一种奶牛耳标识别系统
1.本发明涉及畜牧业技术领域,特别是涉及一种奶牛耳标识别系统。
背景技术:
2.在奶牛养殖的过程中,需要实时掌握每头奶牛的健康状况及位置信息,以便于在奶牛生病或离开养殖区域时快速找到奶牛或对其进一步检查治疗,从而保证奶牛的健康状况,避免发生奶牛群体疾病,同时防止奶牛的丢失。
3.人工对单个奶牛的监测需要时间和劳动力成本,而且在大规模的奶牛养殖场中也很难处理。通常在大规模奶牛养殖中每个奶牛都佩戴一个黄色耳标,每个耳标上都有该奶牛特定的id编号。
4.现有的奶牛个体识别方法有基于射频技术的个体识别,但在这种方法中,奶牛必须佩戴特定的射频发射器才能进行识别定位,识别成本高且识别准确率较低。
技术实现要素:
5.为解决现有奶牛耳标识别精确度低的问题,本发明提供一种奶牛耳标识别系统和控制系统。
6.本发明采用如下技术方案实现:一种奶牛耳标识别系统,其包括如下步骤:
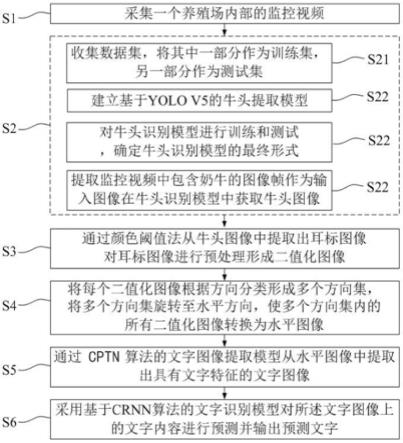
7.s1:采集一个养殖场内部的监控视频。
8.s2:提取监控视频中包含奶牛的图像帧,并将提取出的各个图像帧作为输入图像。通过基于yolo v5的牛头提取模型从输入图像中提取包含牛头特征的牛头图像。提取牛头图像的方法包括如下步骤:
9.s21:收集数据集。数据集包含多张奶牛的牛头原形图像。牛头原形图像通过对养殖场内多个奶牛以不同背景、不同角度或不同距离拍照而获取。其中一部分牛头原形图像作为测试集,另一部分牛头原形图像作为训练集。
10.s22:建立基于yolo v5的初始牛头提取模型。yolo v5模型包括输入层、主干网络、预测层和损失函数。输入层包括数据增强、自适应锚框计算和自适应图像缩放。数据增强用于对训练集中的牛头原形图像进行拼接,丰富训练集。自适应锚框计算用于输出预测框。自适应图像缩放用于将输入的图像缩放到一个设定的规格。主干网络用于输出特征图。预测层用于根据预测框输出预测图像。损失函数用于消除多余的预测框,找到最佳的预测图像。
11.s23:通过训练集对初始牛头识别模型进行训练获取牛头提取模型。通过测试集对牛头提取模型进行测试,保留通过测试的牛头提取模型。
12.s24:将输入图像输入牛头识别模型中获取牛头图像。
13.s3:通过颜色阈值法从每个牛头图像中提取出耳标图像。对耳标图像进行预处理形成二值化图像。
14.s4:检测每个二值化图像的方向并将每个二值化图像根据方向分类形成多个方向集。根据方向类别将所有二值化图像旋转至水平方向作为水平图像。
15.s5:通过基于cptn算法的文字图像提取模型从水平图像中检测并提取出具有文字特征的文字图像。
16.s6:采用基于crnn算法的文字识别模型对文字图像上的文字内容进行预测并输出预测文字。
17.本发明通过采集奶牛的视频并在视频中选取奶牛的图像,根据奶牛牛头的特征利用牛头识别模型提取奶牛图像中的牛头图像,再根据耳标颜色与图像背景颜色的差异,通过颜色阈值法提取出耳标图像并对耳标图像预处理使耳标图像转化为二值化图像,随后提取二值化图像中的文字图像,最后采用crnn模型识别文字图像的内容并输出预测文字。本发明通过对奶牛群体采集视频并逐级拆分获取文字区域,有效地降低了采集耳标图像及文字图像的成本,尽可能地保持了耳标及其文字的特征,提高识别耳标文字的效率。
18.作为上述方案的进一步改进,在s1中,采集视频信息的方法包括如下步骤:
19.s11:在养殖场内选取供奶牛活动的活动区域。
20.s12:在活动区域内安装多个监控摄像头。根据每个监控摄像头的监控覆盖范围将活动区域划分为多个分区域。在每个分区域内安装至少一个用于实时监控分区域的监控摄像头。
21.s13:通过监控摄像头采集每个分区域的监控视频并将监控视频传输到牛头图像提取模型中。
22.作为上述方案的进一步改进,在s3中,颜色阈值法包括如下步骤:
23.s31:使用颜色空间转换工具将牛头图像的颜色空间变换到hsv颜色空间获得hsv图像。
24.s32:设置奶牛耳标的hsv颜色阈值范围,根据颜色阈值范围从牛头图像中分割出耳标图像。
