一种端到端的图片文字实体抽取方法
1.本发明涉及图像文字识别技术领域,具体涉及一种端到端的图片文字实体抽取方法。
背景技术:
2.图像识别技术是人工智能技术领域中非常重要的发展方向。其中,图像中文字识别技术尤为重要,因为图片中的文字比单纯的图像承载了更多的有用信息,文字识别一般是识别字母、数字、符号、文字,应用非常广泛。
3.随着人工智能技术的飞速发展,图像文字识别技术也越来越成熟,从vgg文字分类,到cnn+rnn的端到端文字识别技术,再到gru+ctc端到端的文字识别技术等等,文字识别的应用范围也越来越广,票据证件识别、车牌识别、交通标识识别等等。图片文字识别达到了99%的准备率,但是有一些场景并不需要识别全部的文字,而是识别重要的文字,比如简历中要识别出姓名,住址,学历,参加比赛经历,所做的项目名称等等,退货的图片要识别出收件人、寄件人、手机号、收件人地址、寄件人地址等等。
4.现有的技术在识别图片中的文字的重要的实体的时候,一般先通过图片文字识别的方法提取出图片中的文字,然后再利用命名实体识别的方法对提取出的文字进行命名实体识别,但是这样做识别效率低下,而且并不是端到端的训练方法,导致识别准确率较低。
5.现有技术采用ocr技术提取出图片中的文字,再将提取后的文字送入命名实体识别模型中,得到命名实体,首先,利用ocr技术提取图片中的文字存在误差,这个误差将会第二阶段命名实体识别中继续放大,而且,ocr技术对于一些复杂图片中的文字,提取效果并不好,可能会文字的先后顺序弄混淆,二阶段的识别效率低下,达不到实时的效果。
技术实现要素:
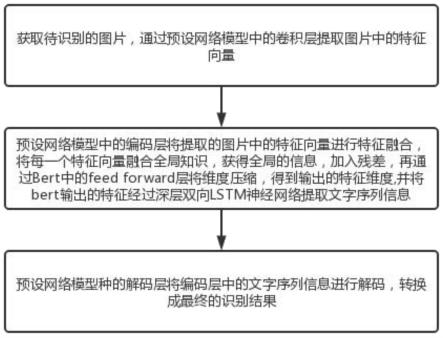
6.本发明的目的在于提供一种端到端的图片文字实体抽取方法,包括以下步骤:步骤一:获取待识别的图片,通过预设网络模型中的卷积层提取图片中的特征向量;步骤二:预设网络模型中的编码层将提取的图片中的特征向量进行特征融合,将每一个特征向量融合全局知识,获得全局的信息,加入残差,再通过bert中的feed forward层将维度压缩,得到输出的特征维度,并将bert输出的特征经过深层双向lstm神经网络提取文字序列信息;步骤三:预设网络模型种的解码层将编码层中的文字序列信息进行解码,转换成最终的识别结果,利用了cnn卷积网络+albert+bilstm+crf解码的网络架构,能够处理图片中不定长的文字。
7.本发明的目的可以通过以下技术方案实现:
8.一种端到端的图片文字实体抽取方法,包括以下步骤:
9.步骤一:获取待识别的图片,通过预设网络模型中的卷积层提取图片中的特征向量;
10.步骤二:预设网络模型中的编码层将提取的图片中的特征向量进行特征融合,将
每一个特征向量融合全局知识,获得全局的信息,加入残差,再通过bert中的feed forward层将维度压缩,得到输出的特征维度,并将bert输出的特征经过深层双向lstm神经网络提取文字序列信息;
11.步骤三:预设网络模型种的解码层将编码层中的文字序列信息进行解码,转换成最终的识别结果。
12.作为本发明进一步的方案:卷积层提取图片中的特征向量的特征图尺寸为1*s*d;
13.其中,s表示每张图片的特征序列数,d表示每个特征序列的维度。
14.作为本发明进一步的方案:编码层采用bert编码,bert编码中针对每一个特征向量的位置信息引入有位置编码向量。
15.作为本发明进一步的方案:编码层的编码方式为旋转位置编码,旋转位置编码公式为:
16.pe(pos,2i)=sin(pos/10000
2i/d
),
17.pe(pos,2i+1)=cos(pos/10000
2i/d
),
18.其中,2i表示位置、表示偶数位,2i+1表示奇数位,pos代表了向量在相应维度的数值,d表示向量的维度。
19.作为本发明进一步的方案:编码层的编码方式还能够为线性编码方式。
