一种基于元学习的地铁新开车站短期客流预测方法
1.本发明涉及交通客流预测技术领域,更具体地,涉及一种基于元学习的地铁新开车站短期客流预测方法。
背景技术:
2.精确的地铁车站短时预测客流,对于合理配置站内资源、缓解拥堵、降低运营风险具有重要意义。相比于历史客流数据充足的车站,新开通地铁车站的客流数据有限,这会降低新开车站内的短时客流预测精度,增加车站管理和运营的难度。因此如何精准预测新开通地铁车站的短时客流是亟待解决的问题,既有的短时客流预测方法普遍依赖于充足的历史客流数据,难以直接应用于新开通的地铁车站。
3.时空预测是大数据时代地铁运营管理的一项基础性任务。传统的时间序列预测方法已被广泛使用,如ha方法、arima、卡尔曼滤波方法等。近年来,许多经典的深度学习方法被引入到交通时空预测领域,如门控循环单元(gru)、cnn、st-resnet和st-gcn。随后,出现了基于rnn、cnn和gcn的混合模型,或者将残差架构与lstm(长短时记忆网络)相结合,用于地铁车站的短期客流预测。
4.总体而言,已有的时空模型表现良好需要提供大量数据支持。但是,由于新开通的车站客流数据不足,使得依赖于充足数据的时空预测模型无法达到令人满意的性能。因此,有必要引入一个框架,该框架不仅可以利用上述方法在具有足够数据的多个站点上捕获时空知识,而且可以将知识转移到数据稀缺站点。
5.迁移学习方法为在数据不足的情况下进行准确预测提供了解决方案,但在地铁客流预测方面的应用较少。迁移学习方法通过将知识从数据丰富的源域迁移到数据有限的目标域来解决问题。例如,为了解决数据不足的空气质量预测问题,迁移学习方法从数据丰富的城市学习多种模式的语义相关词典,同时将词典转移到数据不足的目标城市。又如,以数据模式和地理属性为标准,从数据充足的链路(即源链路)中选择与目标链路相似的链路(即数据不足的链路),并将知识转移到目标链路。然而,当知识从单一源域转移时,转移的性能不稳定。例如,如果源域和目标域的特征匹配良好,则迁移的性能表现较好。但是,如果源域和目标域的特征不匹配,则迁移学习方法将没有任何贡献,甚至会降低性能。
6.总之,目前针对新开地铁车站的短时客流预测主要存在以下问题:1)既有的短时客流预测方法依赖于充足的历史客流数据,难以应对数据缺乏条件下的地铁车站客流预测。2)虽然迁移学习方法为数据缺乏条件下的客流预测提供了解决方案,但既有迁移学习方法考虑单一目标之间的知识迁移,导致迁移学习的效果不稳定,例如迁移对象与被迁移对象之间的特征相似时,迁移效果较好,而当两者之间的特征不相似时,迁移效果较差。
技术实现要素:
7.本发明的目的是克服上述现有技术的缺陷,提供一种基于元学习的地铁新开车站短期客流预测方法,该方法包括:
8.将针对目标车站的短期客流预测问题建模为:
[0009][0010]
其中,su={s1,
…
,su}是一组源车站,s
t
={s1,
…
,s
t
}是一组目标车站,τ是历史时间步的数量,是目标车站第τ+1个时间步的客流,f为客流预测模型,θ0表示从源车站提取后迁移到目标车站的参数,至是目标车站的τ历史时间步的客流信息;
[0011]
通过以下步骤获得目标车站第τ+1时间步的客流:
[0012]
构建元学习器,该元学习器包括局部学习器和全局学习器,其中局部学习器用于在单个元学习任务上对基础网络进行训练,全局学习器用于优化所有单个元学习任务对应的总体损失,基础网络用于学习客流的空间和时间特征;
[0013]
利用元学习任务集优化所述元学习器,获得基础网络的先验知识θ0,其中每个元学习任务是包含车站空间位置和客流的时空信息的矩阵;
[0014]
将所述先验知识θ0作为基础网络的初始化参数,利用目标车站的历史客流信息预训练所述基础网络;
[0015]
针对目标车站,采集τ个历史时间步的客流信息,输入到预训练的基础网络,获得第τ+1时间步的客流信息。
[0016]
与现有技术相比,本发明的优点在于,构建一种基于元学习的深度学习模型,该模型可以从多个数据丰富的地铁站学习客流特征知识,并将知识转移到数据有限的新开地铁车站或其他的目标车站,提高了知识迁移的稳定性和新开地铁车站的客流预测精度。
[0017]
通过以下参照附图对本发明的示例性实施例的详细描述,本发明的其它特征及其优点将会变得清楚。
附图说明
[0018]