25.作为上述方案的进一步改进,在s3中,预处理的方法包括:滤波、直方图均衡化和二值化。滤波处理用于对耳标图像的噪声进行抑制。直方图均衡化用于调整耳标图像的对比度。二值化用于将耳标图像转化为二值化图像。
26.作为上述方案的进一步改进,在s4中,方向集的分类方法包括:
27.s41:构建基于vggnet-16神经网络的分类模型。
28.s42:根据分类模型识别二值化图像中耳标方向与水平方向的夹角范围。
29.s43:根据夹角范围对二值化图像进行分类形成多个方向集。多个方向集包括:0
°
集、90
°
集、180
°
集和270
°
集。0
°
集、90
°
集、180
°
集和270
°
集分别对应的夹角范围为[θ,θ+90
°
)、[θ+90
°
,θ+180
°
)、[θ+180
°
,θ+270
°
)和[θ+270
°
,θ+360
°
)。其中θ∈[-45
°
,0
°
]。
[0030]
作为上述方案的进一步改进,在s41中,vggnet-16神经网络包括13个卷积层、5个池化层和3个全连层。每个卷积层均为3
×
3的小型卷积滤波器。13个卷积层按照两层、两层、三层、三层和三层的顺序分为五集。每集内连接一个池化层。每个池化层均为2
×
2的最大池化核。全连接层用于整合卷积层和池化层中具有类别区分性的局部信息。
[0031]
作为上述方案的进一步改进,在s43中,将0
°
集定义为水平方向集。旋转其余的方向集直至全部的方向集转换为水平方向集。
[0032]
作为上述方案的进一步改进,在s5中,文字图像提取模型的建立方法包括如下步骤:
[0033]
s51:获取文本图像集。根据耳标所使用的编号文字选择相应的文本集。通过对文本集内的所有非重复文字进行单独拍照获取多个文字图像。多个文字图像共同构成文本图像集。其中一部分文本图像集作为训练集二。另一部分文本图像作为测试集二。
[0034]
s52:建立基于cptn算法的初始文字检测模型。
[0035]
s53:通过训练集二对初始文字图像提取模型进行训练获取文字图像提取模型。通过测试集二对文字图像提取模型进行测试。保留通过测试的文字图像提取模型。
[0036]
作为上述方案的进一步改进,在s6中,文字识别模型包括:
[0037]
cnn卷积层,其用于提取文字图像中具有文字特征的特征图像并对特征图像进行切片形成多个切片图像。
[0038]
rnn循环层,其用于对切片图像循环编码与解码。将切片图像输出为预测值。
[0039]
ctc转录层,其用于对rnn循环层获取的预测值排序并转换成预测文字。
[0040]
一种奶牛耳标识别系统,其应用上述的奶牛耳标识别方法实时监测养殖场内每头佩戴耳标的奶牛的位置信息,其包括:视频采集模块、视频传输模块、牛头图像提取模块、耳标图像提取模块、耳标图像分类模块、耳标图像旋转模块、文字图像提取模块和文字区域识别模块。
[0041]
视频采集模块包括多个监控摄像头,监控摄像头用于采集养殖场内的监控视频。
[0042]
牛头图像提取模块用于从监控视频中提取出包含奶牛的图像帧,并通过存储在其内部的基于yolo v5的牛头图像提取模型从图像帧中提取出具有牛头特征的牛头图像。
[0043]
视频传输模块用于将监控视频传输至牛头图像提取模块中。
[0044]
耳标图像提取模块用于将牛头图像的颜色空间转换到hsv颜色空间形成hsv图像,并根据耳标颜色的阈值范围从hsv图像中分割出耳标图像。耳标图像提取模块还用于通过预处理将耳标图像转换成二值化图像。
[0045]
耳标图像定向模块包括方向分类模块和图像旋转模块。方向分类模块用于通过存储在其内部的基于vggnet-16神经网络的分类模型识别二值化图像中耳标的方向,并将二值化图像按照耳标方向与水平方向的夹角范围分类形成多个方向集。图像旋转模块用于将多个方向集旋转至水平方向,使所有二值化图像转化为水平图像。
[0046]
文字图像提取模块用于通过存储在其内部的基于cptn算法的文字检测模型从水平图像中检测并提取出具有文字特征的文字图像。
[0047]
文字区域识别模块用于通过存储在其内部的基于crnn算法的文字识别模型识别文字图像并输出预测文字。
