并行训练中突破内存限制的方法、系统、设备及存储介质
1.本发明涉及深度学习并行训练技术领域,尤其涉及一种并行训练中突破内存限制的方法、系统、设备及存储介质。
背景技术:
2.2019年美国微软公司,卡耐基梅隆大学和斯坦福大学的深度学习团队在sosp(acm symposium on operating systems principles)会议上发表分布式深度学习并行训练系统pipedream(pipedream: generalized pipeline parallelism for dnn training),同年在开源社区github上开源。该系统做流水线并行时,每个gpu设备(又称工作者)都负责训练一组不相交的连续模型层;并按照原整体模型层前后向计算顺序,把模型层组间的数据传递给下一个gpu(图形处理器)设备。为了充分利用gpu设备计算资源,每个gpu会维护多个版本的中间数据和参数,但是在1台有8张nvidia 1080ti gpu设备的服务器上进行批处理量大于128的resnet152模型训练,和参数量大于6.4亿的bert模型训练时都出现了内存不足的错误,而此时整个模型内存消耗仅占8个gpu内存总和的68.9%和88.7%。本质原因在于中间数据在每个微批的前向计算时产生,在对应的后向计算时才被消耗,导致训练模型靠前部分的gpu积累更多的中间数据,使得内存占用不均衡,占用最多的设备甚至是最少的7.9倍。为了降低gpu内存占用,该系统可以开启反向重计算,但是会使得反向计算时间增加50%;出于同样的目的,2020年美国纽约大学深度学习团队在asplos(architectural support for programming languages and operating systems)会议上发表深度学习并行训练内存压缩系统swapadvisor(swapadvisor: push deep learning beyond the gpumemory limit via smart swapping),其中提出了把空闲数据交换到cpu(中央处理器)内存,下次需要时再从cpu内存交换到gpu内存。但是与用于gpu间直连的nvlink2.0(一种总线及其通信协议)带宽相比,cpu和gpu之间经过pcie gen3x16链路交换数据的速度仅为16gb/s,是gpu间直连链路nvlink2.0带宽的10.7%,传输速率过低也将影响训练效率。有鉴于此,有必要研发突破内存限制的方案,以提升训练效率。
技术实现要素:
3.本发明的目的是提供一种并行训练中突破内存限制的方法、系统、设备及存储介质,通过使用异构内存,混合多种内存压缩方式突破内存限制,从而提高训练效率。
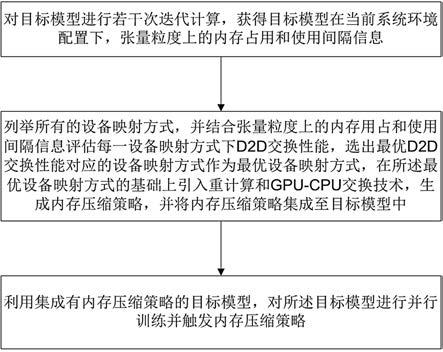
4.本发明的目的是通过以下技术方案实现的:一种在深度学习并行训练场景下突破内存限制的方法,包括:对目标模型进行若干次迭代计算,获得目标模型在当前系统环境配置下,每个张量的内存占用和使用间隔信息;根据每个张量的内存占用和使用间隔信息,选择使用d2d交换方式、重计算方式或gpu-cpu交换技术生成内存压缩策略,并将相应内存压缩策略集成至目标模型中;如果选择使用d2d交换,则列举所有的设备映射方式,评估每一设备映射方式下d2d交换性能,选出最
优d2d交换性能对应的设备映射方式作为最优设备映射方式;其中,d2d为设备到设备通信,gpu为图形处理器,cpu为中央处理器;利用集成有内存压缩策略的目标模型,对所述目标模型进行并行训练并触发内存压缩策略。
5.一种在深度学习并行训练场景下突破内存限制的系统,包括:剖析器,用于对目标模型进行若干次迭代计算,获得目标模型在当前系统环境配置下,每个张量的内存占用和使用间隔信息;规划者,用于根据每个张量的内存占用和使用间隔信息,选择使用d2d交换方式、重计算方式或gpu-cpu交换技术生成内存压缩策略,并将相应内存压缩策略集成至目标模型中;如果选择使用d2d交换,则列举所有的设备映射方式,评估每一设备映射方式下d2d交换性能,选出最优d2d交换性能对应的设备映射方式作为最优设备映射方式;改写器,用于并将内存压缩策略集成至目标模型中;模型训练与内存压缩单元,用于利用集成有内存压缩策略的目标模型,对所述目标模型进行并行训练并触发内存压缩策略。
6.一种处理设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述的方法。
