基于故障预测的服务功能链迁移方法
1.本发明属于网络功能虚拟化领域,涉及一种基于故障预测的服务功能链迁移方法,包括改进型的长短时记忆网络、改进型的麻雀搜索算法以及基于改进型麻雀搜索算法的服务功能链迁移方法。
背景技术:
2.文献“j.shen,j.wan,s.lim,l.yu.random-forest-based failure prediction for hard disk drives”针对硬件容易发生故障的问题,提出了随机森林的故障预测方法,即rfbp方法。文献“a.santo,a.galli,m.gravina,v.moscato,g.sperli.deep learning for hdd health assessment:an application based on lstm”针对硬件容易发生故障的问题,提出了基于长短时记忆网络的故障预测方法,即lstmp方法。文献3“j.xue,b.shen.anovel swarm intelligence optimization approach:sparrow search algorithm”提出了麻雀搜索算法(ssa),相比于其他群智能优化算法,麻雀优化算法具有更强的全局优化能力以及更快的搜索速度。但是到了迭代后期,随着种群数量减少,麻雀搜索算法也容易陷入局部最优。文献“s.zhou,h.xie,c.zhang,y.hua,w.zhang,q.chen,g.gu,x.sui.wavefront-shaping focusing based on a modified sparrow search algorithm”将交叉变异操作引入到了麻雀搜索算法中,即mssa,从而提高麻雀搜索算法的全局优化能力。文献“y.zhu,n.yousefi.optimal parameter identification of pemfc stacks using adaptive sparrow search algorithm”将自适应学习因子引入到了发现者、追随者、警戒者的位置更新函数中,即assa,从而提高麻雀搜索算法的全局优化能力。文献“d.zhao,g.sun,d.liao,s.xu,v.chang.mobile-aware service function chain migration in cloud-fog computing”针对服务功能链(service function chain,sfc)的迁移问题,提出了两阶段的sfc方法,即sfctsm方法。sfctsm方法首先迁移最小数量的虚拟网络功能(virtual network function,vnf),从而快速恢复服务。然后再迁移其他vnf,从而降低底层资源开销。文献“b.yi,x.wang,m.huang,k.li.design and implementation of network-aware vnf migration mechanism”针对服务功能链的迁移问题,提出了基于节点感知的vnf迁移方法,即navmm。navmm方法优先迁移具有最低迁移开销的vnf,一直重复这个过程,直到没有过载节点存在。但目前仍存在以下问题:
3.(1)针对硬件故障,为了更好的对相应的服务进行迁移和保护,故障预测方法的性能仍需进一步提高。
4.(2)麻雀算法在迭代后期容易陷入局部最优,为了更好地将麻雀搜索算法应用到实际问题中,麻雀算法的全局优化能力仍需进一步提高。
5.(3)针对即将发生硬件故障的服务器节点,部署在这个服务器节点上的所有vnf都需要迁移。这些vnf可能属于不同的sfcs,这将会使sfc迁移问题更加复杂。为了更加合理地使用底层资源以及提高相对应sfcs的迁移性能,这些vnf的迁移节点需要同时考虑。现有的sfc迁移方法一次只考虑一个vnf的迁移节点,针对硬件故障,现有的迁移方法会降低迁移
成功率和资源利用率。
技术实现要素:
6.要解决的技术问题
7.为了有效地预测硬件故障同时提前迁移服务功能链,本发明提供了一种基于故障预测的服务功能链迁移方法。
