基于Stacking的灌浆量集成代理预测模型及预测方法
基于stacking的灌浆量集成代理预测模型及预测方法
技术领域
1.本发明涉及水利水电工程中大坝基岩灌浆施工领域,特别涉及一种基于stacking的灌浆量集成代理预测模型及预测方法。
背景技术:
2.目前,灌浆施工作为大坝基础防渗、地基改善和修复的主要方法,对保证水工建筑物的稳定运行至关重要。灌浆量是表征灌浆施工质量的重要参数,且与灌浆施工的成本效益密切相关。通过灌浆量的预测,可以完善灌浆设计方案,节省灌浆材料和设备投资,指导后续灌浆施工控制和工程量优化。
3.然而,由于灌浆工程的隐蔽性和复杂性,根据施工人员经验和简化物理模型试验等传统方法预估的灌浆量与实际情况存在较大误差。随着计算流体力学方法和离散裂隙网络建模方法的快速发展,数值模拟技术成为计算坝基灌浆量的有力工具。但数值模拟存在建模过程复杂、计算量大、耗时长等问题,导致灌浆量计算效率低,无法满足指导灌浆工程建设的需求。基于机器学习算法的代理模型可以替代复杂耗时的数值模拟过程,同时兼顾计算效率与预测精度。因此,基于机器学习算法的代理模型技术成为解决复杂工程灌浆量预测问题的有效途径。
4.然而,单一机器学习器代理模型的预测稳定性较差,可能由于随机而导致泛化性能不佳,且只使用一种机器学习模型容易低估预测的不确定性以至准确性较差。因此,一些研究通过采用组合代理模型的方式来提高整体预测精度。然而组合代理模型在决定各算法的赋权值时存在主观性和不确定性,也无法训练出更优异的模型。而集成学习(ensemble learning)方法通过集成策略将多个单一模型的信息融合在一起构建集成学习模型能够增加模型多样性、减少过拟合和预测不确定性,产生更准确、更稳健的预测结果。集成学习通常包括bagging,boosting和stacking三种策略,其中stacking算法由于能够根据实际问题灵活组合多种不同类型的基学习器来构建合适的集成学习模型,获得更好的预测性能和模型泛化能力,被广泛应用于各个领域处理预测问题。
5.此外,考虑模型参数的选择对模型的最终预测效果有显著影响,如何确定模型最优参数也是模型建立的核心问题。群智能算法由于操作简单,求解问题能力强,在参数优化领域表现突出,被广泛应用于机器学习算法参数寻优。麻雀搜索算法(ssa)是xue等在2020年提出的一种新型群智能优化算法,试验证明其在搜索精度、收敛速度、稳定性等方面均优于灰狼优化算法(gwo)、粒子群优化算法(pso)、引力搜索算法(gsa)、蚁狮优化算法(alo)等当前主流算法。然而,ssa在搜索后期存在种群多样性逐渐降低并导致算法无法跳出局部极值的问题,因此迫切需要一种能够兼顾全局搜索能力、局部搜索能力和计算效率的优化算法。
6.综上所述,现有的坝基灌浆量预测模型的研究,数值模拟存在建模过程复杂、计算量大、耗时长等问题,而仅使用一种机器学习模型容易低估预测的不确定性以至准确性较差,此外组合代理模型在决定各算法的赋权值时存在主观性和不确定性,无法训练出更优
异的模型。
技术实现要素:
7.本发明为解决公知技术中存在的技术问题而提供一种基于stacking的灌浆量集成代理预测模型及预测方法。
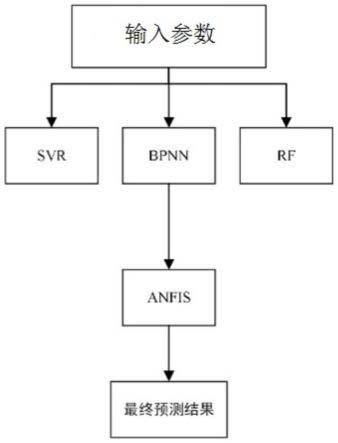
8.本发明为解决公知技术中存在的技术问题所采取的技术方案是:一种基于stacking的灌浆量集成代理预测模型,包括集成代理模型,该集成代理模型设有两层,第一层包括采用五折交叉验证方法进行训练和验证的三个基学习器,第二层包括一个元学习器;三个基学习器分别为svr神经网络、bpnn神经网络和rf模型;元学习器为anfis神经网络;元学习器的训练集中的训练数据包括三个基学习器的预测结果数据。
9.进一步地,还包括基于三维精细裂隙建模的灌浆数值模拟模型,灌浆数值模拟模型输入地质参数、施工参数及浆液特性参数,输出灌浆量模拟值;元学习器的训练集中的训练数据还包括灌浆量模拟值。
