一种基于深度贝叶斯蒸馏网络的皮肤病变智能识别方法
1.本发明涉及人工智能与智慧医疗领域,尤其涉及一种基于深度贝叶斯蒸馏网络的皮肤病变智能识别方法。
背景技术:
2.皮肤病变具有分布人群广和分布年龄广的特点,全世界30%—70%的人口有与皮肤相关的健康问题。黑色素瘤等恶性皮肤癌,恶化速度快,死亡率高,对人类的生命安全造成很大威胁。黑色素瘤的早期诊断和及时治疗可以使患者的生存率提高到90%。因此,提高皮肤病变识别的准确性与效率具有重要的现实意义。借助卷积神经网络(convolutional neural networks,cnn),可实现基于图像的皮肤病的自动识别分类,提高诊断的效率和准确率。
3.当前主流cnn架构对皮肤病变识别准确率不足的主要原因在于,cnn设计存在缺陷,无法建模预测相关的不确定性,模型的输出通常为预测概率。预测概率代表了模型的置信度,但是置信度难以客观地反映模型的不确定性。因此,当前主流的cnn模型只能给出测试数据与训练数据拟合的偏差和置信度,但无法进一步提高cnn的预测准确率。而深度贝叶斯可以量化模型的不确定性,因此需要引入深度贝叶斯提高cnn的预测准确率。
4.当前,cnn辅助的识别皮肤病变类别,尤其是恶性皮肤病变识别,与贝叶斯深度学习结合的方案,主要分为优化超参数方法与优化结构方法。
5.优化超参数的方法:该类方法虽然在一定程度上缓解了由于cnn无法量化不确定性的缺陷导致的精度缺失问题,利用贝叶斯优化模型的超参数从而提高检测精度,但是没有从根本上解决cnn的结构缺陷。优化参数的方法的局限性较大,需要占用大量的计算资源训练,模型泛化能力差,实际应用成本高。
6.优化结构的方法:该类方法表明,将深度贝叶斯模型用于cnn可以显著提高模型精度,优化cnn的结构缺陷,使得模型量化不确定性能力提高。但是上述研究方案存在的问题是模型规模较大,训练占用的计算资源和时间长,模型部署占用资源大,运行等待时间长,实际应用价值低。
技术实现要素:
7.为解决上述问题,本发明提出了一种基于深度贝叶斯蒸馏网络的皮肤病变识别方法,对比主流cnn无法量化模型不确定性,为了提高诊断结果的准确度,构建了一个深度贝叶斯网络,用贝叶斯深度学习量化了模型的偶然不确定性和认知不确定性,对不确定性进行更为精确的建模;引入了知识蒸馏对模型参数量和时间进行优化,构建了一个学生网络模型拟合教师网络的输出,用教师网络的参数和真实值标签训练学生网络的输出,从而减小模型的规模与等待时间。
8.本发明所述的一种基于深度贝叶斯蒸馏网络的皮肤病变智能识别方法,包括以下步骤:
9.步骤1、采集皮肤病变图像作为样本,对所述皮肤病变样本进行标注并构建皮肤病变样本集;
10.步骤2、将所述皮肤病变样本作为输入,构建基于深度残差金字塔多尺度编码网络的深度贝叶斯网络模型;通过先验分布刻画所述深度贝叶斯网络模型不确定性,同时基于似然函数对所述不确定性进行建模推导从而推导后验分布;
11.步骤3、所述深度贝叶斯网络模型包括教师模型及学生模型,基于知识蒸馏对所述深度贝叶斯网络模型进行压缩,构建学生模型拟合教师模型输出。
12.进一步的,所述于深度残差金字塔多尺度编码网络的深度贝叶斯网络模型,包括输入层、卷积层、激活层、池化层、瓶颈层与输出层;所述模型针对的不确定性包括偶然不确定性和认知不确定性,对于偶然不确定性,采用k折交叉验证法对数据进行训练;对于认知不确定性,采用深度贝叶斯蒸馏网络拟合训练数据模型。
13.进一步的,采用k折交叉验证法对数据进行训练的具体步骤为:
14.步骤2-1-1、预处理病变样本d,同时设置交叉验证子样本划分次数k,设置循环次数n并初始化n=0;
15.步骤2-1-2、本轮迭代开始,当n《k时表示交叉验证没有执行完,进行迭代交叉验证,否则跳出迭代;
16.步骤2-1-3、采用深度贝叶斯网络模型,以第n个子样本作为验证集,其余n-1个样本作为训练集,进行模型训练,输出评估指标jn,;
17.步骤2-1-4、迭代计数k=k+1;
