基于自学习规则运算的铁路货运大数据可视化展示平台
1.本发明涉及大数据技术领域,尤其涉及一种基于自学习规则运算的铁路货运大数据可视化展示平台。
背景技术:
2.数据是21世纪最重要的资产,是数字经济时代的核心生产要素。随着我国铁路网规模、技术装备水平的快速发展,铁路货运积累了丰沃的数据,然而铁路货运的大量数据尚未转化成高质量提升生产效率的数据资产。
3.如今我国产业结构调整升级,能源结构向绿色低碳转型,铁路货运既面临传统运输优势与我国经济发展趋势不适配的挑战,又同时迎来可持续交通发展的机遇。由此,市场对铁路货运的敏捷性、灵活性和个性化提出了更高的要求。精准对接市场需求,深刻洞察市场趋势是数字经济赋能铁路货运营销的首要目标。
4.目前铁路货运运营决策依据多源于决策者丰富的工作经验,而在数字经济时代,从历史数据中挖掘和提取的信息能够给出更客观、全面的判断依据,然而因工具和技术受限,大多数数据挖掘成果停留在文本阶段,难以转化成辅助现实实践决策的实用工具。
5.大数据可视化技术通过计算机系统获取企业数据并进行分析处理后生成人机交互的图像形式,帮助决策者迅速获得大规模复杂数据的有效信息。铁路货运数据结合大数据可视化技术能够帮助决策者在短时间内查看大量数据并获得对现实运营情况的高效监测和深入洞察。同时,大数据可视化平台的交互式特征可辅助决策者识别运营数据中尚未被发现的数据走势和关系。因此,研发应用于铁路货运的大数据可视化分析展现平台既是提高铁路货运运营决策科学性、前瞻性的核心诉求,也是在我国经济进入新发展阶段下铁路货运实现数字化升级的当务之急。
技术实现要素:
6.为了克服现有技术的上述缺点,本发明提出了一种基于自学习规则运算的铁路货运大数据可视化展示平台,能够直观展示数据的价值信息点,便于使用者探索未知数据组合信息,有助于使用者全面、客观、高效地洞察铁路货运运行情况,精准对接市场需求,为铁路货运科学决策提供支持。
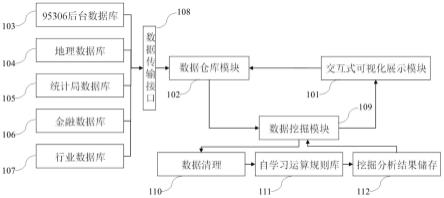
7.本发明解决其技术问题所采用的技术方案是:一种基于自学习规则运算的铁路货运大数据可视化展示平台,包括交互式可视化展示模块、数据仓库模块、数据传输接口和数据挖掘模块,其中:
8.所述数据仓库模块响应用户通过交互式可视化展示模块提交的查询信息,通过数据传输接口并行提取铁路货运电子商务平台后台数据库、地理数据库、统计局数据库、金融数据库和行业数据库的数据,并将提取的数据通过数据传输接口传送至数据挖掘模块;
9.所述数据挖掘模块包括数据清理模块、自学习规则运算模块和挖掘结果存储模块,用于清理数据仓库模块提取的数据,并结合交互式可视化展示模块的查询数据,运用基
于lstm的铁路货运运价率波动预测算法、基于集成学习的铁路货运客户流失预警算法、基于cnn-lstm的铁路区域货运量短期预测算法构成自学习规则运算库进行训练,然后通过挖掘结果存储模块对挖掘结果进行存储,并返回挖掘结果于交互式可视化展示模块。
10.与现有技术相比,本发明的积极效果是:
11.本发明提供的基于自学习规则运算的铁路货运大数据可视化展示平台能够实现对铁路货运总体情况、货物分布、货物流动、货物预测、客户分类、客户流动和货运运价七个方面的刻画,同时数据挖掘模块能够实现上述内容的智能分析,从海量数据中挖掘分析出辅助铁路货运科学决策的高价值信息。并通过大数据可视化和交互式方式给使用者提供高效、全面、直观的使用体验,为使用者迅速提供对高价值信息的高效洞察力。平台的研发是对铁路货运数据资产的高效率转化,助力铁路货运运营效率的提升。
12.本发明能够实时获取货票数据,并在结合地理数据的基础上,根据铁路局货运部门运营决策需求,对海量数据挖掘分析得到关键信息,再针对关键数据进行可视化图像设计,兼具交互式体验效果,为铁路货运的科学管理和正确决策提供了高效、全面、直观的信息支撑。该平台的应用大大提高了铁路货运的数据利用率,数据利用率平均提升85%,提高运营决策效率约60%。
附图说明
13.本发明将通过例子并参照附图的方式说明,其中:
14.图1为铁路货运的大数据可视化分析展现平台的功能结构图。
15.图2为铁路货运的大数据可视化分析展现平台的主页面结构图。
16.图3为铁路货运的大数据可视化分析展现平台的总体情况页面结构图。
17.图4为铁路货运的大数据可视化分析展现平台的货物分布页面结构图。
18.图5为铁路货运的大数据可视化分析展现平台的货物流动页面结构图。
19.图6为铁路货运的大数据可视化分析展现平台的货物预测页面结构图。
20.图7为铁路货运的大数据可视化分析展现平台的客户分类页面结构图。
21.图8为铁路货运的大数据可视化分析展现平台的客户流动页面结构图。
22.图9为铁路货运的大数据可视化分析展现平台的货运运价页面结构图。
具体实施方式
