基于数据集成聚类的工业燃煤锅炉工况划分方法及系统
1.本发明属于数据聚类技术领域,尤其涉及一种基于数据集成聚类的工业燃煤锅炉工况划分方法及系统。
背景技术:
2.随着社会对安全、节能和环保方面的要求逐年提高,如何在推进行业健康稳步发展和确保工业燃煤锅炉安全运行的形势下,进一步加速推进节能减排工作的开展,已成为工业锅炉行业未来发展面临的新课题和严峻挑战。我国的能源结构以煤为主,量大面广的工业燃煤锅炉要消耗大量的煤炭,同时也是我国主要的煤烟型污染源。然而,工业燃煤锅炉平均运行效率较低,行业节能潜力巨大,着眼未来发展,节能减排既是工业燃煤锅炉行业的当务之急更是长远战略要务。
3.发明人发现,在燃煤锅炉生产工作的过程中,锅炉设备的各个环节都在持续不断的产生着状态数据,而且会实时采集并保存到后台数据库中,但是对于这座数据“金库”,很多企业并没有发掘出内部隐藏的价值,只是简单的将其存在计算机中,丧失了这些数据所产生的价值。燃煤锅炉数据具有数据量大维度高的特点,传统的集成聚类算法已经不再适用,传统的聚类方法计算时间复杂度太高,不能有效构建燃煤锅炉数据的亲和矩阵。
技术实现要素:
4.本发明为了解决上述问题,提出了一种基于数据集成聚类的工业燃煤锅炉工况划分方法及系统,本发明针对燃煤锅炉工况划分方法进行了相应的技术创新,通过对大规模的工业燃煤锅炉数据进行集成聚类,更清晰的展示了燃煤锅炉生产工作过程中各参数和锅炉工况之间的关系,为后续工人调整参数,保持燃煤锅炉高效运行提供了可靠的技术支持。
5.为了实现上述目的,本发明是通过如下的技术方案来实现:
6.第一方面,本发明提供了一种基于数据集成聚类的工业燃煤锅炉工况划分方法,包括:
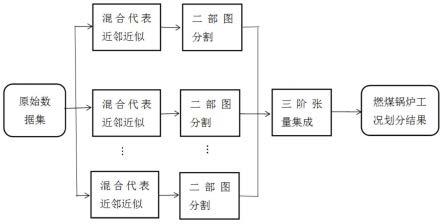
7.获取工业燃煤锅炉的运行状态数据;
8.基于运行状态数据,构建亲和矩阵;
9.针对构建亲和矩阵,依据混合代表近邻近似方法,构建稀疏亲和子矩阵;
10.将稀疏亲和子矩阵作为二部图,对二部图进行划分,得到多个基聚类结果;
11.基于三阶张量,将基聚类结果集成到一个统一的集成聚类框架中,得到最终的聚类结果,实现工业燃煤锅炉的工况划分。
12.进一步的,从运行状态数据中随机选择多个候选代表,对于多个候选代表,使用密度峰值聚类方法获得多个聚类中心点作为代表点。
13.进一步的,密度峰值聚类方法根据数据点的局部密度,以及从数据点到局部密度大于它的最近数据点的距离确定聚类中心。
14.进一步的,进一步筛选代表点的数量,在筛选后的代表点上找到最近的代表,利用
k最近邻近似方法在最近的代表的相邻区域找到k个最近的代表。
15.进一步的,通过调整密度峰值聚类方法的阈值进一步筛选代表性点。
16.进一步的,二部图具有n+p节点,通过特征值和特征向量传递公式,将具有n+p个节点的二部图转移分割为具有p个节点的二部图;设具有p个节点的二部图求解特征问题时的前k个特征对表示为具有n+p个节点的二部图求解特征问题时的前k个特征对表示为特征值和特征向量传递公式为:
17.γi(2-γi)=λi,
18.其中,转移矩阵d
x
为对角矩阵,b为稀疏矩阵。
19.进一步的,通过叠加多个基聚类结果构造初始张量;将所述初始张量展开为一个矩阵,并将初始张量折叠到它的三个维度模式,得到三个展开矩阵;对三个展开矩阵进行奇异值分解:
20.y
(t)
=a
(t)
∑
(t)
(b
(t)
)
t
21.其中,y
(t)
为第t个展开矩阵;a
(t)
为左奇异矩阵;b
(t)
为右奇异矩阵;
22.减少包含左奇异矩阵a
(t)
的每个数组的维数;基于σ
(t)
中的奇异值,保持每个对应左奇异矩阵a
(t)
中的主导e
t
左奇异向量,得到的矩阵为最终聚类结果。
23.第二方面,本发明还提供了一种基于数据集成聚类的工业燃煤锅炉工况划分系统,包括:
24.数据采集模块,被配置为:获取工业燃煤锅炉的运行状态数据;