10.本发明还提供了一种基于stacking的灌浆量集成代理预测模型的预测方法,构建基于stacking的灌浆量集成代理预测模型;该集成代理预测模型设置两层,第一层设置三个基学习器,第二层设置一个元学习器,三个基学习器分别为svr神经网络、bpnn神经网络和rf模型;元学习器为anfis神经网络;采集包括地质参数、施工参数和浆液特性参数的历史数据作为训练样本,构建训练集及验证集;使用五折交叉验证方法对三个基学习器进行训练;构建包括由三个基学习器得到的预测结果数据的训练集来训练元学习器;将包括地质参数、施工参数和浆液特性参数的输入参数同时输入至三个基学习器,然后将三个基学习器得到的预测结果输入至元学习器,由元学习器输出灌浆量预测值。
11.进一步地,还设置基于三维精细裂隙建模的灌浆数值模拟模型,使灌浆数值模拟模型输入地质参数、施工参数及浆液特性参数,输出灌浆量模拟值;将三个基学习器得到的预测结果与对应的灌浆量模拟值组合,构建新的训练集来训练元学习器。
12.进一步地,构建训练集及验证集的方法包括:利用拉丁超立方抽样方法抽取多组地质参数,将其与不同的施工参数和浆液特性参数进行组合,构建具有代表各种裂隙地质条件及施工工况的参数样本集;将参数样本集中的数据输入至灌浆数值模拟模型中,得到灌浆量模拟值;将地质参数、施工参数和浆液特性参数及对应生成的灌浆量模拟值作为样本数据,构建样本集,按比例将样本集划分为训练集和测试集。
13.进一步地,采集包括地质参数、施工参数和浆液特性参数的历史数据作为训练样本的方法包括:根据三维精细裂隙网络模型获取如下地质参数:裂隙数量、裂隙平均倾向、平均倾角和平均隙宽;根据工程实际施工方案以及水工建筑物水泥灌浆施工技术规范获取如下施工条件参数:灌浆孔的排序、孔序、孔深以及灌浆压力;根据根据工程实际施工方案获取如下浆液参数:浆液水灰比。
14.进一步地,基于混沌理论和l
é
vy飞行策略对麻雀搜索算法进行改进,采用改进的麻雀搜索算法对基学习器和元学习器的模型参数进行同步优化。
15.进一步地,基于混沌理论和l
é
vy飞行策略对麻雀搜索算法进行改进的方法包括:
16.基于混沌理论进行麻雀种群初始化,使用tent混沌映射生成混沌序列初始化麻雀位置xp
i,j
,其中i=1,2,3
…
n,n表示麻雀种群的数量,j=1,2,3
…
d,d表示待优化变量的维
数;
17.随机生成[0,1]之间的初始值x
pi,0
,此时j=0;
[0018]
使用tent混沌映射生成混沌序列:
[0019][0020]
将混沌序列映射到解的搜索空间,得到混沌初始化种群:
[0021][0022]
采用l
é
vy飞行策略对探索者、跟随者和侦察者的位置更新公式进行改进,扩大搜索范围提高全局搜索能力,改进后的探索者位置更新公式如下:
[0023][0024][0025]
改进后的探索者位置更新公式如下:
[0026][0027]
改进后的探索者位置更新公式如下:
[0028][0029]
上述各式中:
[0030]
y={yi,i=1,2,3
…
,n}表示响应灌浆量值;
[0031]
f={fi,i=1,2,3
…
,k}表示最终灌浆量预测值;
[0032]
xp表示待优化参数的种群向量集合;
[0033]
i表示麻雀种群中的个体;
[0034]
j表示待优化变量;
[0035]
为使用tent混沌映射得到的混沌初始化种群;
[0036]
xp
min,j
为第j维种群向量值的最小值;
[0037]
xp
max,j
为第j维种群向量值的最大值;
[0038]
表示为第t次迭代时第i个麻雀个体的第j维种群向量值;
[0039]
表示为第t+1次迭代时第i个麻雀个体的第j维种群向量值;
[0040]
t表示当前迭代次数;
[0041]
iter
max
表示最大迭代次数;
[0042]
α∈(0,1)表示随机系数;
[0043]
r2∈[0,1]表示预警值;
[0044]
st∈[0.5,1]表示安全值;
[0045]
是迭代计算的中间变量;
[0046]
表示当前全局最优的位置;
[0047]
⊕
表示点乘积;
[0048]
l
é
vy(λ)表示l
é
vy随机搜索路径;
[0049]
表示当下探索者所占的最优位置,
[0050]