[0048]
相较于现有的奶牛耳标识别方法,本发明的一种奶牛耳标识别方法及识别系统具有如下有益效果:
[0049]
1.通过对奶牛群体采集视频并逐级拆分获取文字区域,有效地降低了采集耳标图像及文字图像的成本,尽可能地保持了耳标及其文字的特征,提高识别耳标文字的效率。
[0050]
2.通过对养殖场活动区域的划分,从多方向多角度采集奶牛的视频,避免因奶牛耳标被遮挡导致难以在视频中提取出耳标图像,从而提高耳标识别的精确度。
[0051]
3.yolo v5模型通过自我训练强化学习,对于大目标、中等目标和小目标均有较高的识别准确率,通过对牛头外形的整体特征及部分细节特征的多重预测,有效地提高识别的精度,避免重复识别。
[0052]
4.vggnet-16神经网络结构简洁,识别效率高,能快速处理大量的耳标图像,以便于耳标文字的识别。
[0053]
5.crnn模型对文字图像进行先提取特征再切片后循环识别,有效地提高文字识别的精确度。
附图说明
[0054]
图1为本发明实施例1的奶牛耳标识别方法的流程图。
[0055]
图2为本发明实施例1的牛头图像采集图。
[0056]
图3为本发明实施例1的文字图像采集图。
[0057]
图4为本发明实施例1的crnn模型的结构示意图。
[0058]
图5为本发明实施例1的奶牛耳标的主视剖面结构示意图。
[0059]
图6为图6中奶牛耳标的俯视剖面结构示意图。
具体实施方式
[0060]
为了使本发明的目的、技术方案及优点更加清楚明白,如下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0061]
实施例1
[0062]
请参阅图1,其为本实施例的奶牛耳标识别系统的流程图。奶牛耳标识别方法包括如下步骤,即s1-s6。
[0063]
s1:采集一个养殖场内部的监控视频。在养殖场中,通过为每头奶牛佩戴具有特定编号的耳标来实时掌握奶牛的健康状况和位置信息。每头奶牛可以佩戴一只或两只耳标,耳标固定在奶牛的耳朵上。由于耳标的体积小,难以直接获取耳标的图像或视频,因此需要先采集奶牛的监控视频,再从中提取耳标的信息。
[0064]
采集奶牛的监控视频可以通过以下步骤实现:
[0065]
s11:在养殖场内选取供奶牛活动的活动区域。奶牛在养殖过程中,其所处的位置并非固定不变的,如在喂养奶牛时,可以在某一固定区域内同时喂养多头奶牛,而在奶牛走动或休息时,可以在相应的走动区域或休息区域内进行。此外,养殖场还包括奶牛不可进入的区域,如仓库、养殖人员活动区等,因此需要将奶牛的活动区域分隔出来。
[0066]
s12:在活动区域内安装多个监控摄像头。根据每个监控摄像头的监控覆盖范围将活动区域划分为多个分区域。在每个分区域内安装至少一个用于实时监控分区域的监控摄像头。奶牛的活动区域面积较大,若仅通过一个监控摄像头进行监控,则难以将奶牛所佩戴的耳标识别出来。进行区域划分可以在每个较小范围内采集奶牛的监控视频,这样能提高耳标识别的准确度。此外,每个分区域的监控摄像头的数量可以根据奶牛在每个分区域可能面向的方向来设定,从而避免因奶牛所处方向不同而导致难以获取清晰的监控视频。
[0067]
s13:通过监控摄像头采集每个分区域的监控视频并将监控视频传输到牛头图像提取模型中。每个监控摄像头都有一个固定的位置,若奶牛的耳标可以从一个监控摄像头所采集的监控视频中提取出来,则耳标对应的奶牛位于相应的监控摄像头所处的分区域内。
[0068]
请结合图2,其为本实施例的牛头图像采集图。
[0069]
s2:提取监控视频中包含奶牛的图像帧,并将提取出的各个图像帧作为输入图像。通过基于yolo v5的牛头提取模型从输入图像中提取包含牛头特征的牛头图像。位于任一分区域内的奶牛数量可能是零个或多个,在具有一个以上的奶牛的视频中,通过选取视频中的一个片段,并在这个片段内的所有帧上的图像任意选取包含奶牛的图像帧作为输入图像,从而通过牛头提取模型牛头图像。获取方法包括如下步骤:
[0070]
