一种产业图谱智能生成方法及系统与流程
1.本发明属于知识图谱技术领域,具体涉及一种产业图谱智能生成方法及系统。
背景技术:
2.产业图谱主要是对各个产业及各细分市场规模、发展现状、趋势等数据进行研究分析和探索,每一个领域范畴内有一个产业图谱,用图谱清楚的准确的反映出一个行业每一个领域的数据,可让企业对这一产业信息得到了解。产业图谱功能可以让公司了解自身在行业内所处的位置,为公司的发展方向提供参考,了解自身的优势、劣势,也是为了让整个市场能从大的环境上寻找与自己有关的企业定位跟投资策略等前瞻信息。同时产业图谱还可以应用于精准分析、智慧搜索、智能推荐、智能解释、自然人机交互和深层关系推理等各方面。
3.目前人们在构建产业图谱数据系统时,存在操作繁琐,大量的数据和分析工作通过人工来完成,分析的数据量有限,产业知识图谱的创建时间周期长,工作量大,从而降低了系统工作效率。鉴于此,本技术提出并设计了产业知识图谱的智能生成方法和系统用以克服上述问题。
技术实现要素:
4.本发明的目的在于解决上述现有技术中存在的难题,提供一种产业图谱智能生成方法及系统。
5.本发明产业图谱的智能生成方法是通过以下技术方案实现的:步骤1:产业源数据获取,按照产业类别在对应行业下获取源数据,获取源数据中可通过以下多种方式获取,包含但不限于web爬虫、企业微信、小程序等。获取的数据至少包含产业类别下的投融资数据、政策数据、科研项目数据、专利数据,上述数据中至少包含数据内容和发布时间;步骤2:数据预处理,按照预设的规则对获取的源数据按照数据类别进行清洗、整理,通过数据标签将处理后的源数据分别存储于投融资数据子库、政策数据子库、科研项目数据子库、专利数据子库;步骤3:产业图谱智能生成,包括产业政策图谱、产业链图谱和产业发展历程图谱;步骤3.1 产业政策图谱生成,对上述存储于政策数据库中产业政策数据进行知识图谱构建,得到产业政策图谱;具体步骤包含:对政策子数据库中文本进行分词处理,去除停用词、语气词等干扰项;对分词进行关键词提取和统计分析,得到政策文件的关键词;构建共词矩阵;本发明基于科技政策数据的外部特征的外部特征和内在知识元素来构建科技政策知识图谱中所需实体,主要包括政策类别、机构、关联政策、省份、城市5个实体类型,本体中的实体属性及描述包含发布年份、一般鼓励条文、大力发展条文和禁止条文以及对应的描述;关系定义包含关联关系、依从关系、引用关系。对上述定义的三元组进行内容抽取,构
建产业政策《实体,关系,属性》的三元组知识图谱,具体属性类别的分类可以基于监督和非监督训练的方法获得。
6.步骤3.2 产业链图谱生成,对上述存储于各子库中的投融资数据、政策数据、科研项目数据、专利数据进行文本主题聚类分析,对得到的与产业链相关主题进行类型识别,分别得到产业图谱中上、中、下游产业图谱内容。产业链图谱生成步骤具体包含:对各子数据库中文本进行分词处理,去除停用词、语气词、编码符号干扰。
7.进行特征表示以及文本特征提取,本文采用tf-idf 算法,获取得到每个文本的词向量特征f;在各子库中对相应的文本数据进行相似性的计算,采用余弦距离度量、jaccard 距离度量的一种或多种,得到文本间词向量特征相似度s;进行文本聚类得出产业链主题中,由于通过网络抓取的大量无实际含义的分词会构成聚类主题,因此提出的聚类方法可以排除这种干扰,提升产业链图谱聚类的精度,具体聚类过程如下:对每个文本得到的词向量相似度计算后,建立词向量相似度图t=《s,d》,其中s代表文本间词向量特征相似度,d为文本集合构成的边;计算相似度图中词向量特征的偏差度:,其中,dv表示偏差度,dist(d)为相似度图中任意一条边的相似度,d为边的集合。
8.设定一个偏差预设参数
µ
=0.25,遍历上述相似度图找到总体偏差值大于预设参数,删除偏差较高的一些簇(子图);遍历相似度子图中顶点个数,删除顶点个数大于一定数量的子图;重复遍历上述相似度图找到总体偏差值大于预设参数,删除偏差大于预设参数的子图,直到到达遍历次数或者子图变化小于一定阈值时终止条件;完成聚类的分析后,将每个簇的主题及主题关系抽取出输出对应的产业链主题内容。上述通过相似度图中偏差度计算,保证了无意义的文本不会被用来构成主题,提升数据主题聚类的准确度。
