基于循环多模态融合的机械臂抓取位姿检测方法
1.本发明涉及机械臂抓取位姿检测技术领域,尤其涉及基于循环多模态融合的机械臂抓取位姿检测方法。
背景技术:
2.近年来,深度学习技术在计算机视觉、自然语言处理、推荐系统、数据挖掘等领域都有良好的应用,启发到了机械臂抓取领域的研究人员。实验发现,训练好的深度神经网络能提高抓取位姿检测的精度和速度,同时减少人工的工作量,对未知物体也有较好的检测性能。但抓取位姿检测任务需要考虑更多因素,包括环境和夹具等。针对不同的场景和任务,机械臂的抓取往往会采取不同的夹具,应用最广泛的是吸盘式和平行夹持器。其中由于平行夹持器在实施抓取操作时能完成更多抓取任务,更具灵活性,受到广泛研究。针对不同的抓取方式可以将抓取位姿检测分为二维平面抓取和六自由度(6-dof)抓取。其中,平面抓取方法是指仅从一个方向获取待抓取物体的相关信息,并进行抓取。通常使用的输入信息为rgb图像和rgb-d图像。
3.lenz等人(lenz i,lee h,saxenaa.deep learning for detecting robotic grasps[j],the international journal ofrobotics research,2013,34:4-5)首次将深度学习应用于抓取位姿检测领域,利用滑窗(sliding window)对整张图片进行遍历,将每个图像块先输入到第一级网络中进行学习,得到大致的抓取位置,再通过第二级更深的网络学习到更准确的位置。kumra等人(kumra s,kanan c.robotic grasp detection using deep convolutional neural networks[c].ieee/rsj international conference on intelligent robots and systems(iros),vancouver,canada,2017:769-776)采用两个并行网络结构进行多模态融合的抓取检测模型,输入分别是rgb图像和三通道的深度图像。首先利用两个深度卷积神经网络resnet-50分别从场景中提取特征,然后将两个并行网络得到的特征图进行融合,最后再利用浅卷积神经网络预测给定对象的抓取位置。zhang等人(z.f.zhang q,xu f,etc,robust robot grasp detection in multimodal fusion,international conference on mechanical,electronic and information technology engineering(icmite),2017.)提出了一种基于回归和分类的方法来处理数据融合问题,并引入了welsch函数来增强训练过程的鲁棒性。guo等人(guo d.,sunf.,liu h.,kong t.,fang b.,x.n.,ahybrid deep architecture for robotic grasp detection,2017ieee international conference on robotics andautomation(icra),2017.)提出了一种新的混合神经网络来处理多模态数据,并通过在抓取过程中结合视觉和触觉信息来检测最佳抓取姿势。
[0004]
目前的一些基于深度学习的机械臂抓取位置检测方法中,lenz设计的两阶段检测方法是深度学习在机械臂抓取位置检测的首次运用,具有开创性价值,为人们提供了新的研究方向,但是该方法对整张图片进行滑窗遍历,非常的耗时,并且每个图像块还必须进入两级网络,导致网络的实时性非常的差。而kumra采用两个并行网络结构进行多模态融合的
抓取检测模型,该方法相比于之前的模型大大提高运行速度,实现了实时性检测,该模型利用两个深度卷积神经网络提取得到图像rgb和深度信息分别从场景中提取特征,是一个不错的思路,有着不错的准确率,然而该网络忽略两个深度卷积神经网络隐藏层产生的特征图,中间层的特征可能隐含着检测物体的其他重要信息,我们提出的本发明的基于循环多模态融合的机械臂抓取位姿检测方法尝试提取不同层级的网络的抽象特征进行融合。zhang、welsch、guo等人提出的方法和kumra一样大多数都是简单地从两个卷积网络的最后一层提取特征,并通过全连接或最大池化层将这些特征结合起来,融合过程中没有充分利用两种信息类型的全部信息对最后机械臂抓取位置的检测会有一定的影响。