s21:收集数据集。通过预先对奶牛拍照的方式收集多张奶牛的牛头原形图像作为数据集,这些牛头原形图像可以通过在养殖场的不同分区域内以不同角度、不同背景、不同距离拍照获取。将其中一部分牛头原形图像作为测试集,另一部分牛头原形图像作为训练集。在本实施例中,选取牛头原形图像2652张,其中2248张牛头原形图像作为训练集,余下的404张牛头原形图像作为测试集。
[0071]
s22:建立基于yolo v5的初始牛头提取模型。yolo v5模型包括输入层、主干网络、预测层和损失函数。
[0072]
输入层包括数据增强、自适应锚框计算和自适应图像缩放。数据增强用于对训练集中的牛头原形图像进行拼接,丰富训练集。数据增强的方法包括:使用随机缩放、随机裁剪、随机排布的方式进行拼接,丰富检测数据集。在本实施例中,每次同时对任意四张训练集中的牛头原形图像进行随机裁剪拼接形成集合图像,集合图像包含了四张牛头原形图像的所有特征。通过随机缩放增加了很多小目标,让yolo v5模型的鲁棒性更好。自适应图像缩放用于将输入的图像缩放到一个设定的规格。自适应锚框计算用于输出预测框。yolo v5模型具有一个初始锚框,在yolo v5模型的训练过程中,在初始锚框的基础上输出预测框,在牛头原形图像中设置框选牛头的真实框,进而将预测框与真实框进行比对,计算两者差距,再反向更新,迭代网络参数,形成牛头识别模型。自适应图像缩放用于将输入的图像缩放到一个设定的规格。自适应图像缩放包括如下步骤:计算缩放比例。在牛头识别模型中设置一个固定的图像规格,以原集合图像的长和宽分别除以图像规格的长和宽获得两个缩放比例,选取其中较小的缩放比例作为实际缩放比例。计算缩放后的尺寸,以原集合图像的长和宽分别乘以实际缩放比例获得实际缩放图像的长和宽。计算黑边填充数值,将较大的缩放比例乘以其对应的原集合图像的长或宽再减去实际缩放图像中相应的长或宽,得到需要填充的高度,再采用取余数的方式,得到像素数,再除以二,即得到实际缩放图像长或宽两端需要填充的数值。
[0073]
主干网络用于输出特征图。在本实施例中,主干网络通过切片操作,同时将四张实际缩放图像切分为与大小相同的十二张切片图像。再经过一次牛头识别模型的32个卷积核的卷积操作,最终变成三十二张特征图。牛头识别模型还具有5个csp模块,每个csp模块进行下取样,即将任一特征图逐级等比例选取其1/4的图像。经过5次csp模块后得到其长和宽均为特征图1/32大小的最终特征图。
[0074]
预测层用于根据预测框输出预测图像。在本实施例中,牛头识别模型采用fpn结构和pan结构对最终特征图进行融合,得到预测图像。fpn结构是通过上采样的方式进行传递融合,pan结构则通过下采样的方式进行传递融合,最终得到预测图像。
[0075]
损失函数用于消除多余的预测框,找到最佳的预测图像。在本实施例中,牛头识别模型采用giou_loss做损失函数。giou_loss充分考虑预测框与真实框的差异面积,解决预
测框与真实框边界不重合时的问题。由于牛头识别模型在giou_loss下具有更丰富的识别能力,因此在输出预测图像时,往往会有重叠或多余的候选框,如果将这些候选框全部输出为预测图像,则会增加牛头识别模型的计算量,降低识别效率。采用加权nms的方式做测试推理,消除多余的候选框,找到最佳的物体检测位置。
[0076]
s23:通过训练集对初始牛头识别模型进行训练获取牛头提取模型。通过测试集对牛头提取模型进行测试,保留通过测试的牛头提取模型。牛头提取模型在不断训练的过程中进行自我迭代,对牛头特征的识别准确度逐步提升。在对牛头提取模型的测试准确度达到一个预定的阈值时,即视为通过测试,便可以保留通过测试的牛头提取模型。
[0077]
s24:将输入图像输入牛头识别模型中获取牛头图像。在本实施例中,选取连续的四帧图像作为输入。连续的四帧图像具有相近的牛头特征,在进行拼接形成集合图像时更容易识别牛头特征,从而在牛头识别模型中获取更清晰、质量更高的牛头图像。
[0078]
s3:通过颜色阈值法从每个牛头图像中提取出耳标图像。对耳标图像进行预处理形成二值化图像。颜色阈值法包括:
[0079]