是当前全局最差的位置,
[0051]
n为麻雀种群的个体总数,
[0052]
a表示一个1
×
d的矩阵,其中每个元素取值为1或-1,且a
+
=a
t
(aa
t
)-1
;
[0053]
fb表示当前全局最佳适应度值;
[0054]fw
表示当前全局最差适应度值;
[0055]fi
表示待更新麻雀个体的适应度值;
[0056]
ε为较小常数,防止分母为零。
[0057]
进一步地,采用改进的麻雀搜索算法对基学习器和元学习器的模型参数进行同步优化的方法包括如下步骤:
[0058]
步骤1,确定种群数量、最大迭代次数、适应度值范围、求解区间范围、探索者比例及侦察者比例;
[0059]
步骤2,采用tent混沌映射初始化种群;
[0060]
步骤3,迭代次数加1;计算麻雀种群适应度值;
[0061]
步骤4,从适应度值较优的麻雀中选取部分作为探索者,进行位置更新;
[0062]
步骤5,剩余麻雀作为跟随者,进行位置更新;
[0063]
步骤6,从麻雀种群中选择部分作为侦察者,进行位置更新;
[0064]
步骤7,计算麻雀种群适应度值;
[0065]
步骤8,判断适应度值是否满足条件,如果不满足则执行步骤9;如果满足则执行步骤10;
[0066]
步骤9,判断迭代次数是否小于最大迭代次数,如果小于最大迭代次数则执行步骤3,否则执行步骤10;
[0067]
步骤10,结束优化,得到最优模型参数。
[0068]
进一步地,采用麻雀搜索算法进行优化的模型参数包括:svr神经网络的惩罚因子和核参数,bpnn神经网络的初始阈值与权值,rf模型的决策树数量n和最大深度h,anfis神经网络的前件参数。
[0069]
本发明具有的优点和积极效果是:本发明采用基于stacking的集成代理预测模型搭建灌浆量集成代理预测模型,能够增加模型多样性、减少过拟合和预测不确定性,产生更准确、更稳健的预测结果。本发明采用改进麻雀搜索算法对模型参数进行优化,可以保证初始化模型参数的种群分布的均匀性和多样性,并且可以克服在搜索过程中可能会出现种群多样性降低进、避免陷入局部最优。本发明解决了现有机器学习的灌浆量预测模型的如下
技术问题:没有考虑地质参数、灌浆数值模拟计算复杂耗时、单一代理模型精度较低且组合代理模型赋权主观性大。相较于单一代理模型,本发明的预测性能提高,能够实现快速精确地预测灌浆量,从而获得更准确可靠的预测结果,为决策提供指导,保证灌浆的安全和质量;在实际灌浆工程中能够为待灌区域的灌浆量估计提供可靠的方法支撑,具有重要的工程应用价值;同时本发明所提模型也为其他工程参数预测提供了新思路,具有良好的工程运用前景。
附图说明
[0070]
图1是本发明的一种基于stacking的灌浆量集成代理预测模型结构示意图。
[0071]
图2是本发明的一种基于stacking的灌浆量集成代理预测模型训练流程示意图。
[0072]
图3是本发明的一种基于stacking的灌浆量集成代理预测模型的预测方法的流程示意图。
[0073]
图中:
[0074]
svr:支持向量回归。
[0075]
bpnn:bp神经网络模型。
[0076]
rf:随机森林模型。
[0077]
anfis:自适应神经模糊推理系统。
[0078]
x:决策变量集合。
[0079]
y:响应量集合。
[0080]
x
tr
:训练样本中的决策变量。
[0081]ytr
:训练样本中的响应量。
[0082]
x
te
:测试样本中的决策变量。
[0083]yte
:测试样本中的响应量。
[0084]
p
tr-svr
:利用支持向量机模型基于训练样本得到的响应量预测值。
[0085]
p
tr-bpnn
:利用bp神经网络模型基于训练样本得到的响应量预测值。
[0086]
p
tr-rf
:利用随机森林模型基于训练样本得到的响应量预测值。
[0087]
p
tr-1~5
:利用基学习器基于训练样本训练五次分别得到的响应量预测值。
[0088]
p
tr
:集合三个基学习器对训练样本的输出构成的新训练样本。
[0089]
p
te-svr
:利用支持向量机模型基于测试样本得到的响应量预测值。