[0005]
为此,我们提出了一种单阶段的机械臂抓取位姿检测模型,从卷积网络的多个隐藏层中提取rgb和深度信息,再通过一个循环神经网络将这些特征组合起来,循环神经网络的存储单元将这些特征组合为若干数据序列,从数据序列中选择和保留最相关的信息。
技术实现要素:
[0006]
本发明的目的是提供基于循环多模态融合的机械臂抓取位姿检测方法,用于解决技术背景中提到的现有技术问题。
[0007]
为了实现上述目的,本发明采用了如下技术方案:
[0008]
本发明提供基于循环多模态融合的机械臂抓取位姿检测方法,包括以下步骤:
[0009]
将同一物体的rgb图像和深度图像输入到两个并行的结构相同的多模态特征提取模块;
[0010]
从不同隐藏层和最终输出层中提取对应的不同级别的抽象特征;
[0011]
将提取的抽象特征通过投影块进行单独转换以投影到同一个公共的特征空间中,然后通过拼接模块将投影到同一特征空间的特征向量进行拼接;
[0012]
将拼接好的特征向量输入循环神经网络进行多模态特征融合获取更紧凑的多模态特征表示;
[0013]
由三个卷积滤波器来分别获得预测出的中心点位置、抓取框的宽高以及抓取框的旋转角度。
[0014]
进一步地,所述投影块的结构为:
[0015]
第一个卷积层使用大小为7
×
7的过滤器,利用输入的空间维度、宽度和高度;
[0016]
第二个卷积层使用大小为1
×
1的过滤器,利用输入的深度。
[0017]
进一步地,其中,进行多模态特征融合获取多模态特征表示,表示为:
[0018][0019][0020]
式中,f
i*
表示从网络第i层中提取的rgb或深度特征,gi(.)表示一组非线性操作,即投影块操作,表示经过投影块处理后的rgb或深度特征,pi表示第i层的投影rgb和深度特征拼接特征。
[0021]
进一步地,所述循环神经网络包括有门控循环单元(gru)。
[0022]
进一步地,所述检测方法的损失函数计算如下:
[0023]
将抓取姿态估计看作回归问题,以平滑函数作为回归损失函数,损失函数表达式
为:
[0024][0025]
smooth(.)函数表达式为:
[0026][0027]
其中,n表示可操作的抓取位姿数量,q表示抓取质量,w表示抓取矩形的长度,θ表示旋转角度;将θ的取值区间用sigmoid(.)激活函数进行变换到[0,1]的范围内;smooth(.)函数中,σ表示平滑区域的超参数,取值为1。
[0028]
本发明还提供基于图像的循环多模态融合的机械臂抓取位姿检测系统,包括:
[0029]
多模态特征提取模块,用于提取rgb图像和深度图像的不同级别的抽象特征;
[0030]
特征投影模块,用于将多模态特征提取模块提取的抽象特征投影到同一个公共的特征空间中;
[0031]
拼接模块,用于将特征投影模块投影的同一个公共的特征空间的特征进行拼接;
[0032]
循环多模态融合模块,用于将拼接模块连接好的特征进行多模态特征融合。
[0033]
进一步地,所述多模态特征提取模块采用resnet-50深度神经网络。
[0034]
本发明至少具备以下有益效果:
[0035]
本发明提出了基于循环多模态融合的机械臂抓取位姿检测方法,引入了一种新型的多模态特征融合方法,利用两个卷积神经网络来分别处理rgb和深度信息,从不同层级的网络获得不同级别的抽象特征,然后通过投影块将这些处理后的特征组合在一起,接着为生成紧凑的多模态表示,运用循环神经网络进行融合增强特征信息,通过实验验证,本发明的方法相比去传统的方法有着更好的姿态估计成功率和目标抓取成功率。
附图说明
[0036]
为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0037]
图1为本发明方法模型的整体过程示意图;
[0038]
图2为投影块结构示意图;
[0039]
图3为jaccard指数图解示意图;
[0040]
图4为康奈尔数据集上部分实验结果可视化。
具体实施方式
[0041]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0042]