s31:使用颜色空间转换工具将牛头图像的颜色空间变换到hsv颜色空间获得hsv图像。在本实施例中,颜色空间转换工具为opencv工具。牛头图像的颜色空间为rgb颜色空间。rgb颜色空间俗称三基色模式,是以红、绿和蓝三种基本色为基础,通过不同程度的叠加,产生丰富而广泛的颜色。hsv颜色空间也称六角锥体模型,其颜色的参数分别是色调h,饱和度s和明度v。
[0080]
s32:设置奶牛耳标的hsv颜色阈值范围,根据颜色阈值范围从牛头图像中分割出耳标图像。在本实施例中,将hsv颜色空间的阈值设定为(-30,330),耳标为黄色,其阈值为[30,90)。
[0081]
预处理的方法包括:滤波、直方图均衡化和二值化。滤波是在尽量保留图像细节特征的条件下对目标图像的噪声进行抑制。滤波的方法包括自适应中值滤波、高斯滤波、双边滤波和导向滤波。自适应中值滤波的基本原理是:选择待处理像素的一个邻域中各像素值的中值来代替待处理的像素,使某像素的灰度值与周围领域内的像素比较接近,从而消除一些孤立的噪声点,所以自适应中值滤波器能够很好的消除椒盐噪声。不仅如此,中值滤波器在消除噪声的同时,还能有效的保护图像的边界信息,不会对图像造成很大的模糊。高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个模板扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。图像大多数噪声均属于高斯噪声,因此高斯滤波应用也较广泛。高斯滤波是一种线性平滑滤波,适用于消除高斯噪声,广泛应用于图像去噪。双边滤波是结合图像的空间邻近度和像素值相似度的一种折中处理,同时考虑空域信息和灰度相似性,达到保留边缘且去除噪声的目的。导向滤波不仅能实现双边滤波的边缘平滑,还能保留图像边缘。
[0082]
直方图均衡化是一种增强图像对比度的方法,其主要思想是将一副图像的直方图分布变成近似均匀分布,从而增强图像的对比度。
[0083]
图像的二值化,就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的只有黑和白的视觉效果。一幅图像包括目标物体、背景还有噪声,要想从多值的数字图像中直接提取出目标物体,最常用的方法就是设定一个全局的阈值t,用t将图
像的数据分成两部分:大于t的像素群和小于t的像素群。将大于t的像素群的像素值设定为白色,小于t的像素群的像素值设定为黑色。
[0084]
通过预处理可以提高耳标图像的质量,使得耳标图像的特征更加明显,有利于耳标图像的进一步识别。
[0085]
s4:检测每个二值化图像的方向并将每个二值化图像根据方向分类形成多个方向集。根据方向类别将所有二值化图像旋转至水平方向作为水平图像。
[0086]
方向集的分类方法包括:
[0087]
s41:构建基于vggnet-16神经网络的分类模型。vggnet-16神经网络包括13个卷积层、5个池化层和3个全连层。每个卷积层均为3
×
3的小型卷积滤波器。13个卷积层按照两层、两层、三层、三层和三层的顺序分为五集。每集内连接一个池化层。每个池化层均为2
×
2的最大池化核。全连接层用于整合卷积层、池化层中具有类别区分性的局部信息。vggnet-16神经网络在训练时将一张耳标图像缩放到不同的尺寸,再随机剪裁到224*224的大小,能够增加数据量。
[0088]
s42:根据分类模型识别二值化图像中耳标方向与水平方向的夹角范围。分类模型在预测时将一张二值化图像缩放到不同尺寸做预测,最后取平均值,提高预测输出的精确度。
[0089]
s43:根据夹角范围对二值化图像进行分类形成多个方向集。多个方向集包括:0
°
集、90
°
集、180
°
集和270
°
集。0
°
集、90
°
集、180
°
集和270
°
集分别对应的夹角范围为[θ,θ+90
°
)、[θ+90
°
,θ+180
°
)、[θ+180
°
,θ+270
°
)和[θ+270
°
,θ+360
°
)。其中θ∈[-45
°
,0
°
]。将0
°
集定义为水平方向集。
[0090]