18.步骤2-1-5、本轮迭代结束,判断是否满足迭代停止条件,满足则停止迭代,否则重复步骤2-1-2到步骤2-1-4;
19.步骤2-1-6、输出评估结果的平均值n表示循环计数器,k表示交叉验证计数器。
20.进一步的,采用深度贝叶斯蒸馏网络拟合训练数据模型的具体步骤为:
21.步骤2-2-1、预处理病变样本d,同时设置交叉验证子样本划分次数k,设置循环次数n并初始化n=0;
22.步骤2-2-2、本轮迭代开始,当n《k时表示交叉验证没有执行完,进行迭代交叉验证,否则跳出迭代;
23.步骤2-2-3、采用深度贝叶斯网络模型,以第n个子样本作为验证集,其余n-1个样本作为训练集,进行模型训练,输出评估指标jn,求解样本的不确定分数i,对每个样本的多次预测先取平均再计算熵,求得h[y|x,d],对每个样本的多次预测先计算熵再取平均,求得e
θ~p(θ∣d)
h[y|x,θ],基于i调整训练,更新训练模型;d为标注样本,h为当前模型熵,θ为求解目标模型参数,x为网络输入,y为网络输出;
[0024]
步骤2-2-4、迭代计数k=k+1;
[0025]
步骤2-2-5、本轮迭代结束,判断是否满足迭代停止条件,满足则停止迭代,否则重复步骤2-4;
[0026]
步骤2-2-6、输出评估结果的平均值n表示循环计数器,k表示交叉验证计数器。
[0027]
进一步的,步骤2-2-3中,通过mc dropout训练标注样本d,最小化给定标注样本d下参数的不确定性,即最小化条件熵h,如公式(1):
[0028]
m=argmindh[θ|d]
ꢀꢀꢀꢀꢀ
(1)
[0029]
argmind表示熵取最小值时变量d对应的取值;
[0030]
实际训练时,用贪婪法求解,求得一个能使当前模型熵最大程度减少的样本点z,如公式(2):
[0031][0032]
argmax
x
表示熵取最大值时变量x对应的取值;
[0033]
由于所述深度贝叶斯网络模型参数维度高,导致难以求解公式(2),因此要求解公式(2)的等价问题;公式(2)等价成求解在给定样本d和新增样本点x条件下模型的互信息i,即求模型的不确定分数,即公式(3);记模型预测和模型参数之间的最大不确定分数为im,即公式(4):
[0034][0035][0036]
进一步的,步骤3中,所述深度贝叶斯网络模型通过使用softmax输出层来产生类概率,该输出层通过将每个类计算得到的logitzi与其他logit进行比较,将其转换为概率qi,表达式如式(5)所示:
[0037][0038]
其中,zi为学生的logits,n为标签总数,logitzi为当前模型计算得到的结果,logit是应用最广的分类评定模型,t为温度;t值越大,在类上产生更弱的概率分布,因此,在训练学生模型时,采用更大的t,以使softmax的输出更接近于教师模型的输出;训练结束再重新设置t的值,以使用学生模型,如式(6)所示:
[0039][0040]
其中,表示为教师模型在温度t下通过softmax输出在第i类上的值;vi为教师的logits,n为标签总数,t为温度;在训练学生模型时,将教师模型的输出称为弱目标,真实输出称为强目标;训练时,利用弱目标和强目标一起训练学生模型,在此过程中产生两个函数,学生模型与弱目标的交叉熵、学生模型与强目标的交叉熵,将两个目标函数的加权平均作为学生模型的训练目标;训练目标是加权平均损失最小,如式(7)、式(8)、式(9)所示:
[0041]
l
kd
=αl
soft
+βl
hard
ꢀꢀꢀ
(7)
[0042]
[0043][0044]
其中,cj为真实值,表示教师在温度t下softmax输出在第j类上的值,表示学生在温度t下softmax输出在第j类上的值,l表示损失loss,l
kd
为知识蒸馏损失,l
soft
表示学生模型与弱目标一起训练的交叉熵损失,l
hard
表示学生模型与强目标一起训练的交叉熵损失;α,β为调制因子,在训练时调整参数比例。
[0045]