23.一种基于自学习规则运算的铁路货运大数据可视化展示平台,如图1所示,包括:交互式可视化展示模块101、数据仓库模块102、铁路货运电子商务平台后台数据库103、地理数据库104、统计局数据库105、金融数据库106、行业数据库107、数据传输接口108、数据挖掘模块109、数据清理模块110、自学习规则运算模块111、挖掘分析结果存储模块112等。
24.用户在交互式可视化展示模块101提交查询时间段选择项201和所属路局选择项202作为后续页面内容的基础,数据仓库模块102响应以上查询信息后通过数据传输接口108,并行提取95306铁路货运电子商务平台后台数据库103有关货票数据、地理数据库104相关数据、统计局数据库105相关数据、金融数据库106相关数据、行业数据库107相关数据,再通过数据传输接口108传达至数据挖掘模块109,在该模块内通过数据清理模块110进行数据清理,再通过自学习规则运算模块111的简易数学模型算法、聚类分析算法、基于多变
量lstm的铁路货运运价率波动预测算法、基于集成学习的铁路货运客户流失预警算法、基于cnn-lstm的铁路区域货运量短期预测算法构成自学习运算规则库进行训练,得到的挖掘分析结果在存储模块112暂为储存,预备除主页面以外的其他页面的功能模块数据请求,当交互式可视化展示模块101有相应的数据查询请求时返回结果。
25.所述的数据仓库模块包括:接入95306铁路货运电子商务平台后台数据库,提取主体单位为货票、时间颗粒度为日的数据集;地理数据,经纬度数据、省市区域数据、各铁路局集团公司的管辖区域数据。
26.所述数据传输接口,用于同步进行多端口数据并行采集和传输。
27.所述的数据挖掘模块,提取、清理数据仓库数据,结合交互式可视化展示模块的查询数据,运用聚类分析算法包、神经网络算法包形成各页面的功能模块的自学习运算规则库,返回挖掘结果于交互式可视化展示模块。
28.所述的可视化展示模块包括:主页面、总体情况页面、货物分布页面、货物交流页面、货运量情况页面、客户流动页面、客户分类页面、货运运价页面。
29.所述主页面为用户初始进入页面,包括查询时间段选择项,所属路局选择项,后续页面选择项。
30.所述查询时间段选择项,查询时间段选择起始年和终点年,后续页面中的时间轴以该时间段为基础。
31.所属后续页面选择项,跳转后续总体情况页面、货物分布页面、货物交流页面、货物预测页面,客户流动页面、客户分类页面。
32.所述总体情况页面有助于使用者对货运全局情况的了解,包括:时间轴、货物主品类选项、货站选项、货票总金额、总里程、货票单数、计费重量、环比和同比计算数据。
33.所述货物主品类选项来源于《铁路货物运价规则》中的《铁路货物运输品名分类与代码表》,主品类代码和主品类名称。
34.所述货站选项即所属铁路局的各个站点名称。
35.所述货物分布情况页面结合地图数据和时间轴,便于使用者观察铁路货物各品类的时空分特征,了解各类货物地理分布情况、随时间演变情况以及黑货白货比例。页面包括:时间轴、货物主品类选项、观测类别选项、观测分层地图(精细到市)、各品类货物构成、黑货白货构成。
36.所述观测类别选项包括货票总金额、总里程、货票单数、计费重量。
37.所述观测分层地图展示所观测目标的观测类别数值,从数据仓库提取各站点经纬度和省市区域范围数据,以市为单位,加总各个市内各个站点的观测类别数据得到各市观测类别数值。结合使用者所选择的时间、货物品类选项和观测类别选项,运用自然断点法划分各市观测类别数值的组群,在地图上由深色至浅色对应各市观测类别数据集各组群数值的由大至小。
38.所述各品类货物构成选项,各品类货物来源于《铁路货物运价规则》中的《铁路货物运输品名分类与代码表》,主品类下的各品类代码和各品类名称。
39.所述黑货白货,黑货为石油、煤、焦炭和金属矿石等大宗稳定货物,白货为除黑货以外的其他货品。
40.所述货物流动情况页面展示各时间段货物在各个观测单位之间以及观测单位之
内的流动情况信息,便于管理者观察各观测单位货物的交流情况以及变动情况。页面包括:时间轴、观测类别选项、观测单位选项、各观测单位流入流出图、数据表格展示区域、数据表格展示选项、到发比例。
41.所述观测单位选项,各市、各铁路局集团公司、各站点。
42.所述货物流动情况页面的观测类别选项,可多选,货票总金额总和、货票单数总和、计费重量总和、总里程平均值。
43.所述数据表格展示区域,分上下两模块,上部分展示流入观测单位的同级别观测单位的名称、所属省、所属路局、观测类别选项,下部分展示流出观测单位的同级别观测单位的名称、所属省、所属路局、观测类别选项。
44.所属数据表格展示选项,升序、降序。