8.技术方案
9.一种基于故障预测的服务功能链迁移方法,其特征在于步骤如下:
10.步骤1:采用lstm神经网络来预测硬件故障,采用sapso算法来优化每层lstm的神经元数量以及时间窗长度,即pmilsm方法;根据预测结果判断服务器节点上的vnf是否需要迁移,即如果服务节点将要发生故障,该服务器节点所承载的所有vnf都需要被迁移;
11.步骤2:根据cpu资源约束、存储资源约束和承载能力约束获得候选迁移服务器节点集合;采用改进型的麻雀搜索算法同时为待迁移vnf在候选迁移服务器节点集合中选择最优的迁移服务器节点。
12.所述步骤1中pmilsm方法具体如下:
13.输入:初始化迭代次数ni和学习因子α1、α2,初始化时间窗长度以及每层lstm神经元数量作为粒子,smart属性值
14.输出:故障预测结果
15.(1)训练lstm模型,计算初始适应度值;
16.(2)使用sapso算法更新粒子的全局最优位置;
17.(3)获得最优的时间窗长度以及每层lstm神经元数量;
18.(4)使用步骤(3)获得的参数更新lstm模型;
19.(5)使用训练数据训练lstm模型以及门限值;
20.(6)输入samrt属性值,通过训练后的lstm模型预测硬件驱动故障。
21.所述步骤2中改进型的麻雀搜索算法:
22.步骤21:初始化参数,将即将故障服务器节点承载的vnf数量值设为搜索空间的维度;
23.步骤22:使用生产者、追随者和警戒者的位置更新函数来更新生产者、追随者和警戒者的位置,计算适应度值;
24.步骤23:判断是否满足迭代停止条件,如果不满足,则继续迭代;如果满足,则将最优位置输出,即为这些vnf的迁移服务器节点。
25.一种计算机系统,其特征在于包括:一个或多个处理器,计算机可读存储介质,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述的方法。
26.一种计算机可读存储介质,其特征在于存储有计算机可执行指令,所述指令在被执行时用于实现上述的方法
27.有益效果
28.本发明提供的一种基于故障预测的服务功能链迁移方法,首先采用长短时记忆网络(long short-term memory,lstm)对硬件故障进行预测,同时采用模拟退火粒子群算法
优化每层lstm的神经元数量和时间窗长度,提出了基于改进型lstm的故障预测方法,即pmilstm方法。其次,将混沌、反向学习、动态权重因子以及变异操作引入到麻雀搜索算法(sparrow search algorithm,ssa)中,提出了改进型的麻雀搜索算法,即issa。最后,将改进型的麻雀搜索算法应用sfc迁移方法中,提出了基于issa的服务功能链迁移方法,即mmissa方法。mmissa方法同时考虑了故障节点上所有vnf的迁移服务器节点,适应值函数同时考虑了迁移开销进而迁移时间。因此,mmissa方法有效地提高了迁移成功率,降低了迁移开销和迁移时间。
29.1、首先用模拟退火粒子群算法优化lstm每层的神经元数目以及时间窗长度,利用改进型的lstm网络预测硬件故障,提高了预测的准确率。
30.2、其次,将混沌、反向学习、动态权重因子以及变异操作引入到ssa中,提高了ssa的全局优化能力。
31.3、最后将issa应用到sfc迁移中,同时考虑了故障节点部署的所有vnf的迁移服务器节点。有效提高了迁移成功率,降低了迁移开销与迁移时间。
附图说明
32.附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
33.图1是本发明所给出的sfc迁移示意图。
34.图2是本发明所给出的lstm单元结构图。
35.图3是本发明所给出的sapso算法流程图。
36.图4是本发明所给出的麻雀搜索算法流程图。
37.图5是本发明方法中改进型麻雀搜索算法流程图。
38.图6是本发明方法中故障检测率对比结果图。
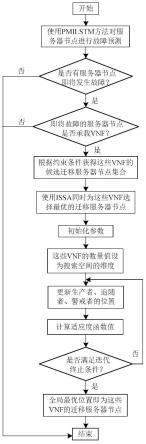
39.图7是本发明方法中故障误报率对比结果图。