[0090]
p
te-bpnn
:利用bp神经网络模型基于测试样本得到的响应量预测值。
[0091]
p
te-rf
利用随机森林模型基于测试样本得到的响应量预测值。
[0092]
p
te
:集合三个基学习器对测试样本的输出构成的新测试样本。
[0093]fte
:最终预测结果。
具体实施方式
[0094]
为能进一步了解本发明的发明内容、特点及功效,兹列举以下实施例,并配合附图详细说明如下:
[0095]
本技术中如下外文单词及缩写的中文释义如下:
[0096]
stacking:集成学习策略的一种,通过训练一个元学习器来学习各基学习器的模
型输出与实际输出之间的关系,以此将不同类型的基学习器结合起来构建集成模型。
[0097]
bagging:集成学习策略的一种,通过样本训练以并行方式生成多个同类型基学习器,并将他们的结果进行线性组合。
[0098]
boosting:集成学习策略的一种,通过样本训练以串行方式生成多个同类型基学习器,并将他们的结果进行线性组合。
[0099]
ssa:麻雀搜索算法,一种新型群智能优化算法。
[0100]
issa-stacking:基于改进麻雀搜索算法的集成学习算法。
[0101]
svr:支持向量回归,基于超平面的预测模型,对于解决小样本、高纬度的非线性回归预测问题具有独特优势。
[0102]
bpnn:bp神经网络模型,经典的神经网络模型,具有较好的数值处理及逼近能力。
[0103]
rf:随机森林模型,bagging集成算法的代表,具有泛化误差低、稳定性好、不易过拟合等优。
[0104]
anfis:自适应神经模糊推理系统。
[0105]
lhs:拉丁超立方抽样方法。
[0106]
l
é
vy:l
é
vy飞行策略是一类非高斯随机过程。
[0107]
tent:tent混沌映射,指一种分段的线性映射。
[0108]
请参见图1至图3,一种基于stacking的灌浆量集成代理预测模型,包括集成代理模型,该集成代理模型设有两层,第一层包括采用五折交叉验证方法进行训练和验证的三个基学习器,第二层包括一个元学习器;三个基学习器分别为svr神经网络、bpnn神经网络和rf模型;元学习器为anfis神经网络;元学习器的训练集中的训练数据包括三个基学习器的预测结果数据。
[0109]
优选地,还可包括基于三维精细裂隙建模的灌浆数值模拟模型,灌浆数值模拟模型可输入地质参数、施工参数及浆液特性参数,输出灌浆量模拟值;元学习器的训练集中的训练数据还可包括灌浆量模拟值。
[0110]
本发明还提供了一种基于stacking的灌浆量集成代理预测模型的预测方法,构建基于stacking的灌浆量集成代理预测模型;该集成代理预测模型设置两层,第一层设置三个基学习器,第二层设置一个元学习器,三个基学习器分别为svr神经网络、bpnn神经网络和rf模型;元学习器为anfis神经网络;采集包括地质参数、施工参数和浆液特性参数的历史数据作为训练样本,构建训练集及验证集;使用五折交叉验证方法对三个基学习器进行训练;构建包括由三个基学习器得到的预测结果数据的训练集来训练元学习器;将包括地质参数、施工参数和浆液特性参数的输入参数同时输入至三个基学习器,然后将三个基学习器得到的预测结果输入至元学习器,由元学习器输出灌浆量预测值。
[0111]
优选地,还可设置基于三维精细裂隙建模的灌浆数值模拟模型,可使灌浆数值模拟模型输入地质参数、施工参数及浆液特性参数,输出灌浆量模拟值;可将三个基学习器得到的预测结果与对应的灌浆量模拟值组合,构建新的训练集来训练元学习器。
[0112]
优选地,构建训练集及验证集的方法可包括:可利用拉丁超立方抽样方法抽取多组地质参数,将其与不同的施工参数和浆液特性参数进行组合,构建具有代表各种裂隙地质条件及施工工况的参数样本集;可将参数样本集中的数据输入至灌浆数值模拟模型中,得到灌浆量模拟值;可将地质参数、施工参数和浆液特性参数及对应生成的灌浆量模拟值
作为样本数据,构建样本集,可按比例将样本集划分为训练集和测试集。
[0113]