本发明介绍了一种新的机械臂抓取位姿检测方法——基于图像的循环多模态融合的机械臂抓取位姿检测。该模型主要是利用两个深度神经网络提取分别处理rgb和深度数据,从不同层级的隐藏层中提取不同层次的网络特征,根据这些特征和一些操作最后得
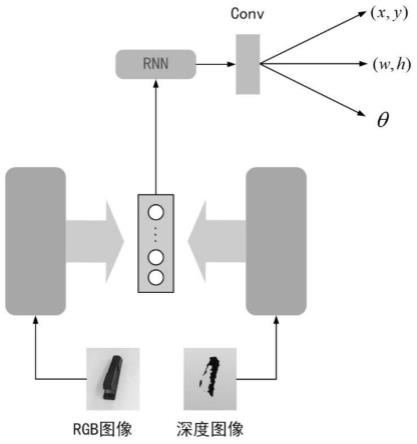
到图像中物品的最佳抓取位置。本发明主要由多模态特征提取模块、特征投影和拼接模块及循环多模态融合模块组成,整体流程如图1。具体如下:
[0043]
1.网络架构:
[0044]
如图1所示,把同一物体的rgb图像和深度图像输入两个结构相同的深度神经网络,考虑到计算和内存效率,选择了resnet作为分别提取rgb和深度信息的网络。resnet-50有50个卷积层布置在7个残差块中,从每个残差块中分别提取特征传递给投影块,获得不同级别的提取特征。两个resnet-50网络来分别处理rgb和深度信息、一个循环神经网络创建多模态特征表示,最后由三个针对特定任务的卷积滤波器来获得最终的结果,核大小为3
×
3,分别得到预测出的中心点位置、抓取框的宽高以及抓取框的旋转角度。
[0045]
最终的输出结果表达式为:
[0046][0047][0048][0049]
2.多模态特征提取:
[0050]
卷积神经网络通过一组从大量数据中学习到的滤波器来处理输入,这些滤波器代表了从输入到输出的更高层次的抽象特征:边缘、纹理、图案、部分和对象。在大多数情况下,对rgb-d数据处理的方式通常是将rgb信息和深度信息输入到相同的两个神经网络中,再将从两个神经网络提取出的最后一层输出特征进行结合,获得最终的多模态特征。这种策略基于一个假设,即所选的网络层代表相应的抽象级别,才能来组合这两种图像输入形式。因此,若能从通过在卷积网络的多个隐藏层中结合rgb和深度信息,并使用它们来生成具有高度区别性的rgb-d特征,可以消除这种假设。所以本发明采取了一种新的多模态特征融合方法。输入rgb和深度信息到两个相同结构的神经网络中,从不同层级中提取不同级别的抽象特征,将这些特征通过投影块进行单独转换,最后连接以获得更有用的rgb-d特征。已经证明,所选的卷积网络架构始终如一地从参考层生成具有相同抽象级别的特征。因此,当为rgb和深度信息选择相同的神经网络结构时,就可以通过每个相同的隐藏层获得相同级别的抽象特征。
[0051]
3.特征投影和拼接
[0052]
严格来说,从不同隐藏层提取的特征不属于同一特征空间,即不同特征向量的元素之间缺乏一对一的对应关系。因此本发明设计了一组投影块,旨在将这些特征投影到同一个公共的特征空间中,以便进行后续的特征拼接。投影块的结构是:第一个卷积层使用大小为7
×
7的过滤器,重点利用输入的空间维度、宽度和高度,而第二个卷积层使用大小为1
×
1的过滤器,利用其深度。最后,利用最大池化层来计算每个深度切片的最大值。投影到同一特征空间的特征向量将进行连接后,送入循环神经网络中获得多模态表示。结构如图2所示。多模态特征融合后的最终特征表示为
[0053][0054][0055]
式中,f
i*
表示从网络第i层中提取的rgb或深度特征,gi(.)表示一组非线性操作,
即投影块操作,表示经过投影块处理后的rgb或深度特征,pi表示第i层的投影rgb和深度特征拼接特征。
[0056]
4.循环多模态融合
[0057]
为了创建一个紧凑的多模态表示,从各层中提取出的特征集合被顺序地送到一个循环神经网络中。循环模型将元素在序列中的位置与计算时间的步长对齐,并根据前一个隐藏状态h
i-1
和当前输入的特征pi生成一个隐藏状态序列。
[0058]
在发明中使用循环神经网络中的一种门控机制——门控循环单元(gru,gated recurrent unit)来得到多模态特征的紧凑表示。gru改进了循环神经网络中隐藏状态的计算方式,加入了门的概念。与常用的长短期记忆(lstm)相同,gru旨在解决标准循环神经网络中的梯度消失和爆炸问题,并保留序列中的长期信息,且两种方法在序列任务上的性能相当。但相较之下,gru所需的参数比lstm少25%左右,仅包含一个更新门(update gate)和一个重置门(reset gate),这两个门控向量决定了哪些信息最终能作为门控循环单元的输出。第i个时间步中隐藏状态的第n个元素的更新门和重置门r
in
的计算方式为:
[0059][0060]rin
=σ(θrpi+γ
rhi
)n[0061]