被结合在说明书中并构成说明书的一部分的附图示出了本发明的实施例,并且连同其说明一起用于解释本发明的原理。
[0019]
图1是根据本发明一个实施例的一个元任务的构建过程示意图;
[0020]
图2是根据本发明一个实施例的捕获客流长期的空间-时间依赖性的示意图;
[0021]
图3是根据本发明一个实施例的lstm的示意图;
[0022]
图4是根据本发明一个实施例的源车站的元学习任务集结构示意图;
[0023]
图5是根据本发明一个实施例的元学习器示意图;
[0024]
图6是根据本发明一个实施例的局部学习器的结构示意图;
[0025]
图7是根据本发明一个实施例的局部学习器和全局学习器的更新过程示意图;
[0026]
图8是根据本发明一个实施例的将知识应用到目标车站的过程示意图;
[0027]
图9是根据本发明一个实施例的南宁地铁数据集上不同模型和数据量的预测性能比较示意图;
[0028]
图10是根据本发明一个实施例的杭州地铁数据集上不同模型和数据量的预测性能比较示意图;
[0029]
图11是根据本发明一个实施例的南宁地铁会展中心站实际值与预测值对比示意图;
[0030]
图12是根据本发明一个实施例的杭州地铁钱江路站实际值与预测值对比示意图;
[0031]
图13是根据本发明一个实施例的杭州地铁凤起站实际值与预测值对比示意图;
[0032]
附图中,source domain-源域;task set-任务集;target domain-目标域;line-线路;fusion-融合;real time-实时;forget gate-遗忘门;input gate-输入门;output-输出门;source stations-源站;basic network-基础网络;loss-损失;optimal weight-优化权重;optimal bias-优化偏置;data volumn-数据量。
具体实施方式
[0033]
现在将参照附图来详细描述本发明的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本发明的范围。
[0034]
以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。
[0035]
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
[0036]
在这里示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。
[0037]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
[0038]
本发明提出了一种元长短时记忆网络模型(即meta-lstm)用于预测新开地铁车站的短时客流。该模型通过构建深度学习框架,使得长短时记忆网络(lstm)能够在多个数据充足的地铁车站学习客流特征,从而提高lstm对多种客流特征的泛化能力,然后通过参数初始化方式将学习到的参数应用于数据缺乏的新开车站。并且,在南宁、杭州、北京的地铁网络上对meta-lstm进行了测试,结果表明meta-lstm的预测效果优于现有的几个具有竞争力的模型,并且meta-lstm对多种客流特性具有良好的泛化能力,可以为缺乏客流数据的车站的客流预测提供参考。
[0039]
在下文中,将从以下方面描述本发明:首先,定义所使用的符号,并对新运营地铁站短期客流预测问题进行定义。然后,介绍如何构建用于知识学习的任务,并描述所提出的元学习方法如何通过多个元学习任务从数据丰富的站点学习知识,并将学到的知识转移到数据有限的新开车站。最后,在多个urt数据集上评估了所提出的元学习方法。
[0040]
一、问题定义
[0041]
定义1(时空序列):假设有n个地铁车站。根据数据采集的粒度,将研究时段分为t个时间间隔。那么,第i站的时空序列被表示为一个张量其中i∈n。对于一个包含i个站点的元学习任务,任务的时空序列被表示为xi=[x1,
…
,xi]。
[0042]
问题定义:给定一组源车站su={s1,
…
,su}和一组目标车站s
t
={s1,
…
,s
t
},目标是在s
t
缺乏数据(即新开通的车站)而su能够提供充足数据的前提下,利用s
t
