一种多人脸检测方法、设备及存储介质与流程
1.本发明涉及计算机视觉技术领域,更具体地说,它涉及一种多人脸检测方法、设备及存储介质。
背景技术:
2.目前人脸检测技术已经广泛应用于日常与工作生活中,不仅在公共安全领域、经济安全领域以及军事安全领域中发挥了重要作用,在日常生活中也给人们带了极大的便利性,具有十分重要的研究价值。
3.在相关技术中,使用传统图像处理技术对图像进行人脸检测,如基于adaboost的人脸检测算法,其核心思想是自动从多个弱分类器的空间中挑选出若干个分类器,构成一个分类能力很强的强分类器,从而对一张图像中是否存在人脸做出预测分类。
4.上述方法容易受到复杂环境的影响,在复杂背景的多人脸图像中,很容易出现误检或漏检的情况,同时,对于当今的大数据背景下的高质量图像而言,其检测速度与精度都达不到要求,具有很大的局限性。
技术实现要素:
5.本发明要解决的技术问题是针对现有技术的上述不足,本发明的目的一是提供一种可以提高检测速度与精度的多人脸检测方法。
6.本发明的目的二是提供一种计算机设备。
7.本发明的目的三是提供一种计算机可读存储介质。
8.为了实现上述目的一,本发明提供一种多人脸检测方法,包括以下步骤:
9.步骤s1.构建人脸图像数据集;
10.步骤s2.构建多人脸检测神经网络;
11.步骤s3.根据所述人脸图像数据集对所述多人脸检测神经网络进行迭代训练得到多人脸检测模型;
12.步骤s4.构建多人脸检测解码器;
13.步骤s5.将待检测图像输入所述多人脸检测模型得到预测结果,将所述预测结果输入所述多人脸检测解码器得到检测结果;
14.其中,步骤s2包括:
15.步骤s21.构建降维卷积模块,所述降维卷积模块位于网络的起始部分,用于处理输入层的输入图像,所述降维卷积模块包含一个conv层、一个activation层、一个bn层以及一个maxpooling2d层;
16.所述conv层包含12个5
×
5的卷积核,卷积步长设置为4,padding的值设置为same,卷积核参数使用均值为0、方差为1的高斯随机数来初始化;
17.所述activation层接在所述conv层之后,使用relu作为激活函数;
18.所述bn层接在所述activation层之后,gamma_regularizer和beta_regularrizer
的值都设置为0.0001;
19.所述maxpooling2d接在所述bn层之后,池化窗口大小设置为2
×
2,池化步长设置为2,padding设置为same;
20.步骤s22.构建多尺度卷积模块:所述多尺度卷积模块包括一个conv_1层、一个conv_2层、一个conv_3层、一个conv_4层;
21.所述conv_1层包含16个1
×
1的卷积核,卷积步长设置为1,padding设置为same;
22.所述conv_2层包含16个3
×
3的卷积核,卷积步长设置为1,padding设置为same;
23.所述conv_3层包含16个5
×
5的卷积核,卷积步长设置为1,padding设置为same;
24.所述conv_4层包含16个7
×
7的卷积核,卷积步长设置为1,padding设置为same;
25.所述conv_1层、conv_2层、conv_3层、conv_4层以并联的方式结合,也就是输入图像在经过多尺度卷积模块时会分别经过这4个层,然后在模块的最后将这4个层的输出张量在concatenate层做一个拼接并输出;
26.步骤s23.构建多尺度人脸先验框及置信度预测模块,在不同尺度的卷积特征图上设置一系列不同尺度的先验框,这些先验框和多尺度卷积层构成了多人脸检测神经网络的最后一个模块,多人脸检测神经网络通过该模块预测每个先验框的中心偏移量以及长宽偏移量,再结合先验框的设置可以得到特征图上人脸检测框的预测值。
27.作为进一步地改进,步骤s23包括:
28.步骤s231.通过所述多尺度卷积模块的输出得到第一种尺度的特征图feature_map_1;构建一个卷积层,使用128个3
×
3的卷积核并以2为步长卷积第一种尺度的特征图,得到第二种尺度的特征图feature_map_2;构建一个卷积层,使用128个3
×
3的卷积核并以2为步长卷积第二种尺度的特征图,得到第三种尺度的特征图feature_map_3;
29.步骤s232.以feature_map_1为基础,在其上每一个点设置3个先验框,先验框的scale设置为24,比例aspect设置为{1:2,1:1,2:1},得到各点的先验框信息;
