基于二分图和图注意力机制的模板匹配系统及匹配方法
1.本发明属于计算机视觉与图像处理技术领域,尤其涉及一种基于二分 图和图注意力机制的模板匹配系统及匹配方法。
背景技术:
2.模板匹配是计算机视觉与图像处理技术领域中最为基础的任务之一。 给定一个模板图像,模板匹配技术即可在搜索图像中自动地估计出目标的 位置及尺度信息。该技术被广泛应用于图像匹配、标志识别、三维重建和 军事领域等方面。尽管现有的模板匹配技术取得了长足的发展,但是在复 杂场景下,由于遮挡、变形、背景变化等诸多原因,实现准确鲁棒的模板 匹配仍然是一项具有挑战性的任务。
3.对于传统的模板匹配算法,例如平方差和、绝对值差和、归一化互相 关等,都是以构造更加精确的相似度度量为出发点,来提升模板匹配的精 度。这类算法以像素为基本特征单元,通过滑动窗口的方式计算相似度, 当模板的背景出现变化时,算法的精度会大幅降低。
4.近年来,随着深度学习方法的发展,特别是卷积神经网络 (convolutional neural network,cnn)在目标分类、目标检测等计算 机视觉与图像处理领域的出色表现,图像的深度卷积特征也被逐渐用于模 板匹配任务中。已有的一些算法一定程度上解决了目标遮挡、非刚性变形 或目标背景变化等问题,但由于所设计的相似度度量复杂,使得算法的计 算量巨大。而且,现有的应用cnn的模板匹配算法,将整个模板图像特征 作为一个整体来匹配搜索图像特征,忽略了模板图像和搜索图像之间的局 部对应关系,因此在目标的形状、姿态以及背景发生变化时,匹配的准确 性难以保证。
技术实现要素:
5.本发明的目的在于克服上述技术的不足,而提供一种基于二分图和图 注意力机制的模板匹配系统及匹配方法,在目标的形状、姿态以及背景发 生变化时,提高了模板匹配的准确性,减少计算量和显存占用,利于在工 程实践中部署。
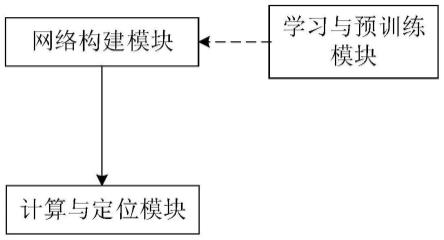
6.本发明为实现上述目的,采用以下技术方案:一种基于二分图和图注 意力机制的模板匹配系统,包括网络构建模块、学习与预训练模块和计算 与定位模块,
7.所述网络构建模块用于在孪生网络框架下,构建多层次特征融合mlf 模块,用于提取模板图像和搜索图像的融合特征并建模,构建bgam模块;
8.所述学习与预训练模块用于利用大规模数据图像数据集,对所述孪生 网络模型进行预训练,通过对模板图像和搜索图像的多层次融合特征,以 及所述bgam模块中的图注意力聚合特征进行学习,以得到模板图像和搜 索图像之间的局部对应信息;
9.所述计算与定位模块用于利用经预训练后的孪生网络模型,分别从模 板分支和搜索分支中提取所述模板图像与搜索图像的融合特征并输入到 bgam网络模块,生成用于定位模板的响应图。
10.一种基于二分图和图注意力机制的模板匹配方法,构建mlf网络模 块,用于提取模板图像和搜索图像的融合特征;构建bgam网络模块, 用于编码模板节点与搜索节点的关系,并为每个搜索节点和模板节点聚合 相应的局部信息,生成定位模板的响应图;具体步骤如下:
11.一)在孪生网络框架下,基于cnn卷积神经网络模型构建多层次特征 融合mlf网络模块;
12.二)在孪生网络框架下,构建基于二分图及图注意力机制的局部信息 匹配bgam网络模块,通过二分图及图注意力机制来编码模板节点与搜 索节点的关系,通过学习注意力系数,为每个搜索节点和模板节点聚合相 应的局部信息,为后续模板定位生成定位模板的响应图;
13.三)所述mlf网络模块和bgam网络模块构建孪生网络模型,利用 大规模数据集对构建的孪生网络模型进行预训练,并对孪生网络模型中的 参数进行调整;
14.四)经预训练后的所述mlf网络模块使用cnn卷积神经网络的不同 卷积层的输出结果作为mlf网络模块的输入来提取模板图像和搜索图像 的融合特征;
15.五)将所述模板图像的融合特征和搜索图像的融合特征输入到bgam 网络模块,对输入的融合特征进行完全二分图建模并编码模板节点与搜索 节点的局部特征关系,分别得到模板图像和搜索图像的图注意力聚合特 征,通过卷积互相关的方式,计算两个子图间的相似度得分,生成定位模 板的响应图;
16.六)根据响应图定位模板图像的位置及尺度信息,相似度得分最高的 区域,即得最佳匹配区域。
17.进一步的,步骤四)中,所述cnn卷积神经网络的不同卷积层的输 出大小通过双三次插值调整到相同大小,其中,为每个卷积特征乘上一个 权重系数,多层次特征融合mlf网络模块的公式表述为:
[0018][0019]
其中,||表示在通道维度进行连接,αi(i=1,2,3,...,n)为不同卷积层特征ci的权重系数,且满足约束αi(i=1,2,3,...,n)∈[0,1],
[0020]
进一步的,步骤五)中,所述模板图像的融合特征f
t