旋转方法包括:旋转其余的方向集直至全部的方向集转换为水平方向集。在调整耳标图像的方向时,90
°
集、180
°
集和270
°
集内的耳标图像分别逆时针旋转90
°
、180
°
和270
°
,从而使全部耳标图像均处于0
°
类别内,即处于水平方向。相较于识别每个耳标图像的方向后单独旋转的方法,将耳标图像统一分类后整体旋转的方法效率更高。
[0091]
s5:通过基于cptn算法的文字图像提取模型从水平图像中检测并提取出具有文字特征的文字图像。文字图像提取模型的建立方法包括如下步骤:
[0092]
s51:获取文本图像集。根据耳标所使用的编号文字选择相应的文本集。文本集可包含中文、英文、数字、希腊字母、标点符号等。通过对文本集内的所有非重复文字进行单独拍照获取多个文字图像。多个文字图像共同构成文本图像集。其中一部分文本图像集作为训练集二。另一部分文本图像作为测试集二。训练集二和测试集二均包含全部的非重复文字的特征。
[0093]
s52:建立基于cptn算法的初始文字区域检测模型。通过vgg16提取水平图像中的文字图像特征作为预测图,在预测图上做滑窗,滑窗的窗口大小为3
×
3,每个滑窗输出一个特征向量,将得到的特征向量输入到一个双向的lstm中得到一个输出层,在输出层上接一个全连接层进行输出,最后使用基于图的文本行构造算法输出预测的文字图像。
[0094]
s53:通过训练集二对初始文字图像提取模型进行训练获取文字图像提取模型。通过测试集二对文字图像提取模型进行测试。保留通过测试的文字图像提取模型。文字图像提取模型在不断训练的过程中进行自我迭代,对文字特征的识别准确度逐步提升。在对文字图像提取模型的测试准确度达到一个预定的阈值时,即视为通过测试,便可以保留通过
测试的文字图像提取模型。
[0095]
请结合图3,其为本实施例的文字图像采集图。可以看出,文字图像是仅由黑白两色构成的图像,其中文字为白色。这是在耳标图像二值化处理时得到的图像效果,使耳标上的文字区域更容易被识别。在本实施例中,奶牛所佩戴的耳标上文字显示较为明显,文字所处的区域范围占耳标顶面的60%以上,且耳标的底色为黄色,编号为黑色字体。在实际识别的过程中,影响文字图像提取的主要因素是奶牛所处的位置和视频拍摄的方向。基于识别精确度的考虑,每头奶牛最好是双耳各佩戴一只耳标,且每头奶牛所佩戴的两个耳标均具有双面相同的编号。此外,可以为奶牛佩戴可旋转的耳标,从而在视频中更容易获取奶牛耳标图像及文字图像,提高耳标识别的精确度。
[0096]
s6:采用基于crnn算法的文字识别模型对文字图像上的文字内容进行预测并输出预测文字。请结合图4,其为本实施例的crnn模型的结构示意图。文字识别模型包括:
[0097]
cnn卷积层,其用于提取文字图像中具有文字特征的特征图像并对特征图像进行切片形成多个切片图像。在本实施例中,cnn网络模型共包含7层卷积神经网络,基础结构采用的是vgc的结构,其中输入是把灰度图缩放到尺寸为w*32,即固定高。在第三个和第四个池化层的时候,为了追求真实的高宽比例,采用的核尺寸为1*2。为了加速收敛并引入了bn层。把cnn提取到的特征图按列切分,每一列的512维特征,输入到两层各256单元的双向lstm进行分类。在训练过程中,通过ctc损失函数的指导,实现字符位置与类标的近似软对齐。
[0098]
rnn循环层,其用于对切片图像循环编码与解码。将切片图像输出为预测值。编码与解码可分别通过编码器和解码器来实现。编码器是将信号或数据进行编制、转换为可用以通讯、传输和存储的信号形式的设备。解码器是一种输入模拟视频信号并将它转换为数字信号格式,以进一步压缩和传输的硬设备。编码器和解码器均具有多个lstm单元。lstm单元的运行主要有三个阶段:忘记阶段、选择记忆阶段和输出阶段。忘记阶段主要是对上一个节点传进来的输入进行选择性忘记。选择记忆阶段将输入有选择性地进行记忆。对于重要的特征则着重记录下来,不重要的特征则少记一些。输出阶段将决定哪些特征将会被当成当前状态的输出。为了最小化训练误差,使用梯度下降法对lstm单元训练:应用时序性倒传递算法,依据错误修改每次的权重。