中前τ个时间步的客流来预测下一个时间步的客流。该问题描述如下:
[0043]
[0044]
其中,是第τ+1个时间步的客流,f为客流的预测模型,θ0表示从源车站提取后迁移到目标站的初始化参数。
[0045]
二、模型介绍
[0046]
1)元学习任务构建
[0047]
元学习任务是一个包含了车站空间位置和客流的时空信息的矩阵。例如,将所有源车站和目标车站按照地铁线路的顺序分别构建成一个一维序列。每个一维序列承载着各站的相对位置信息,并根据目标车站的数量来设定元学习任务的大小,即单个元学习任务中的车站数。参见图1所示,目标域中有10个站,从源域中选择前10个站作为第一个元学习任务,后续10个站作为第二个任务。然后对后续多个任务的车站数量进行相应确认。
[0048]
车站的客流具有空间-时间上的相关性,主要体现在:一个车站的当前客流会受到最近时间间隔的影响;在相邻的两天,客流可能相似;而相同的客流分布可能每周都会出现。此外,不同车站的客流可能相互影响。因此,在获得车站位置的基础上,设置不同的客流模式(如实时模式、日模式和周模式)来捕捉长期的空间-时间依赖性,如图2所示。例如,车站内客流的时间序列表示为:
[0049][0050]
其中,t表示第t个时间间隔,τ是历史时间步数,分别代表实时模式、日模式和周模式下在第t个时间间隔的客流。以源车站为例,将多个车站的时间序列定义为:
[0051]
x
u,t
=[x
1,t
,x
2,t
,x
3,t
,
…
,x
u,t
]
t
ꢀꢀ
(3)
[0052]
其中,u为车站的索引。
[0053]
2)知识学习与迁移
[0054]
为了从源车站学习知识,并将知识转移到目标车站,提出了一种元学习方法,主要包括三个部分:基础网络、元学习器和将知识应用到目标车站。基础网络用来学习客流的空间-时间特征。元学习器是一个深度学习框架,通过多个元学习任务提高基础网络对各种客流特征的泛化能力。将知识应用于目标车站是指将学到的知识以参数初始化的形式应用于目标车站的客流预测,其中在目标车站用于预测的网络也是上述的基础网络。
[0055]
在一个实施例中,选择长短时记忆网络(lstm)作为基础网络。参见图3所示,lstm有一个带有重复神经网络模块的链式形式,重复的神经网络模块(即记忆单元)有相互作用的四层,分别为细胞状态(cellstatus)、输入门(inputgate)、遗忘门(forgetgate)和输出门(outputgate),能够有效捕捉较长周期的短时客流特征信息,其中细胞状态结构提供了一个信息传递的路径,遗忘门控制从上一时刻的细胞状态中获得多少信息,由遗忘门的值决定,如式(4)所示:
[0056][0057]
其中,为当前的遗忘门,σ为激活函数,w和b是可学习的权重和偏置,h
t-1
是隐藏
状态,表示前一序列的信息,x
t
是当前输入的数据。输入门гi决定了当前时刻可以传递多少信息,它使用激活函数σ将选定的信息转换成可以添加到细胞状态的形式。然后,它使用一个候选的细胞状态向量用于更新细胞状态。过程如下:
[0058][0059][0060]
最后,结合遗忘门和输入门来更新当前时刻的细胞状态c
t
,并设置一个输出门гo来控制输出信息。
[0061][0062][0063][0064]
上述遗忘门、输入门和输出门的取值范围都在[0,1],若门的值为0或1,则表示记忆单元不保存任何信息或全部信息,在(0,1)中的其他值意味着只有部分信息可以传递到下一个部分。h
t
表示某个车站的客流信息。下一个时间步的客流序列可以通过以下方式预测:
[0065][0066]
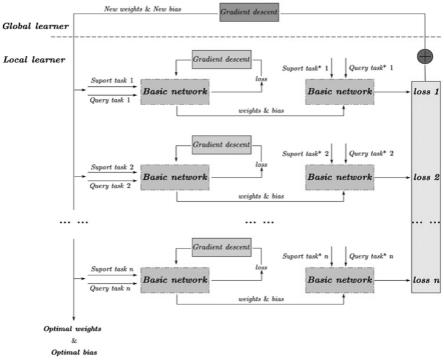
元学习器是一个深度学习框架,它通过多个元学习任务提高基础网络对各种客流特征的泛化能力,元学习任务集的构造参见图4所示,包含两部分,即训练任务集(traintaskset)和测试任务集(testtaskset)。在每个任务集中,supporttask(支持任务)用于训练,querytask(查询任务)用于测试。为了提高基础网络对各种客流特征的泛化能力,目标是在源车站的每个任务上用少量的梯度步骤优化模型参数,然后使整个源站的泛化损失的平均值最小,如图5所示,因此数据量受限的新任务上仍然是有效的。元学习器的优化目标表示为:
[0067][0068]