25.亲和矩阵构建模块,被配置为:基于运行状态数据,构建亲和矩阵;
26.稀疏亲和子矩阵构建模块,被配置为:针对构建亲和矩阵,依据混合代表近邻近似方法,构建稀疏亲和子矩阵;
27.聚类模块,被配置为:将稀疏亲和子矩阵作为二部图,对二部图进行划分,得到多个基聚类结果;
28.划分模块,被配置为:基于三阶张量,将基聚类结果集成到一个统一的集成聚类框架中,得到最终的聚类结果,实现工业燃煤锅炉的工况划分。
29.第三方面,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现了第一方面所述的基于数据集成聚类的工业燃煤锅炉工况划分方法的步骤。
30.第四方面,本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了第一方面所述的基于数据集成聚类的工业燃煤锅炉工况划分方法的步骤。
31.与现有技术相比,本发明的有益效果为:
32.1、本发明通过混合代表近邻近似、二部图分割和三阶张量集成三个步骤,对工业燃煤锅炉数据进行集成聚类操作,对锅炉数据实现有效的工况划分;具体的,通过混合代表近邻近似构建稀疏亲和子矩阵,可以解决传统的聚类方法计算时间复杂度太高,不能有效构建燃煤锅炉数据的亲和矩阵的问题,通过对二部图进行划分,减少了特征问题求解时间,
以及通过将多基聚类结果集成到一个统一的集成聚类框架中,在保持高效率的同时进一步提高了聚类的准确性和鲁棒性;通过混合代表近邻近似、二部图分割和三阶张量集成三个步骤,极大的降低了传统的聚类方法计算时间的复杂度;
33.2、本发明的最终聚类结果,可以为工人调节锅炉参数提供了辅助决策,实现更有效的故障检测,节能减排,提高锅炉生产的安全性。
附图说明
34.构成本实施例的一部分的说明书附图用来提供对本实施例的进一步理解,本实施例的示意性实施例及其说明用于解释本实施例,并不构成对本实施例的不当限定。
35.图1为本发明实施例1的流程图;
36.图2为本发明实施例1的dpc一次计算两次选择代表点解释图;
37.图3为本发明实施例1的代表集合r和一个对象xi∈x;
38.图4为本发明实施例1的进一步筛选后的代表点和一个对象xi∈x;
39.图5为本发明实施例1的xi和筛选后的代表点之间的距离;
40.图6为本发明实施例1的xi的最近的代表点r
l
;
41.图7为本发明实施例1的xi和r
l
的k`个最近邻之间的距离;
42.图8为本发明实施例1的xi的k个最近代表(k=3);
43.图9为本发明实施例1的三阶张量集成过程的可视化。
具体实施方式:
44.下面结合附图与实施例对本发明作进一步说明。
45.应该指出,以下详细说明都是示例性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
46.锅炉生产的主要步骤是:先通过给煤机驱动,向炉膛内不断送入煤炭并让其在炉膛内燃烧,通过送风机,向炉膛不断送入燃烧所需要的氧气,并通过控制风量来控制炉膛燃烧的温度,炉膛燃烧产生的热量对汽包进行加热,汽包内会产生大量高温高压的蒸汽,而后吹动汽轮机转动进行发电。一个个的生产环节构成了燃煤锅炉的运行状态数据,而这些生产环节中的运行状态数据包括汽包压力、主汽温度、料层温度、一次风量和烟气含氧量等数据。
47.根据申请人对锅炉生产的调研以及与一线工人的交流后发现,虽然每年的锅炉热电生产都是使用的同一个锅炉,但是因为锅炉设备老化,检修的缘故,其实每年锅炉设备的工况都是不一样的。通过往年的历史数据分析研究得到的规律以及模型,可能并不适用于第二年锅炉的设备工况。保障锅炉的工作状态处于稳定是至关重要的,所以实际上工人需要时时刻刻监控锅炉的工作生产过程中的状态以及及时调整。就比如汽包的压力、燃料层的温度、烟气的含氧量、给煤机的转速等环节,都是对锅炉状态的稳定非常重要的环节,也是使锅炉正常安全工作的保证和前提,需要时刻监控的这些参数并做出相应的调整。