本发明的有益效果为:本发明基于resnet与fpn(特征金字塔网络)构建了一个深度贝叶斯网络,采用贝叶斯深度学习量化了模型的偶然不确定性和认知不确定性,多次采样分布拟合训练数据模型,对不确定性进行更为精确的建模;为了解决模型部署时规模大与等待时间长的问题,引入了知识蒸馏对模型参数量和时间进行优化,构建了一个学生网络模型拟合教师网络的输出,用教师网络的参数和真实值标签训练学生网络的输出,从而减小模型的规模和参数量,降低了模型训练和部署的开销,减少了训练时间和运行时间。
附图说明
[0046]
图1为皮肤病智能识别系统模型示意图;
[0047]
图2为神经元网络结构示意图;
[0048]
图3为深度贝叶斯蒸馏网络模型;
[0049]
图4为训练集图片示意图;
[0050]
图5为测试集图片示意图;
[0051]
图6为对比文献传统数据增强resnet方法的混淆矩阵示意图;
[0052]
图7为无深度贝叶斯网络预测结果的混淆矩阵示意图;
[0053]
图8为深度贝叶斯蒸馏网络预测结果混淆矩阵示意图;
[0054]
图9为最终预测结果不同病变类别的准确率指标示意图;
[0055]
图10为本发明所述方法与其他模型预测结果准确率的对比示意图。
具体实施方式
[0056]
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明。
[0057]
本发明公开一种基于深度贝叶斯蒸馏网络的皮肤病变识别方法,包括如下步骤:
[0058]
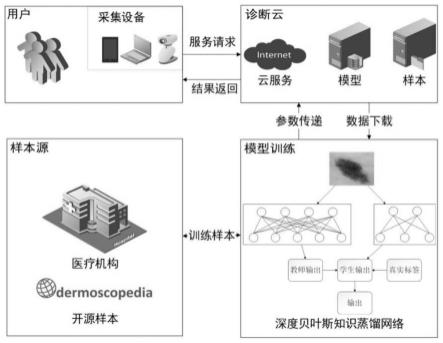
s1、构建了一个基于深度贝叶斯知识蒸馏网络的皮肤病变智能识别模型,该模型由四个部分组成:用户、诊断云、模型训练与样本源。
[0059]
用户:本发明考虑的用户为皮肤病患者与皮肤科医生。本发明为不同患者提供不同水平的服务,主要分为业余采集用户与专业皮肤科采集用户。业余采集用户,如一般患者,可以将相机或手机拍摄的皮肤病变照片上传到诊断云层,以获得诊断结果。同样,专业皮肤科采集用户,如皮肤科医生,可以上传皮肤镜图像并获得结果,这将为皮肤科医生提供诊断帮助,从而为患者做出更准确的诊断。业余用户主要通过移动设备(如手机)拍摄病变图片后获得初诊结果,受移动设备拍摄的光照、角度与清晰度等因素影响,服务诊断结果的精确度会因此受到影响,作为初步筛查提取参考;专业皮肤科采集用户通过医院皮肤科专
业采集设备(如皮肤镜)获取服务,通过皮肤科专业的皮肤镜采集并上传从而辅助医生进行医疗提取,可获得精确的提取结果。
[0060]
诊断云:本发明的诊断云由云服务、模型存储与数据缓存组成,主要提供提取与数据存储传输服务。其中,模型存储将模型训练的模型存储用于诊断服务,诊断根据模型训练结果及时更新以提高提取准确率;数据缓存将用户数据缓存用于模型训练的下载,从而提供给样本源,用于核验提取结果与扩充样本集。当诊断云接收到用户的诊断请求后,对采集到的皮肤病变图像进行处理,并根据训练好的模型将诊断结果发送给用户。同时,当诊断云完成诊断服务后,会将这张带有标签结果的图像存储起来以丰富训练数据集。
[0061]
模型训练:由于用户采集设备和诊断云计算能力有限,而本发明的模型训练基于深度贝叶斯知识蒸馏网络的皮肤病变智能识别模型,模型训练需要大量的算力和存储,因此本发明神经网络的训练主要在gpu服务器上完成模型训练。训练数据来自样本源,在训练服务器中结合数据提供方提供的训练样本进行训练,训练服务器由数个gpu与cpu组成,部署本发明基于深度贝叶斯知识蒸馏网络的皮肤病变智能识别模型与训练环境进行模型训练,并更新诊断云的模型参数。
[0062]
样本源:在数据提供中,样本由isic提供的开源数据与医疗机构中专业的皮肤镜采集人员采集并由皮肤科医生进行标注的样本构成;皮肤科医生提取采集人员提供的采集数据并提供提取结果,为样本数据进行标注,作为训练样本提供给模型训练;同时皮肤科医生从模型训练下载诊断云的提取结果进行结果分析,提取后标注数据以扩充训练样本;皮肤科医生会诊解决疑难杂症,审查诊断云的对比结果并评估模型的优势与不足。