其中,θ0是将要被迁移到目标车站的参数(即最优的权重和偏置)。考虑从源车站获取的任务分布p(ts)。任务ti为从p(ts)中采样,ts表示源车站的全部任务,表示任务ti的真实值。参数由基础网络在训练任务集上输出。其中不一定要最小化训练任务集中单个任务的损失,但需要最小化测试任务集中所有任务的总损失。表示当参数为时任务ti的预测值,是任务ti的真实值。l是损失函数。
[0069]
仍结合图5所示,元学习器由local-learner(局部学习器)和global-learner(全局学习器)组成。local-learner用于提高基础网络在单个元学习任务中捕捉客流时空特征的能力。local-learner首先使用元学习任务ti(即traintaskset中的任务)和相应损失的反馈进行训练,然后在新任务(从testtaskset中采样的任务)上进行测试。
[0070]
图6是一个local-learner的结构示例。为了进一步解释,假设有一个参数为θ的参数化函数f
θ
。当将其应用到新任务ti时,将参数θ更新为如图7的(a)所示。以一次梯度更新为例,local-learner表示如下:
[0071][0072]
其中α是local-learner的学习率,代表梯度下降(gradientdescent)的操作。
[0073]
global-learner是使基础网络能够对多种任务具有优越的泛化性能,它的更新过程是通过优化所有采样于p(ts)的任务中关于θ的性能来实现,如图7的(b)所示。学习过程以参数迭代更新的形式呈现,即:
[0074][0075][0076]
其中β是global-learner的学习率。
[0077]
将式(14)右侧的梯度部分展开,可以得到:
[0078][0079]
根据式(12),式(15)可以表示为:
[0080][0081]
式中存在一个二阶微分,会增加计算复杂度,降低计算效率。因此,有必要通过以下操作简化降低微分阶数。在地铁车站内,客流预测是一个多元线性回归问题。因此,local learner和global learner的损失函数都是多元线性回归问题,这意味着损失函数的二阶偏导数为零,即:
[0082][0083]
那么,global learner的更新过程将简化如下:
[0084][0085]
经过适当简化后,在参数更新过程中只考虑一阶梯度,这也简化了计算过程。然后,可以将初始化参数θ0迁移到目标车站。目标车站可以在先验知识的基础上学习新的知识,获得更好的泛化性能。
[0086]
进一步地,将知识应用于目标车站。为了提高目标车站的预测精度,首先利用先验
知识θ0作为目标车站预训练(pre-training)的初始化参数,然后将预训练获得的权重和偏置应用于测试,如图8所示。参数通过迭代来更新。例如,一个梯度更新过程表示为:
[0087][0088]
其中l
tn
是目标车站的损失函数,γ是设定常数,表示目标车站客流预测训练时的学习率。
[0089]
三、实验结果分析
[0090]
1)数据集描述
[0091]
从三个城市收集了三个地铁的afc数据集:1)北京地铁数据集(05:00-23:00,2016-02-29至2016-04-03);2)杭州地铁数据集(06:00-23:00,2019-01-01至2019-01-25);3)南宁地铁数据集(06:30-22:00,2016-06-28至2016-07-17)。截至2016年3月,北京地铁共有17条线路,276个地铁站(不含机场快线及对应站)分别于1971年至2014年间开通运营。截至2016年6月,南宁地铁新开通1条线路10站。截至2019年1月,在杭州地铁共有3条线路,80个地铁站。杭州地铁的3条线路在2012年至2015年期间开通运营。运营中的地铁线路详细信息见表1。只考虑了工作日数据且客流时间间隔为15分钟。
[0092]
虽然杭州地铁三条线已经运营了一段时间,但相比于北京地铁,其客流分布特征还是缺乏,南宁地铁站全部新建。因此,以北京地铁站为源车站,南宁地铁和杭州地铁站为目标车站。对于每个源车站,选择80%的数据进行训练和验证,其余的进行测试。对于每个目标站,选择1天、3天和5天的数据进行训练,其余的进行测试。
[0093]
表1地铁线路的运营时间
[0094][0095]
2)模型配置
[0096]