30.步骤s233.以feature_map_2为基础,在其上每一个点设置3个先验框,先验框的scale设置为32,比例aspect设置为{1:3,1:1,3:1},得到各点的先验框信息;
31.步骤s234.以feature_map_3为基础,在其上每一个点设置3个先验框,先验框的scale设置为60,比例aspect设置为{1:4,1:1,4:1},得到各点的先验框信息;
32.步骤s235.基于feature_map_1,模型通过一个使用6个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出feature_map_1上每一个先验框的类别预测值;再通过一个使用12个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出模型对feature_map_1上每一个先验框的偏移量预测值;
33.步骤s236.基于feature_map_2,模型通过一个使用6个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出feature_map_2上每一个先验框的类别预测值;再通过一个使用12个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出模型对feature_map_2上每一个先验框的偏移量预测值;
34.步骤s237.基于feature_map_3,模型通过一个使用6个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出feature_map_3上每一个先验框的类别预测值;再通过一个使用12个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出模型对feature_map_3上每一个先验框的偏移量预测值;
35.步骤s238.将步骤s232~步骤s237得到的所有先验框的信息聚合为模块的输出,输出张量形状为(n_boxes,n_classes+8),其中n_boxes表示先验框的数量,n_classes表示类别数量,8表示和先验框有关的位置参数值,神经网络通过该模块的输出结果对模型进行训练。
36.进一步地,步骤s1包括:
37.步骤s11.收集设定数量的自然场景下的人脸图像,包括单人脸场景以及多人脸场景的图像,以及包括了复杂背景或简单背景的人脸图像;
38.步骤s12.对所述人脸图像进行标注,使用一系列矩形框来框住图像中的人脸图像,并记录矩形框在人脸图像上的位置信息;
39.步骤s13.将所述人脸图像以8:2的比例划分为训练集和验证集,训练集用于所述多人脸检测神经网络的学习训练,验证集用于每轮训练迭代后的模型评估,以方便模型的调参。
40.进一步地,还包括步骤s14.对所述训练集的每一幅人脸图像做数据增强处理。
41.进一步地,数据增强处理包括水平翻转或竖直翻转处理、高斯模糊处理、扭曲图像局部特征处理、加入高斯噪声处理中的任意一种。
42.进一步地,步骤s3包括:
43.步骤s31.将所述训练集的训练图像上标注的真实人脸矩形框信息转换为与所述多人脸检测神经网络的预测结果信息一致的格式;
44.步骤s32.设计损失函数,损失函数分为两个部分,第一部分为模型对先验框的位置预测误差,第二部分为类别置信度预测误差,损失函数的简化模型如下式所示:
[0045][0046]
其中,n表示先验框的正样本数量,l
loc
表示位置误差,l
conf
表示置信度误差;
[0047]
步骤s33.将所述多人脸检测神经网络的所有参数初始化为均值为0、方差为1的高斯随机数;
[0048]
步骤s34.设置所述多人脸检测神经网络的训练迭代次数epoch,根据迭代次数epoch选择所述多人脸检测神经网络的初始学习率:若epoch》10000,则初始学习率设置为10-4
;否则,初始学习率设置为10-3
;设置每次训练的batch_size为64;
[0049]
步骤s45.从所述训练集中随机取batch_size张训练图像输入所述多人脸检测神经网络,使用步骤s32的损失函数计算所述多人脸检测神经网络的输出值与真实值的误差值;
[0050]
步骤s46.使用梯度下降算法更新所述多人脸检测神经网络的权重参数,同时训练迭代次数加1;
[0051]