激活函数σ(.)为sigmoid函数,θz、γz和θr、γr均为训练参数。更新门可以控制前一时间步与当前时间步的信息对当前隐藏状态的影响程度,即有多少信息需要传递到未来。重置门决定丢弃多少过去的信息。两者表达式相同,但线性变换参数和用处有所差异。
[0062]
接下来,基于重置门r
in
来计算候选隐藏状态
[0063][0064]
其中θh和γh为由训练得到的参数,
⊙
为按元素乘法符。由此可看出重置门控制了上一个时间步对当前时间步的影响程度。如果重置门接近0,即上一个隐藏状态被丢弃。
[0065]
最后,gru以自适应线性插值的方式利用更新门计算第i个时间步中隐藏状态的第n个元素:
[0066][0067]
该向量将保留当前时间步的信息并传递到下一个时间步中,它决定了当前时间步和前一时间步中需要传递的信息内容。若更新门接近于0,即上一个时间步中的输入信息几乎没有流入当前的隐藏状态,对当前状态产生微弱影响。这种计算方法可以更好地捕捉时间步相距较大情况下的信息相关性。
[0068]
经过以上流程之后,门控循环单元不会随时间而清除过去的信息,而是会保留相关的信息并传递到下一个时间步中,因此它利用全部信息从而避免了梯度消失问题。
[0069]
5.损失函数
[0070]
本发明通过优化预测抓取框g与和其对应的标签l之间的最小误差来训练模型。将抓取姿态估计看作回归问题,以平滑函数作为回归损失函数,损失函数表达式为:
[0071][0072]
smooth(.)函数表达式为:
[0073][0074]
其中,n表示可操作的抓取位姿数量,q表示抓取质量,w表示抓取矩形的长度,θ表示旋转角度。由于直接使用θ的取值区间容易产生较大误差,故将其用sigmoid(.)激活函数进行变换到[0,1]的范围内。smooth(.)函数中,σ表示平滑区域的超参数,本发明中取值为1。
[0075]
为了进一步验证本发明效果,我们设计实验如下:
[0076]
1.实验结果及分析
[0077]
大部分研究采取五折交叉验证的评估方法,本发明沿用该方法来评价模型性能。
[0078]
该方法将初始样本分割为5个子样本,其中4个样本作为训练数据,剩余1个子样本作为验证模型性能的数据,每个子样本验证一次。对训练集和测试集的划分方法有两种,分别是图像分割和对象分割。图像分割是指将数据集中的所有图像按五折随机划分,训练集与测试集的图像数量比例为4:1,这种分割方法有利于评估模型在检测物体位置和姿态时的性能。对象分割是指将数据集中的所有对象实例按五折随机划分,训练集与测试集的对象分割比例为4:1,这种分割方法有利于评估模型在测试未知对象时的性能。
[0079]
本发明利用康奈尔抓取数据集上的矩形度量标准来对给定图像上抓取位姿检测结果的准确率进行评估。如果预测出的抓取框g与ground truth中标注的抓取框g'同时满足以下两个条件,则认为该抓取框是一个正确的抓取位置。
[0080]
(1)|g
θ-g'
θ
|<30
°
[0081]
(2)
[0082]
其中条件(1)表示预测抓取框与标注矩形框的角度大小相差小于30
°
,这意味着两者抓取角度的差值在[-30
°
,30
°
]均可。条件(2)表示预测的抓取框与标注矩形框的交并比(intersection over union,iou)大于25%;在抓取位姿检测中,这一指标又被称为jaccard指数,如图3所示。
[0083]
在康奈尔抓取数据集上进行训练和测试,验证其有效性。模型取得了89.2%的图像分割检测精度和88.8%的对象分割检测精度,每张图像的检测时间为55ms。下表展示了能正确预测不同物体抓取位姿的次数。
[0084]
物体类别检测次数成功检测次数成功率运动鞋10880%香蕉1010100%帽子10880%尖头鞋10990%锁具10880%绳子10770%擀面杖1010100%剃须刀1010100%勺子1010100%
胶带10990%带线鼠标10880%
[0085]
2.可视化效果分析
[0086]
参阅图4,本发明对检测的部分结果即对应的数据集标注进行了可视化。第一行展示了部分目标的数据集标签,第二行展示了该方法在给定目标上检测出的置信度最高的点以及该点对应的其他参数组成的抓取矩形。可以看出,采用本发明的方法,检测结果与标签基本吻合。
[0087]
下表显示了本章节提出的抓取位姿模型分别在图像分割和对象分割两种分割方法下的位姿检测结果,以及其与以往一些算法的比较。