9.由于产业链中不同主题内容会处于不同产业链位置,因而本技术进一步对得到的与产业链相关主题进行类型识别,分别得到产业图谱中上、中、下游产业图谱内容。具体通过监督学习算法对前期收集的大量产业图谱上中下游主题内容,并按照上中下游类别分别进行标记形成学习样本,并基于有监督的样本识别方法进行识别模型训练,本技术采用bp神经网络、svm或深度学习网络的一种。
10.步骤3.3产业发展历程图谱生成,通过产业图谱系统对上述得到的专利数据进行统计,依据专利申请数量统计产业阶段,具体包括产业萌芽期、快速发展期、成熟期以及衰落期,并按照得到的各个产业阶段对应的时间范围,通过数据内容的发布时间确定子库中属于该时间范围的数据,对属于该时间范围内该产业的各子库按照上述步骤3.2中产业链图谱生成中的方法进行文本聚类,形成各个阶段的产业图谱数据,各个阶段的产业图谱对应生成产业发展历程图谱内容。
11.步骤4:输出融合后的产业图谱报告,基于产业图谱生成模型得到产业政策图谱、产业链图谱和产业发展历程图谱后,系统会针对多种图谱进行自动化合并整理,进行可视
化展示,最后在系统面板处生成报告并进行多种文件格式导出。具体导出文件的格式包含但不限于pdf、图片文件、html等形式。
12.本发明产业图谱的智能生成系统包含如下技术内容:产业源数据获取模块,按照产业类别在对应行业下获取源数据,获取源数据中可通过以下多种方式获取,包含但不限于web爬虫、企业微信、小程序等。获取的数据至少包含产业类别下的投融资数据、政策数据、科研项目数据、专利数据,上述数据中至少包含数据内容和发布时间;数据预处理模块,按照预设的规则对获取的源数据按照数据类别进行清洗、整理、再定义,通过数据标签将处理后的源数据分别存储于投融资数据子库、政策数据子库、科研项目数据子库、专利数据子库;产业图谱智能生成模块,包括产业政策图谱、产业链图谱和产业发展历程图谱;步骤3.1 产业政策图谱生成,对上述存储于政策数据库中产业政策数据进行知识图谱构建,得到产业政策图谱;具体步骤包含:对政策子数据库中文本进行分词处理,去除停用词、语气词等干扰项;对分词进行关键词提取和统计分析,得到政策文件的关键词;构建共词矩阵;本发明基于科技政策数据的外部特征的外部特征和内在知识元素来构建科技政策知识图谱中所需实体,主要包括政策类别、机构、关联政策、省份、城市5个实体类型, 本体中的实体属性及描述包含发布年份、一般鼓励条文、大力发展条文和禁止条文以及对应的描述;关系定义包含关联关系、依从关系、引用关系。对上述定义的三元组进行内容抽取,构建产业政策《实体,关系,属性》的三元组知识图谱,具体属性类别的分类可以基于监督和非监督训练的方法获得。
13.产业链图谱生成模块,对上述存储于各子库中的投融资数据、政策数据、科研项目数据、专利数据进行文本主题聚类分析,对得到的与产业链相关主题进行类型识别,分别得到产业图谱中上、中、下游产业图谱内容。产业链图谱生成具体包含:对各子数据库中文本进行分词处理,去除停用词、语气词、编码符号干扰。
14.进行特征表示以及文本特征提取,本文采用tf-idf 算法,获取得到每个文本的词向量特征f;在各子库中对相应的文本数据进行相似性的计算,可选择的采用余弦距离度量、jaccard 距离度量的一种或多种,得到文本间词向量特征相似度s;进行文本聚类得出产业链主题中,由于通过网络抓取的大量无实际含义的分词会构成聚类主题,因此提出的聚类方法可以排除这种干扰,提升产业链图谱聚类的精度,具体聚类过程如下:对每个文本得到的词向量相似度计算后,建立词向量相似度图t=《s,d》,其中s代表文本间词向量特征相似度,d为文本集合构成的边;计算相似度图中词向量特征的偏差度:,其中,dv表示偏差度,dist(d)为相似度图中任意一条边的相似度,d为边的集合。
15.设定一个偏差预设参数
µ
