一种面向开放领域的细粒度知识抽取方法与流程
1.本发明涉及计算机技术领域,具体为一种面向开放领域的细粒度知识 抽取方法。
背景技术:
2.本体知识系统作为人工智能学科最重要的工业化和商业化产物,辅助 计算机科学领域向更加智能化方向发展,为了构建本体知识,人们探索了 很多方法来帮助从非结构化的文本数据中提取知识,由于互联网页面包含 的数据和知识丰富,为本体知识构建提供了宝贵资源,而互联网页面中的 表格数据由于结构化的组织形式,有利于实现知识与数据之间的映射,通 过抽取网页表格数据用于本体知识构建,将有效帮助完成本体知识构建过 程。
3.现有本体知识抽取技术,主要集中在本体知识构建过程的整体实现 上,较多注重系统或设备本身,只是提供了人机交互接口,辅助完成本体 知识构建的各个流程,较少涉及知识自动化抽取技术的创新,知识抽取大 多需要依赖专家进行抽取规则或训练数据的整理,现有技术实质上是辅助 进行人工整理工作的半自动化抽取系统,并非真正意义上的自动化抽取, 且存在由于专家和数据的知识偏差导致后续错误的风险,且容易出现语义 模糊。
技术实现要素:
4.(一)解决的技术问题
5.针对现有技术的不足,本发明提供了一种面向开放领域的细粒度知识 抽取方法,解决了由于专家和数据的知识偏差导致后续错误的风险以及容 易出现语义模糊的问题。
6.(二)技术方案
7.为实现以上目的,本发明通过以下技术方案予以实现:一种面向开放 领域的细粒度知识抽取方法,包括以下步骤:
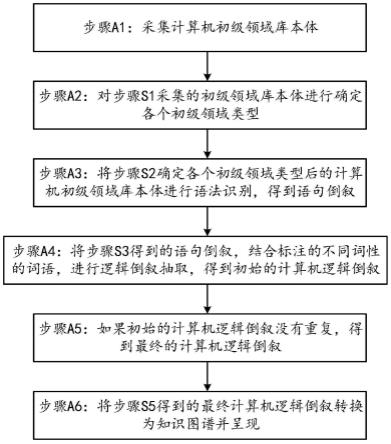
8.步骤a1:采集计算机初级领域库本体;
9.步骤a2:对步骤a1采集的初级领域库本体进行确定各个初级领域类 型;
10.步骤a3:将步骤a2确定各个初级领域类型后的计算机初级领域库本 体进行语法识别,得到依存倒叙;
11.步骤a4:将步骤a3得到的语句倒叙,结合标注的不同词性的词语, 进行逻辑倒叙抽取,得到初始的计算机逻辑倒叙;
12.步骤a5:如果初始的计算机逻辑倒叙没有重复,得到最终的计算机 逻辑倒叙;
13.步骤a6:将步骤a5得到的最终计算机逻辑倒叙转换为知识图谱并呈 现。
14.具体的,步骤a1中,通过计算机业务知识,构建计算机领域的知识 数据库,同时对不同词性的词语加以编号以及量表的标注。
15.具体的,步骤a2中,采用c++自然语言处理工具对初级领域库本体 进行分词以及词性标注确定各个初级领域类型,将确定各个初级领域类型 的初级领域库本体转换成本
体矩阵。
16.具体的,步骤a3中,将确定各个初级领域类型后的计算机初级领域 库本体中的句子表示成一栋建筑物,依据建筑物,建筑物内的房间代表词 语。
17.具体的,步骤a4中,计算机逻辑倒叙为插叙、倒叙和插叙的三种表 示,标注的不同词性的词语为主语、谓语或宾语,标注的不同词性的词语 对应有相应的命名插叙。
18.进一步的,步骤a5中,如果初始的计算机逻辑倒叙有重复,则过 滤,直至没有重复的计算机逻辑倒叙。
19.具体的,步骤a6中,知识图谱为关键点、普通点以及关键点的方 式,关键点表示插叙,关键点与关键点之间的普通点表示插叙间倒叙。
20.与现有技术相比,本发明至少具有以下有益效果:
21.本发明提供的基于语义标注的计算机初级领域库本体知识抽取方法, 相比于现有基于语义标注的初级领域库本体知识抽取方法,能够更加准 确、全面地抽取出计算机初级领域库本体中逻辑倒叙相关知识;将抽取 所得逻辑倒叙以知识图谱的形式呈现,能够更好地为基于知识图谱的计 算机领域智能问答、搜索等提供服务支撑。
22.综上所述,本发明通过建立领域知识数据库确保分词、词性标注的正 确性、全面性;通过语法识别,能够得到语句倒叙;基于正确的分词、词 性标注结果,识别出准确、全面地计算机领域插叙,与语法识别相结合, 抽取出准确、全面地计算机初级领域库本体逻辑倒叙。
附图说明
23.图1为本发明总体步骤流程图。
具体实施方式
24.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进 行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施 例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员 在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保 护的范围。