[0088][0089]
其中:
[0090]
【1】参阅:lenz i,lee h,saxena a.deep learning for detecting robotic grasps[j],the international journal ofrobotics research,2013,34:4-5
[0091]
【2】参阅:j.redmon,a.angelova,real-time grasp detection using convolutionalneural networks,robotics and automation(icra),ieee,2015ieee international conference on seattle,2014.
[0092]
【3】参阅:l.chen,p.huang,z.meng,convolutional multi-grasp detection using grasp path for rgbd images,robotics&autonomous systems(2019).
[0093]
【4】参阅s.kumra,c.j.i.kanan,robotic grasp detection using deep convolutional neural networks,2017ieee/rsj international conference on intelligent robots and systems(iros),vancouver,canada(2017)769-776.
[0094]
【5】参阅s.kumra,s.joshi,f.sahin,antipodal robotic grasping using generative residual convolutional neural network,ieee/rsj international conference on intelligent robots and systems(iros)ieee(2020).
[0095]
可知:本发明分别在将resnet-18和resnet-50作为分别提取rgb和深度信息的网络分别进行实验。得到的结论为,利用resnet-18作五层提取的网络模型分别在图像分和对象分割上获得84.3%和84.0%的准确率,而利用resnet-50作七层提取的网络模型分别在图像分割和对象分割上获得89.2%和88.8%的准确率,分别提高了4.9%和3.2%。但由于
resnet层数的不同,网络模型计算量不同,利用resnet-50作多模态特征提取网络的检测速度要慢于resnet-18。此外,本发明模型还与其他模型在图像分割、对象分割和检测速率方面进行对比。从表中可见,本发明的模型优于前三种anchor-free模型。模型【1】是最先将深度学习方法引入抓取位姿检测领域的模型,本发明模型与其相比在图像分割上提高了15.3%,在对象分割上提高了13.2%。与模型【2】相比,本发明模型在图像分割方面提高了1.2%,在对象分割方面提高1.7%;与模型【3】相比,本发明模型在图像分割方面提高了2.8%,在对象分割方面提高了4.1%;此外,模型【4】与模型【5】同样使用了多模态特征融合的思想并进行特征提取,本发明模型与模型【4】相比,在图像分割和对象分割上的准确度大致持平,但在检测速度上有较大提升;与模型【5】相比,本节模型在图像分割方面提高了0.5%,在对象分割方面提高了0.6%。
[0096]
综合上述可知:
[0097]
为了获得更优的多模态特征,本发明提出了一种基于循环多模态融合的机械臂抓取位姿检测模型;该模型引入了一种新型的多模态特征融合方法,利用两个卷积神经网络来分别处理rgb和深度信息,从不同层级的网络获得不同级别的抽象特征,然后通过投影块将这些处理后的特征组合在一起,接着为生成紧凑的多模态表示,运用循环神经网络进行融合增强特征信息。
[0098]
本发明提出了一种新型的图像特征提取方法,利用两个卷积神经网络来分别处理rgb和深度信息,从不同层级的网络获得不同级别的抽象特征。
[0099]
在实际环境中相比去传统的方法有着不错姿态估计成功率和目标抓取成功率。
[0100]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1