40.图8是本发明方法中收敛对比结果图:(a)f1测试函数;(b)f2测试函数;(c)f3测试函数。
41.图9是本发明方法中迁移成功率对比结果图:(a)λ
p
=0.05;(b)λ
p
=0.1;(c)λ
p
=0.15。
42.图10是本发明方法中平均迁移开销对比结果图:(a)λ
p
=0.05;(b)λ
p
=0.1;(c)λ
p
=0.15。
43.图11是本发明方法中平均迁移时间对比结果图;
44.图12是本发明方法流程图。
具体实施方式
45.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
46.本发明提供一种基于issa的服务功能链迁移方法(即mmissa方法),包括下述几个
部分:
47.第一部分:建立sfc迁移的网络模型。
48.第二部分:基于改进型lstm的故障预测方法设计(即pmilstm)。
49.第三部分:对麻雀搜索算法进行描述。
50.第四部分:改进型的麻雀搜索算法设计(即issa)。
51.第五部分:基于issa的服务功能链迁移方法设计(即mmissa)。
52.第六部分:验证所提方法的有效性。
53.以下实施例参照图1~11。具体实施过程为:
54.1、建立sfc迁移的网络模型
55.物理网络:本发明选择多个基础设施提供商提供硬件服务作为应用场景,通用服务器节点承载能力可能存在差异。物理网络可以用一个赋权无向图gs=(vs,es)表示,其中vs=v
s,s
∪v
s,f
,v
s,s
={v
s,i
|i=1,2,...,|v
s,s
|}。
56.sfc请求:一个sfc请求可以用一个赋权无向gg={ng,lg,sg,dg},其中ng={fj|j=1,2,...,|ng|}。业务流从一个交换机节点流入,经过给定顺序的虚拟网络功能后,从另一个交换机节点流出。
57.sfc部署:当sfc请求到达时,服务提供者按照既定顺序实例化服务功能链的各个虚拟网络功能。如果服务器节点v
s,i
可以承载vnffj,x(v
s,i
,fj)=1,否则,x(v
s,i
,fj)=0。
58.sfc迁移:当服务器节点v
s,i
发生故障时,其承载的所有vnf都需要迁移。迁移过程中,对于每个vnf,迁移服务器节点要满足它的cpu资源和存储资源需求。同时底层链路也要满足相应虚拟链路的带宽资源需求。
59.如图1所示。sfc1中的vnfs 1、2、3分别部署在服务器节点2、3、7上。黑色虚线表示sfc1的真实路由。假设服务器节点3发生故障,sfc1的vnf2需要迁移到其他服务器节点上。vnf2被迁移到了服务器节点8,服务节点8的可用cpu和存储资源满足vnf2的资源需求。灰色虚线表示sfc1的重构路由。底层链路e
2,8
和e
8,7
的可用带宽满足虚拟链路l
1,2
和l
2,3
的带宽需求。本发明常用符号及其含义如表1所示。
60.表1常用符号及其含义
61.[0062][0063]
2、基于改进型lstm的故障预测方法设计
[0064]
lstm神经网路删除/增加信息通过遗忘门、输入门和输出门。它的重复模块有四个网络层,而标准的循环神经网络只有一个网络层。lstm单元结构如图2所示,第一步是决定从单元状态m
t-1
中丢弃或保留哪些信息,这是通过遗忘门来完成的,如公式(1)所示,遗忘门的输出是r
t
。第二步是决定在单元状态中存储哪些信息,这是通过输入门来完成的,如公式(2)所示,输入门的输出是i
t
。候选单元信息按照公式(3)进行更新。第三步是通过单元状态m
t-1
和候选单元信息来更新单元状态m
t
,如公式(4)所示。下一步是决定输出哪些状态特征,这是通过输出门来完成的,如公式(5)所示,输出门的输出是o
t
。最后的输出结果由输出信息o
t
和单元状态m
t
决定,如公式(6)所示。
[0065]
符号w
rk
、w
ik
、w
mk
和w
ok
表示前一个输出k
t-1
的加权因子。符号w
ry
、w
iy
、w
my
和w
oy
表示输入y
t