=0.25,遍历上述相似度图找到总体偏差值大于预设参数,删除偏差较高的一些簇(子图);遍历相似度子图中顶点个数,删除顶点个数大于一定数量的子图;重复遍历上述相似度图找到总体偏差值大于预设参数,删除偏差大于预设参数的子图,直到到达遍历次数或者子图变化小于一定阈值时终止条件;完成聚类的分析后,将每个簇的主题及主题关系抽取出输出对应的产业链主题内容。上述通过相似度图中偏差度计算,保证了无意义的文本不会被用来构成主题,提升数据主题聚类的准确度。
16.由于产业链中不同主题内容会处于不同产业链位置,因而本技术进一步对得到的与产业链相关主题进行类型识别,分别得到产业图谱中上、中、下游产业图谱内容。具体通过监督学习算法对前期收集的大量产业图谱上中下游主题内容,并按照上中下游类别分别进行标记形成学习样本,并基于有监督的样本识别方法进行识别模型训练,本技术采用bp神经网络、svm或深度学习网络的一种。
17.产业发展历程图谱生成,通过产业图谱系统对上述得到的专利数据进行统计,依据专利申请数量统计产业阶段,具体包括产业萌芽期、快速发展期、成熟期以及衰落期,并按照得到的各个产业阶段对应的时间范围,对属于该时间范围内该产业的各子库按照上述产业链图谱生成中的方法进行文本聚类,形成各个阶段的产业图谱数据,各个阶段的产业图谱对应生成产业发展历程图谱内容。
18.产业发展历程图谱生成模块,通过产业图谱系统对上述得到的专利数据进行统计,划分为产业萌芽期、快速发展期、成熟期以及衰落期,并按照得到的各个阶段对产业申请对该产业的各子库按照上述产业链图谱生成中的方法进行文本聚类,得到该产业各发展阶段的涉及的发展历程图谱内容。
19.产业图谱报告融合输出模块,基于产业图谱生成模型得到产业政策图谱、产业链图谱和产业发展历程图谱后,系统会针对数据进行自动化合并整理,进行可视化展示,最后在系统面板处生成报告并进行多种文件格式导出。具体导出文件的格式包含但不限于pdf、图片文件、html等形式。
20.除此之外,本技术还提供了一种产业图谱智能生成方法及系统,其特征在于,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的计算机可执行指令,所述处理器执行所述计算机可执行指令以实现上述产业图谱的智能生成方法。所述计算机可执行指令在被处理器调用和执行时,计算机可执行指令促使处理器实现上述企业需求数据处理方法。
21.与现有技术相比,本发明的有益效果是:提供了一种基于大数据的产业图谱生成方法和系统,通过智能化的的分析和挖掘,构建了产业政策图谱、产业链图谱和产业发展历程图谱三个维度的融合产业图谱,非本领域的从业人员通过该系统可以依据产业图谱需求,方便快捷的生成对应产业类别下的产业图谱,极大的提升的产业数据分析的效率。系统会针对图谱数据进行自动化合并整理,进行可视化展示,并以多种文件格式导出供企业查看,具有很好的用户体验。
附图说明
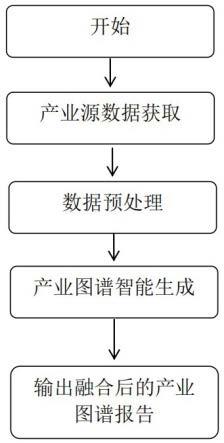
22.图1本技术产业图谱生成流程图;图2 依据本技术产业图谱生成方法得到的产业图谱示意图。
具体实施方式
23.下面结合附图对本发明作进一步详细描述:结合附图1,本发明产业图谱的智能生成方法是通过以下技术方案实现的:步骤1:产业源数据获取,按照产业类别在对应行业下获取源数据,获取源数据中可通过以下多种方式获取,包含但不限于web爬虫、企业微信、小程序等。获取的数据至少包含产业类别下的投融资数据、政策数据、科研项目数据、专利数据,上述数据中至少包含数据内容和发布时间;步骤2:数据预处理,按照预设的规则对获取的源数据按照数据类别进行清洗、整理、再定义,通过数据标签将处理后的源数据分别存储于投融资数据子库、政策数据子库、科研项目数据子库、专利数据子库;步骤3:产业图谱智能生成,包括产业政策图谱、产业链图谱和产业发展历程图谱;步骤3.1 产业政策图谱生成,对上述存储于政策数据库中产业政策数据进行知识图谱构建,得到产业政策图谱;具体步骤包含:对政策子数据库中文本进行分词处理,去除停用词、语气词等干扰项;对分词进行关键词提取和统计分析,得到政策文件的关键词;构建共词矩阵;本发明基于科技政策数据的外部特征的外部特征和内在知识元素来构建科技政策知识图谱中所需实体,主要包括政策类别、机构、关联政策、省份、城市5个实体类型, 本体中的实体属性及描述包含发布年份、一般鼓励条文、大力发展条文和禁止条文以及对应的描述;关系定义包含关联关系、依从关系、引用关系。对上述定义的三元组进行内容抽取,构建产业政策《实体,关系,属性》的三元组知识图谱,具体属性类别的分类可以基于监督和非监督训练的方法获得。