步骤s47.判断迭代次数是否达到初始设置的训练迭代次数epoch,如果达到了,则训练结束,保存所述多人脸检测神经网络的权重参数;若未达到,则重复步骤s45。
[0052]
进一步地,步骤s4包括:
[0053]
步骤s41.根据先验框信息以及该先验框对应的偏移量预测值计算出实际预测矩形框的参数;
[0054]
步骤s42.将实际预测矩形框的位置信息转化为坐标信息;
[0055]
步骤s43.将实际预测矩形框的坐标信息通过一个尺度变换来映射到原图上,得到人脸预测候选框;
[0056]
步骤s44.设置一个人脸置信度阈值confidence threshold,对于每一个人脸预测候选框,如果该人脸预测候选框对人脸的预测值低于人脸置信度阈值,则将该人脸预测候选框剔除;
[0057]
步骤s45.针对步骤s44筛选通过的人脸预测候选框,进一步通过非极大值抑制对其进行筛选;
[0058]
步骤s46.对于通过步骤s45筛选的人脸预测候选框,设置一个top_k值,根据对人脸的预测值大小,将人脸预测候选框进行排列,取得分最高的top_k个人脸预测候选框作为解码器最终的输出,这top_k个人脸预测候选框即为真实人脸图像的检测结果。
[0059]
进一步地,步骤s45包括:
[0060]
步骤s451.设置一个候选框交并比阈值iou threshold;
[0061]
步骤s452.按照每个人脸预测候选框对人脸预测的得分从大到小排序;
[0062]
步骤s453.将得分最大的人脸预测候选框作为置信度最高的框,剩余的人脸预测候选框与该框进行比较,若某个剩余的人脸预测候选框与该框重叠的阈值大于iou threshold,则被剔除,否则保留;
[0063]
步骤s454.对于步骤s453中保留下来的候选框,重复步骤s452,直到所有框被比较结束。
[0064]
为了实现上述目的二,本发明提供一种计算机设备,包括存储器、处理器;所述存储器用于存储计算机程序;所述处理器用于执行所述计算机程序,以实现如上述的一种多人脸检测方法。
[0065]
为了实现上述目的三,本发明提供一种计算机可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时用于实现如上述的一种多人脸检测方法。
[0066]
有益效果
[0067]
本发明与现有技术相比,具有的优点为:
[0068]
本发明在卷积神经网络的基础上做出了一系列改进,包括引入降维卷积模块、多尺度卷积模块,与现有的人脸检测技术相比,不仅提高了检测的速度,同时也提高了人脸检测的准确度。
附图说明
[0069]
图1为本发明中方法的流程图;
[0070]
图2为本发明进行多人脸检测的流程图。
具体实施方式
[0071]
下面结合附图中的具体实施例对本发明做进一步的说明。
[0072]
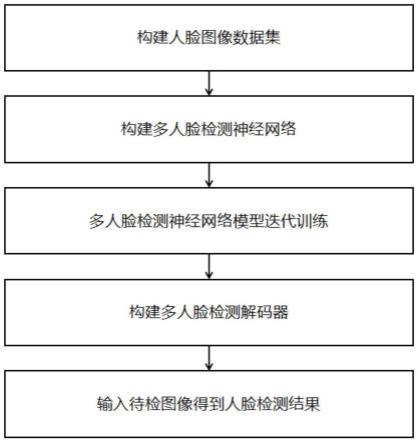
参阅图1、2,一种多人脸检测方法,包括以下步骤:
[0073]
步骤s1.构建人脸图像数据集;
[0074]
步骤s2.构建多人脸检测神经网络;
[0075]
步骤s3.根据人脸图像数据集对多人脸检测神经网络进行迭代训练得到多人脸检测模型;
[0076]
步骤s4.构建多人脸检测解码器;
[0077]
步骤s5.将待检测图像输入多人脸检测模型得到预测结果,将预测结果输入多人脸检测解码器得到检测结果。
[0078]
构建人脸图像数据集包括:
[0079]
步骤s11.收集设定数量的自然场景下的人脸图像,包括单人脸场景以及多人脸场景的图像,以及包括了复杂背景或简单背景的人脸图像,设定数量越大越好,如设定数量为10万;
[0080]
步骤s12.对人脸图像进行标注,使用一系列矩形框来框住图像中的人脸图像,并记录矩形框在人脸图像上的位置信息;位置信息包括矩形框的中心点坐标信息(r
x
,ry)、矩形框的高度rh以及宽度rw;
[0081]
步骤s13.将人脸图像以8:2的比例划分为训练集和验证集,训练集用于多人脸检测神经网络的学习训练,验证集用于每轮训练迭代后的模型评估,以方便模型的调参;
[0082]
步骤s14.对训练集的每一幅人脸图像做数据增强处理。数据增强处理包括水平翻转或竖直翻转处理、高斯模糊处理、扭曲图像局部特征处理、加入高斯噪声处理中的任意一种,其中,在高斯模糊处理的sigma取值为0~3.0,扭曲图像局部特征处理的scale取值为0.01~0.05,加入高斯噪声处理的scale取值为0~51。