7.一种可读存储介质,存储有计算机程序,当计算机程序被处理器执行时实现前述的方法。
8.由上述本发明提供的技术方案可以看出,通过计算训练任务和gpu之间的最佳映射,以最大限度地利用d2d(设备到设备通信)的性能优势,充分利用系统内存,聚合gpu间多条直连高速链路,获得高倍速通信带宽;此外,本发明混合采用了重新计算、gpu-cpu交换,以进一步增加d2d交换的潜力,使得模型训练能够突破内存限制。
附图说明
9.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
10.图1为本发明实施例提供的一种并行训练中突破内存限制的方法的流程图;图2为本发明实施例提供的并行训练中突破内存限制方法的架构及运行流程图;图3为本发明实施例提供的设备拓扑结构示意图;图4为本发明实施例提供的交换技术的训练任务示意图;图5为本发明实施例提供的一种并行训练中突破内存限制的系统的示意图;图6为本发明实施例提供的一种处理设备的示意图。
具体实施方式
11.下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本
发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
12.首先对本文中可能使用的术语进行如下说明:术语“和/或”是表示两者任一或两者同时均可实现,例如,x和/或y表示既包括“x”或“y”的情况也包括“x和y”的三种情况。
13.术语“包括”、“包含”、“含有”、“具有”或其它类似语义的描述,应被解释为非排它性的包括。例如:包括某技术特征要素(如原料、组分、成分、载体、剂型、材料、尺寸、零件、部件、机构、装置、步骤、工序、方法、反应条件、加工条件、参数、算法、信号、数据、产品或制品等),应被解释为不仅包括明确列出的某技术特征要素,还可以包括未明确列出的本领域公知的其它技术特征要素。
14.下面对本发明所提供的一种并行训练中突破内存限制的方法、系统、设备及存储介质进行详细描述。本发明实施例中未作详细描述的内容属于本领域专业技术人员公知的现有技术。本发明实施例中未注明具体条件者,按照本领域常规条件或制造商建议的条件进行。本发明实施例中所用试剂或仪器未注明生产厂商者,均为可以通过市售购买获得的常规产品。
15.实施例一本发明实施例提供一种并行训练中突破内存限制的方法,应用于分布式深度学习流水线并行训练场景下,采用了一种新颖d2d交换技术,在目标模型计算的同时,同时利用多个链接将张量交换到内存轻载的gpu,并混合采用了重新计算和gpu-cpu数据交换技术,以进一步增加d2d交换的潜力,进而突破内存限制对模型训练的影响,使得模型训练更高效。图1为了本发明上述方法的流程图,图2为本发明的架构及运行流程图,图3为本发明中设备拓扑结构示意图(所涉及的各设备数目以及速率均为举例)。如图1所示,上述方法主要包括如下步骤:步骤1、对目标模型进行若干次迭代计算,获得目标模型在当前系统环境配置下,每个张量的内存占用和使用间隔信息。
16.本发明实施例中,为了统计每个张量的大小,和其参与前向与后向计算的时间间隔,使用目标模型和批量大小在一段可容忍的时间段内,训练目标模型,从而得到目标模型在当前系统环境配置下,张量粒度上的内存占用和使用间隔信息。具体的:模型正式开始训练前,在一段可容忍的时间段内(时间段的具体大小可根据实际情况或者经验进行设定),在当前系统环境配置下,对目标模型进行若干次迭代计算,依照计算顺序,遍历与目标模型中每个模型层相关的张量,读取相关的张量的gpu内存占用大小信息;并在目标模型的前向计算和后向计算时,以张量为粒度,记录时间戳,获得张量的使用间隔。
17.本发明实施例中,目标模型的具体类型及结构可根据实际情况自行设定,张量的具体信息也根据目标模型的类型与训练数据的类型来确定。例如,可以选择dnn(全连接神经网络)作为目标模型,输入训练图像,通过dnn提取图像特征张量。
18.如图2所示,本步骤可通过剖析器(profiler)实现,对应于图2中的第
①
步。
19.步骤2、根据每个张量的内存占用和使用间隔信息,选择使用d2d交换方式、重计算方式或gpu-cpu交换技术生成内存压缩策略,并将相应内存压缩策略集成至目标模型中;如果选择使用d2d交换,则列举所有的设备映射方式,评估每一设备映射方式下d2d交换性能,
选出最优d2d交换性能对应的设备映射方式作为最优设备映射方式。