24.步骤3.2 产业链图谱生成,对上述存储于各子库中的投融资数据、政策数据、科研项目数据、专利数据进行文本主题聚类分析,对得到的与产业链相关主题进行类型识别,分别得到产业图谱中上、中、下游产业图谱内容。产业链图谱生成步骤具体包含:对各子数据库中文本进行分词处理,去除停用词、语气词、编码符号干扰。
25.进行特征表示以及文本特征提取,本文采用tf-idf 算法,获取得到每个文本的词向量特征f;在各子库中对相应的文本数据进行相似性的计算,可选择的采用余弦距离度量、jaccard 距离度量的一种或多种,得到文本间词向量特征相似度s;进行文本聚类得出产业链主题中,由于通过网络抓取的大量无实际含义的分词会构成聚类主题,因此提出的聚类方法可以排除这种干扰,提升产业链图谱聚类的精度,具体聚类过程如下:对每个文本得到的词向量相似度计算后,建立词向量相似度图t=《s,d》,其中s代表文本间词向量特征相似度,d为文本集合构成的边;计算相似度图中词向量特征的偏差度:,其中,dv表示偏差度,dist(d)为相似度图中任意一条边的相似度,d为边的集合。
26.设定一个偏差预设参数
µ
=0.25,遍历上述相似度图找到总体偏差值大于预设参数,删除偏差较高的一些簇(子图);遍历相似度子图中顶点个数,删除顶点个数大于一定数量的子图;重复遍历上述相似度图找到总体偏差值大于预设参数,删除偏差大于预设参数的子图,直到到达遍历次数或者子图变化小于一定阈值时终止条件;完成聚类的分析后,将每个簇的主题及主题关系抽取出输出对应的产业链主题内容。上述通过相似度图中偏差度计算,保证了无意义的文本不会被用来构成主题,提升数据主题聚类的准确度。
27.由于产业链中不同主题内容会处于不同产业链位置,因而本技术进一步对得到的与产业链相关主题进行类型识别,分别得到产业图谱中上、中、下游产业图谱内容。具体通过监督学习算法对前期收集的大量产业图谱上中下游主题内容,并按照上中下游类别分别进行标记形成学习样本,并基于有监督的样本识别方法进行识别模型训练,本技术采用bp神经网络、svm或深度学习网络的一种。
28.步骤3.3产业发展历程图谱生成,通过产业图谱系统对上述得到的专利数据进行统计,依据专利申请数量统计产业阶段,具体包括产业萌芽期、快速发展期、成熟期以及衰落期,并按照得到的各个产业阶段对应的时间范围,对属于该时间范围内该产业的各子库按照上述产业链图谱生成中的方法进行文本聚类,形成各个阶段的产业图谱数据,各个阶段的产业图谱对应生成产业发展历程图谱内容。
29.步骤4:输出融合后的产业图谱报告,基于产业图谱生成模型得到产业政策图谱、产业链图谱和产业发展历程图谱后,系统会针对数据进行自动化合并整理,进行可视化展示,最后在系统面板处生成报告并进行多种文件格式导出。具体导出文件的格式包含但不限于pdf、图片文件、html等形式。
30.附图2为本发明实际产生的产业图谱报告结果示意图,包括包括产业政策图谱、产业链图谱和产业发展历程图谱。
31.在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
32.在本发明的描述中,除非另有说明,术语“上”、“下”、“左”、“右”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
33.最后应说明的是,上述技术方案只是本发明的一种实施方式,对于本领域内的技术人员而言,在本发明公开了应用方法和原理的基础上,很容易做出各种类型的改进或变形,而不仅限于本发明上述具体实施方式所描述的方法,因此前面描述的方式只是优选的,而并不具有限制性的意义。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1