45.所述各观测单位流入流出图,结合观测单位选项和时间轴,从数据仓库提取各站点经纬度和铁路局管辖范围数据,以各路局为单位,将各单位货票o(origin,起点)—d(destination,终点))按经纬度划分至各个局的管辖区域内。以中国地图为底,由箭头-线组合展示流入和流出关系,线的粗细由观测类别选项数值的大小决定,图中所展示的流入/流出对象的数量由数据挖掘层运用dbscan聚类算法计算所观测类别的数值最大的组群的个体数量决定。
46.所述到发比例,起点和终点均在观测单位的观测类别对总体的占比,观测单位为站点时,默认该计算是在铁路局级别。
47.所述货运量情况页面结合地图数据和时间轴,便于使用者观察各区域过去和未来货运量变动情况。页面包括:时间轴、观测分层地图、区域货运量预测模型指标数据、货运量走势图。
48.所述货运预测页面的时间轴,固定最新时期为主页面登录日期,可选择观测的历史数据范围。
49.所述货物预测页面的观测分层地图,为主页面所选集团公司的管辖区域地图,以市为单位。
50.所述货物预测页面的区域货运量预测模型指标数据,为本发明自学习规则运算库中基于cnn-lstm的区域货运量短期预测模型中的指标数据,包括该区域(市)最大货运量运输商品所在行业的人数、第二产业增加值、年末总人口、当日平均运价、高速公路里程、gdp(国内生产总值,gross domestic product)、ppi(生产者价格指数,producer price index)。
51.所述货运量走势图,包括所选取时间轴的历史货运量时间序列折线图,以及通过调用自学习规则运算库中基于cnn-lstm的区域货运量短期预测算法,以用户登录时间为节点预测未来7天该区域的货运量走势图。
52.所述客户分类情况页面展示各类客户的消费信息包括,各类客户、各类客户最近一次消费时间间隔天数、各类客户消费频率、各类客户货票总金额占比、各类客户代码及预警信息。
53.所述各类客户,在数据挖掘模块运用k-means算法综合聚类分析各个客户r(recently)最近一次购买时间间隔、f(frequency)消费频率、m(monetary)货票总金额的分布情况。再划分出的各大类客户,将各类铁路货运客户的各指标均值与总体均值相比较,单
个指标对比存在大于(含等于)或小于均值两种可能结果。对于单个类别铁路货运客户的均值大于总体均值,标记为1,反之则标记为0。归一化流失指数(r)、归一化次数(f)和归一化金额(m)3项指标,将客户划分为2*2*2=8类,分别为:(1)重要价值客户(r1f1m1):这类客户较为稳定,同时货运次数和货运金额都很高,是最优质客户;(2)重要唤回客户(r0f1m1):这类客户发货频率和货运金额都比较大,但最近运送间隔时间较长,需要唤回;(3)重要深耕客户(r1f0m1):最近比较稳定且货运金额高,但货运次数低,需要深耕;(4)重要挽留客户(r0f0m1):货运金额高,但频率低且最近无运送,有流失风险,需要重点挽留;(5)一般价值客户(r1f1m0):最近有运送且货运频率高,但货运金额低,客户潜力需要挖掘;(6)一般唤回客户(r0f1m0):货运次数高,但货运金额低且最近无货运,贡献度不大,只需一般维持即可;(7)一般深耕客户(r1f0m0):最近有运送,但货运次数和货运金额低,一般为新客户,有发展价值;(8)一般挽留客户(r0f0m0):最近无运送,且货运次数少、货运金额低,相当于流失客户。
54.所述各类客户最近一次消费时间间隔天数,离上次发货已有天数=使用者在总页面提交的时间范围的最新日期—最近一次发货的日期。
55.所述消费频率,在使用者在总页面提交的时间范围内,各类别客户总运输次数。
56.所述各类客户货票总金额占比,各类别客户在使用者在总页面提交的时间范围内货票总金额之和对总体的占比。
57.所述客户流动情况页面辅助管理者监测客户新旧交替和回流情况,页面包括:时间轴、回流客户数量、回流客户基础信息、新老客户数量、新老客户货票总金额比例构成。
58.所述回流客户数量,回流客户的数量随时间变化的情况。流失客户指距其最近一次发货的时间间隔已经超过其平均发货时间间隔,回流客户指已经标识为流失客户的客户又通过铁路发货的客户。
59.所述回流客户基础信息,回流客户数量、回流货物货票总金额和各个回流客户的代码。
60.所述新老客户数量变化情况,新/老客户的数量随时间变化的情况。新客户即指所观测时间点第一次发货且之前没有发货记录的客户;老客户则是有过发货记录的客户。
61.所述新老客户货票总金额比例构成,新/老客户货票总金额占总体的比例。
62.所述时间轴能调整各页面内容的观测时间,时间轴长度等于主页面所选择的时间段范围。时间轴设置时间滑块,时间轴的单元可以是时间点,也可以是时间段,时间段范围可以灵活选择。时间轴的数据粒度有日、周、月、季度、年。