20.如图2所示,规划者(planner)负责生成内存压缩策略(也即图2中的第
②
步),用以决定系统中的各个张量应该采用哪种内存压缩策略,以及采用压缩策略的时间,恢复数据的时间,以确保目标模型既能突破内存限制,又能高效地训练。
21.本发明实施例中,张量的内存占用和使用间隔信息是用于指导决定张量的内存压缩策略。对于使用间隔非常短的(即使用间隔小于第一设定值),倾向于用d2d交换,使用间隔非常长的(即使用间隔大于第二设定值),更倾向于gpu-cpu交换。对于每个张量都需要进行子块的划分,划分子块时,要考虑子块的内存大小是否小于其他gpu上的空闲内存,以及传输到其他gpu上的时间开销是否能接受,如果其他gpu上的空闲内存不够(即子块的内存大小小于其他gpu上的空闲内存),或是时间开销大于使用间隔,则选择重计算方式或gpu-cpu交换技术;否则,选择d2d交换方式。
22.内存压缩的决策依靠以下两个步骤:1)最大化挖掘d2d交换技术的性能;2)合理规划使用重计算和gpu-cpu交换技术,以更充分的使用d2d交换技术。对于所有张量通过结合以上两个步骤生成较为理想的内存压缩策略。
23.1)最大化挖掘d2d交换技术的性能。
24.由于流水线并行训练模型时,不同gpu上内存需求不同,并且点对点nvlink链路是有限的,因此,需要将训练各阶段合理地映射到各个gpu设备上。为了得到最佳的训练任务与设备映射方式,获得更高的d2d聚合带宽,运行图相关算法,来列举所有可能的设备映射。
25.运行的算法内容如下:1
ꢀꢀ
#spare mem assignment from the view of a single gpu2
ꢀꢀ
defassign_mem(gpu,dev_map)3
ꢀꢀꢀꢀꢀ
spare_amount= mem_cap - men_use[gpu]4
ꢀꢀꢀꢀꢀꢀ
set nbhs = all nvlink neighbors of gpu in dev_map5
ꢀꢀꢀꢀꢀꢀꢀ
set exporters = overflowed gpus6
ꢀꢀꢀꢀꢀꢀ
set candidates = nbhs∩ exporters7
ꢀꢀꢀꢀꢀꢀ
set plans = all possible ways to distribute mem of
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
spare _ amount to candidates8
ꢀꢀꢀꢀꢀꢀꢀ
return plans10
ꢀꢀ
def
ꢀꢀ
device _ mapping _ search():11
ꢀꢀꢀꢀꢀꢀ
best_score= 012
ꢀꢀꢀꢀꢀꢀ
best_dev_map = none13
ꢀꢀꢀꢀꢀꢀ
set all_map = enumeration with no mem constrains14
ꢀꢀꢀꢀꢀꢀ
for dev_map in all_map15
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
all_plans = []16
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
for g in all_gpus:17
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
if g has spare mem:18
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
all_plans . add ( assign_mem (g,dev_map) )19
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
# combiningsingle gpu's plans20
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
concat_plans = permutation (all_plans)
21
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
for plan in concat_plans22
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