的加权因子。符号br、bi、bo和bm表示遗忘门、输入门、输出门以及候选单元的偏差。符号σ和tanh表示激活函数,符号*表示点乘。
[0066]rt
=σ(w
rkkt-1
+w
ryyt-br)
ꢀꢀ
(1)
[0067]it
=σ(w
ikkt-1
+w
iyyt
+bi)
ꢀꢀ
(2)
[0068][0069][0070]ot
=σ(w
okkt-1
+w
oyyt
+bo)
ꢀꢀ
(5)
[0071]kt
=o
t
*tanh(m
t
)
ꢀꢀ
(6)
[0072]
硬件通常是逐渐恶化的,而不是突然恶化。lstm神经网络在记忆长期信息方面有更优的性能。因此,本发明采用lstm神经网络来预测硬件故障。对于lstm神经网络,时间窗长度和每层lstm的神经元数量是不固定的。时间窗长度和每层lstm神经元数量对预测准确性有很大的影响。模拟退火粒子群(sapso)算法具有高精度、实现简单以及分析时间短的优势。因此,本发明采用sapso算法来优化每层lstm的神经元数量以及时间窗长度。sapso算法
的流程图如图3所示,对于优化问题,一个粒子代表一个解。每次迭代中,粒子的速度矢量和位置矢量分别按照公式(7)和(8)进行更新。为了跳出局部最优解,sapso算法根据公式(9)进行模拟退火。根据公式(10)计算接受较差解的概率。最后,根据metropolis准则更新所有粒子的全局最佳位置。
[0073]
vei(j+1)=ωvei(j)+α1β1(pbest(j)-xi(j))+α2β2(gbest(j)-xi(j))
ꢀꢀ
(7)
[0074]
xi(j+1)=xi(j)+vei(j+1)
ꢀꢀ
(8)
[0075]
其中符号vei(j)和xi(j)分别表示粒子i在第j次迭代中的位置矢量和速度矢量。符号α1和α2分别表示局部学习因子和全局学习因子。符号β1和β2是0到1之间的随机数。在每次迭代中,符号pbest表示粒子的局部最优位置,符号gbest表示所有粒子的全局最优位置。符号ω表示权重因子。
[0076][0077][0078]
其中符号t(j)表示第j次迭代时的温度,符号ε表示降温系数。符号f
s,g
(j)表示在第j次迭代时,全局最优位置的适应度值,符号f
s,p
(j)表示第j次迭代后,最优位置的适应度值。
[0079]
为了提高预测硬件故障的准确性,本发明采用sapso算法来优化每层lstm的神经元数量以及时间窗长度,提出了基于改进型lstm的故障预测方法,即pmilstm方法。为了分析方便,本发明主要考虑硬件驱动故障。smart技术已经被验证,在硬件驱动故障预测中具有很好的性能。因此,本发明使用smart属性预测硬件驱动故障。pmilsm方法的主要步骤如算法1所示,每层lstm神经元的数量以及时间窗长度作为搜索空间的粒子。预测的smart属性值和真实的smart属性值的均方误差作为适应度值。
[0080][0081]
3、麻雀搜索算法
[0082]
麻雀搜索算法(sparrow search algorithm,ssa)将种群分为生产者、追随者和警戒者。生产者具有较高的适应度,主要为麻雀提供觅食区域和方向。追随者在生产者提供的区域内觅食,一些追随者甚至监视生产者来竞争食物。警戒者担负着发现捕食者和早期预警的责任,一旦警戒者发现捕食者,它们会向其他麻雀发出警告。
[0083]
麻雀算法的流程图如图4所示,初始化麻雀的位置,用集合si=(s
i,1
,s
i,2
,...,si,d
)表示,麻雀si的适应度值表示为f(si)。符号nn、np、ns和nc分别表示种群、生产者、追随者和警戒者的数量。符号q
max
表示最大迭代次数,符号d表示搜索空间。搜索空间的上限和下限分别表示为ub={ubj|j=1,2,...,d}和lb={lbj|j=1,2,...,d}。生产者的位置更新函数如公式(11)所示。
[0084][0085]
其中符号at和st分别表示报警值和安全阈值。符号q表示当前迭代次数,符号μ是一个随机数。符号q是一个服从正态分布的随机数。符号i表示一个1
×