在源车站的训练过程中,每个lstm层由32个神经单元组成。lstm的输入和输出维度取决于每个元学习任务中的车站数。将local-learner和global-learner的学习率设置为0.001。每个元任务的更新次数设置为5。使用adam作为优化器。每次迭代的batch size大小设置为16,元学习的最大迭代次数设置为40000。在目标车站的训练过程中,将学习率设置为0.01。每次迭代的batch size为16,使用adam作为优化器。
[0097]
使用均方误差(mse)作为损失函数。为了平衡模型训练时间和预测性能,对于每个客流模式,使用前五个时间步来预测下一个时间步。在训练过程中,使用model checkpoint和early stopping技术来保存最佳模型并避免过度拟合。
[0098]
3)基线模型
[0099]
实验中,设置了两种基线模型,包括非迁移模型和迁移模型。对于非迁移模型,使用的模型为arima、ha、lstm、cnn和st-resnet,并且使用目标车站的训练数据进行训练,其余的数据用于评估。对于迁移模型,使用fine-tuning方法和meta-cnn模型,使用源车站的训练数据来训练它们并将知识应用到目标车站,基线模型的详细信息如下。
[0100]
arima:用于时间序列预测的具有代表性的基于数理统计的模型。
[0101]
ha:ha模型使用历史客流数据的平均值进行预测。
[0102]
lstm:长短时记忆网络。包括一个隐藏层和两个全连接层。每个lstm层由32个神经单元组成。优化器是adam,学习率为0.01。lstm的输入和输出维度取决于每个元学习任务中的车站数。
[0103]
cnn:卷积神经网络(cnn)是一种具有深度结构和卷积计算的前馈神经网络。设置了四个卷积层和一个全连接层。cnn层的参数分别是out channels=1、kernel size=3、stride=1和padding=1。优化器是adam,学习率为0.01。输入进站与出站客流量,输出为进站客流量。
[0104]
spatial-temporal residual network(st-resnet):该方法基于残差网络考虑了客流数据的时空关系。设置了两个残差块,每个块由两个卷积层组成。卷积层的参数与cnn相同。
[0105]
fine-tuning method(ft):该方法是在源车站中随机选择一个元学习任务,然后在选定的元学习任务中训练一个基础网络,将其应用于目标车站并微调。实验中设置了两种fine-tuning方法:1)ft-cnn:选择cnn作为基础网络,卷积层的参数与cnn相同;2)ft-lstm:选择lstm作为基础网络,基础网络的参数与上述lstm相同。
[0106]
meta-cnn:该方法使用与meta-lstm相同的框架,而基础网络由cnn代替。meta-learner的参数和meta-lstm一样,卷积层的参数与上述cnn一样。
[0107]
4)评价标准
[0108]
使用的评价指标为均方根误差root mean square error(rmse)、平均绝对误差mean absolute error(mae)和加权平均绝对百分比误差weighted mean absolute percentage error(wmape),分别表示为:
[0109][0110][0111][0112]
其中,为真实值总和。
[0113]
5)结果与讨论
[0114]
实验中,评估了本发明的模型,并将其与两个地铁数据集上的基线模型进行比较。结果涉及三个部分:1)新开通车站(即南宁地铁站)的客流预测,预测性能见表2和图9;2)运营多年的车站(即杭州地铁站)客流预测,预测性能见表3和图10;3)分析元学习框架对预测性能的改进。为了便于书写,将cnn、ft-cnn、meta-cnn和st-resnet定义为基于cnn的模型,并将lstm、ft-lstm和meta-lstm定义为基于lstm的模型。
[0115]
(1)新开车站预测性能
[0116]
从模型类别来看,arima和ha的性能比基于cnn的模型差,而基于cnn的模型比基于lstm的模型性能差。在数据量为1天的实验中,arima的性能比基于cnn的模型和基于lstm的模型差。arima模型几乎无法给出有利的预测结果。在3天和5天数据的实验中,arima的性能有了显着提升,但仍然比其他模型差。结果表明,新开车站客流不稳定,规律性较差。对于