[0099]
ctc转录层,其用于对rnn循环层获取的预测值排序并转换成预测文字。ctc全称是一种常用在语音识别、文本识别等领域的算法,用来解决输入和输出序列长度不一、无法对齐的问题。在crnn中,它实际上就是模型对应的损失函数。
[0100]
在所有奶牛的编号中查找到与输出文字匹配的奶牛编号,将奶牛编号与分区域相对应,即可得到每头奶牛所处的位置。
[0101]
奶牛耳标识别系统包括:视频采集模块、视频传输模块、牛头图像提取模块、耳标图像提取模块、耳标图像分类模块、耳标图像旋转模块、文字图像提取模块和文字区域识别模块。
[0102]
视频采集模块包括多个监控摄像头,监控摄像头用于采集养殖场内的监控视频。视频采集模块包括多个监控摄像头。在养殖场内安装多个监控摄像头,用于实时监控所有奶牛可能出现的活动区域。监控摄像头可以选用球形摄像头、枪形摄像头或红外摄像头。监控摄像头可以安装在养殖区内的灯杆或墙壁上,只要能清晰的采集奶牛的视频即可。
[0103]
视频传输模块用于将视频传输至牛头图像提取模块中。视频传输模块连接在视频采集模块和牛头图像提取模块之间,其连接方式可以是电连接也可以是远程连接。
[0104]
牛头图像提取模块用于从监控视频中提取出包含奶牛的图像帧,并通过存储在其内部的基于yolo v5的牛头图像提取模型从图像帧中提取出具有牛头特征的牛头图像。牛头图像提取模块包括一个预先设置的牛头识别模型。牛头识别模型是由yolo v5模型与牛头原形图像数据集通过测试训练构建而成的。牛头图像提取模块在运行时,先将含有奶牛的视频截取出一个片段,在这个片段的所有帧图片中选取四张图像作为输出,进而在牛头识别模型中获取相应的牛头图像。
[0105]
耳标图像提取模块用于将牛头图像的颜色空间转换到hsv颜色空间形成hsv图像,并根据耳标颜色的阈值范围从hsv图像中分割出耳标图像。耳标图像提取模块还用于通过预处理将耳标图像转换成二值化图像。耳标图像提取模块包括图像分割单元和图像预处理单元。图像分割单元通过颜色阈值法将牛头图像原有的rgb颜色空间变换为hsv颜色空间,通过预先设置的阈值范围将hsv颜色空间中属于耳标的颜色范围分割出来形成耳标图像。图像预处理单元通过滤波、直方图均衡化和二值化将耳标图像转化为二值化图像,使得耳标图像的特征更加明显,便于耳标识别。
[0106]
耳标图像定向模块包括方向分类模块和图像旋转模块。方向分类模块用于通过存储在其内部的基于vggnet-16神经网络的分类模型识别二值化图像中耳标的方向,并将二值化图像按照耳标方向与水平方向的夹角范围分类形成多个方向集。这些方向集中包括一个水平方向集,其他方向集与水平方向集具有相同的夹角范围并共同构成完整的圆周角范围。耳标图像旋转模块用于将二值化图像按照夹角范围旋转至水平方向形成水平图像。每个方向集均通过旋转转换为水平方向集。
[0107]
文文字图像提取模块用于通过存储在其内部的基于cptn算法的文字检测模型从水平图像中检测并提取出具有文字特征的文字图像。文字图像提取模块通过一个预先获取的文本集在cptn算法模型中训练获得文字检测模型。将水平图像输入文字图像检测模型中获得预测的文字图像。
[0108]
文字区域识别模块用于通过存储在其内部的基于crnn算法的文字识别模型识别文字图像并输出预测文字。文字区域识别模块使用与文字图像提取模块相同的文本集对crnn模型进行测试训练。将文字图像输入训练后的crnn模型中获取预测的文字。
[0109]
在奶牛耳标识别的过程中,往往由于奶牛头部的朝向或奶牛所处的位置导致奶牛佩戴的耳标被遮挡,从而难以在监控视频中提取出完整的耳标图片。因此,本实施例提供一种奶牛耳标,奶牛耳标固定在奶牛的耳朵上且奶牛耳标的主标板可任意旋转,从而增加奶牛耳标在监控视频中可被识别的角度,提高耳标识别的准确度。
[0110]
请结合图5和图6,图5为本实施例的奶牛耳标的主视剖面结构示意图;图6为图6中奶牛耳标的俯视剖面结构示意图。奶牛耳标包括主标板1、耳标颈2、齿轮一3、限位杆5、压板6、副标板8和耳标柱9。
[0111]