d的矩阵,其中每个元素都为1。当at<st,它表示生产者没有收到危险警告,将会扩大觅食范围;否则,生产者将会根据正态分布移动到更安全的区域觅食。
[0086]
追随者的位置更新函数如公式(12)所示。
[0087][0088]
其中符号g
worst
和p
best
分别表示麻雀的最差位置和生产者当前的最佳位置。符号a
+
表示一个1
×
d的矩阵,其中每个元素为1或-1,而且a+=a
t
·
(a
·at
)-1
。当i>nn/2,追随者i将飞到其它区域觅食;否则,追随者i将在生产者的最佳位置附近觅食。
[0089]
警戒者的位置更新函数如公式(13)所示。
[0090][0091]
其中符号g
best
表示麻雀的当前最佳位置,符号γ是一个服从正态分布的随机数。符号λ是一个表示步长控制因子的随机数,符号是一个趋近于0的常数。
[0092]
4、改进型的麻雀搜索算法
[0093]
麻雀搜索算法在迭代后期,由于种群数量减少,容易陷入局部最优。因此,本发明提出了改进型的麻雀搜索算法,即issa算法。为了提高ssa的全局优化能力,issa将混沌、反向学习、动态加权因子和变异操作引入到了ssa中。issa的算法流程图如图5所示。为了提高迭代开始时的全局搜索能力,issa采用混沌映射中的logistic映射初始化种群的位置。logistic映射如公式(14)所示。
[0094]
s(d+1)=τs(d)(1-s(d))s(d)∈(0,1),τ∈(0,4]
ꢀꢀ
(14)
[0095]
其中符号τ表示控制参数
[0096]
初始化种群位置如下所示:
[0097]
利用公式(15)将麻雀的初始位置s
ij
(i=1,2,...,nn;j=1,2,...,d)归一化为s
ij
(0)(i=1,2,...,nn;j=1,2,...,d)来满足混沌条件。
[0098]sij
(0)=(s
ij-lbj)/(ub
j-lbj)
ꢀꢀ
(15)
[0099]
利用logistic映射得到s
ij
(d+1),如公式(16)所示。
[0100]sij
(d+1)=τs
ij
(d)(1-s
ij
(d))
ꢀꢀ
(16)
[0101]
根据公式(17),将s
ij
(d+1)从原来的域[0,1]转化为新的s
ij
(i=1,2,...,nn;j=1,2,...,d)。
[0102]sij
=lbj+s
ij
(d+1)(ub
j-lbj)
ꢀꢀ
(17)
[0103]
为了进一步提高初始种群的全局搜索能力,issa使用反向学习获得新的种群,如公式(28)所示。根据适应度值对两个种群的麻雀进行排序,选择nn个适应度值高的麻雀作为初始化种群。
[0104]
s'
i,j
=ubj+lb
j-s
i,j
ꢀꢀ
(18)
[0105]
在每个迭代中,为了避免陷入局部最优,issa使用反向学习优化当前最佳位置和全局最佳位置。issa通过公式(19)获得当前生产者最佳位置和麻雀全局最佳位置的反向位置,然后通过比较适应度值,得到新的生产者当前最佳位置和麻雀全局最佳位置,如公式(20)和(21)所示。
[0106][0107][0108][0109]
生产者从迭代开始就向全局最优位置移动,导致搜索范围不足,容易陷入局部最优。因此,issa将上一次麻雀全局最优位置引入到了生产者的位置更新函数中。这样,生产者的位置不仅受上一次迭代中生产者位置的影响,而且受上一次全局最优位置的影响,可以避免陷入局部最优。除此之外,issa将一个动态加权因子ωs引入到了生产者的位置更新函数中。动态加权因子在迭代开始时值较大,可以进行更好的全局搜索,在迭代后期加权因子自适应减小,以便更好地进行局部搜索,提高收敛速度。加权因子的计算方式如公式(22)所示。
[0110][0111]
改进的生产者位置更新函数如公式(23)所示。
[0112][0113]
其中,符号表示上一代麻雀全局最优位置。
[0114]
在迭代的后期,由于种群的减少,ssa容易陷入局部最优。因此,issa引入了一种变
异操作来增加种群的多样性。为了不影响算法的收敛性,每次迭代只变异一个个体,如公式(24)所示。