score = ratio of revenue to cost23
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
if score 》 best score:24
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
best score = score25
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
best_dev_map = dev_map26
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
return best_dev_map关于上述算法的说明如下:对于每个设备映射,首先从单个gpu的角度确定所有可能的空闲内存分配方案(第1-8行),并将这些方案结合到全局交换计划(第14-20行)。最后,我们通过使用评分函数对所有候选方案进行评估,选择最佳方案 (第21-26行)。第10-13行是启动算法时参数的初始化。第1-8行的功能是从单个gpu的角度确定所有可能的空闲内存分配方案,流程如下:计算当前gpu上的空闲内存大小spare_amount;确定于当前gpu有直连链路(有nvlink链路)的gpu集合nbhs;确定在设备映射dev_map下,内存会溢出的gpu集合exporters;当前gpu上的空闲内存将会分配给其他gpu集合candidates,candidates是内存会溢出(溢出指内存不够用)并且与当前gpu直连的gpu集合;然后枚举所有把当前gpu上空闲内存分配给candidates的所有方案集合plans。第14-20行的功能是,枚举所有的设备映射方案(第14行),对于每个设备映射方案,再枚举每个设备的内存分配方案(第16-18行);第20行,对每个设备的内存分配方案排列组合,得到在当前设备映射方案dev_map下,所有设备的所有内存分配方案concat_plans。
[0026]
设备映射的评估方式为:通过数据加权切片,将选定的目标张量划分为多个子块,子块的大小与相应的链接带宽(直连的gpu设备间的带宽)成正比,按照每一设备映射方式,将多个子块通过多个不相干的nvlink链路并行传输(由设备映射方式决定),实现将一个gpu设备上的张量交换到多个的gpu设备上;评分函数评估了设备映射、从轻载的gpu到高内存压力的gpu,以及可用gpu内存分配的有效性和效率。评分分数计算为固定分配的d2d交换的最大时间成本的倒数。当分数越高,d2d交换的整体性能就越好,从高负载的gpu卸载模型数据的整体性能就会降低。最后,确定最好的设备映射加上空闲的gpu内存分配,作为最高分。
[0027]
本发明实施例中,gpu设备间链路带宽是不同的,不同的原因是,gpu设备间的直连的nvlink链路数量是不同的,一条nvlink链路的带宽是25gb/s,两条nvlink链路的带宽是50gb/s;例如图3中,gpu0和gpu3之间的带宽是50gb/s,和gpu0和gpu1之间的带宽是25gb/s,gpu0和gpu6之间没有直连(没有nvlink),也就不能传输。设备映射时,目标张量划分的子块大小与链接带宽成正比,也就是说,带宽较高的gpu设备承担较多的数据量。
[0028]
上述每一设备映射方式评估过程中,将一个gpu设备上的张量尽可能地交换到更多的gpu上,使得聚合多条高速点对点nvlink链路,进而获得更高倍速的输出传输带宽。
[0029]
2)更充分的使用d2d交换技术。
[0030]
通过进行活变量分析,计算每个张量的活跃间隔,将gpu-cpu交换分配给具有极长活期间隔的张量,具有极长活期间隔是指活期间隔超过设定阈值,阈值大小可根据实际情况或者经验进行设定;当对一张量采用重计算后引入的时间开销低于gpu-cpu交换时,则对相应张量采用重计算的内存压缩策略,再将gpu-cpu交换用于剩余的张量,以达到节约gpu内存占用;当对一张量采用重计算后引入的时间开销高于gpu-cpu交换时,则对相应张量采
用gpu-cpu交换的内存压缩策略。这个部分,一般需要通过多个迭代步骤来逐步更新减少内存的优化分配,减少两个连续分配之间的额外时间延迟。
[0031]
本领域技术人员可以理解,张量有活跃区间和非活跃区间,两个活跃区间之间即为活跃间隔,也就是非活跃区间。
