
t
+q,需由训练集中n组观测数据计算样本协方差矩阵作为协方差矩阵∑的估计,利用主成分法估计因子载荷矩阵a和特殊因子ε。由此可得因子分析的估计结果如图4(a)所示。图4(a)中“累积”栏显示:当m=3时累积贡献约0.90,即说明当m=3时的正交因子模型可靠可信,故公共因子数m取3,最终得到训练集sasdata.train因子模型如图4(b).
[0182]
进一步地,此时得到的公共因子的实际意义较难解释,因此,为了给得到的m个公共因子赋予现实意义,利用方差最大的正交旋转对因子载荷矩阵施行旋转变换,使得各因子载荷矩阵的每一列元素分散性较大。训练集sasdata.train经旋转后得到的因子载荷矩阵如图4(c)。
[0183]
为方便利用得到的公共因子矩阵f进行过程3的回归分析,需要把公共因子矩阵f表示成可观测随机矩阵的线性组合,并对每一电影样本计算公共因子的估计值,称为因子得分,常用回归法估计因子得分,设中的可观测向量x1,x2,
…
,x
p
均为标准化的,公共因子矩阵f也标准化,设公共因子矩阵对可观测随机向量满足回归方程
[0184]
f=b
j1
x1+b
j2
x2+
…
+b
jp
x
p
+εj,j=1,2,
…
,m
[0185]
需要估计回归系数b
(j)
=(b
j1
,b
j2
,...,b
jp
)
t
。,可以证明,利用回归法所建立的公共因子对变量的回归方程为
[0186][0187]
其中a为因子载荷矩阵,j为样本相关矩阵,为可观测随机矩阵,根据计算可以得到各电影样本对应的因子得分,利用sas的procscore过程所得训练集sasdata.train的因子得分结果如图4(d).所示;
[0188]
步骤4:合理设置sas中procreg的参数实现训练集电影的回归分析:
[0189]
根据步骤2因子分析的结果,训练集中的每个电影样本有m=3个公共因子,即为步骤2因子分析所得的不可观测的互不相关的公共因子f1,f2…
,fm,由于训练集中所有的电影样本的实际票房变量构成一个可观测的随机变量y=[y1,y2,
…
,yn]
t
,它受到不可观测的互不相关的公共因子f1,f2…
,fm和随机误差δ的影响,利用线性回归模型,对n组电影样本数据进行分析,则满足
[0190][0191]
式中,n表示电影样本总数;f
k1
,f
k2
,
…
,f
km
是第k个电影样本的m个公共因子;β0,β1,
…
,βm是待估的线性回归模型系数;随机误差δ1,δ2,
…
,δn相互独立且均服从n(0,σ2)分布,化简为矩阵形式:
[0192]
y=fβ+δ
[0193]
其中
[0194][0195]
利用最小二乘法,求解待估的线性回归模型系数β使得随机误差项的平方和s(β)最小。具体实现过程采用“逐步回归法”,即对每一个公共因子计算相应的偏f检验统计量的值,与相应f分布的上侧分位数比较以决定是否有其它变量可进入模型。如果有新的变量进入模型,则再次检验原模型中是否有变量需删除。
[0196]
由此,电影样本总体g1,g2,g3,经逐步回归法得到的在不同电影类别下总体的电影票房与公共因子f1、f2、f3线性回归模型。训练集sasdata.train的线性回归的拟合过程如图5(a).
[0197]
得到回归方程:
[0198][0199]
其中y
*
表示电影票房的线性拟合预测值,方程参数估计如图5(b).