48.实施例1:
49.本实施例提供了一种基于数据集成聚类的工业燃煤锅炉工况划分方法,包括:
50.获取工业燃煤锅炉的运行状态数据;
51.基于运行状态数据,构建亲和矩阵;
52.针对构建亲和矩阵,依据混合代表近邻近似方法,构建稀疏亲和子矩阵;
53.将稀疏亲和子矩阵作为二部图,对二部图进行划分,得到多个基聚类结果;
54.基于三阶张量,将基聚类结果集成到一个统一的集成聚类框架中,得到最终的聚类结果,实现工业燃煤锅炉的工况划分。
55.可以理解的,所述运行状态数据可以为采集的燃煤锅炉生产工作过程中产生的状态数据;基于状态数据,对燃煤锅炉数据进行工况划分,其能够提高锅炉数据工况划分的准确性,为工人在燃煤锅炉运行过程中的参数调控操作起到辅助优化的作用;采集数据后,本实施例的具体内容为:
56.s1、混合代表近邻近似:采用随机选择和密度峰值聚类算法(clustering by fast search and find of density peaks,dpc)结合的混合代表选择策略来选择代表性点,从而缩减数据的规模,然后利用k最近邻近似方法快速有效的获得样本点的k个最近的代表,并将其他代表归零,进一步稀疏亲和子矩阵。
57.对于采集整合后的大规模燃煤锅炉数据,需要根据数据之间的相似性,构建亲和矩阵。然而传统的聚类方法计算时间复杂度太高,不能有效构建燃煤锅炉数据的亲和矩阵。因此实施例提供一种混合代表近邻近似方法来快速有效构建稀疏亲和子矩阵;首先通过随机选择和密度峰值聚类算法结合的混合代表选择策略来选择代表性点,然后利用k最近邻近似方法快速有效地获得样本点的k个最近的代表,并将其他代表归零,进一步稀疏亲和子矩阵。
58.设x={x1,x2,...,xn}表示一个包含n个对象的燃煤锅炉数据集,其中xi∈rd是第i个对象,d是维数。首先,从锅炉数据中随机选择p`个候选代表,以减少时间成本(p`《《n),然后,对于p`个候选点,本实施例使用dpc方法获得p个聚类中心点,并使用聚类中心点作为代表点。dpc根据ρi和δi确定聚类中心;数据点的局部密度为ρi,从数据点到局部密度大于它的最近数据点的距离为δi。
[0059][0060][0061]
ρi·
δi》ε
ꢀꢀꢀꢀ
(3)
[0062]
其中,d
ij
为数据点i与数据点j之间的距离;dc为截止距离;χ为逻辑判断函数;ε为阈值,本实施例中定义,当一个数据点的ρi和δi的乘积大于阈值ε时,该点是聚类中心,因此,可以通过调整阈值ε来控制聚类中心的数量。在形式上,本实施例将选定的代表的集合表示为:
[0063]
r={r1,r2,..r
p
}
ꢀꢀꢀꢀ
(4)
[0064]
在获得p个代表后,下一个目标是通过一个小的代表集对整个数据集的成对关系进行编码。本实施例中采用了一种基于粗到细机制的k最近邻近似方法,构造了一个稀疏亲和子矩阵。本实施例中的k最近代表近似的主要思想是,首先进一步筛选代表点的数量,然后在筛选后的代表点上找到最近的代表,记为r
l
,然后在r
l
的相邻区域找到k个最近的代表。
本实施例通过调整dpc的阈值ε来进一步筛选代表性点,这样可以通过一次计算进行两次选择,降低了时间复杂度。通过得到每个对象的k个最近代表,可以构造稀疏n
×
p的稀疏亲和子矩阵。本实施例采用高斯核作为相似度核,因此,稀疏亲和子矩阵可以表示为:
[0065]
b={b
ij
}n×
p
ꢀꢀꢀꢀ
(5)
[0066][0067]
其中,nk(xi)表示xi的k个最接近代表的集合;核参数σ被设置为对象和它们的k个最近代表之间的平均欧氏距离;b是一个稀疏矩阵,它只包含nk个非零项。
[0068]
如图2所示,为dpc一次计算两次选择代表点解释图,第一次选择代表点设置阈值ε=4000,选择出1000个代表点,如蓝线的右上区域所示,第二次选择设置阈值ε=12000,进一步选择出7个代表点,如红线的右上区域所示,该方法减少了寻找样本点最近代表点的计算量。