[0115]
sa=lb+(ub-lb)*rand(1,d)
ꢀꢀ
(24)
[0116]
其中符sa表示在每次迭代中的一个随机个体,符号*表示点乘。
[0117]
5、基于issa的服务功能链迁移方法设计
[0118]
为了更好地解决硬件故障造成的服务功能链迁移问题。本发明提出了一种基础issa的服务功能链迁移方法,即mmissa方法。mmissa方法根据pmilstm方法的预测结果对sfc进行迁移。如果预测结果显示某个服务器节点将会发生故障,则部署在该服务器节点上的所有vnf都需要迁移。mmissa方法采用改进型的麻雀搜索算法迁移这些vnf和相应的虚拟链路。搜索空间的维度d与即将故障服务器节点承载的vnf数量相同。因此,mmissa方法可以同时为部署在即将故障服务器节点上的所有vnf寻找迁移服务器节点。为了降低平均迁移开销与平均迁移时间,适应度函数同时考虑了平均迁移开销和平均迁移时间,如公式(25)所示。
[0119][0120]
其中符号c
av
和分别表示平均迁移开销和平均迁移时间,符号qc和q
t
分别表示平均迁移开销和平均迁移时间的影响因子。
[0121]
流程图如图12所示,首先使用pmilstm对每个服务器节点进行故障预测。如果预测结果显示有服务器节点即将发生故障,判断此服务器节点是否承载了vnf。如果承载了vnf,则需要迁移这些vnf。根据cpu资源约束、存储资源约束和承载能力约束获得候选迁移服务器节点集合。使用issa算法同时为这些vnf在候选迁移服务器节点集合中选择最优的迁移服务器节点。初始化参数,将此即将故障服务器节点承载的vnf数量值设为搜索空间的维度。使用生产者、追随者和警戒者的位置更新函数来更新生产者、追随者和警戒者的位置,计算适应度值。判断是否满足迭代停止条件,如果不满足,则继续迭代。如果满足,则将最优位置输出,即为这些vnf的迁移服务器节点。
[0122]
mmissa方法的主要步骤如算法2所示。mmissa方法首先根据pmilstm方法的预测结果判断服务器节点上的vnf是否需要迁移。如果服务节点将要发生故障,该服务器节点所承载的所有vnf都需要被迁移。对于每一个需要被迁移的vnf,mmissa方法根据cpu资源约束、存储资源约束和承载能力约束选择候选服务器节点集合,将这些集合作为麻雀的搜索空间(line3
–
10)。符号v
m,i
表示vnffi的候选迁移服务器节点集合。mmissa方法同时为部署在即将故障服务器节点上的所有vnf寻找迁移服务器节点,使相应sfc的整体迁移性能更优。使用logistic映射和反向学习提高了迭代开始时的全局搜索能力(line13
–
14)。生产者、追随者、警戒者的位置分别按照公式(23)、(12)和(13)进行更新(line17
–
18)。采用反向学习优化生产者的当前最佳位置和麻雀的全局最佳位置(line20)。每次迭代随机对一个个体进行变异操作(line21)。如果终止条件满足,则迭代停止。输出全局最优位置,该位置即为相应sfc的迁移结果。
[0123][0124][0125]
6、性能评估与分析
[0126]
本发明的实验仿真分为三部分。第一部分对pmilstm方法的性能进行验证,第二部分对issa算法的性能进行验证,第三部分对mmissa方法的性能进行验证。本发明采用matlab进行实验仿真,每个仿真实验做100次,取平均结果作为最终结果。
[0127]
6.1故障预测性能验证与讨论
[0128]
本发明主要考虑硬件驱动故障,使用数据中心的真实数据集进行实验。这些数据已经被用于文献“c.xu,g.wang,x.liu,d.guo,t.liu.health status assessment and failure prediction for hard drives with recurrent neural networks”和“b.zhu,g.wang,x.liu,d.hu.proactive drive failure prediction for large scale storage systems”。70%的数据作为训练数,30%的数据作为测试数据。如表2所示,数据集从smart中的23个属性中保留了10属性。每个样本有12个特征,包括10个属性以及reallocated sectors count和current pending sector count属性的原始数据。三种预测方法的描述如表3所示。