arima模型,它根据历史值和历史值的预测误差来预测当前客流。如果数据具有很强的日周期性,模型的预测误差将会降低,可以获得完美的预测性能。但新开通车站的客流日周期性还未确立。arima很难找到每日的周期性,这降低了arima的准确性。随着数据量的增加,客流的规律性逐渐显现,性能得到提升。在数据量为1天的实验中,ha的性能比基于cnn的模型和基于lstm的模型差。在3天和5天数据的实验中,ha的性能得到了改善。ha模型优于几乎所有基于cnn的模型(st-resnet在5天数据实验下的性能除外),但仍比所有基于lstm的模型差。结果表明,与arima不同,ha模型的客流预测是基于历史数据的平均值,减少了客流不稳定对预测结果的影响。然而,当ha模型使用历史数据的平均值进行预测时,客流信息也有所减少。与ha模型相比,基于lstm的模型具有更好的性能,特别是我们提出的旨在捕捉历史客流的全部特征的meta-lstm。
[0117]
在数据量为1天、3天和5天的实验中,基于cnn的模型的性能比基于lstm的模型差。基于cnn的所有模型中性能最好的是st-resnet。其他三个模型(即ft-cnn、cnn和meta-cnn)的预测性能从差到好。结果表明,不灵活地应用迁移学习方法并不一定会提高目标站点客流预测的性能。当源车站和目标车站的客流时空分布存在显著差异时(例如,源车站来自北京地铁,目标车站来自南宁地铁),迁移学习方法的不灵活应用表现出较差的性能(即,ft-cnn的性能比cnn差)。使用cnn作为本发明提出的元学习方法的基本模型,称为meta-cnn。当通过meta-cnn将源车站的知识学习应用到目标车站时,获得了比cnn更好的性能。与其他基于cnn的模型相比,st-resnet考虑了时间和空间相关性,这可能是st-resnet的性能优于其他基于cnn的模型的原因之一。
[0118]
此外,基于lstm的模型的性能优于其他方法。所提出的meta-lstm实现了最佳性能。ft-lstm的性能不稳定,原因是源车站和目标车站的客流时空分布不同。当源车站和目标车站的时空分布不匹配时,会降低预测的准确性。与lstm相比,本发明的模型不仅学习了更好的初始化,而且学习了多种元知识,包括长期短期客流信息和来自源车站元任务的空间相对位置信息,然后将知识迁移到目标车站,提高了预测性能。
[0119]
表2南宁地铁数据集上客流预测性能对比
[0120][0121]
(2)运营多年的车站客流预测性能
[0122]
将meta-lstm推广到运营了几年的车站(即杭州地铁网络),并分析了预测性能。从模型类别来看,传统预测模型(即arima和ha)的性能比基于cnn的模型差,而基于cnn的模型比基于lstm的模型性能差。模型预测性能排序与新开车站类似。
[0123]
在数据量为1天的实验中,arima和ha的性能比其他模型差,而arima和ha的性能差别不大。在3天和5天数据的实验中,虽然arima和ha的性能有所提高,但它们之间的准确率差距却有所增加。ha模型的性能优于所有基于cnn的模型,并且性能比基于lstm的模型差。运行多年的站点的预测性能与新运行站点的结果相似(详见表3)。结果表明,杭州地铁车站(即运营多年的车站)客流存在一定的周期性,而客流量仍不稳定,ha模型减少的信息量较少,因为杭州地铁站客流不稳定的程度较低。然而,ha模型捕捉时空特征量小于基于lstm的模型,这导致ha的性能比基于lstm的模型差。尽管增加了数据量,但arima捕捉客流特征的能力仍弱于基于lstm的模型和基于cnn的模型。
[0124]
在数据量为1天的实验中,所有基于cnn的模型都优于arima和ha(即,按1天数据的性能排序:cnn》ha》arima)。在3天和5天数据的实验中,基于cnn的模型的性能比ha模型差,而在1天、3天和5天数据的实验中,所有基于cnn的模型都表现良好比基于lstm的模型差(即,按3天和5天数据的性能排序:ha》基于cnn的模型;对于1天、3天、5天的数据:基于lstm的模型》基于cnn的模型)。在所有基于cnn的模型中,st-resnet性能最佳。meta-cnn和ft-cnn的性能仅次于st-resnet。cnn的性能最差(即,按基于cnn的模型的性能排序:st-resnet》meta-cnn和ft-cnn》cnn)。数据量为1天和3天时,ft-cnn优于meta-cnn,而数据量为5天时ft-cnn的性能比meta-cnn差。结果表明,简单地在单个目标之间迁移知识是不稳定的。而通过从多个源站学习知识,使得meta-cnn的性能比ft-cnn更稳定。对于st-resnet,考虑了时间和空间相关性,这显着提高了性能。