[0032]
优选的,在每一步,模拟运行最新的分配,若新更配性能更优,则更新分配;若后续的分配比前一个分配带来了不可见的性能提升,这个算法就会终止。具体来说:将内存压缩策略集成至目标模型中后,模拟运行集成有内存压缩策略的目标模型,对内存压缩策略进行评估,以确定内存压缩策略是否为最佳内存压缩策略;若不为最佳内存压缩策略,则对内存压缩策略进行优化,直至获得最佳内存压缩策略;将所述最佳内存压缩策略集成至目标模型中,再进行并行训练并触发内存压缩策略。
[0033]
如图2所示,改写器(rewriter)负责将内存压缩策略集成到目标模型中(也即图2中的第
③
步),具体的,改写器以保证运算符的依赖性为原则,把张量粒度的内存压缩策略集成到目标模型中。模拟器(emulator)用于模拟运行集成有内存压缩策略的目标模型,对内存压缩策略进行评估(也即图2中的第
④
步),以权衡内存压缩策略的gpu内存节省收益和性能损失,从而确定生成的策略是否接近于最佳配置,并将评估结果反馈会规划者(planner)(也即图2中的第
⑤
步)。规划者再次根据收到的反馈微调更新内存压缩策略,如此循环迭代图2中第
③
,
④
,
⑤
步,以收敛到最终的内存压缩策略作为输出,并集成在目标模型中传递给下一步运行时模型训练部分。
[0034]
步骤3、利用集成有内存压缩策略的目标模型,对所述目标模型进行并行训练并触发内存压缩策略。
[0035]
本发明实施例中,在步骤2提供的优选方案基础上执行步骤3,即目标模型中集成有最佳内存压缩策略,将其作为输入,按照内存压缩策略执行并行训练;没有内存压缩策略的运算符需要通过底层训练框架的执行,而有内存压缩策略的运算符还需要执行节省内存的操作(例如,卸载,重计算),以释放已使用的gpu内存和恢复状态的操作(例如,换入,重新计算),以满足其下一次使用。执行并行训练过程中,为张量分配和释放gpu设备与cpu设备内存空间,并跟踪每个设备(gpu设备与cpu设备)的内存使用情况;此外,还需要维护一个元数据表,跟踪经过d2d交换或gpu-cpu交换的张量的状态;张量的状态用一个标签表示,用于区分张量是驻留在内存,还是已经被交换到了其他gpu上,还是正在被交换出或交换进。对于每个张量,在执行卸载操作之前记录如下信息:数据块的数量、每个数据块的大小和目标gpu设备的索引;其中,数据块是张量片段;对张量切片,形成张量片段,用于同时将不同的张量片段发送到不同的gpu上;所记录的信息被用来指导后续取回操作。
[0036]
图2中包含三个关键的系统组件,即执行器(executor)、内存管理器(memory manager)和内存压缩库(compaction library)。执行器按照内存压缩策略执行并行训练内存管理器按照执行者的命令接管内存分配/再分配的工作,内存压缩库需要提供三种支持内存节省优化的有效实现,包括:d2d交换,gpu-cpu交换以及重计算技术。运行时的工作流程如下:执行器把集成有内存压缩策略的目标模型作为输入(图2中的第
⑥
步),触发支持内存压缩的计算间并行训练。除了节省内存的运算符外,普通运算符直接通过底层训练框架的执行(图2中的第
⑨
步),可以理解为:没有集成内存压缩的运算符如传统方案一样,仍在底层训练框架中执行;而集成了内存压缩的运算符既需要执行在mpressruntime集成的内
存压缩,还要执行在底层训练框架中计算;其中,m表示内存(memory),press表示压缩,mpress表示内存压缩。执行者执行节省内存的计算(即交换出、放弃),以释放已使用的gpu内存,以及恢复状态的操作(即交换入、重新计算),以完成它们的任务,恢复状态的操作用以满足其下一次使用(图2中的第
⑧
步)。在执行过程中,内存管理器通过遵循执行者的命令,接管内存的实际分配/再分配(图2中的第
⑦
步)。第
⑦
与第
⑧
步可以理解为:对集成有内存压缩策略的目标模型进行解析,根据内存压缩策略提供相关的内存管理策略,并且在第
⑧
步中将执行内存压缩策略的代码库集成到模型中,供底层训练框架的执行。具体的:图2的第
⑦
步中内存管理器为张量分配和释放gpu设备/cpu设备内存空间,并跟踪每个设备的内存使用情况。首先,对于gpu内存的分配,管理器直接使用pytorch的本地gpu内存分配器。其次,在cpu主机内存请求时,相较于pageable memory(页内存),使用传输给gpu更快的pinned memory作为交换空间。为了避免为分配和释放pinned memory(固定内存)带来高额性能开销,需进一步建立了一个pinned memory pool(固定内存池),与pytorch模型训练并行,pytoch是底层训练框架(即,图2中的pytorch engine),也就是说,目标模型与底层训练框架的执行相并行。图2的第