[0063]
s2、本发明设计的深度贝叶斯网络基于深度残差金字塔多尺度编码网络,包括输入层、卷积层、激活层、池化层和瓶颈层,并增加了dropout层用于mc dropout训练。在设计时,主要针对的不确定性分为偶然不确定性和认知不确定性。
[0064]
偶然不确定性:即数据不确定性,如毛发、光照、皮肤损伤等因素导致的数据缺失和噪声,同时也有人为在图片上加入少量的对抗噪声和数据裁剪,这类不确定性虽然人眼可以轻松识别出,但会导致主流的cnn产生不同程度的误判。加入对抗噪声或引入对抗网络的效果并不理想,偶然不确定性仍然会影响cnn的识别准确率,因此本发明采用k折交叉验证的方法避免偶然误差。
[0065]
采用k折交叉验证法对数据进行训练的具体步骤为:
[0066]
步骤2-1-1、预处理病变样本d,同时设置交叉验证子样本划分次数k,设置循环次数n并初始化n=0;
[0067]
步骤2-1-2、本轮迭代开始,当n《k时表示交叉验证没有执行完,进行迭代交叉验证,否则跳出迭代;
[0068]
步骤2-1-3、采用深度贝叶斯网络模型,以第n个子样本作为验证集,其余n-1个样本作为训练集,进行模型训练,输出评估指标jn,;
[0069]
步骤2-1-4、迭代计数k=k+1;
[0070]
步骤2-1-5、本轮迭代结束,判断是否满足迭代停止条件,满足则停止迭代,否则重复步骤2-1-2到步骤2-1-4;
[0071]
步骤2-1-6、输出评估结果的平均值
[0072]
认知不确定性:即模型不确定性,是指随着模型规模的不断增加,模型的层数和参数量成指数级增加,因此导致有限的训练数据与训练数据中更为有限的有效信息量,从而导致模型的训练不充分且难以训练出最优模型。归根结底在于,训练数据中的有效信息难以跟上模型体量的大幅增长速度。虽然训练集验证时差别不大,但测试集误差极大。如果训练数据足够多,认知不确定性带来的问题可以轻松解决,但考虑到本发明的数据集分布存在样本不均衡问题,同时数据规模远远不足,因此难以通过扩大数据样本的方法解决认知不确定性。
[0073]
为了解决该问题,本发明采用深度贝叶斯蒸馏网络拟合训练数据模型,通过多次采样分布拟合训练数据模型,如图2所示,对不确定性进行更为精确的建模。具体地,本发明模型通过先验分布刻画模型不确定性,同时基于似然函数对数据不确定性进行建模推断从而推导后验分布。
[0074]
在训练时,为了得到网络的偏置和分布,需要求得后验概率,即求得权重的所有取值空间。而神经网络单个权重的取值空间是实数集r,因此不同层之间的权重构成的空间非常复杂难以积分。同时,本发明采用的是多尺度模型,本发明与主流cnn的不同在于,本发明的cnn基于resnet,在resnet的基础上,使用3个3*3卷积核来代替7*7卷积核,使用2个3*3卷积核来代替5*5卷积核,即使得5*5卷积的全连接网络在5*5区域滑动。主流cnn是单一尺度网络,本发明将瓶颈层划分为多尺度编码网络。具体地,瓶颈层由多个瓶颈层1和瓶颈层2组成,瓶颈层1和瓶颈层2由卷积块、批标准化和线性整流组成。在深度残差金字塔多尺度编码网络基础上训练拟合偏置和分布,进一步提高了不同层之间的权重构成空间的复杂性,因此本发明采用mc dropout来解决该问题。通过增加dropout层,在测试时打开dropout并对同一输出多次求前向传播计算平均,以拟合后验分布,通过多次采样推导出更准确的估计预测置信度,从而提高网络的训练效果。
[0075]
本发明采用的mc dropout提供了dropout的正则化技术的解释。变分推断是一种贝叶斯方法,用于使用任意分布来估计后验分布;但dropout是一种神经网络的正则化方法,训练过程中神经元随机开启或关闭,以免使得网络依赖某个特定的神经元。这是mc dropout的核心思想:dropout能够用于执行变分推断,这里变分分布就是一种伯努利分布,状态为开和关。mc表示dropout用一种类似于蒙特卡罗的方式采样。在本发明中,通过mc dropout使用将传统的网络转变成贝叶斯网络,使得研究问题等价于从伯努利分布中采样,提供一种模型不确定性的度量,即多次采样的做的预测的连续性。本发明通过mc dropout训练标注样本d,旨在尽可能减小模型参数θ可能的假设,也就是最小化给定标注样本d下参数的不确定性,即最小化条件熵h,即公式(1):