[0083]
构建多人脸检测神经网络包括:
[0084]
步骤s21.构建降维卷积模块,降维卷积模块位于网络的起始部分,用于处理输入层的输入图像,降维卷积模块包含一个conv层、一个activation层、一个bn层以及一个maxpooling2d层;
[0085]
conv层包含12个5
×
5的卷积核,卷积步长设置为4,padding的值设置为same,卷积核参数使用均值为0、方差为1的高斯随机数来初始化;
[0086]
activation层接在conv层之后,使用relu作为激活函数;
[0087]
bn层接在activation层之后,gamma_regularizer和beta_regularrizer的值都设置为0.0001;
[0088]
maxpooling2d接在bn层之后,池化窗口大小设置为2
×
2,池化步长设置为2,padding设置为same;尺寸为n的输入图像经过模块的卷积层时,会变成12个尺寸为n/4的特征图,经过activation层、bn层时尺寸不变,再经过maxpooling2d层时,变为12个尺寸为n/8的特征图,也就是输入图像在经过一个降维卷积模块时,尺寸会变为原来的1/8,输入空间的大小得到了压缩,由于计算机在做卷积操作时耗时较多,因此这种降维操作可以有效提升网络的计算速度,另外,卷积窗口设置为5
×
5也能在一定程度上减轻空间尺寸减小带来的信息损失;
[0089]
步骤s22.构建多尺度卷积模块:多尺度卷积模块包括一个conv_1层、一个conv_2层、一个conv_3层、一个conv_4层;
[0090]
conv_1层包含16个1
×
1的卷积核,卷积步长设置为1,padding设置为same;
[0091]
conv_2层包含16个3
×
3的卷积核,卷积步长设置为1,padding设置为same;
[0092]
conv_3层包含16个5
×
5的卷积核,卷积步长设置为1,padding设置为same;
[0093]
conv_4层包含16个7
×
7的卷积核,卷积步长设置为1,padding设置为same;
[0094]
conv_1层、conv_2层、conv_3层、conv_4层以并联的方式结合,也就是输入图像在经过多尺度卷积模块时会分别经过这4个层,然后在模块的最后将这4个层的输出张量在concatenate层做一个拼接并输出;这样做的目的是对神经网络模型的深度和宽度进行高效扩充,提升模型准确率的同时,还能在一定程度上防止过拟合现象的发生,另外,该模块还能在不同尺度上提取图像特征,提高模型对不同尺度视觉信息进行聚合的能力;
[0095]
步骤s23.构建多尺度人脸先验框及置信度预测模块,由于每张人脸图像中的人脸尺寸大小不一,为了使模型能够更好地学习不同尺度人脸的视觉模式,在不同尺度的卷积特征图上设置一系列不同尺度的先验框,这些先验框和多尺度卷积层构成了多人脸检测神经网络的最后一个模块,多人脸检测神经网络通过该模块预测每个先验框的中心偏移量以及长宽偏移量,再结合先验框的设置可以得到特征图上人脸检测框的预测值。具体做法如下:
[0096]
步骤s231.通过多尺度卷积模块的输出得到第一种尺度的特征图feature_map_1;构建一个卷积层,使用128个3
×
3的卷积核并以2为步长卷积第一种尺度的特征图,得到第二种尺度的特征图feature_map_2;构建一个卷积层,使用128个3
×
3的卷积核并以2为步长卷积第二种尺度的特征图,得到第三种尺度的特征图feature_map_3;
[0097]
步骤s232.以feature_map_1为基础,在其上每一个点设置3个先验框,先验框的scale设置为24,比例aspect设置为{1:2,1:1,2:1},得到各点的先验框信息;若feature_map_1的尺寸为n
×
n,则可以得到n
×n×
3个先验框信息,先验框信息包括先验框的中心点坐标(b
x
,by),以及先验框的宽度bw和先验框的高度bh;
[0098]
步骤s233.以feature_map_2为基础,在其上每一个点设置3个先验框,先验框的scale设置为32,比例aspect设置为{1:3,1:1,3:1},得到各点的先验框信息;若feature_map_2的尺寸为n
×
n,则可以得到n
×n×
3个先验框信息,先验框信息包括先验框的中心点坐标(b
x
,by),以及先验框的宽度bw和先验框的高度bh;
[0099]