⑧
步,pytorch中支持了重计算,对于d2d交换,执行器管理着两个额外的线程,分别用于执行换入和换出任务。这两个线程使用两个不同的cuda流,在系统启动时调用cudastreamcreate工具创建。这种设计允许执行者启动张量传输任务,并在不阻塞主线程的情况下检查目标模型的计算状态。因此,gpu设备之间的数据移动可以与目标模型的计算异步进行。
[0037]
gpu-cpu交换和d2d交换的执行如图4所示,图4中,l是layer的简写,表示构成目标模型的一个计算层,l后面的数字表示计算层的标号,体现计算顺序,w是weight的简写表示计算层中的模型参数,w
lj
表示,第j个计算层中的模型参数;w’lj
表示在update计算更新后的模型参数;右下角cpu/other gpu表示,把当前gpu上的模型参数交换到cpu内存上或者是其他gpu内存上,交换到cpu上即为前文中提到的gpu-cpu 交换技术,交换到gpu即为前文提到的d2d技术。
[0038]
本发明实施例上述方案,在分布式深度学习流水线并行训练场景下,使用异构内存,混合多种内存压缩方式突破内存限制的方法,与传统方法相比:一方面,本发明计算出训练任务和gpu之间的最佳映射,以最大限度地利用d2d的性能优势,充分利用系统内存,聚合gpu间多条直连高速链路,获得高倍速通信带宽;另一方面,本发明混合采用了重新计算、gpu-cpu交换,以进一步增加d2d交换的潜力,使得模型训练能够突破内存限制,从而提高训练效率。
[0039]
实施例二本发明还提供一种在深度学习并行训练场景下突破内存限制的系统,其主要基于前述实施例提供的方法实现,如图5所示,该系统主要包括:剖析器,用于对目标模型进行若干次迭代计算,获得目标模型在当前系统环境配置下,每个张量的内存占用和使用间隔信息;规划者,用于根据每个张量的内存占用和使用间隔信息,选择使用d2d交换方式、重计算方式或gpu-cpu交换技术生成内存压缩策略,并将相应内存压缩策略集成至目标模型中;如果选择使用d2d交换,则列举所有的设备映射方式,评估每一设备映射方式下d2d交换性能,选出最优d2d交换性能对应的设备映射方式作为最优设备映射方式;
改写器,用于并将内存压缩策略集成至目标模型中;模型训练与内存压缩单元,用于利用集成有内存压缩策略的目标模型,对所述目标模型进行并行训练并触发内存压缩策略。
[0040]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将系统的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
[0041]
实施例三本发明还提供一种处理设备,如图6所示,其主要包括:一个或多个处理器;存储器,用于存储一个或多个程序;其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述实施例提供的方法。
[0042]
进一步的,所述处理设备还包括至少一个输入设备与至少一个输出设备;在所述处理设备中,处理器、存储器、输入设备、输出设备之间通过总线连接。
[0043]
本发明实施例中,所述存储器、输入设备与输出设备的具体类型不做限定;例如:输入设备可以为触摸屏、图像采集设备、物理按键或者鼠标等;输出设备可以为显示终端;存储器可以为随机存取存储器(random access memory,ram),也可为非不稳定的存储器(non-volatile memory),例如磁盘存储器。
[0044]
实施例四本发明还提供一种可读存储介质,存储有计算机程序,当计算机程序被处理器执行时实现前述实施例提供的方法。
[0045]
本发明实施例中可读存储介质作为计算机可读存储介质,可以设置于前述处理设备中,例如,作为处理设备中的存储器。此外,所述可读存储介质也可以是u盘、移动硬盘、只读存储器(read-only memory,rom)、磁碟或者光盘等各种可以存储程序代码的介质。
[0046]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1