20.作为本发明进一步的方案:bert编码的结构包括多头注意力机制层和feed forward层;
21.步骤一中的特征向量首先进入多头注意力机制层获得全局的信息,加入残差,再进入feed forward层将维度压缩,重复操作为6次。
22.作为本发明进一步的方案:深层双向lstm神经网络采取stack形深层双向rnn网络,将深层双向lstm神经网络的输出做softmax,得到实体概率的输出。
23.作为本发明进一步的方案:预设网络模型中的解码层嵌入有crf解码层。
24.作为本发明进一步的方案:预设网络模型在图片文字实体抽取前,还包括预设网络模型的训练,训练步骤为:
25.s1:收集大量带有文字的图片,并将图片缩放到同样的高度,对这些图片中的文字进行数据分布统计,并进行采样,确保实体的分布平均;
26.s2:选定实体类型,对图片中的文字进行标注;
27.s3:用pytorch搭建卷积网络,并用鸢尾花图片识别卷积网络的参数进行初始化;
28.s4:确定使用场景,针对特殊的使用场景,利用网络爬虫技术爬取相关的大量的五标注预料进行预训练;
29.s5:使用transformers官网提供的bert模型,利用transformer官网提供的预训练接口,在步骤s4提供的数据集上进行再次训练,获取特定场景的语义信息;
30.s6:利用pytorch搭建双向lstm网络和crf解码层;
31.s7:搭建完整网络架构;将s3的卷积网络和s5的albert模型和s6的bilstm网络和crf层进行结合;
32.s8:选取训练参数,进行网络训练和微调,保存网络模型;
33.s9:测试阶段,将图片经过s1预处理,然后将图片输入到s8保存的模型中,获取图片文字的实体;
34.s10:对s9中需要的实体进行过滤,输出目标实体。
35.本发明的有益效果:本发明利用了卷积神经网络+bert模型+深层双向lstm神经网络+crf模型的网络架构,不仅能够处理图片中不定长的序列,而且也可以端到端进行训练,提高了模型的识别准确性和鲁棒性。
附图说明
36.下面结合附图对本发明作进一步的说明。
37.图1是本发明流程图的结构示意图;
38.图2是本发明bert的输入流程图的结构示意图;
39.图3是本发明对深层双向lstm神经网络采取stack形深层双向rnn网络的结构示意图。
具体实施方式
40.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
41.请参阅图1所示,本发明为一种端到端的图片文字实体抽取方法,包括以下步骤:
42.步骤一:获取待识别的图片,通过预设网络模型中的卷积层提取图片中的特征向量;
43.步骤二:预设网络模型中的编码层将提取的图片中的特征向量进行特征融合,将每一个特征向量融合全局知识,获得全局的信息,加入残差,再通过bert中的feed forward层将维度压缩,得到输出的特征维度,并将bert输出的特征经过深层双向lstm神经网络提取文字序列信息;
44.步骤三:预设网络模型种的解码层将编码层中的文字序列信息进行解码,转换成最终的识别结果。
45.步骤一中,卷积层对对一张图片进行卷积和最大池化操作;
46.具体的,在训练前,先把图片缩放到相同的高度,图片的宽度保持不变,高度取32,若一张图片的大小为高度为32,宽度为w,那么经过卷积层输出特征向量的特征图大小为512是每个特征的维度,表示这张图片有个特征序列,每个序列512个维度。
47.步骤二中,编码层采用bert编码,输入特征图大小为的特征向量,bert的输入如图2所示;
48.其中,features vector是卷积层输出的特征向量,长度为维度为512,position embeddings是为了体现出每一个特征向量的位置信息而引入的位置编码向量,bert编码方式采用旋转位置编码,旋转位置编码的公式如下:
49.pe(pos,2i)=sin(pos/10000
2i/d
),
50.pe(pos,2i+1)=cos(pos/10000
2i/d
),
51.其中,2i表示位置、表示偶数位,2i+1表示奇数位,pos代表了向量在相应维度的数值,d表示向量的维度;
52.bert编码的结构包括多头注意力机制层和feed forward层;
53.步骤一中的特征向量首先进入多头注意力机制层,获得全局的信息,加入残差,再进入feed forward层将维度压缩,该过程中也加入残差,重复这样的操作n次(n一般设为6),得到输出的特征,输出特征的维度和输入的维度为一致,输出的特征加入了全局的信息,使语义更好地表达。
54.进一步的,bert输出的结果经过深层双向lstm神经网络进一步提取文字序列信息,对深层双向lstm神经网络采取stack形深层双向rnn网络,具体结构如图3所示:
55.其中,bert输出的一个样本特征向量是大小,即最大的时间长度为将深层双向lstm神经网络的输出做softmax,得到实体概率的输出。
56.基于在深层双向lstm神经网络处理过程中,直接用隐藏层向量去预测标签的概率,在命名实体识别的任务中,输出标签存在一定的约束关系,这些约束关系是深层双向lstm神经网络无法表示出来的,因此,在步骤三中,预设网络模型中的解码层嵌入有crf解码层,即在深层双向lstm神经网络中嵌入crf模型,利用crf模型计算输出的yt值;
57.具体的:
58.在条件随机场中,每个特征函数有下面几个输入值:一个句子x,一个单词在句子中的位置i,当前单词的标签li,前一个单词的标签l
i-1
、输出一个实数,首先定义句子x输出标签序列y的分值s(x,y)的计算公式:
[0059][0060]
其中,a是转移矩阵,表示将所有状态一步转移的概率;p是深层双向lstm神经网络输出的矩阵,p
i,j
是假设从第i个字到第j个字体作为一个实体的分值,根据s(x,y)的值选择y;
[0061]
输出y
*
=argmaxs(x,y
′
),其中y
″
∈y
x
,y
x
表示y所有可能的标签序列。
[0062]
预设网络模型在图片文字实体抽取前,预设网络模型的训练步骤为:
[0063]
s1:收集大量带有文字的图片,并将图片缩放到同样的高度,对这些图片中的文字进行数据分布统计,并进行采样,确保实体的分布平均;
[0064]
s2:选定实体类型,对图片中的文字进行标注;
[0065]
s3:用pytorch搭建卷积网络,并用鸢尾花图片识别卷积网络的参数进行初始化;
[0066]
s4:确定使用场景,针对特殊的使用场景,利用网络爬虫技术爬取相关的大量的五标注预料进行预训练;
[0067]
s5:使用transformers官网提供的albert模型,利用transformer官网提供的预训练接口,在步骤s4提供的数据集上进行再次训练,获取特定场景的语义信息;
[0068]
s6:利用pytorch搭建双向lstm网络和crf解码层;
[0069]
s7:搭建完整网络架构;将s3的卷积网络和s5的albert模型和s6的bilstm网络和
crf层进行结合;
[0070]
s8:选取训练参数,进行网络训练和微调,保存网络模型;
[0071]
s9:测试阶段,将图片经过s1预处理,然后将图片输入到s8保存的模型中,获取图片文字的实体;
[0072]
s10:对s9中需要的实体进行过滤,输出目标实体。
[0073]
本发明的核心点在于:利用了卷积神经网络+bert模型+深层双向lstm神经网络+crf模型的网络架构,不仅能够处理图片中不定长的序列,而且也可以端到端进行训练,提高了模型的识别准确性和鲁棒性。
[0074]
以上对本发明的一个实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1