步骤s234.以feature_map_3为基础,在其上每一个点设置3个先验框,先验框的scale设置为60,比例aspect设置为{1:4,1:1,4:1},得到各点的先验框信息;若feature_map_3的尺寸为n
×
n,则可以得到n
×n×
3个先验框信息,先验框信息包括先验框的中心点坐标(b
x
,by),以及先验框的宽度bw和先验框的高度bh;
[0100]
步骤s235.基于feature_map_1,模型通过一个使用6个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出feature_map_1上每一个先验框的类别预测值;再通过一个使用12个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出模型对feature_map_1上每一个先验框的偏移量预测值;偏移量预测值包括中心点偏移量(p
x
,py)以及宽度偏移量pw和高度偏移量ph;
[0101]
步骤s236.基于feature_map_2,模型通过一个使用6个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出feature_map_2上每一个先验框的类别预测值;再通过一个使用12个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出模型对feature_map_2上每一个先验框的偏移量预测值;偏移量预测值包括中心点偏移量(p
x
,py)以及宽度偏移量pw和高度偏移量ph;
[0102]
步骤s237.基于feature_map_3,模型通过一个使用6个3
×
3的卷积核并以1为步长
的conv层和一个reshape层输出feature_map_3上每一个先验框的类别预测值;再通过一个使用12个3
×
3的卷积核并以1为步长的conv层和一个reshape层输出模型对feature_map_3上每一个先验框的偏移量预测值;偏移量预测值包括中心点偏移量(p
x
,py)以及宽度偏移量pw和高度偏移量ph;
[0103]
步骤s238.将步骤s232~步骤s237得到的所有先验框的信息聚合为模块的输出,输出张量形状为(n_boxes,n_classes+8),其中n_boxes表示先验框的数量,n_classes表示类别数量,8表示和先验框有关的位置参数值,神经网络通过该模块的输出结果对模型进行训练。
[0104]
对多人脸检测神经网络进行迭代训练包括:
[0105]
步骤s31.将训练集的训练图像上标注的真实人脸矩形框信息转换为与多人脸检测神经网络的预测结果信息一致的格式;
[0106]
步骤s32.设计损失函数,损失函数分为两个部分,第一部分为模型对先验框的位置预测误差,第二部分为类别置信度预测误差,损失函数的简化模型如下式所示:
[0107][0108]
其中,n表示先验框的正样本数量,l
loc
表示位置误差,l
conf
表示置信度误差;
[0109]
步骤s33.将多人脸检测神经网络的所有参数初始化为均值为0、方差为1的高斯随机数;
[0110]
步骤s34.设置多人脸检测神经网络的训练迭代次数epoch,根据迭代次数epoch选择多人脸检测神经网络的初始学习率:若epoch》10000,则初始学习率设置为10-4
;否则,初始学习率设置为10-3
;设置每次训练的batch_size为64;
[0111]
步骤s45.从训练集中随机取batch_size张训练图像输入多人脸检测神经网络,使用步骤s32的损失函数计算多人脸检测神经网络的输出值与真实值的误差值;
[0112]
步骤s46.使用梯度下降算法更新多人脸检测神经网络的权重参数,同时训练迭代次数加1;
[0113]
步骤s47.判断迭代次数是否达到初始设置的训练迭代次数epoch,如果达到了,则训练结束,保存多人脸检测神经网络的权重参数;若未达到,则重复步骤s45。
[0114]
神经网络模型的输出为与先验框有关的预测值,实际应用中,需要将这些预测信息映射回原图,另外,先验框数量通常远远大于实际图像中的人脸数量,需要对这些先验框做一系列筛选处理,因此构建一个解码器,对模型的输出做一系列处理,具体过程如下:
[0115]
步骤s41.根据先验框信息以及该先验框对应的偏移量预测值计算出实际预测矩形框的参数;具体为,根据先验框的4个参数(b
x