[0129]
表2从smart中选择的属性
[0130][0131]
表3三种预测方法的描述
[0132][0133][0134]
图6和图7显示了三种方法的故障检测率和故障误报率。pmilstm方法有最高的故障检测率和最低的故障误报率。硬件驱动通常是逐渐恶化,而不是突然恶化lstm神经网络在记忆长期信息方面有更优的性能。因此,pmilstm方法的性能优于rfbp方法。pmilstm方法采用sapso算法优化了每层lstm神经元数量以及时间窗长度,因此,它的性能优于lstmp方法。
[0135]
6.2优化性能验证与讨论
[0136]
通过三种测试函数进行仿真实验验证issa算法的优越性。三种测试函数的描述如表4所示。三种有优化算法的描述如表5所示。最大的迭代次设为500,种群数量设为50,安全阈值设为0.8。
[0137]
表4三种测试函数
[0138][0139]
表5三种优化算法的描述
[0140][0141]
图8显示了三种优化算法的收敛结果。issa算法有最强的优化能力和最快的收敛速度。issa算法采用logistic映射和反向学习初始化种群,因此,初始阶段的全局优化能力得到提高。在每次迭代中,为避免陷入局部最优,issa算法采用反向学习优化生产者的当前最佳位置和麻雀的全局最佳位置。每次迭代中随机对一个个体进行变异操作,从而增加种
群的多样性。除此之外,将动态加权因子和上一代全局最优位置引入到生产者的位置更新函数中,可以有效地避免陷入局部最优。因此,issa算法的性能优于mssa算法和assa算法。
[0142]
6.3迁移性能验证与讨论
[0143]
底层网络具有服务器节点200个,服务器节点的cpu和存储资源服从[30
–
70]的均匀分布,服务器节点的smart属性和实验一的数据相同。底层链路的带宽资源服从[30
–
50]的均匀分布。sfc中vnf的数目服从[5
–
8]的随机分布。vnf的cpu和存储资源需求服从[15
–
30]的均匀分布。虚拟链路的带宽需求服从[10
–
20]的均匀分布。sfc请求的到达率服从泊松分布。三种迁移方法的描述如表6所示。
[0144]
表6三种迁移方法的描述
[0145][0146]
图9显示了不同sfc请求到达率下,三种迁移方法的迁移成功率。从图10中可以看出,mmissa方法具有最高的迁移成功率。mmissa方法采用issa算法迁移vnfs。issa算法具有更高的全局优化能力,因此,mmissa方法具有更高的全局优化能力。除此之外,mmissa方法同时为即将故障服务器节点上的所有vnf寻找迁移服务器节点,这样可以有效地提高相应sfc的整体迁移性能。因此,mmissa方法在三种方法中具有最高的迁移成功率。
[0147]
图10显示了不同sfc请求到达率下,三种迁移方法的平均迁移开销。从图10中可以看出,mmissa方法具有最低的平均迁移开销。mmissa方法采用issa算法迁移vnfs,同时为即将故障服务器节点承载的所有vnf寻找迁移服务器节点。除此之外,适应度函数包含了平均迁移开销。因此,mmissa方法在三种方法中具有最低的平均迁移开销。
[0148]
图11显示了不同sfc请求到达率下,三种迁移方法的平均迁移时间。从图11中可以看出,mmissa方法具有最低的平均迁移时间。mmissa方法同时为即将故障服务器节点承载的所有vnf寻找迁移服务器节点。除此之外,适应度函数包含了平均迁移时间。因此,mmissa方法在三种方法中具有最低的平均迁移时间。
[0149]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1