优选地,采集包括地质参数、施工参数和浆液特性参数的历史数据作为训练样本的方法可包括:可根据三维精细裂隙网络模型获取如下地质参数:裂隙数量、裂隙平均倾向、平均倾角和平均隙宽;可根据工程实际施工方案以及水工建筑物水泥灌浆施工技术规范获取如下施工条件参数:灌浆孔的排序、孔序、孔深以及灌浆压力;可根据根据工程实际施工方案获取如下浆液参数:浆液水灰比。
[0114]
优选地,可基于混沌理论和l
é
vy飞行策略对麻雀搜索算法进行改进,可采用改进的麻雀搜索算法对基学习器和元学习器的模型参数进行同步优化。
[0115]
优选地,基于混沌理论和l
é
vy飞行策略对麻雀搜索算法进行改进的方法可包括:
[0116]
可基于混沌理论进行麻雀种群初始化,可使用tent混沌映射生成混沌序列初始化麻雀位置xp
i,j
,其中i=1,2,3
…
n,n表示麻雀种群的数量,j=1,2,3
…
d,d表示待优化变量的维数。
[0117]
可随机生成[0,1]之间的初始值x
pi,0
,此时j=0。
[0118]
可使用tent混沌映射生成混沌序列:
[0119][0120]
可将混沌序列映射到解的搜索空间,得到混沌初始化种群:
[0121][0122]
可采用l
é
vy飞行策略对探索者、跟随者和侦察者的位置更新公式进行改进,扩大搜索范围提高全局搜索能力,改进后的探索者位置更新公式可如下:
[0123][0124][0125]
改进后的探索者位置更新公式可如下:
[0126][0127]
改进后的探索者位置更新公式可如下:
[0128][0129]
上述各式中:
[0130]
y={yi,i=1,2,3
…
,n}表示响应灌浆量值。
[0131]
f={fi,i=1,2,3
…
,k}表示最终灌浆量预测值。
[0132]
xp表示待优化参数的种群向量集合。
[0133]
i表示麻雀种群中的个体。
[0134]
j表示待优化变量。
[0135]
为使用tent混沌映射得到的混沌初始化种群。
[0136]
xp
min,j
为第j维种群向量值的最小值。
[0137]
xp
max,j
为第j维种群向量值的最大值。
[0138]
表示为第t次迭代时第i个麻雀个体的第j维种群向量值。
[0139]
表示为第t+1次迭代时第i个麻雀个体的第j维种群向量值。
[0140]
t表示当前迭代次数。
[0141]
iter
max
表示最大迭代次数。
[0142]
α∈(0,1)表示随机系数。
[0143]
r2∈[0,1]表示预警值。
[0144]
st∈[0.5,1]表示安全值。
[0145]
是迭代计算的中间变量。
[0146]
表示当前全局最优的位置。
[0147]
⊕
表示点乘积。
[0148]
l
é
vy(λ)表示l
é
vy随机搜索路径。
[0149]
表示当下探索者所占的最优位置,
[0150]
是当前全局最差的位置,
[0151]
n为麻雀种群的个体总数,
[0152]
a表示一个1
×
d的矩阵,其中每个元素取值为1或-1,且a
+
=a
t
(aa
t
)-1
。
[0153]
fb表示当前全局最佳适应度值。
[0154]fw
表示当前全局最差适应度值。
[0155]fi
表示待更新麻雀个体的适应度值。
[0156]
ε为较小常数,防止分母为零。
[0157]
优选地,采用改进的麻雀搜索算法对基学习器和元学习器的模型参数进行同步优化的方法可包括如下步骤:
[0158]
步骤1,可确定种群数量、最大迭代次数、适应度值范围、求解区间范围、探索者比例及侦察者比例。
[0159]
步骤2,采用tent混沌映射初始化种群。
[0160]
步骤3,迭代次数加1。计算麻雀种群适应度值。
[0161]
步骤4,可从适应度值较优的麻雀中选取部分作为探索者,进行位置更新。
[0162]
步骤5,剩余麻雀可作为跟随者,进行位置更新。
[0163]
步骤6,可从麻雀种群中选择部分作为侦察者,进行位置更新。
[0164]
步骤7,计算麻雀种群适应度值。
[0165]
步骤8,判断适应度值是否满足条件,如果不满足则执行步骤9;如果满足则执行步骤10。
[0166]
