一种面向企业服务总线的日志分段式持久化系统及方法与流程
1.本发明涉及信息技术领域,具体涉及一种面向企业服务总线的日志分段式持久化系统及方法。
背景技术:
2.如今随着微服务的蓬勃发展,一个的服务越来越多,各个服务之间的调用也越来越复杂,相互之间的关联也越来越紧密,当一个服务出现问题之后对于问题的排查也越来越困难,使运维及开发人员花费大量的时间来进行日志的查找与定位工作。为此,提出一种面向企业服务总线的日志分段式持久化系统及方法。
技术实现要素:
3.本发明所要解决的技术问题在于:当某个能力节点出现异常或响应超时时,如何能够获取已完成的正常能力节点日志信息,进而使运维人员能够及时跟踪排查异常,实现对问题的快速定位,提供了一种面向企业服务总线的日志分段式持久化系统。
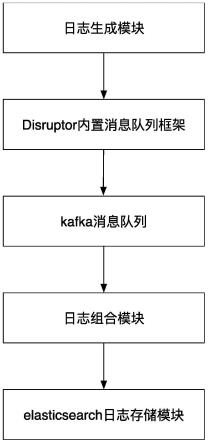
4.本发明是通过以下技术方案解决上述技术问题的,本发明包括日志生成模块、内置队列、分布式消息队列、日志组合模块、日志存储模块;
5.所述日志生成模块,用于在每个请求开始时、能力节点处理时、请求结束时分别生成请求接收日志、能力节点处理日志、请求响应日志,并将请求接收日志、能力节点处理日志、请求响应日志分别存储到三个不同的内置队列对象中;
6.所述内置队列,用于配置生产者、消费者模式以发送、接收、处理日志消息;
7.所述分布式消息队列,用于从内置队列中取出请求开始时、处理时、结束时的日志对象来进行消费;
8.所述日志组合模块,用于从kafka中消费日志信息,并且根据日志id对日志存储模块中的日志进行更新或添加操作,完成对相同的日志id对应的日志对象进行多段式日志的组合;
9.所述日志存储模块,用于收集并存储日志组合模块中根据日志id生成的日志对象,供平台运营维护人员对日志进行检索与读取。
10.更进一步地,在所述日志生成模块中,每个请求生成的日志均有一个相同的日志id。
11.更进一步地,在所述日志生成模块中,在请求开始时,根据从服务网关获取的服务名称、服务编码、服务所关联的应用名称和应用编码、认证方式、持久化策略信息生成请求接收日志;在能力节点处理时,根据请求服务中包含的各个能力节点的节点类型、节点名称、报文列表、报文体、报文大小信息生成能力节点处理日志;在请求结束时,根据处理此服务的时间、接收报文的时间、日志产生的时间信息生成请求响应日志。
12.更进一步地,所述内置队列为disruptor内置消息队列框架,将日志生成模块中的请求接收日志、能力节点处理日志、请求响应日志存到其框架中内置的ringbuffer环状队
列中,以实现异步处理日志信息。
13.更进一步地,所述分布式消息队列为kafka消息队列,每个内置队列对象对应kafka消息队列中不同的主题。
14.更进一步地,在所述日志组合模块中,从kafka消息队列中消费日志信息,并且根据日志id生成一篇包含请求接收日志、能力节点处理日志、请求响应日志的完整的日志信息。
15.更进一步地,所述日志存储模块基于分布式全文搜索引擎elasticsearch实现,具备实时搜索、对日志的分析及处理能力。
16.本发明还提供了一种面向企业服务总线的日志分段式持久化方法,采用上述的系统实现日志分段式持久化,包括以下步骤:
17.s1:在每个请求开始时、能力节点处理时、请求结束时产生日志,每个请求产生的日志均有一个相同的日志id,请求接收日志、能力节点处理日志、请求响应日志会分别存储到三个不同的内置队列对象中;
18.s2:s2:通过disruptor内置消息队列用来接收、处理消息日志;
19.s3:通过kafka消息队列来对内置队列中的日志对象进行消费;
20.s4:从kafka消息队列中消费日志信息,并且根据日志id对日志存储模块中的日志进行更新或添加操作,完成对相同的日志id对应的日志对象进行多段式日志的组合;
21.s5:收集日志组合模块中根据日志id生成的日志对象存储到日志存储模块中。
22.更进一步地,所述步骤s2包括以下子步骤:
23.s21:在spring中创建disruptor框架中ringbuffer类的bean,即为内置消息队列对象;
24.s22:创建内置消息队列生产者disruptorproducer对象,在该disruptorproducer对象中调用ringbuffer对象的publishevent方法,参数为日志数据,达到将数据发送至内置消息队列的目的;
25.s23:创建内置消息队列生产者对象,在该生产者对象中调用ringbuffer对象的publishevent方法,参数为日志数据,达到将数据发送至内置消息队列的目的;
26.s24:创建内置消息队列消费者对象,该消费者继承为disruptor框架中eventhandler类,重写onevent方法来对内置消息队列中的日志数据进行消费处理。
27.本发明相比现有技术具有以下优点:该面向企业服务总线的日志分段式持久化系统及方法,对资源日志进行多段式处理使得某个能力节点出现异常或响应超时时,日志存储模块能够获取已完成的正常能力节点日志信息,经过处理存到elasticsearch中,使运维人员能够及时跟踪排查异常,实现对问题的快速定位;并且日志的持久化方式是通过disruptor内置队列异步进行的,即当kafka消息队列消费日志信息时,系统对于网关的调用和日志的处理是在同步进行的,大大提高了服务网关调用以及日志存储的效率,值得被推广使用。