63.所述货运运价情况页面辅助管理者和客户了解各类运输货物货运运价的波动情况,探索未来运价的走向。页面包括:时间轴、各品类货物选项、运价率相关要素数据、历史运价率走势图、未来运价率走势图构成。
64.所述货运运价情况页面的各品类货物选项,各品类货物来源于《铁路货物运价规则》中的《铁路货物运输品名分类与代码表》,主品类下的各品类代码和各品类名称。
65.所述运价率相关要素数据,为本发明自学习规则运算库中基于多变量lstm的铁路货运运价率预测模型中的指标数据,包括仓储价格指数、pmi(采购经理指数,purchase management index)、gdp(国内生产总值,gross domestic product)、零售商品价格指数、公路运价指数、公路货运量、运输货物产量、运输货物价格指数。
66.所述历史运价率走势图,为调用自学习规则运算库中基于多变量lstm的铁路货运运价率预测算法中运价率的计算方法,显示所选择时间轴范围内的该品类货物的历史运价率时间序列折线图。
67.所述未来运价率走势图,通过调用自学习规则运算库中基于多变量lstm的铁路货运运价率预测算法,以用户登录时间为节点预测未来7天该品类货物运价率的运价率时间序列折线图。
68.以下结合附图对各面页详细描述如下:
69.如图2所示,主页面在完成查询时间段选择项201,以及所属路局选择项202的前提下,选择后续页面选择项203。
70.如图3所示,当主页面后续页面选择项203选择总体情况页面时,(1)若仅选择时间轴301,将获得时间段内全品类所属路局的总体情况,货票总金额304、总里程305、货票单数306、计费重量307,这4个模块以趋势图形式展现,环比和同比计算数据308呈现具体数值;(2)若选择时间轴301和货站选项302,将获得时间段内各货站的总体情况;(3)若选择时间轴301和货物主品类选项303,将获得时间段内各主品类的总体情况;(4)若选择时间轴301、货站选项302和货物主品类选项303,将获得各站点各品类的总体情况;对于(2)、(3)、(4)的情形,均会同时呈现货票总金额304、总里程305、货票单数306、计费重量307、同比计算数据308的可视化结果。
71.如图4所示,当主页面后续页面选择项203选择货物分布页面时,(1)若选择时间轴401和观测类别选项403,可得到所属路局202的全局观测分层地图404、黑白货构成405、各品类构成406;(2)若选择时间轴401、观测类别选项403和货物主品类402,可得到所属路局202和货物主品类选项402下的全局观测分层地图404、黑白货构成405、各品类构成406,需要指出的是此时的各品类构成406为所选货物主品类402范围内;(3)若选择时间轴401、观测类别选项403和观测分层地图404内的任一地区拼图,将得到该地区该时间段观测类别的黑白货构成405、各品类构成406;(4)若选择时间轴401、观测类别选项403、观测分层地图404和货物主品类选项402,可得到该品类该地区该时间段观测类别的黑白货构成405、各品类构成406。
72.如图5所示,当主页面后续页面选择项203选择货物流动页面时,可选择时间轴501、观测类别选项502、观测单位选项503,将得到观测单位流入流出图504,互动点击504任一单元模块,得到到发比例505和数据表格展示区域信息流入507/流出508,通过点选数据表格展示选项506获得数据表格展示区域信息流入507/流出508的相应排序。
73.如图6所示,当主页面后续页面选择项203选择货物预测页面时,可选择时间轴601、观测分层地图选项602,选取观测分层地图选项602中的最小单位得到区域货运量预测模型指标数据603,调用自学习规则运算模块111中的基于cnn-lstm的铁路区域货运量短期预测算法,得出所选取时间轴的历史货运量时间序列折线图604,以及通过调用该算法进行预测的用户登录时间未来7天的区域货运量走势图605。其中:所述基于cnn-lstm的铁路区域货运量短期预测算法包括如下步骤:
74.步骤一:确定铁路区域货运量影响因素,建立影响因素指标集;包括内部影响因素和外部影响因素,其中外部影响因素又可分为宏观经济、大宗商品、交通运输结构、消费水平以及其他,基于灰色关联分析求解各影响因素与货运量的关联度,并根据关联度阈值选
取关键影响因素;
75.步骤二:建立影响因素数据仓库,从行业数据库、统计数据库、95306调取影响因素指标对应的数据,如国家和区域(省市)经济社会数据、其他交通方式数据以及铁路货运运价数据;
76.步骤三:将关键影响因素数据与货运量数据进行拼合得到组合序列,并进一步进行数据预处理,包括:归一化、重构为监督学习、划分训练集和测试集,构建多维数据集;