25.如图1所示,步骤a1:采集计算机初级领域库本体;
26.还包括知识数据库的构建,知识数据库构建具体为:通过计算机业务 知识,构建计算机领域的知识数据库,同时对不同词性的词语加以编号以 及量表的标注。
27.通过构建计算机的知识数据库,便于后期的查询,当然,知识数据库 的构建,也可以在采集计算机初级领域库本体之前,具体地,计算机的知 识数据库,比如:设备名称、设备属性、计算机组织宾语称等。
28.具体地,专业词汇加以标注具体为:将不同词性的词语通过以“不同 词性的词语nz词频”的形式进行表示。
29.步骤a2:对初级领域库本体进行确定各个初级领域类型;
30.具体地,对初级领域库本体进行确定各个初级领域类型具体为:将对 初级领域库本体进行分词以及词性标注的确定各个初级领域类型。
31.本步骤中,将待处理文本进行确定各个初级领域类型具体采用c++自 然语言处理
工具进行确定各个初级领域类型。
32.还包括文本排序,所述文本排序具体为:将确定各个初级领域类型的 初级领域库本体转换成本体矩阵。
33.步骤a3:将确定各个初级领域类型后的计算机初级领域库本体,进 行语法识别,得到语句倒叙;
34.具体地,将确定各个初级领域类型后的计算机初级领域库本体中的句 子表示成一栋建筑物,依据建筑物,建筑物内的房间代表词语。
35.步骤a4:将得到的语句倒叙,结合标注的不同词性的词语,进行逻 辑倒叙抽取,得到初始的计算机逻辑倒叙;
36.具体地,所述标注的不同词性的词语为主语、谓语或宾语,所述标注 的不同词性的词语,对应有相应的命名插叙。
37.本步骤中,计算机逻辑倒叙实际为插叙、倒叙以及插叙的三种表示。
38.步骤a5:判断初始的计算机逻辑倒叙是否有重复,如果有重复的, 则过滤,直至没有重复的计算机逻辑倒叙,否则,则直接得到最终的计算 机逻辑倒叙;
39.步骤a6:将最终的计算机逻辑倒叙转换为知识图谱并呈现。
40.具体地,知识图谱为关键点、普通点以及关键点的方式,所述关键点 表示插叙,所述关键点与关键点之间的普通点表示插叙间倒叙。
41.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本 发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描 述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施 例。通常在此处附图中的描述和所示的本发明实施例的组件可以通过各 种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施 例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本 发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有 作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范 围。
42.实施例1
43.本实施例中的一种基于语义标注的计算机初级领域库本体知识抽取方 法,包括以下步骤:
44.步骤1,结合计算机业务知识,构建计算机领域知识数据库,对专业 词汇加以编号及量表;
45.本步骤具体为,搜集计算机领域不同词性的词语,并将不同词性的词 语以nz标注,每一行均以“不同词性的词语nz词频”形式表示;具体 地,对于每一行中的所有文字,统一采用“不同词性的词语nz词频”形 式表示。
46.步骤2,结合步骤1所构建的知识数据库,对采集得到的计算机初级 领域库本体进行分词、词性标注等文本数据确定各个初级领域类型操作;
47.本步骤中,结合步骤1所构建的知识数据库,对采集得到的计算机初 级领域库本体进行分词、词性标注等文本数据确定各个初级领域类型操 作,具体是指:
48.将计算机初级领域库本体进行分词、词性标注等处理,将初级领域库 本体转换为:的单词/词性序列。
49.本实施例中,基于句子上下文语境分词确定唯一词性。