步骤9,判断迭代次数是否小于最大迭代次数,如果小于最大迭代次数则执行步骤3,否则执行步骤10。
[0167]
步骤10,结束优化,得到最优模型参数。
[0168]
优选地,采用麻雀搜索算法进行优化的模型参数可包括:svr神经网络的惩罚因子和核参数,bpnn神经网络的初始阈值与权值,rf模型的决策树数量n和最大深度h,anfis神经网络的前件参数。
[0169]
下面以本发明的一个优选实施例来进一步说明本发明的工作流程及工作原理:
[0170]
本发明采用能够增加模型多样性、减少过拟合和预测不确定性,产生更准确、更稳健的预测结果的stacking集成学习策略和可以保证初始化种群分布的均匀性和多样性,并且可以克服在搜索过程中可能会出现种群多样性降低进、避免陷入局部最优的改进改进麻雀搜索算法。本发明解决了现有机器学习灌浆量预测模型没有考虑地质参数、灌浆数值模拟计算复杂耗时、单一代理模型精度较低且组合代理模型赋权主观性大的问题。相较于单一代理模型,本发明的预测性能有很大提升,能够实现快速精确的灌浆量预测,从而获得更准确可靠的预测结果,为决策提供指导,保证灌浆的安全和质量;在实际灌浆工程中能够为待灌区域的灌浆量估计提供可靠的方法支撑,具有重要的工程应用价值;同时本文所提模型也为其他工程参数预测提供了新思路,具有良好的工程运用前景。
[0171]
在实际工程中,准确可靠的灌浆量预测对灌浆施工过程控制具有重要意义。针对现有灌浆量预测研究中存在数值模拟方法复杂耗时,而基于单一机器学习方法的代理模型精度较低等不足,采用一种基于issa-stacking的坝基灌浆量预测集成代理模型,快速实现各种地质条件和灌浆工况下的灌浆量准确预测,从而为后续灌浆施工控制和工程量优化提供有效可靠的理论指导。基于issa-stacking的坝基灌浆量预测集成代理模型,具体包括以下步骤:
[0172]
a、获取包括地质属性、施工条件和浆液属性三个因素在内的输入参数。
[0173]
b、生成数据集。
[0174]
c、构建基于stacking的集成代理模型。
[0175]
d、利用改进的ssa优化基于stacking的集成代理模型参数,建立基于stacking的集成代理模型。
[0176]
为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明具体实施方式作进一步地详细描述。
[0177]
1、获取包括地质属性、施工条件和浆液属性三个因素在内的输入参数
[0178]
根据三维精细裂隙网络模型获取裂隙数量、裂隙平均倾向、平均倾角和平均隙宽等裂隙岩体参数;根据工程实际施工措施以及《水工建筑物水泥灌浆施工技术规范》(dl/t5148-2012)确定灌浆孔的排序、孔序、孔深以及灌浆压力;根据工程实际施工措施确定浆液水灰比。
[0179]
2、生成数据集
[0180]
基于裂隙岩体参数样本空间,利用拉丁超立方(lhs)抽样方法抽取多组地质参数,将其与不同的施工参数和浆液特性参数进行组合,构建具有代表各种裂隙地质条件及施工工况的参数样本点。将参数样本点带入基于三维精细裂隙建模的灌浆数值模拟模型中计算获得灌浆量模拟值,由此生成参数样本点与对应灌浆量模拟值构成的数据集,并进一步按
比例将数据集划分为训练集和测试集。
[0181]
3、构建基于stacking的集成代理模型
[0182]
将上述获得的数据训练集使用五折交叉验证对svr、bpnn和rf三个基学习器进行训练,提高模型整体泛化性和多样性。将得到的预测结果与模拟响应值构成新的训练集来训练anfis元学习器,在考虑预测过程不确定性的情况下实现对基学习器结果的归纳融合,方法流程如图1所示。具体步骤如下:
[0183]
3-1,将由输入数据和灌浆量模拟值组成的样本数据集(x,y)按比例划分为训练集(x
tr
,y
tr
)和测试集(x
te
,y
te
);
[0184]
3-2,采用五折交叉验证对svr、bpnn、rf基学习器进行训练,并得到一个预测结果p
tr-j
,该过程重复五次,得到各基学习器对整个原始训练集的预测结果p
tr-svr
={p
tr-j