77.步骤四:构建基于cnn-lstm的铁路区域货运量近短期预测模型,设置模型初始参数值,使用训练集对cnn-lstm多变量预测模型进行超参数优化,得到最优模型;将测试集应用于训练好的预测模型,将预测值进行反归一化处理,使其与真实值处于同一量级,输出预测结果、输出预测误差曲线和真实值与预测值的拟合曲线图评估模型预测质量。
78.所述步骤一中建立的铁路区域货运量影响因素包含内部影响因素和外部影响因素。内部影响因素来源于指铁路货运系统内部,一般包括铁路基础设施建设、经营管理水平、铁路从业人员数量、铁路货运运价等。外部影响因素包括宏观经济、区域经济、大宗商品、交通运输结构,其中宏观经济包括gdp、第一产业增加值、第二产业增加值、第三产业增加值等;外部影响因素中的大宗商品包括煤炭、石油、钢铁、金属矿石、粮食、化肥等的产量和价格;外部影响因素中的交通运输结构包括公路货运量、水路货运量、航空货运量等;外部影响因素中的区域经济包括人口数量、居民消费水平、发电量、ppi等。需要注意的是,不仅仅局限于这些因素且这些因素也并非缺一不可,而是根据预测区域特征进行灵活增减。
79.所述步骤一中的灰色关联分析具体步骤如下:
80.(1)反映系统特征的参考数列为货运量y,y=y(k)|k=1,2,3,....n;影响系统特征的比较数列为影响因素xi,xi=xi(k)|k=1,2,3...n;i=1,2,3,...m;由于系统中原始数据列的计量单位和数量级不尽相同,为了使各数据列具有可比性,因而采用min-max法对原始数据列进行无量纲化处理,计算公式如下:
[0081][0082]
式中:min y为原始参考序列y中的最小值;max y为原始参考序列y中的最大值。
[0083][0084]
式中:minxi为原始比较序列xi中的最小值;maxxi为原始比较序列xi中的最大值。
[0085]
(2)计算各个比较数列与参考数列在第k点的关联系数,计算公式如下:
[0086][0087]
式中:|y(k)-xi(k)|为差序列;min
i mink|y(k)-xi(k)|和max
i maxk|y(k)-xi(k)|;ρ为分辨系数,取ρ=0.5。
[0088]
(3)将各个时刻的关联系数集中为一个值即关联度γi,计算公式如下:
[0089]
[0090]
(4)根据关联度γi数值的大小,将关联度进行排序,若γ1<γ2,则参考数列y与比较数列x2的相关性比x1更强。
[0091]
步骤三中的归一化采用min-max法,并使用滑动窗口将数据转化为监督学习形式。最后将前80%的数据作为训练集,余下的数据则作为测试集。
[0092]
所述步骤四的基于cnn-lstm的多变量铁路货运量预测模型其结构包括输入层、隐含层、输出层三层结构。首先,将数据组织为模型能够识别的形式并通过输入层导入模型。随后交给核心部分隐含层处理,其中cnn层解析货运量及其影响因素之间的关联特征,再使用lstm层提取序列数据在时间上的特征,最后通过dense层增加模型的复杂度,并将数据从高维映射到低维,保留有用信息。同时,在每层之后连接一个dropout层用于增强模型的鲁棒性并防止模型过拟合。最后,通过输出层输出预测值。
[0093]
所述步骤四的模型参数初始化,将卷积核的大小设置为3*3并采用平均池化,采用adam算法作为模型的优化算法,使用mse作为损失函数,激活函数采用relu,以及采用dropout方法防止模型过拟合。除此之外,还有步长、批量大小、迭代次数、filter数量、lstm层神经元个数等超参数,分别对各个超参数进行敏感性分析。在对某一个超参数进行敏感性分析时,固定其它超参数的取值不变。
[0094]
如图7所示,当主页面后续页面选择项203选择客户分类页面时,即可得到由数据挖掘模块106传导出来的各类客户701、各类客户最近一次消费时间间隔天数702、各类客户消费频率703和各类客户货票总金额占比704。使用者通过点选各类客户701任一单元模块,可得到相应的各类客户最近一次消费时间间隔天数702、各类客户消费频率703和各类客户货票总金额占比704的具体信息,以及该类客户的各客户代码和预警图示705。
[0095]
所述各类客户代码及预警信息,以两列表格形式展示,左侧为该类别客户的客户代码,右侧为通过调用自学习规则运算模块111中的基于集成学习的铁路货运客户流失预警算法得到的各客户流失概率和对应的流失预警颜色标识。其中:所述基于集成学习的铁路货运客户流失预警算法包括如下步骤:
[0096]
步骤1:提取待预测铁路货运客户查询时间前12月的历史发货订单原始数据集,并对原始数据集进行数据预处理;
[0097]
步骤2:构建铁路货运客户运单数据特征指标、通过特征相关性分析和重要性排序进行特征选择构建的铁路货运客户流失预测特征指标体系,处理原始数据集获得关键特征指标,并作为特征矩阵输入本模型;
[0098]