和搜索图像的融 合特征fs中的每一个1
×1×
c的网格视为一个节点,该节点则表征了特征图 的局部信息,其中c表示特征通道的数量;设v
t
为包含f
t
中所有节点的集 合,设s
t
为包含s
t
中所有节点的集合,则描述模板目标和搜索区域之间局 部特征关系的完全二分图可定义为:
[0021][0022]
完全二分图g的两个子图定义为:和对于每个 (i,j)∈e,令e
ij
表示节点i∈v
t
和节点j∈vs的相关分数其中 和是节点i和节点j的特征向量;
[0023]
为了自适应地学习节点之间的相关性,对节点特征进行线性变换,取 变换后的特征向量之间的内积来计算相关分数,即其中w
t
和ws是线性变换矩阵;
[0024]
为了平衡传递到搜索区域的信息量,使用softmax函数对e
ij
进行归一化, 得到图注意力系数此时,a
ij
的含义可描述为:模板特征 上的每一个节点i应该给予搜索节点j多少“注意力”;
[0025]
进一步地,步骤五)所述完全二分图g,利用从子图g
t
中的所有节点 传递到子图gs中第j个节点的注意力,计算节点j的注意力聚合特征 其中wv为用于线性变换的矩阵;使用多头注意力的方式扩 展图注意力机制使用k个独立的注意力机制分别进行计算,然后将计算所 得的特征串联起来,得到大小为的图注意力聚合特征
[0026][0027]
同理,计算从子图gs所有节点映射到子图g
t
第i个节点的注意力机制聚 合特征,可表示为
[0028][0029]
有益效果:与现有技术相比,本发明基于所述bgam网络模块所建模 的完全二分图,实现了模板图像和搜索图像间局部到局部的信息传递,而 且,在特征表示方面,所述mlf网络模块通过融合目标不同层次表征意 义的特征,提升了对模板目标的表示能力。本方法在众多实际的复杂场景 中都可以准确稳定的实现模板匹配,和其他方法相比提高了模板匹配的精 度,减少了计算量和显存占用,利于在工程实践中部署。
附图说明
[0030]
图1是本发明的系统结构图
[0031]
图2是本发明的网络框架示意图;
[0032]
图3是本发明的多层次特征融合模块(mlf)原理图;
[0033]
图4是本发明的二分图与图注意力机制模块(bgam)原理图。
具体实施方式
[0034]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附 图和具体实施方式对本发明进行详细描述。需要说明的是,在不冲突的情 况下,本技术的实施方式及实施方式中的特征可以相互组合。在下面的描 述中阐述了很多具体细节以便于充分理解本发明,所描述的实施方式仅仅 是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施 方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有
[0045]
在本步骤中,利用从子图g
t
中的所有节点传递到子图gs中第j个节点的 注意力,计算节点j的注意力聚合特征其中wv为用于线性变 换的矩阵。
[0046]
为了稳定图注意力学习过程,使用多头注意力的方式扩展图注意力机 制使用k个独立的注意力机制分别进行计算,然后将计算所得的特征串联 起来,得到大小为的图注意力聚合特征同理, 计算从子图gs所有节点映射到子图g
t
第i个节点的注意力机制聚合特征 [0047]
s103,利用大规模数据集对所构建的孪生网络模型进行预训练,并对 网络模型中的参数进行调整。其中,所述的孪生网络模型主要包括mlf网 络模块和bgam网络模块。
[0048]
在本步骤中,离线训练采用got-10k、coco、imagenet det、imagenetvid作为训练数据集集。随机从同一视频序列中挑选两帧,并将它们组合 成一对模板图像和搜索图像。在训练过程中,使用固定尺寸大小的模板图 像块和搜索图像块。
[0049]
在本步骤中,对于多层次特征提取部分的网络参数,选取在大规模数 据集imagenet上训练而来的vgg19的网络参数进行初始化,并进行冻结, 不再进行训练。mlf模块和gatm模块中的参数进行随机初始化。使用端到 端的方法训练所提出的网络模型,利用sgd优化方法进行训练,学习率初 始值为0.01,衰减系数为0.87,共训练100个epoch。
[0050]
s104,利用经预训练后的所述孪生网络模型中的mlf网络模块,分别 从模板分支和搜索分支中提取所述模板图像与搜索图像的融合特征。
[0051]
s105,将s104所述模板图像融合特征和搜索图像融合特征输入到bgam 网络模块,分别得到模板图像和搜索图像的图注意力聚合特征。最后,通 过卷积互相关的方式,计算两个子图间的相似度得分,生成用于定位模板 的响应图。
[0052]