主标板1为方形板。主标板1的顶面上设置有奶牛标识。标识可以是数字,也可以是文字或图案,只要能区分不同的耳标即可。主标板1的底面固定安装一个连接轴11,主标板1和连接轴11偏心设置。
[0112]
耳标颈2为环形结构。耳标颈2的顶部内固定安装一个轴承21。轴承21和连接轴11
固定连接。连接轴11可以在轴承21内侧沿连接轴11的中心轴任意旋转。主标板1的底部固定安装一个电机31,电机31的旋转轴上固定连接一个齿轮一3。耳标颈2的外侧同轴固定连接一个齿轮二32,齿轮二32和齿轮一3啮合设置。电机31驱动齿轮一3自转,进而驱动齿轮一3在齿轮二32的外侧公转,进而驱动主标板1偏心旋转。在对奶牛实时监控时,奶牛的双耳各佩戴一只耳标。由于奶牛头部方向不定,因此采集耳标标识的方向也不固定,从而导致耳标标识难以识别。通过驱动主标板1的旋转,将主标板1调节至水平方向,从而使主标板1上的标识能被清晰识别,提高对奶牛监控的时效性和准确性。
[0113]
耳标颈2的底部设置有底座23,底座23为环形板。底座23的底面上固定连接一个橡胶垫一41。底座23内设置有供限位杆5滑动的滑槽。限位杆5包括弹簧一51和滑块52。滑块52与滑槽滑动连接。弹簧一51设置在限位杆5的外侧,且弹簧一51的一端与滑块52固定连接,弹簧一51的另一端与底座23的内壁抵接。弹簧一51自然复位时,限位杆5的一端伸入耳标颈2内,另一端与耳标颈2的外壁抵接。在本实施例中,限位杆5设置有两集,当然在其他实施例中,限位杆5的数量也可以更多或更少。
[0114]
副标板8和耳标柱9螺接。副标板8包括底板和连接杆。连接杆与底板同轴固定连接。连接杆内设置有用于螺接耳标柱9的螺纹槽。耳标柱9的一端固定安装一个耳标头91,耳标头91为圆锥形结构。耳标柱9的另一端固定连接一个限位块,可以防止耳标柱9从副标板8内脱落。将耳标头91卡入耳标颈2内,耳标头91向两侧推动限位杆5直至完全超出限位杆5,弹簧一51复位驱动限位杆5向耳标颈2内滑动,从而使得限位杆5和耳标颈2抵接,避免耳标头91从耳标颈2内脱落。通过安装限位杆5,可以快速将耳标头91与耳标颈2卡接或拆卸,提高耳标安装或拆卸的效率,减少装配耳标的人工成本。
[0115]
连接杆外侧滑动连接一个压板6。压板6为中空的圆形板。压板6的顶面上安装一个橡胶垫二42。压板6与底板之间固定连接有多个弹簧二7。耳标佩戴在奶牛耳朵上时,橡胶垫一41和橡胶垫二42刚好抵接在奶牛耳朵的两侧上,可以避免奶牛耳朵与耳标的刚性接触,减小奶牛佩戴耳标的痛感。
[0116]
将耳标佩戴到奶牛耳朵上的步骤为:使用耳标头91穿透奶牛的耳朵形成一个耳洞,连接杆随即穿过耳洞将副标板8安装在耳洞内。将耳标颈2卡接在耳标头91外侧,即将两集限位杆5抵接在耳标头91的底面上,避免耳标头91脱落。旋转耳标柱9调节耳标头91和副标板8的间距,进而调节副标板8和底座23的间距,直至橡胶垫一41和橡胶垫二42分别紧固抵接在奶牛耳朵的两侧。耳标佩戴的方式简单便捷,可以降低对奶牛耳朵的损伤,提高耳标装配的效率。通过安装橡胶垫一41和橡胶垫二42,既可以防滑,避免耳标从奶牛耳朵上脱落,又可以避免耳标与奶牛耳朵的刚性接触,减小奶牛佩戴耳标的痛感。
[0117]
奶牛耳标还包括定位器100、心率传感器300、温度传感器200。定位器100固定安装在副标板8上。温度传感器200固定安装在压板6的顶面上。心率传感器300固定安装在连接杆上。通过定位器100可以实时掌握奶牛所处的位置。通过心率传感器300、温度传感器200可以实时掌握奶牛的健康信息。奶牛耳标还可以与监控装置和处理器相互连通,实时采集奶牛和奶牛耳标的视频信息以及奶牛的位置信息和健康信息,当奶牛的体温或心率异常时,可以通过处理器快速识别并做出反馈,进而帮助养殖人员快速找到对相应的奶牛并进行进一步检查或治疗,从而降低奶牛患病的概率。
[0118]
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和
原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1