[0125]
在所有实验数据量下,基于lstm的模型都比所有其他模型表现得更好,其中本发
明提出的meta-lstm实现了最佳性能。ft-lstm仅次于meta-lstm,lstm的性能是所有基于lstm的模型中最差的(即,按基于lstm的模型的性能排序:meta-lstm》ft-lstm》lstm)。结果表明,随着车站运营时间的增加,客流具有周期性,因此在客流数据有限的情况下,ft方法的性能优于非迁移学习方法。本发明提出的meta-lstm可以学习多个长期知识,这提高了结果的稳定性并获得了更好的性能,尽管源车站和目标车站之间的客流分布不同。
[0126]
表3杭州地铁数据集上客流预测性能与基线模型的比较
[0127][0128]
(3)元学习框架对预测性能的改进
[0129]
meta-lstm的预测性能是所有目标站的平均值。元学习框架如何提高基础网络的性能并不直观。因此,在这一部分继续分析元学习框架对基础网络的哪些方面进行了改进。
[0130]
选择三个典型的站点作为实例。第一个是南宁地铁一号线会展中心站。位于五路交汇处,未来规划为地铁1号线、4号线换乘站。预计每天都会有大量客流进站。另外两个站,钱江路站和凤起站,是杭州地铁一号线和二号线、二号线和四号线的换乘站。
[0131]
会展中心站是新开车站。大部分旅客以试探性的态度进站,日客流量呈现逐渐增加的趋势,如图11所示。使用lstm对高峰时段客流的预测性能优于非高峰时段的客流预测性能。meta-lstm和lstm预测的高峰时段客流性能差异不大,meta-lstm提高了非高峰时段的客流预测性能。但是,随着数据量的增加,这种改善则不显著。
[0132]
钱江路站和凤起站位于一个以居民为主的社区周围,早上有数千人通勤,导致早高峰的客流量明显高于晚高峰,如图12和图13所示。在这两个站点中,meta-lstm和lstm预测的高峰时段客流预测性能几乎一致。在非高峰时段,meta-lstm的表现优于lstm。随着数据量的增加,两种模型的性能差距逐渐缩小。
[0133]
总的来说,对于高峰时段的客流预测性能,meta-lstm和lstm是没有区别的。元学习框架对预测性能的改进主要体现在非高峰时段,随着数据量的增加,对改进的影响变得不显著。一个可能的原因是高峰时段的客流特征是单一的(即高峰时段的客流量是一个单
峰),这两种模式都能很好地应对。非高峰时段客流波动使客流特征复杂化。因此,具有良好泛化能力的meta-lstm的性能优于lstm。
[0134]
综上所述,本发明首次提出meta-lstm用于地铁车站客流预测,可用于新开地铁车站的客流预测,也可用于数据缺乏的非新开车站,能够提高预测精度。此外,本发明提出了元学习任务,用于存储地铁车站的客流信息和车站空间位置,是实现新开地铁车站客流预测的关键部分。实验结果表明,本发明在新开地铁车站的客流预测精度高于几个有竞争力的客流预测模型,并且将本发明推广到数据缺乏条件下的非新开地铁车站后,预测精度高仍于几个有竞争力的客流预测模型。
[0135]
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
[0136]
计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。这里所使用的计算机可读存储介质不被解释为瞬时信号本身,诸如无线电波或者其他自由传播的电磁波、通过波导或其他传输媒介传播的电磁波(例如,通过光纤电缆的光脉冲)、或者通过电线传输的电信号。
[0137]
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。本发明的范围由所附权利要求来限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1