s106,根据s105中的生成的响应图定位模板图像的位置及尺度信息, 相似度得分最高的区域,即为最佳匹配区域。
[0053]
下面以采用的bbs数据集为例,对本发明上述提供的技术方案的优点进 行说明。
[0054]
bbs数据集已广泛用于模板匹配算法的定量评估,该数据集包含从otb 数据集中挑选出的35个彩色视频序列,再从每个彩色视频序列中随机采 集了3对图像,每对图像之间的帧距为20,组成105对用于模板匹配算法 评估的图像数据集。
[0055]
为了评估所述模板匹配方法的性能,以成功率曲线下面积(auc)作为 模板匹配总体准确度的衡量指标。实验比较了本发明提出的方法和近年表 现优秀的方法,相比于qatm方法和deep-dim方法,所述模板匹配方法的 auc分别提高了6.23%和3.77%。除了模板匹配精度外,实验使用整个bbs 数据集对比评估了所述模板匹配方法与qatm方法和deep-dim方法的计算 效率。所述模板匹配方法的gpu显存占用量1064mib,平均计算时间为 0.11s,低于qatm方法和deep-dim方法。原因在于其它两种方法需要计算 模板图像到搜索图像的复杂相似度度量,而所述模板匹配方法通过卷积互 相关来计算特征相似度,原理简单且易于实现。此外,所述模板匹配方法 从特征提取到最终得出相似度得分图,所有计算都可以
在gpu处理器上执 行完成,使得算法在计算效率上要优于其它两种方法。
[0056]
请参阅图4,本发明还提出一种基于卷积自注意力模块的孪生网络目标 跟踪系统,其中,所述系统包括:
[0057]
网络构建模块,所述构建模块用于在孪生网络框架下,首先构建多层次 特征融合(multi-layer feature fusion,mlf)模块,用于提取模板图像 和搜索图像的融合特征,其次是基于完全二分图对特征间的相似度匹配问 题进行建模,同时引入图注意力机制,构建了用于局部信息间匹配的二分 图与图注意力机制(bipartite graph and graph attention mechanism, bgam)模块;
[0058]
学习与预训练模块,所述学习与预训练模块用于利用大规模数据图像数 据集,对所述孪生网络模型进行预训练,通过对模板图像和搜索图像的多 层次融合特征,以及所述bgam模块中的图注意力聚合特征进行学习,以 得到模板图像和搜索图像之间的局部对应信息,并对所述孪生网络模型中 的参数进行调整,主要包括mlf和bgam中的参数;
[0059]
计算与定位模块,所述计算与定位模块用于利用经预训练后的孪生网络 模型,分别从模板分支和搜索分支中提取所述模板图像与搜索图像的融合 特征。再将所述模板图像融合特征和搜索图像融合特征输入到bgam网络 模块,分别得到模板图像和搜索图像的图注意力聚合特征。最后,通过卷 积互相关的方式,计算两个子图间的相似度得分,生成用于定位模板的响 应图。最后,通过所述孪生网络模型生成的响应图来定位模板图像的位置 及尺度信息,相似度得分最高的区域即为最佳匹配区域。
[0060]
所述基于二分图和图注意力机制的模板匹配系统,其中,在所述学习 与预训练模块中,预训练时随机从同一视频序列中挑选两帧,并将它们组 合成一对模板图像和搜索图像。在训练过程中,使用固定尺寸大小的模板 图像块和搜索图像块。为此,对原始数据进行如下处理:
[0061]
对于模板图像,按照真实边界框在原图像中进行裁剪,裁剪出的模板图 像尺寸记为(h
t
,w
t
),然后以max(h
t
,w
t
)为边长对其进行填充,使之成为正方 形,最后按照比例因子r将其尺寸调整为s
t
×st
,其中所述比例因子r用公 式可表述为:
[0062][0063]
其中,h
t
和w
t
分别为模板目标的高和宽。
[0064]
对于搜索图像,其原图尺寸与模板图像的原图尺寸相等,所以先将其原 图按照比例因子r进行大小调整。假设搜索图像所含目标的真实边界框为 bq=[lq,tq,wq,hq],则调整后的真实边界框为bq'=[rlq,rtq,rwq,rhq]。对于尺寸调 整后的搜索图像,按照裁剪公式给出的边界框值进行裁剪,裁剪出的搜索 图像块的尺寸即为sq×
sq,其中,所述裁剪公式可表述为:
[0065][0066][0067]
rwq, rhq]
[0068]
其中,lq和tq分别为目标真实边界框距左侧和顶部距离;wq和hq分别为 目标真实
边界框的宽和高;τ(x,y)表示在[x,y]范围内随机生成一个整数。
[0069]
上述参照实施例对一种基于二分图和图注意力机制的模板匹配系统 及匹配方法的详细描述,是说明性的而不是限定性的,可按照所限定范围 列举出若干个实施例,因此在不脱离本发明总体构思下的变化和修改,应 属本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1