[0076]
m=argmindh[θ|d]
ꢀꢀꢀ
(1)
[0077]
实际训练时,需要用贪婪法求解,求得一个能使当前模型熵最大程度减少的样本点z,即公式(2):
[0078][0079]
由于本发明模型参数维度较高,导致难以求解公式(2),因此要求解公式(2)的等价问题。公式(2)等价成求解在给定样本d和新增样本点x条件下模型的互信息
[81]
(mutual information,mi),记为i,也就是求模型的不确定分数,即公式(3)。记模型预测和模型参数
之间的最大不确定分数为im,即公式(4):
[0080][0081][0082]
采用深度贝叶斯蒸馏网络拟合训练数据模型的具体步骤为:
[0083]
步骤2-2-1、预处理病变样本d,同时设置交叉验证子样本划分次数k,设置循环次数n并初始化n=0;
[0084]
步骤2-2-2、本轮迭代开始,当n《k时表示交叉验证没有执行完,进行迭代交叉验证,否则跳出迭代;
[0085]
步骤2-2-3、采用深度贝叶斯网络模型,以第n个子样本作为验证集,其余n-1个样本作为训练集,进行模型训练,输出评估指标jn,求解样本的不确定分数i,对每个样本的多次预测先取平均再计算熵,求得h[y|x,d],对每个样本的多次预测先计算熵再取平均,求得e
θ~p(θ∣d)
h[y|x,θ],基于i调整训练,更新训练模型;
[0086]
步骤2-2-4、迭代计数k=k+1;
[0087]
步骤2-2-5、本轮迭代结束,判断是否满足迭代停止条件,满足则停止迭代,否则重复步骤2-4;
[0088]
步骤2-2-6、输出评估结果的平均值
[0089]
s3、本发明模型压缩方法基于知识蒸馏设计,在模型压缩的过程中涉及到两个模型,即教师模型和学生模型。教师模型是预先训练好的大模型,预测精度高,但是规模大占用资源高;学生模型是待训练的小模型,是希望得到的规模小占用资源少的最终模型。知识蒸馏通过训练学习的方式,给待训练的学生模型部署教师模型的参数等有用知识,同时转移给学生模型教师模型的泛化能力,通过将教师模型产生的类概率作为学生模型的训练目标来实现。蒸馏从具有较好的泛化能力的大模型中提取知识,将知识迁移至小模型中。学生模型向教师模型学习有用的知识,以实现逼近教师模型的性能。利用教师模型的输出训练学生模型可以将教师模型的知识转移到学生模型。将教师模型的输出称为软目标,而将期望的数据作为硬目标,利用软目标和硬目标一起训练学生模型,通过调节软目标和硬目标的比重来调整教师模型对学生模型的影响。利用软目标训练学生模型的损失称为蒸馏损失,利用期望的数据训练学生模型的损失称为学生损失,在训练过程中,将蒸馏损失和学生损失之和作为学生模型的总损失,并且训练目标是使得学生模型的总损失最小。知识蒸馏具有以下优势:学生模型可以学习到教师模型的知识,以较小规模的模型,获得了相对较好的模型性能;软目标和硬目标一起训练学生模型,提高了学生模型的泛化能力。
[0090]
本发明神经网络通过使用softmax输出层来产生类概率,该输出层通过将每个类计算得到的logitzi与其他logit进行比较,将其转换为概率qi,表达式如式(5)所示:
[0091][0092]
其中,zi为学生的logits,n为标签总数,t为温度,通常设置为1。t值越大,可以在类上产生更弱的概率分布。因此,在训练学生模型时,可以采用更大的t,以使softmax的输出更接近于教师模型的输出。训练结束再重新设置t的值(如t=1),以使用学生模型,如式
(6)所示。
[0093][0094]