步骤3:基于客户行为数据信息具体定义铁路货运客户流失并对客户样本进行赋值得到铁路货运客户流失样本数据标签;
[0099]
步骤4:将铁路货运客户特征数据及客户样本标签整理为新数据集,按预设比例划分为训练集和测试集,并划分跨时间样本验证数据集,作为模型的输入数据集;
[0100]
步骤5:选取随机森林、gbdt、lightgbm作为基学习器以搭建第一层模型,使用k折交叉验证方法基于训练集生成训练好的基学习器,并将测试集输入训练好的基学习器,分别得到三个训练好的基学习器对测试集的预测结果;使用逻辑回归作为元学习器建立第二层模型,将三个训练好的基学习器对测试集的预测结果作为元学习器的特征值,由此形成stacking融合模型对目标特征进行预测并输出预测结果,得到待测客户的流失概率,并转化成客户流失预警颜色标识。其中:
[0101]
1.数据提取和预处理
[0102]
从95306后台数据中调取铁路货运货票数据,以货票编号、发货人代码、制票日期、主品名汉字、主品名代码、货票总金额、计费重量特征属性构建数据集,并对为空值且无法进一步获取的数据,采取直接删除法处理。进一步,以发货人代码为主键,将同一客户(发货人)的多条货票数据的特征属性整合。再通过观测数据集内客户发货行为的特征属性,发现仅有一次发货行为客户的发货量(计费重量)和货票金额较小,且无法反映客户流失的趋势,因此删除数据集中只存在一次发货行为记录的客户,最终选取不少于两次发货记录的客户进行流失预测。
[0103]
2.构建和提取特征指标
[0104]
构建铁路货运客户运单数据特征指标、通过特征相关性分析和重要性排序进行特征选择构建的铁路货运客户流失预测特征指标体系,处理原始数据集获得关键特征指标,并作为特征矩阵输入本模型;其中特征相关性分析主要是使用python中的seaborn库计算衍生特征的线性相关系数,相关性系数的绝对值越大表明相关性越强,并绘制皮尔逊相关性热力图查看特征之间的相关程度;其中重要性排序主要是使用随机森林的feature importance的变量维度重要性排序,其值越大表示该特征对目标属性的预测能力越强,得到样本中每个特征的维度重要性。本发明构建的铁路货运客户运单数据特征指标如下表所示。
[0105]
铁路货运客户运单数据特征指标构建
[0106][0107]
3.数据打标
[0108]
客户流失预测模型通常需要建立数据标签,通过数据挖掘技术对客户的数据表现进行数据标记,从而对客户未来流失倾向进行预测。本发明将铁路货运客户在未来一段时间里有无发货行为作为客户流失判定的依据,结合时间窗口的设定,以此来定义铁路货运客户流失数据标签。铁路货运客户发货行为具有季节性、波动性和随机性特点,为最大程度上获取客户发货行为的信息、观察客户发货行为特征,需设定较长时期的时间窗口,本发明以所查询时间点前12个月为单位设立时间窗口。铁路货运客户流失数据标签具体为定义在t-2时间窗口产生发货行为且发货次数不少于2次,但在t-1时间窗口未产生发货行为的客户判定为流失客户。
[0109]
4.构建输入数据集
[0110]
1)训练集与测试集
[0111]
将原始数据集随机划分为训练集和测试集两类,其中训练集占总体样本的70%,测试集占30%。训练集主要用作客户分类预测模型的构建,测试集主要用作测试、衡量和评估模型的有效性。
[0112]
2)跨时间样本验证数据集
[0113]
考虑到铁路货运客户的发货行为特性,本发明采用多周期训练数据方法,划分跨时间样本数据集,将所有数据样本滚动划分为多个时间窗口并依照周期顺序依次排列,即将历史行为数据多次采样观测,使得数据样本具有动态的数据特征和较大的信息密度,同时验证模型的泛化能力。
[0114]
5.构建和训练集成学习stacking模型
[0115]
集成学习(ensemble learning)是将多个模型通过某种策略集成起来,利用群体决策得到更优越的泛化性能和更高的决策准确率,常用的集成策略有加权平均和直接平均等,通常采取bagging和boosting两类方法来增加模型间的差异性。bagging类每轮训练的数据集是有放回选取不同的,且最终进行学习器组合时各学习器权重相同;而boosting类学习器为串行,每轮训练的数据集相同,且小误差的学习器具有大权重,后序模型依赖于前序模型。其中,bagging的代表性方法有随机森林,boosting的代表方法有gbdt、lightgbm等。
[0116]
stacking作为一种新兴的集成学习方法,通过胜者全得的机理完成异源集成,本质上是一种分层结构,在解决分类问题时通常分为两层。首先,多个基分类器组成第一层,训练数据是各基分类器的输入。第二层是元分类器,训练数据由原始训练数据标签和第一层基分类器的输出组成。元分类器经过训练后得到最终输出结果。构建一个两层的stacking集成模型的流程主要分为以下几个步骤:
[0117]
步骤一:将数据分为训练集和测试集两个部分。
[0118]
步骤二:引入五折交叉验证方法将训练集划分成五份。在训练各个基分类器时,每次取其中四份训练模型,把第五份的特征输入训练好的模型进行预测,以得到预测值。再重复上述步骤四次,获得完整的五份预测值。将五份预测值合并起来得到一列预测值,其长度与训练数据长度相同。
[0119]
步骤三:针对各个基分类器分别进行步骤二的流程,得到模型对应的训练集和测试集的预测结果。再将每个基分类器得到的预测值与原始训练数据的标签值堆叠起来作为第二层元分类器的输入进行训练和预测。可将第一层所有模型看作一个大型的特征转换器,第二层应用转换后的特征进行最终预测,stacking集成学习模型由此生成。
[0120]
本发明基于集成学习(stacking)构建融合模型,第一层分类器采用随机森林、gbdt和lightgbm算法作为基分类器,第二层采用逻辑回归算法作为元分类器,在建立数据集特征属性的基础上进行模型训练,并且通过测试集和跨时间样本测试数据集分别验证各模型的预测能力和泛化能力。
[0121]
6.客户的流失概率与预警颜色标识
[0122]
通过分析流失客户的流失概率分布情况,将铁路货运客户分成4种不同风险等级的客户类别,主要包括稳定客户和低、中、高风险客户,具体的客户流失风险等级划分和对应的预警颜色标识如下表所示。
[0123]
客户流失预警颜色标识
[0124][0125]
如图8所示,当主页面后续页面选择项203选择客户流动页面,可选择时间轴801,展示该时间段中回流客户数量802、回流客户具体信息803、新老客户数量804、新老客户货票总金额比例构成805。若使用者点选回流客户数量802和新老客户数量804的任一单元模块,可以得到相应时间段内具体的回流客户具体信息和新老客户货票总金额比例构成信息。
[0126]
如图9所示,当主页面后续页面选择项203选择货运运价页面时,可选择时间轴901、货物主品类选项902,再调用自学习规则运算模块111中的基于多变量lstm的铁路货运运价率波动预测算法,得到指标数据903,并得出所选取时间轴的运价率走势图904,通过调用该算法进行预测的用户登录时间未来7天的运价率走势图905。其中:所述基于多变量lstm的铁路货运运价率波动预测算法包括如下步骤:
[0127]
步骤一:根据铁路的运费结构与运价浮动机制,提出运价浮动率计算公式,基于订单数据与官方报价,计算运价浮动率;
[0128]
步骤二:建立模型预测数据仓库;包括运输成本数据集、宏观环境数据集、市场竞争数据集与运输对象数据集,将自变量x1,x2,...,xm作为数据集中影响因素的特征变量和因变量(运价浮动率)进行相关性分析,根据变量间的相关性程度筛选关键的影响因素作为模型输入;筛选后剩余n个特征变量,n《m;
[0129]
步骤三:将选取的特征变量和因变量做数据预处理,主要包含数据降噪、数据聚合以及数据标准化;将数据划分为训练集和测试集;
[0130]
步骤四:构建用于铁路运价浮动预测的多变量lstm模型框架,设置模型初始参数值,使用训练集对多变量lstm预测模型进行超参数优化,得到最优模型;将测试集应用于训练好的预测模型,将预测值进行反归一化处理,使其与真实值处于同一量级,输出预测结果、输出预测误差曲线,以及真实值和预测值的拟合曲线图进行预测效果评估。
[0131]
其中:
[0132]
1、铁路运价浮动率计算
[0133]
本发明将铁路运价预测转化为铁路运价浮动比率预测,该浮动比率即为实际承运价格与铁路95306货运官网价格进行比价得出。以货物种类代码为x的第i票货运数据为例,其运价浮动率表示为r
xi
,具体计算公式如下:
[0134][0135]
[0136][0137][0138][0139][0140]
其中,p1为实际运价率;p2为理论运价率;为货物x所适用的基价1;为货物x所适用的基价2;γ
xi
为该票货物的货票总金额;l
xi
为该票货物的运输总里程,其值大于0;w
xi
为该票货物的计费重量,其值大于0;f
xi
为该票货物所需缴纳的所有附加费用;f
t
为第t类费用的系数,包括电气化费用系数、新路新价公摊费用系数、税费系数等,所有系数均大于0;m
xi
为该票货物所需缴纳的所有杂费;mk为第k项杂费的系数,包括接、送站费系数、搬运费系数等,所有系数均大于0;θk为该项杂费服务的距离,如货物的搬运距离;λ
xi
为该票货物所有的加减成率;λj为第j项加成率或减成率,该数据可为正数也可为负数,当存在两个以上负数时仅取其中最小一个,当存在两个以上正数时所有数值进行叠加运算。
[0141]
2、构建数据仓库
[0142]