[0200]
已知任意电影样本的豆瓣评分、豆瓣评分人数、短评数量、影评数量、imdb评分和imdb评分人数这6项数据变量,便可由此构造该电影样本的可观测随机向量,即为步骤4中矩阵中的任意可观测随机向量xi,记为x,根据步骤4的因子分析结果得到该电影样本的不可观测的互不相关的公共因子f1,f2,f3:
[0201][0202]
代入回归方程可得:
[0203][0204]
即电影票房的线性拟合预测值y
*
与电影样本的可观测随机向量x之间的线性回归方程,其中α是线性回归方程系数矩阵;
[0205]
针对步骤1所分类的不同的电影类别gk(k=1,2,3),分别求此类别下的电影票房的线性回归方程:
[0206]y*
(gk)=α(gk)x
[0207]
步骤5:所述bayes判别过程具体包括:
[0208]
根据步骤2聚类分析的结果,训练集电影聚类分类后共有k=3个类别总体g1,g2,
…
,gk,其中,电影样本分类为类gj的概率密度为fj(x),j=1,2,
…
,k.各总体出现的先验概率
[0209]
pj=p(gj),j=1,2,
…
,k
[0210]
计算结果为
[0211][0212]
满足
[0213]
式中,pj表示先验概率,p(gj)表示求电影样本分类为gj的概率;
[0214]
基于sas数据分析过程的电影票房预测方法的一个判别准则是对电影训练集的一个不相重叠的划分r1,r2,
…
,rk,满足
[0215][0216]
这一划分记为r=(r1,r2,
…
,rk),r代表一个判别准则;
[0217]
在判别准则r=(r1,r2,
…
,rk)下,将来自gi类别总体的电影误判为来自gj的概率
[0218][0219]
设来自gi类别总体的电影误判为来自gj的损失记为c(j|i).我们总约定c(i|i)=0.c(j|i)构成一个损失矩阵
[0220][0221]
在对测试集进行bayes判别时,设先验概率按比例分布,则当gj出现的先验概率是pj,j=1,2,
…
,k时,误判的平均概率是
[0222][0223]
一个最优划分r=(r1,r2,
…
,rk)应使p
*
达到最小;
[0224]
在损失函数c(j|i)的一般情况下,将来自gi类别总体的电影误判为来自其它类别总体的平均损失是
[0225][0226]
当gj出现的先验概率是pj,j=1,2,
…
,k时,误判的平均损失是
[0227][0228]
一个最优划分应使l达到最小;
[0229]
具体实现时,sas的procdiscrim建立二次判别函数,否则利用联合协方差矩阵估计建立线性判别函数,训练集sasdata.train的线性判别函数参数估计如图6(a)所示。
[0230]
记
[0231][0232]
则误判的平均损失
[0233][0234]
取划分r=(r1,r2,
…
,rk)为
[0235][0236]
此划分使误判的平均损失l达到最小,故它是最优划分;
[0237]
因p(gi|x)
∝
p
ifi
(x),若记
[0238][0239]
h(gj|x)表示出现电影样本x后,将x判定来自类别总体gj造成的后验平均误判损失;
[0240]
使误判的平均损失l达到最小的最优划分rj可表为
[0241][0242]
这表明当出现测试集中电影x时,应判定x来自后验平均误判损失达到最小的那个总体gj。
[0243]
具体实现时,计算bayes判别的误判的平均损失l有回代误判和交叉确认误判两种实现形式,故基于图6(a)所示的线性判别函数进行bayes判别的训练集sasdata.train的部分回判结果如图6(b),其中“*”表示误判。此时,误判率的估值是0.0278;部分交叉确认结果如图6(c),其中“*”表示误判。此时,误判率的估值是0.0500.所以bayes判别的估计误判率在0.0278~0.0500.
[0244]
将bayes判别应用于电影测试集上,部分测试集sasdata.test的判别结果如图6(d).
[0245]
步骤6:当得到测试集中任意电影样本x在步骤5的bayes分类下的电影分类结果,记为gk后。将该电影样本的可观测随机向量x代入步骤3所得的对应类别的线性回归模型:
[0246]y*
(gk)=α(gk)x
[0247]
所得的结果y
*
即为电影样本x的电影票房预测值,从而实现电影票房的预测。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1