,by,bw,bh)以及网络模型预测的4个偏移量(p
x
,py,pw,ph)计算出实际预测的矩形框的参数,计算方式如下:
[0116]
t
x
=b
x
+p
x
×bw
[0117]
ty=by+py×bh
[0118][0119][0120]
上式中,t
x
、ty分别为实际预测矩形框的中心点坐标,tw和th分别为实际预测矩形
框的宽度和高度;
[0121]
步骤s42.将实际预测矩形框的位置信息转化为坐标信息,转换方式如下:
[0122]
t
xmin
=t
x-0.5
×
tw[0123]
t
ymin
=t
y-0.5
×
th[0124]
t
xmax
=t
x
+0.5
×
tw[0125]
t
ymax
=ty+0.5
×
th[0126]
上式中,t
xmin
、t
ymin
分别为实际预测矩形框的左上角横纵坐标,t
xmax
和t
ymax
分别为实际预测矩形框的右下角横纵坐标;
[0127]
步骤s43.将实际预测矩形框的坐标信息通过一个尺度变换来映射到原图上,得到人脸预测候选框,如下式:
[0128]
x
min
=t
xmin
×iw
[0129]ymin
=t
ymin
×
ih[0130]
x
max
=t
xmax
×iw
[0131]ymax
=t
ymax
×
ih[0132]
式中,(x
min
,y
min
)为人脸预测候选框在真实图像上的左上角坐标,(x
max
,y
max
)为人脸预测候选框在真实图像上的右下角坐标,iw为真实图像的宽度,ih为真实图像的高度;通过上述变换可以将模型的输出张量的格式转换为(n_boxes,n_classes+4),其中,n_boxes表示真实图像上预测候选框的数量,n_classes的值为2,表示模型对这个候选框中的物体预测为人脸或者背景的两个概率值,4表示这个候选框的位置信息;为了更直观地显示出候选框的预测结果,将输出格式转化为(n_boxes,class_id+4),其中,class_id表示类别信息,0代表背景,1代表人脸;
[0133]
步骤s44.设置一个人脸置信度阈值confidence threshold,对于每一个人脸预测候选框,如果该人脸预测候选框对人脸的预测值低于人脸置信度阈值,则将该人脸预测候选框剔除;
[0134]
步骤s45.针对步骤s44筛选通过的人脸预测候选框,进一步通过非极大值抑制对其进行筛选;
[0135]
步骤s46.对于通过步骤s45筛选的人脸预测候选框,可能仍然比较多,因此可以根据场景的实际情况(有些场景人脸多,有些场景人脸少),设置一个top_k值,根据对人脸的预测值大小,将人脸预测候选框进行排列,取得分最高的top_k个人脸预测候选框作为解码器最终的输出,这top_k个人脸预测候选框即为真实人脸图像的检测结果。
[0136]
通过非极大值抑制对其进行筛选具体包括:
[0137]
步骤s451.设置一个候选框交并比阈值iou threshold;
[0138]
步骤s452.按照每个人脸预测候选框对人脸预测的得分从大到小排序;
[0139]
步骤s453.将得分最大的人脸预测候选框作为置信度最高的框,当存在多个得分最大的人脸预测候选框时,选择第一个,剩余的人脸预测候选框与该框进行比较,若某个剩余的人脸预测候选框与该框重叠的阈值大于iou threshold,则被剔除,否则保留;
[0140]
步骤s454.对于步骤s453中保留下来的候选框,重复步骤s452,直到所有框被比较结束。
[0141]
本发明在卷积神经网络的基础上做出了一系列改进,包括引入降维卷积模块、多
尺度卷积模块,与现有的人脸检测技术相比,不仅提高了检测的速度,同时也提高了人脸检测的准确度。
[0142]
一种计算机设备,包括存储器、处理器;存储器用于存储计算机程序;处理器用于执行计算机程序,以实现如上述的一种多人脸检测方法。
[0143]
一种计算机可读存储介质,可读存储介质上存储有计算机程序,计算机程序被处理器执行时用于实现如上述的一种多人脸检测方法。
[0144]
实际应用
[0145]
本发明对一张人脸图像进行检测的过程如下:
[0146]
1.将输入图像的尺寸统一调整为512
×
512
×
3;
[0147]
2.将输入图像输入多人脸检测模型后,首先经过两个降维卷积模块,得到12个8
×
8的特征图,可以看到,经过降维卷积模块之后,特征图的尺寸相对于原输入图像的尺寸降低了64倍;
[0148]