其中,vi为教师的logits,n为标签总数,t为温度,通常设置为1。在训练学生模型时,将教师模型的输出称为弱目标,真实输出称为强目标。训练时,利用弱目标和强目标一起训练学生模型。在此过程中产生两个函数,学生模型与弱目标的交叉熵、学生模型与强目标的交叉熵,将两个目标函数的加权平均作为学生模型的训练目标。训练目标是加权平均损失最小,如式(7)、式(8)、式(9)所示:
[0095]
l
kd
=αl
soft
+βl
hard
ꢀꢀꢀ
(7)
[0096][0097][0098]
其中,cj为真实值,表示教师在温度t下softmax输出在第j类上的值,表示学生在温度t下softmax输出在第j类上的值。
[0099]
如图3所示,本发明采用深度贝叶斯网络作为教师网络,构建深度贝叶斯蒸馏网络。训练数据同时输入教师网络和学生网络,学生网络单独设计,结构与教师网络相同,但尺度和层数均少于教师网络,从而减少了模型部署的开销和训练时间,提高了网络训练的效率。教师输出由教师网络通过训练数据训练得出,而学生训练的输出要结合真实标签和教师网络输出进行知识蒸馏。
[0100]
本发明设置l
hard
旨在防止教师模型出错,使用l
hard
能避免老师的错误传递给学生。设置l
soft
和l
hard
的权重目的在于调整其对模型效果的影响,因为经验表明l
hard
权重较小往往带来更好的效果。l
soft
的梯度贡献大约是1/t2,因此为了确保两个loss的梯度贡献等同,本发明将l
soft
与t2相乘。最原始的softmax函数就是t=1,当t《1,概率分布更密集;当t趋向于0时,输出值就变成了hard权重导向;当t》1,概率分布就会更平滑。随着t增大,概率分布熵会随之增大;当t趋于无穷时,softmax结果就均匀分布。t的变化程度决定了学生模型有多少关注度在负类别上,当温度很低,模型就不太关注负类别,特别是那些小于均值的负类别;当温度很高,模型就更多的关注负类别。事实上负类别携带更多信息,特别是大于均值的负类别。t的选择与学生模型的大小密切相关,而经验表明,当学生模型相对较小时,t的设置不宜过大,因为学生模型没有能力学习老师模型全部的知识,一些负类别信息就可以忽略。因此本发明t基于实验选择,通过多次采样调整t的取值,从而在提高知识蒸馏优化程度的同时降低模型的精度损失。
[0101]
本发明样本集为rgb颜色系统三通道皮肤镜图像,样本集分为训练集和测试集,由isic开源的皮肤病样本集与医疗机构中专业的皮肤镜采集人员采集并由皮肤科医生进行标注的样本构成。本文样本每个病变图像包括一个原发病变,不包括较小的继发性病变或其他色素区。病变样本的分布符合现实情况,即良性病变多于恶性病变,但恶性病变种类较
多。本发明训练集构成为12609张皮肤镜病变图像,主要的病变类型为黑色素瘤(mel)、黑色素细胞痣(nv)、基底细胞癌(bcc)、光化性角化病(akiec)、良性角化病(bkl)、皮肤纤维瘤(df)和血管病变(vasc)等,训练集选自isic2018和医疗机构脱敏采样图片,如图4与图5所示,图片不带有患者任何个人信息,从而保护患者隐私,同时每张图片对应csv格式的标签,该训练集图片标签为mel。为了避免采集到的训练集样本存在毛发、气泡、光照等因素对实验结果的影响,本发明采用去噪、色彩恒常性等算法对图片进行预处理,同时对样本集平移、翻转、拉伸、旋转扩充训练集至20000张。
[0102]
为了进一步微观地评判模型,设t为分类器判断正确(true),f为分类器判断错误(false),p表示疾病结果为阳性(positive),n表示疾病结果为阴性(negative),则tp为真阳性,tn为真阴性,fp为假阳性,fn为假阴性。本发明采用灵敏度(sensitive)作为评判诊断准确度的标准,sensitive=tp/p,同时引入特效度(specifity)和精度(precision)辅助判断。specifity=tn/n,precision=tp/(tp+fp)。
[0103]