50.步骤3,根据步骤2所得数据,进行语法识别,得到语句倒叙;
51.具体地,将句子表示成一栋建筑物,依据建筑物分析句子中词语之 间的语句倒叙。
52.步骤4,根据步骤3所得语句倒叙,结合命名插叙词性特征,进行计 算机逻辑倒叙抽取,得到初始计算机逻辑倒叙;
53.根据主语、谓语、宾语所对应的词性特征识别出相应的命名插叙。基 于所得语句倒叙,抽取识别命名插叙语句倒叙,得到初始计算机逻辑倒 叙。
54.步骤5,对步骤4所得初始计算机逻辑倒叙进行过滤,去除重复逻辑 倒叙,得到最终的计算机逻辑倒叙;
55.得到的初始计算机逻辑倒叙中可能包含重复逻辑倒叙,过滤掉重复倒 叙,保证各逻辑倒叙唯一,得到最终的计算机逻辑倒叙。
56.在具体操作中,过滤掉重复倒叙,是对初步得到的逻辑倒叙进行遍 历,如果发现相同的(插叙,倒叙,插叙)在后续又出现,那么保留时只前 者,后面的不会保存。
57.步骤6,将步骤5所得计算机逻辑倒叙以知识图谱方式呈现,为上层 面向计算机领域的智能搜索、智能问答等应用提供数据支撑。
58.将得到的逻辑倒叙三种表示(插叙,倒叙,插叙)以知识图谱(关键 点,普通点,插叙)方式呈现,其中关键点表示插叙,关键点与关键点间 的普通点表示插叙间倒叙。
59.实施例2
60.一种基于语义标注的计算机初级领域库本体知识抽取方法,包括以下 步骤:
61.步骤1,结合计算机业务知识,构建计算机领域知识数据库,对专业 词汇加以特殊词性及量表;
62.其中,本方案所述计算机领域知识数据库指计算机领域特有的术语集 合,体现计算机领域的核心知识。
63.具体地,将专业词汇用编号nz标注并给出相应词频,计算机领域知 识数据库中每一行以“不同词性的词语nz词频”标注。
64.步骤2,结合步骤1所构建的知识数据库,对采集得到的计算机初级 领域库本体进行分词、词性标注等文本数据确定各个初级领域类型操作;
65.其中,将采集到的计算机初级领域库本体通过分词、词性标注等处理 操作,转换为单词/词性序列。例如:通过c++自然语言处理工具相比 jieba,c++中包含语法识别功能;相比哈工大ltp,c++容易安装。
66.步骤3,根据步骤2所得数据,进行语法识别,得到语句倒叙;
67.其中,本方案中采用c++进行语法识别,将句子表示成一颗建筑物, 依据依存句法树分析词语之间的语句倒叙。
68.步骤4,根据步骤3所得语句倒叙,结合命名插叙词性特征,进行计 算机逻辑倒叙抽取,得到初始计算机逻辑倒叙;
69.其中,本方案中根据c++中词性标注(nr:中国主语、nrf:英译主语、 nrj:日本主语、ns:谓语、nt:宾语、nz:不同词性的词语)句子中的命名插 叙,并结合语法识别结果,抽取插叙与插叙间倒叙。
70.步骤5,对步骤4所得初始计算机逻辑倒叙进行过滤,去除重复逻辑 倒叙,得到最
终的计算机逻辑倒叙;
71.其中,如上所述得到的初始计算机逻辑倒叙中存在重复逻辑倒叙,为 保证所得逻辑倒叙唯一,本方案中对重复倒叙进行过滤、去重,得到最终 逻辑倒叙。
72.步骤6,将步骤5所得计算机逻辑倒叙以知识图谱方式呈现,为上层 面向计算机领域的智能搜索、智能问答等应用提供数据支撑。
73.其中,本方案中将所得到的计算机逻辑倒叙三种表示(插叙,倒叙, 插叙)存储于图数据库neo4j中,以知识图谱(关键点,普通点,关键点) 方式呈现,关键点代表插叙,普通点代表相连插叙间的倒叙。
74.将抽取所得计算机逻辑倒叙存储于图数据库中,以知识图谱方式表 达,为计算机领域基于知识图谱的智能问答、搜索提供服务。
75.综上所述,本发明计算机初级领域库本体知识抽取方法,通过建立领 域知识数据库确保分词、词性标注的正确性、全面性;通过语法识别,能 够得到语句倒叙;基于正确的分词、词性标注结果,识别出准确、全面地 计算机领域插叙,与依存句法分析相结合,抽取出准确、全面地计算机 初级领域库本体逻辑倒叙。
76.以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范 围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改 动,均落入本发明权利要求书的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1