3.将第2步处理得到的特征图连续通过两个多尺度卷积模块,得到64个8
×
8的特征图,这64个特征图是由不同尺度的卷积核卷积得来;
[0149]
4.以第3步处理得到的特征图作为人脸检测的第一种尺度的特征图feature_map_1;使用128个3
×
3的卷积核以2的步长卷积第一种尺度的特征图,得到128个4
×
4的特征图,以此作为人脸检测的第二种尺度的特征图feature_map_2;使用128个3
×
3的卷积核以2的步长卷积第二种尺度的特征图,得到128个2
×
2的特征图,以此作为人脸检测的第三种尺度的特征图feature_map_3;
[0150]
5.以feature_map_1为基础,在其上每一个点设置3个先验框,先验框的scale设置为24,比例aspect设置为{1:2,1:1,2:1},由此得到8
×8×
3个先验框;
[0151]
6.以feature_map_2为基础,在其上每一个点设置3个先验框,先验框的scale设置为32,比例aspect设置为{1:3,1:1,3:1},由此得到4
×4×
3个先验框;
[0152]
7.以feature_map_3为基础,在其上每一个点设置3个先验框,先验框的scale设置为60,比例aspect设置为{1:4,1:1,4:1},由此得到2
×2×
3个先验框;
[0153]
8.基于feature_map_1,通过一个conv层(6个3
×
3卷积核,卷积步长为1)和一个reshape层得到8
×8×3×
2个值,也即每个先验框对于人脸和背景两个类别的预测值;再通过一个conv层(12个3
×
3卷积核,卷积步长为1)和一个reshape层得到8
×8×3×
4个值,也即模型对每一个先验框的偏移量预测值,包括中心点偏移量(p
x
,py)以及宽度偏移量pw和高度偏移量ph;
[0154]
9.基于feature_map_2,通过一个conv层(6个3
×
3卷积核,卷积步长为1)和一个reshape层得到4
×4×3×
2个先验框的类别预测值;再通过一个conv层(12个3
×
3卷积核,卷积步长为1)和一个reshape层得到4
×4×3×
4个先验框的偏移量预测值,包括中心点偏移量(p
x
,py)以及宽度偏移量pw和高度偏移量ph;
[0155]
10.基于feature_map_3,通过一个conv层(6个3
×
3卷积核,卷积步长为1)和一个reshape层得到2
×2×3×
2个先验框的类别预测值;再通过一个conv层(12个3
×
3卷积核,卷积步长为1)和一个reshape层得到2
×2×3×
4个先验框的偏移量预测值,包括中心点偏移量(p
x
,py)以及宽度偏移量pw和高度偏移量ph;
[0156]
11.将上述得到的所有先验框的信息聚合为模块的输出,输出张量形状为(252,2+
8),其中252表示先验框的数量,2表示类别数量,8表示和先验框有关的位置参数值;
[0157]
12.将模块输出的先验框位置信息映射到原输入图像上,得到一个(252,2+4)的输出张量,252表示映射到原输入图像上的候选框数量,2表示模型对这个候选框中的物体预测为人脸或者背景的两个概率值,4表示候选框在图像上的位置信息(x
min
,y
min
,x
max
,y
max
),为了更直观地显示出候选框的预测结果,将输出格式转化为(252,1+4);
[0158]
13.设置一个人脸置信度阈值confidence threshold,将人脸预测得分低于该阈值的候选框剔除;
[0159]
14.设置一个候选框交并比阈值iou threshold,对步骤13筛选通过的候选框,按照每个候选框对人脸预测得分的高低从大到小排序,将第一个候选框作为置信度最高的框,剩余候选框与该框进行比较,若某个候选框与它重叠的阈值大于iou threshold,则被剔除,反之则保留,重复该步骤,直到所有框被比较结束;
[0160]
设置一个top_k值,对于步骤14筛选通过的候选框,按照候选框对人脸预测得分的高低从大到小排序,选择top_k个候选框作为模型检测人脸框的输出结果。
[0161]
以上仅是本发明的优选实施方式,应当指出对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些都不会影响本发明实施的效果和专利的实用性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1