附图说明
28.图1是本发明实施例一中日志分段式持久化系统的结构示意图。
具体实施方式
29.下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
30.实施例一
31.如图1所示,本实施例提供一种技术方案:一种面向企业服务总线的日志分段式持久化系统,包括日志生成模块、内置队列、kafka消息队列、日志组合模块、elasticsearch日志存储模块。
32.本实施例中,在所述日志生成模块中,在请求开始时,将从服务网关获取的服务名称、服务编码、服务所关联的应用名称和应用编码、认证方式、持久化策略等字段信息初始化构成请求接收日志。在对能力节点进行处理时,将请求服务中包含的各个能力节点的节点类型、节点名称、报文列表、报文体、报文大小等字段信息(特别的:如果节点类型是http资源则包括请求的header头、请求的url等字段信息,如果节点类型是groovy脚本则包括脚本处理时间等字段信息)构成能力节点处理日志,在请求结束时,将处理此服务的时间、接收报文的时间、日志产生的时间等字段信息填充构成请求响应日志。
33.本实施例中,在所述disruptor内置消息队列框架中,此框架是用于一个jvm(java虚拟机)中多个线程之间的高性能队列,能够在无锁的情况下实现网络的队列并发操作,通过配置类定义生产者模式用来发送消息,设置消费者处理器处理生产者发送来的消息。此模块将日志生成模块中的请求接收日志、能力节点处理日志、请求响应日志存到其框架中内置的ringbuffer环状队列中去,以达到异步处理日志信息的目的。
34.本实施例中,在所述kafka消息队列(分布式消息队列),采用kafka消息队列从内置队列中取出请求开始时、处理时、结束时的日志对象来进行消费,每个内置队列对象对应kafka消息队列中不同的主题topic。
35.本实施例中,在所述日志组合模块中,此模块从kafka中消费日志信息,并且根据日志id生成一篇包含请求接收日志、能力节点处理日志、请求响应日志完整的日志信息。
36.本实施例中,所述elasticsearch日志存储模块,此模块是一个分布式全文搜索引擎,提供了实时搜索、可靠、稳定、快速的海量日志的分析及处理能力。
37.本实施例中还提供了一种基于上述面向企业服务总线的日志分段式持久化方法,包括以下步骤:
38.s1:企业服务总线的服务通过多个能力编排组合而成,在每个请求开始时、能力节点处理时、结束时均会产生日志,每个请求产生的日志均有一个相同的日志id,请求接收日志、能力节点处理日志、请求响应日志会分别存储到三个不同的内置队列对象中;
39.s2:通过内置消息队列框架来配置生产者、消费者模式用来发送、接收、处理消息日志;
40.s3:通过kafka消息队列来对内置队列中的日志对象进行消费;
41.s4:从kafka消息队列中消费日志信息,并且根据日志id对elasticsearch日志存储模块中的日志进行更新或添加操作,完成对相同的日志id对应的日志对象进行多段式日志的组合;
42.s5:收集日志组合模块中根据日志id生成的日志对象存储到elasticsearch日志
存储模块中;
43.在本实施例中,所述步骤s2包括以下子步骤:
44.s21:在spring中创建disruptor框架中ringbuffer类的bean,即为内置消息队列对象;
45.s22:创建内置消息队列生产者disruptorproducer对象,在该disruptorproducer对象中调用ringbuffer对象的publishevent方法,参数为日志数据,达到将数据发送至内置消息队列的目的;
46.s23:创建内置消息队列生产者对象,在该生产者对象中调用ringbuffer对象的publishevent方法,参数为日志数据,达到将数据发送至内置消息队列的目的;
47.s24:创建内置消息队列消费者对象,该消费者继承为disruptor框架中eventhandler类,重写onevent方法来对置消息队列中的日志数据进行消费处理。
48.实施例二
49.在本实施例中,用户配请求服务a,服务编码servicea,调用方为consumera,请求结束后查询调用日志,调用日志分为请求开始时、能力节点处理时、请求结束时三个部分,每个部分记录了请求头、请求报文内容、请求报文大小、请求耗时等信息,同时记录了调用方名称、服务名称、服务编码、调用时间等信息,直观清晰地反映了整个调用过程。
50.除上述实施方式外,本实施例中的其余实施方式均与实施例一相同。
51.综上所述,上述实施例的面向企业服务总线的日志分段式持久化系统,对资源日志进行多段式处理使得某个能力节点出现异常或响应超时时,日志存储模块能够获取已完成的正常能力节点日志信息,经过处理存到elasticsearch中,使运维人员能够及时跟踪排查异常,实现对问题的快速定位;并且日志的持久化方式是通过disruptor内置队列异步进行的,即当kafka消息队列消费日志信息时,系统对于网关的调用和日志的处理是在同步进行的,大大提高了服务网关调用以及日志存储的效率,值得被推广使用。
52.尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1