一种基于RASPBERRY的LCD监控屏制造气泡裂纹检测方法与流程
一种基于raspberry的lcd监控屏制造气泡裂纹检测方法
技术领域
1.本发明涉及人工智能图像识别技术领域,具体为一种基于raspberry的lcd监控屏制造气泡裂纹检测方法。
背景技术:
2.如今的电子产品,例如电脑和电视机显示器普遍都是用lcd屏幕作为显示设备。
3.而lcd屏也成为目前所主流的显示设备,然而在生产过程中,显示屏由于环境的影响,往往会出现一些工艺及质量方面的问题,导致产品外观存在气泡、裂纹的瑕疵,从目前来看,为了分辨出具体瑕疵和缺陷,传统企业都是通过人工来检测,由于人工检测往往都是主观判断瑕疵缺陷,一旦检测时间过长就会产生疲劳、误检及漏检等情况发生,从而导致工作效率下降。
4.为此我们提出一种基于raspberry的lcd监控屏制造气泡裂纹检测方法,通过在工业微型电脑raspberry pi(raspi/rpi)linux系统上使用python调用opencv模块,以实现lcd屏玻璃制造过程中的瑕疵检测。
技术实现要素:
5.本发明的目的在于提供一种基于raspberry的lcd监控屏制造气泡裂纹检测方法,以解决上述背景技术中提出的问题。
6.为实现上述目的,本发明提供如下技术方案:一种基于raspberry的lcd监控屏制造气泡裂纹检测方法,包括以下步骤:
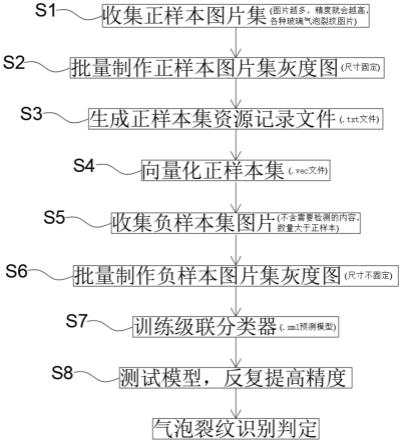
7.s1:收集正样本图片集,收集各种玻璃气泡裂纹图片;
8.s2:批量制作正样本图片集灰度图,样本全部为灰度图片,正样本图片尺寸需要固定,可根据服务器性能进行调整;
9.s3:生成正样本集资源记录文件(.txt文件),对样本集的各文件位置进行描述;
10.s4:根据描述文件向量化正样本集,生成.vec文件,为训练级联分类器做准备;
11.s5:收集的负样本图片中一定不要包含待识别的特征物体,负样本数量要比正样本多;
12.s6:批量制作负样本图片集灰度图,不过这里不要求尺寸一样;
13.s7:根据正样本集的.vec文件训练级联分类器,生成.xml训练模型文件;
14.s8:测试模型,通过调整参数反复提高精度,最终完成气泡裂纹的识别判定。
15.优选的,所述s1中收集的各种玻璃气泡裂纹图片越多则训练的精度越高,至少以万为单位。
16.优选的,所述s2中正样本图片的固定尺寸为40*40。
17.优选的,所述s2包括:
18.1)使用图片编辑软件将需要识别的瑕疵的图片全部裁剪出来;
19.2)再用图片编辑软件将批量将图片灰度化;
20.3)将图片自动有序排名并重新命名。
21.优选的,所述s3包括:
22.1)使用代码生成正样本资源记录文件;
23.2)生成后删除最后一行的带有(pos.txt)的内容,使文件位置进行描述。
24.优选的,所述s4包括:
25.1)使用opencv提供的opencv_createsamples.exe程序生成样本vec文件,并新建批处理文件:createsamples.bat。
26.优选的,所述s6包括:
27.1)新建neg文件夹,将负样本的灰度图拷贝进去,使用程序代码生成负样本资源记录文件;
28.2)生成后删除最后一行的带有(neg.txt)的内容。
29.优选的,所述s7包括:
30.1)使用opencv提供的opencv_traincascade.exe程序训练分类器,新建xml文件夹,再新建批处理文件:lbp_train.bat;
31.2)运行后会在xml文件夹生成新的文件。
32.优选的,所述s8中测试模型所使用的编程语言为python。
33.与现有技术相比,本发明的有益效果是:
34.综上所述,本发明基于raspberry并选择性能最稳定的linux系统,同时采用在物联网和人工智能领域使用最广泛的python编程语言,使得lcd监控屏的生产制造过程中采用一种低成本的ai智能识别方法,检测出玻璃产品的初步瑕疵,如气泡裂纹等,通过及时发现瑕疵,检查调整生产线的参数变化,提高产品的一次合格率。
附图说明
35.图1为本发明流程示意图;
36.图2为本发明正样本资源记录文件示意图;
37.图3为本发明负样本资源记录文件示意图;
38.图4为本发明xml文件夹生成示意图。
具体实施方式
39.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
40.请参阅图1-4,本发明提供一种技术方案:一种基于raspberry的lcd监控屏制造气泡裂纹检测方法,包括以下步骤:
41.s1:收集正样本图片集,收集各种玻璃气泡裂纹图片,收集的各种玻璃气泡裂纹图片越多则训练的精度越高,至少以万为单位;s2:批量制作正样本图片集灰度图,样本全部为灰度图片,正样本图片尺寸需要固定,可根据服务器性能进行调整,正样本图片的固定尺寸为40*40,同时使用图片编辑软件ps将需要识别的瑕疵的图片全部裁剪出来(尺寸一致
为:40*40),保存到一个文件夹pos中,可以先用大尺寸正方形框进行裁剪,然后再用图片缩小工具进行指定尺寸缩小,再用图片编辑软件ps批量灰度化图片,最后用名字自动有序化算法代码string path="c:\\pos\\";
42.file f=new file(path);
43.file[]files=f.listfiles();
[0044]
for(file file:files){i++;
[0045]