[0069]
s2、二部图分割:稀疏亲和子矩阵反映了数据对象与代表点之间的关系,可以自然地解释为二部图,利用二部图的结构,可以利用传递切割有效地对图进行划分,得到最终的聚类结果。
[0070]
稀疏亲和子矩阵b反映了x中的对象与r中的代表之间的关系,可以自然地解释为二部图g={x,r,b},其中,xur是节点集(u表示x和r两个集合作并集运算),b是交叉亲和矩阵。利用二部图的结构,可以利用转移切割有效地对图进行划分,得到最终的聚类结果。
[0071]
首先,如果把二部图g看作是一个具有n+p节点的一般图,那么它的全亲和矩阵可以记为:
[0072][0073]
聚类试图通过求解以下广义特征问题来对图进行划分:
[0074]
lu=γdu
ꢀꢀꢀꢀ
(8)
[0075]
其中,l=d-e是二部图g的拉普拉斯算子,d=r
(n+p)
×
(n+p)
是度矩阵;γ为特征值;u为特征向量。通过将二部图g作为一般图,需要o((n+p)3)的时间复杂度来解决特征问题等式(8),它在非常大规模的锅炉数据集上不可行,o是时间复杂度的代表符号。
[0076]
因此,本实施例中使用转移切割来减少特征问题求解时间,求解二部图g的特征问题转移到求解一个更小的图gr上的特征问题,二部图g有n+p个节点,图gr有p个节点。具体来说,图gr={r,er},其中,r是代表点集;是亲和矩阵,d
x
∈rn×n是对角矩阵,对角线上的数是b对应每行数目的总和。lr=d
r-er是拉普拉斯算子,dr∈r
p
×
p
是gr的度矩阵。然后,将图gr上的广义特征问题可以表示为
[0077]
lrv=λdrv
ꢀꢀꢀꢀ
(9)
[0078]
设特征问题(9)的前k个特征对表示为特征问题(8)的前k个特征对表示为特征值和特征向量传递公式为:
[0079]
γi(2-γi)=λiꢀꢀꢀꢀ
(10)
[0080]
[0081][0082]
其中,为转移矩阵;在求解特征问题后,将得到的k个特征向量堆叠成一个(n+p)
×
k矩阵。将矩阵的每一行作为一个新的特征向量,利用对应于n原始对象的n行,在此基础上进行k-means,得到最终的聚类结果。
[0083]
s3、三阶张量集成:为在保持高效率的同时进一步提高聚类的准确性和鲁棒性,本实施例中,将多基聚类结果集成到一个统一的集成聚类框架中,进一步提高聚类的准确性和鲁棒性。三阶张量集成主要利用张量分解的优势来挖掘数据的隐藏层信息,从而获得更好、更鲁棒的一致聚类。
[0084]
本实施例提供了一种基于三阶张量的集成算法,将多基聚类结果集成到一个统一的集成聚类框架中,旨在在保持高效率的同时进一步提高聚类的准确性和鲁棒性。三阶张量集成主要利用张量分解的优势来挖掘数据的隐藏层信息,从而获得更好、更鲁棒的一致聚类。每个基聚类都由一定数量的簇组成。本实施例中将每个基聚类中的簇表示为
[0085]
c={c1,c2,
…
,ck}
ꢀꢀꢀ
(13)
[0086]
其中,ci是基簇中的第i个簇,k是基簇中的簇数。基聚类的结果可以表示为:
[0087]
w={w
ij
}n×kꢀꢀꢀꢀ
(14)
[0088][0089]
其中,w是一个稀疏矩阵,它只包含n个非零的项。根据五个主要步骤,本实施例得到了一个更好的聚类结果:
[0090]
s3.1、张量y的初始构造:本实施例可以得到一个初始的三阶张量其中,通过叠加p个基聚类结果来构造张量y∈rn×k×
p
。
[0091]
s3.2、张量y的矩阵展开:通过将y对应的单位元素排列为y
(t)
的列,t=1、2、3,张量y可以展开为一个矩阵。初始张量y可以折叠到它的三个维度模式。y
(1)
∈rn×
kp
,y
(2)
∈rk×
np
,y
(3)
∈r
nk
×
p
。
[0092]
s3.3、每个展开矩阵上的奇异值分解(svd):三个展开矩阵y(t)(t=1、2、3)的svd分解:
[0093]y(t)
=a
(t)
∑
(t)
(b
(t)
)
t
t=1,2,3
ꢀꢀꢀꢀ
(16)
[0094]
为了更好地显示不同基聚类结果之间的潜在关联,必须减少包含左奇异矩阵a
(t)
(t=1,2,3)的每个数组的维数。基于σ
(t)
中的奇异值,保持每个对应矩阵a
(t)
(t=1,2,3)中的主导e
t
左奇异向量,所得到的矩阵是参数e
t
的值通常是通过σ
(t)
中的知识来选择的。
[0095]
s3.4、核心张量g的构造:三种不同模态之间的相关性可以由核心张量g来主导,并被执行:
[0096][0097]
这里y是初始张量,
×
t
表示三阶张量的模乘法,是的转置,g是e1×
e2×
e3的张量。
[0098]
s3.5、重构的张量y`:这一步验证了重构的张量与原始张量相似。重构的张量y`:
[0099][0100]
y`近似于y,这意味着很小。此外,不同基聚类结果之间的潜在关联包含在左奇异向量的一个子集中。最后,聚类结果wf表示为
[0101]
三阶张量集成的结果与模糊聚类的结果相似。矩阵中每一行的值为样本点属于一个簇的概率,一行中最大值对应的聚类为样本点所属的簇。因此,最终的聚类结果表示为
[0102]
wf={wf
ij
}n×kꢀꢀꢀꢀ
(19)
[0103][0104]
其中,wf
ij
的值为1代表第i个样本点属于第j个簇,wf
ij
值为0代表第i个样本点不属于第j个簇,最终wf只包含n个非零的项;可以理解的,公式(20)就是把矩阵wf每一行的最大值变为1,其余变为0。
[0105]
本实施例可针对工业燃煤锅炉生产工作的过程产生的状态数据进行处理,设计了相应算法流程,获取燃煤锅炉生产过程中各个参数和运行工况之间的关系,为工人调整参数,保持燃煤锅炉高效运行提供了合理的科技支持。为燃煤锅炉数据提供最近代表近邻近似方法,缩减数据的规模,快速有效构造数据之间的稀疏亲和子矩阵,从而通过二部图分割获得聚类结果,然后提供基于三阶张量的集成方法优化聚类结果,提高燃煤锅炉工况划分的准确性。
[0106]
实施例2:
[0107]
本实施例提供了一种基于数据集成聚类的工业燃煤锅炉工况划分系统,包括:
[0108]
数据采集模块,被配置为:获取工业燃煤锅炉的运行状态数据;
[0109]
亲和矩阵构建模块,被配置为:基于运行状态数据,构建亲和矩阵;
[0110]
稀疏亲和子矩阵构建模块,被配置为:针对构建亲和矩阵,依据混合代表近邻近似方法,构建稀疏亲和子矩阵;
[0111]
聚类模块,被配置为:将稀疏亲和子矩阵作为二部图,对二部图进行划分,得到多个基聚类结果;
[0112]
划分模块,被配置为:基于三阶张量,将基聚类结果集成到一个统一的集成聚类框架中,得到最终的聚类结果,实现工业燃煤锅炉的工况划分。
[0113]
所述系统的工作方法与实施例1的基于数据集成聚类的工业燃煤锅炉工况划分方法相同,这里不再赘述。
[0114]
实施例3:
[0115]
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现了实施例1所述的基于数据集成聚类的工业燃煤锅炉工况划分方法的步骤。
[0116]
实施例4:
[0117]
本实施例提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了实施例1所述的基于数据集
成聚类的工业燃煤锅炉工况划分方法的步骤。
[0118]
以上所述仅为本实施例的优选实施例而已,并不用于限制本实施例,对于本领域的技术人员来说,本实施例可以有各种更改和变化。凡在本实施例的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本实施例的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1