通过本发明模型诊断后输出结果如图所示,其中图6为budhiman使用传统数据增强resnet的混淆矩阵(现有文献a.budhiman,s.suyanto,a.arifianto.melanoma cancer classification using resnet with data augmentation[c].proceedings of international seminar on research of information technology and intelligent systems(isriti),2019:17-20.),图7为本发明无深度贝叶斯网络预测结果的混淆矩阵,图8为本发明深度贝叶斯蒸馏网络预测结果的混淆矩阵。
[0104]
图8为本发明最终预测结果不同病变类别的准确率指标。从图中可以看出,本发明对nv和vasc的识别准确率以及所有分类结果的特效度均达到较高水平。如图9和表1所示,虽然由于样本不均衡导致akiec和df的灵敏度稍低,但本发明模型平均灵敏度、特效度和精度与主流模型相比均有所提升,每种类别的分类结果均取得较高的灵敏度、特效度和精度。
[0105]
表1 本发明最终预测结果不同病变类别的准确率指标
[0106][0107]
如图10和表2所示,本发明深度贝叶斯模型平均预测结果优于主流方案,原因在于主流方案与深度残差金字塔的模型无法建模预测相关的不确定性,模型输出为预测概率,难以客观地反映模型的不确定性,只能给出测试数据与训练数据拟合的偏差和置信度。而本发明深度贝叶斯网络通过多次采样分布拟合训练数据模型,对不确定性进行更为精确的建模,将贝叶斯不确定性建模与深度残差金字塔模型拟合能力结合,发挥其互补优势,在预
测时集成后验分布预测模型的结果从而提高模型的预测能力,因此具有更好的预测结果,本发明深度贝叶斯蒸馏网络模型预测结果与其他论文模型对比,灵敏度、特效度和精度均为最高。
[0108]
表2 本发明与其他模型预测结果准确率的对比
[0109][0110]
本发明深度贝叶斯网络可以拟合训练数据的模型,通过多次采样分布拟合训练数据模型,对不确定性进行更为精确的建模。具体来说,本发明模型通过先验分布刻画模型不确定性,同时基于似然函数对数据不确定性进行建模推断从而推导后验分布。本发明将贝叶斯不确定性建模与传统cnn的函数拟合能力结合,以弥补传统cnn存在的局限,发挥其互补优势,解决过拟合问题,在预测时集成后验分布预测模型的结果从而提高模型的预测能力。本发明采用mc dropout来解决该问题,增加dropout层,在测试时打开dropout并对同一输出多次求前向传播计算平均,以拟合后验分布。通过多次采样推导出更准确的估计预测置信度,从而提高网络的训练效果。
[0111]
本发明采用深度贝叶斯网络作为教师网络,构建深度贝叶斯蒸馏网络,训练数据同时输入教师网络和学生网络。学生网络单独设计,结构与教师网络相同,但尺度和层数均少于教师网络,从而减少了模型部署的开销和训练时间,提高了网络训练的效率。教师输出由教师网络通过训练数据训练得出,而学生训练的输出要结合真实标签和教师网络输出进行知识蒸馏。如表3所示,知识蒸馏通过训练学习的方式,给待训练的学生模型部署教师模型的参数等有用知识,同时转移给学生模型教师模型的泛化能力,通过将教师模型产生的类概率作为学生模型的训练目标来实现。表3展示了本发明深度贝叶斯蒸馏网络模型与主流方案参数量和运行时间对比,有效简化了模型运行时的参数量和时间,在压缩的同时,减少了模型精度降低程度,表4展示了本发明深度贝叶斯蒸馏网络与本发明无知识蒸馏网络的模型对比。
[0112]
表3 本发明深度贝叶斯蒸馏网络与主流方案参数量与运行时间对比
[0113][0114]
表4 本发明深度贝叶斯蒸馏网络知识蒸馏后参数变化
[0115][0116]
以上所述仅为本发明的优选方案,并非作为对本发明的进一步限定,凡是利用本发明说明书及附图内容所作的各种等效变化均在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1