file.renameto(newfile(path+i+"."+file.getname().split("\\.")[1]));}将图片自动生成了以阿拉伯数字顺序命名的各图片,图片实际排序没有要求,并通过points*=math.pow(factor,qid-1)方法;循环读取图片名并进行重新命名;s3:生成正样本集资源记录文件(.txt文件),对样本集的各文件位置进行描述,使用代码string path="\\pos\\";
[0046]
file txtfile=new file(path+"pos.txt");
[0047]
fileoutputstream fos=new fileoutputstream(txtfile);
[0048]
printwriter pw=new printwriter(fos,true);
[0049]
string s="";
[0050]
file[]files=new file(path).listfiles();
[0051]
for(file file:files){pw.println("pos/"+file.getname()+"1 0 0 40 40");}生成正样本资源记录文件,生成后删除最后一行的带有(pos.txt)的内容,让正样本资源记录文件内容如附图2所示,其中(1 0 0 40 40)分别指代:数量,左上方的坐标位置(x,y),右下方的坐标位置(x,y);s4:根据描述文件向量化正样本集,生成.vec文件,为训练级联分类器做准备,使用opencv提供的opencv_createsamples.exe程序生成样本vec文件,并新建批处理文件:createsamples.bat,内容如下:opencv_createsamples.exe-vecpos.vec-info pos.txt-num30-w40-h40pause,说明:30是正样本图片的数量,根据实际有多少图片修改,40、40是正样本图片的宽高;s5:收集的负样本图片中一定不要包含待识别的特征物体,负样本数量要比正样本多;s6:批量制作负样本图片集灰度图,不过这里不要求尺寸一样,新建neg文件夹,将负样本的灰度图拷贝进去,使用程序代码string path="\\neg\\";
[0052]
file txtfile=new file(path+"neg.txt");
[0053]
fileoutputstream fos=new fileoutputstream(txtfile);
[0054]
printwriter pw=new printwriter(fos,true);
[0055]
string s="";
[0056]
file[]files=new file(path).listfiles();
[0057]
for(file file:files){pw.println("neg/"+file.getname());}生成负样本资源记录文件,生成后删除最后一行的带有(neg.txt)的内容,让负样本资源记录文件内容如附图3所示;s7:根据正样本集的.vec文件训练级联分类器,生成.xml训练模型文件,使用opencv提供的opencv_traincascade.exe程序训练分类器,新建xml文件夹,再新建批处理文件:lbp_train.bat,内容如下:opencv_traincascade.exe-dataxml-vecpos.vec-bgneg.txt-numpos30-numneg888-numstages10-w40-h40-minhitrate0.999-maxfalsealarmrate0.2-weighttrimrate0.95-featuretype lbp pause,说明:30是正样本
图片的数量,888为负样本图片的数量,根据实际有多少图片修改,numneg是层级数,40、40是训练样本的宽高;运行后会在xml文件夹生成新的文件如附图4所示,其中cascade.xml是实际检测中需要使用的训练好的分类器模型;s8:测试模型,通过调整参数反复提高精度,最终完成气泡裂纹的识别判定,测试模型所使用的编程语言为python,python代码如下:
[0058]
[0059][0060]
cv2.destroyallwindows(),最后根据识别效果再做之前步骤参数的调整优化。
[0061]
工作原理:如图1-4所示,在使用该x时,首先,通过在工业微型电脑raspberry pi(raspi/rpi)linux系统上使用python调用opencv模块,opencv实现的cascade(级联)分类器就是基于多个弱分类器对不同的特征进行依次处理(分类)来完成对目标的检测,每一级都比前一级复杂,简单的说有多个弱分类器串起来,然后提取每个平滑窗上的不同特征,把这些特征依次放进不同的弱分类器里判断,如果所有的弱分类器都判断正标签,则表示该平滑窗内检测到目标。这样做的好处是不但通过多个弱分类器来形成一个强的级联分类器,而且可以减少运算量,比如当一个平滑窗第一个特征没有通过第一个分类器,那么就没有必要继续运算下去,直接拒绝掉当前平滑窗,转而处理下一个平滑窗,目的就是为了快速抛弃没有目标的平滑窗,从而达到快速检测目标,每一个强分类器对负样本的判别准确度非常高,所以一旦发现检测到的目标位负样本,就不再继续调用下面的强分类器,减少了很多的检测时间。因为一幅图像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负样本的复杂检测,所以级联分类器的速度是非常快的;只有正样本才会送到下一个强分类器进行再次检验,这样就保证了最后输出的正样本的伪正的可能性非常低,以实现lcd屏玻璃制造过程中的瑕疵检测,这就是该x的特点。
[0062]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1