本发明所构建的数据仓库由运输成本、宏观环境数据、竞争对手数据以及运输对象数据组成。其中运输成本数据来源于95306货票数据;宏观环境数据包括gdp月同比增长率、pmi月同比变化率、零售商品价格指数、仓储价格指数,其中前三者均来国家统计局,最后一项来自中国物流与采购联合会与中储发展股份有限公司报告数据库;竞争对手数据,主要是公路相关数据,包括公路运价指数和公路月货运量,两者分别来自中国公路物流运价指数网和交通运输部;运输对象数据,主要包含运输货物指数和运输货物产量两个因素,两者均来自wind数据库。
[0143]
相关性分析主要是通过皮尔逊相关系数来计算变量间的相关性。相关系数的绝对值越大表明相关性越强,而正负显示两变量是正相关还是负相关。
[0144][0145]
其中,n为样本数;xi、yi为变量值;r的取值范围在[-1,1],当r》0时,表示两个变量之间呈正相关关系;r《0时,表示两个变量之间呈负相关关系;|r|》0.8表明变量间存在显著的线性相关性,而|r|《0.1则表明两变量间线性相关性较弱。
[0146]
3、数据预处理
[0147]
(1)数据聚合
[0148]
本发明对各类运输货物运价浮动率进行周预测,因此将所有货票数据以各类运输货物品类代码为主键,在以周为单位进行加和再取均值处理。此外,外部影响因素往往具备不同的时间粒度,对于以日为单位的运输货物相关数据,按周内均值取值。而宏观环境数据
往往数据粒度较大,最小也为月,则按照该周所处月份均取同一数值。公路运输数据粒度则本身为周。
[0149]
(2)数据标准化
[0150]
采取的数据标准化方式是归一化:对于每个属性a,将a的一个原始值xi通过min-max标准化映射成在区间[0,1]中的值xi′
,其公式为
[0151][0152]
其中,x
max
为属性a中的最大值;x
min
为属性a中的最小值;xi为原始值;xi′
为原始值xi通过归一化映射成在区间[0,1]中的值。
[0153]
(3)将所有数据按照时间先后排序,按照4:1比例划分训练集和测试集。
[0154]
4、多变量lstm模型构建
[0155]
标准的rnn模型存在梯度消失和爆炸的问题,因此阻碍了网络的优化学习。也是由于这个原因,rnn仅存在短期记忆,在需要记住完整序列特征的长序列预测中不能取得较好的效果。长短期记忆(long-short term memory,lstm)循环网络通过引入称为constant error carousel(cec)的线性单元,克服了梯度消失问题,该单元可以为每个时间步添加信息。cec的错误流控制是使用“门”进行的。输入门控制添加到单元的信息,输出门调节信息流向网络的其余部分,而遗忘门衰减先前时间步的激活。
[0156]
其具体计算过程是前一个隐藏单元的信息a
t-1
和当前输入的信息x
t
通过σsigmoid激活函数计算所有门值,并通过tanh激活函数计算新信息这些信息将被用于更新。lstm一个细胞单元的计算公式是:
[0157][0158]
γu=σ(wu[a
t-1
,x
t
]+bu)
[0159]
γf=σ(wf[a
t-1
,x
t
]+bf)
[0160]
γo=σ(wo[a
t-1
,x
t
]+bo)
[0161][0162]at
=γo×
tanh(c
t
)
[0163]
其中,wu、wf、wo分别表示更新门、遗忘门、输出门的权重;bu、bf、bo分别表示更新门、遗忘门、输出门的偏差;wc为存储单元的权重;bc为存储单元的偏差。
[0164]
本发明的多变量lstm预测模型是以运价浮动率为预测对象,输入数据为多维特征数据集及历史运价浮动率,包括:仓储价格指数、pmi、gdp、零售商品价格指数、公路运价指数、公路货运量、运输货物产量、运输货物价格指数9个影响因素以及历史运价浮动率。模型共包含4层,其中第一层为lstm网络层,其余3层为全联接dense层,最后一个dense层的神经元个数为输出值个数。每两个全连接层之间添加不同的dropout层来防止网络过拟合。
[0165]
对于多变量lstm预测模型来说,模型输入为t-1,t-2,...,t-k时刻的影响因素和历史运价浮动率yi,i=t-1,...t-k,模型的输出为预测的t时刻的运价浮动率将归一化后的数据按照4:1进行划分为训练集和测试集,训练集用于模型训练,测试集用于检测模型预测效果。y
t
为t=1,2,3,...周的实际运价浮
动率,模型在训练过程中计算与y
t
的误差来自动更新参数,优化模型。通过参数的不断迭代优化,当误差达到设定的误差时结束训练。在模型训练过程中,模型的损失误差使用mse进行计算,使用adam优化器自动调整权重梯度,选择tanh激活函数使模型快速收敛。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1