,j=1,2,3,4,5}、p
tr-bpnn
={p
tr-j
,j=1,2,3,4,5}和p
tr-rf
={p
tr-j
,j=1,2,3,4,5}。与原始训练集中的响应值构建成新训练集(p
tr
,y
tr
)用于训练元学习器anfis,其中p
tr
={p
tr-svr
,p
tr-bpnn
,p
tr-rf
};
[0185]
3-3,在测试过程中,各个已经训练好的基学习器分别获得原始测试集相应的预测结果,并与原始测试集中的响应值构建成新测试集(p
te
,y
te
)用于测试已经训练好的元学习器anfis,其中p
te
={p
te-svr,p
te-bpann,p
te-rf}。由此得到最终预测结果f
te
={fi,i=1,2,3
…
,k}。
[0186]
3-4,利用改进的ssa优化基于stacking的集成代理模型参数,建立基于stacking的灌浆量集成代理预测模型。
[0187]
采用混沌理论和l
é
vy飞行策略改进的麻雀搜索算法对基学习器和元学习器的模型参数进行同步优化,进而建立基于stacking的灌浆量集成代理预测模型,实现灌浆量的高精度预测。具体步骤如下:
[0188]
3-4-1,采用混沌理论进行麻雀种群初始化,使用tent混沌映射生成混沌序列初始化麻雀位置x
pi,j
,其中i=1,2,3
…
n,n表示麻雀种群的数量,j=1,2,3
…
d,d表示待优化变量的维数。
[0189]
a、随机生成[0,1]之间的初始值x
pi,0
,此时j=0。
[0190]
b、使用tent混沌映射生成混沌序列:
[0191][0192]
c、将混沌序列映射到解的搜索空间,得到混沌初始化种群:
[0193][0194]
式中,xp
min,j
,xp
max,j
分别为第j维的最小值和最大值。
[0195]
3-4-2,采用l
é
vy飞行策略对探索者、跟随者和侦察者的位置更新公式进行改进,扩大搜索范围提高全局搜索能力,改进后的探索者位置更新公式如下:
[0196][0197]
式中t表示当前迭代次数,iter
max
表示最大迭代次数,α∈(0,1)是一个随机数,r2∈[0,1]代表预警值,st∈[0.5,1]代表安全值。是当前全局最优的位置,
⊕
是点乘积,l
é
vy(λ)是l
é
vy随机搜索路径。
[0198]
改进后的探索者位置更新公式如下:
[0199][0200]
式中表示当下探索者所占的最优位置,是当前全局最差的位置,a表示一个1
×
d的矩阵,其中每个元素取值为1或-1,且a
+
=a
t
(aa
t
)-1
。
[0201]
改进后的探索者位置更新公式如下:
[0202][0203]
式中,fb和fw分别是当前全局最佳适应度值和最差适应度值。fi为表示待更新麻雀个体的适应度值;ε为较小常数,作用是防止分母为零。
[0204]
3-4-2,利用上述提出的具有更加优越的全局搜索能力和收敛性能的issa对基于stacking的集成代理模型中各个机器学习算法进行参数同步优化。
[0205]
基于stacking的集成代理模型的预测性能受到以下参数影响:主要包括svr的惩罚因子c和核参数g,bpnn的初始阈值b与权值w,rf的决策树数量n和最大深度h以及anfis的前件参数ai、bi、ci。基于issa的参数搜索过程可以转化为如下优化问题:
[0206][0207]
式中,y={yi,i=1,2,3
…
,n}和f={fi,i=1,2,3
…
,n}分别代表响应灌浆量值和最终灌浆量预测值,xp表示待优化参数的种群向量集合,xp
lb
和xp
ub
分别为待优化参数的取值下限和上限。由此构建出基于issa-stacking的集成代理模型。
[0208]
以上所述的实施例仅用于说明本发明的技术思想及特点,其目的在于使本领域内的技术人员能够理解本发明的内容并据以实施,不能仅以本实施例来限定本发明的专利范围,即凡本发明所揭示的精神所作的同等变化或修饰,仍落在本发明的专利范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1