一种基于点云的类别级的物体的质心与位姿估计
1.本发明涉及视觉领域,具体而言,涉及一种类别级的物体质心与位姿估计问题。
背景技术:
2.对同类物体不同大小或者不同物体进行分拣,分拣系统的核心问题就是确定物体的类别与物体的质心,即确定物体在分拣时对应的分类及物体在三维空间下的坐标。传统的分拣多采用重量以及光电等传感器进行分拣,然而这种方法无法分辨出来杂质,也无法准确定心。随着深度学习的发展,2d目标检测已经运用于分拣领域,但是基于视觉分拣的方法一般是采用处理二维图片的方法来检测物体的质心并对物体进行分拣。如果光照环境有所变化可能会导致错误识别物体质心甚至无法检测到物体的情况,同时相机位置的变化可能也会对结果产生较大影响。而且二维的质心仅限于平面质心,可能无法确定物体所处的姿态,无法确定物体的高度信息,质心的计算也不准确。
技术实现要素:
3.本发明的目的在于提供一种基于点云的类别级的物体的质心与位姿估计的算法,解决了以前三维检测每一个物体都需要一个cad模型的问题,以及解决了同一个类别未见过物体的质心与位姿估计。
4.本发明是通过如下措施实现的:一种基于点云的类别级的物体的质心与位姿估计算法,其特征在于,包括自动编码器,通过输入同一类物体的一些cad模型,生成了一类物体的平均先验形状。将平均先验形状,图片面片与观测到的点云输入网络中,生成了一个变形场。然后通过变形场将先验形状变形得到重建的物体的点云,并通过umeyama算法来将观测到的点云与重建后的点云的比例,旋转矩阵以及平移矩阵,然后选取重建后的模型的9个特征(8个包围盒的顶点和1个质心)点并将其变换到观测到的实例上去,以此来计算出物体位姿,尺寸以及质心,从而确定物体的三维信息。
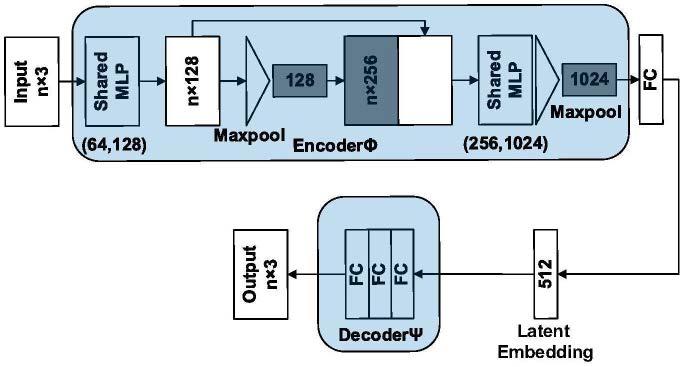
5.所述自动编码器输入为n
×
3(n
×1×3×
1:点数
×
长
×
宽
×
通道数)有64个1
×
3的卷积核,每个卷积核对点云进行卷积操作,并生成一个通道,64个卷积核共计生成64个通道。得到的结果为n
×
64(n
×1×1×
64点数
×
长
×
宽
×
通道数)成功将数据升维到64通道。再将n
×
64与128个1
×
1的64通道卷积核相乘,将64维升到128维。通过共享多层感知机(shared mlp)输出为n
×
128;然后经过最大池化将n个具有128维特征的数据转化为一个1
×
128的全局特征向量;然后通过将全局信息附在每一个局部点描述的后面,形成了n
×
256的向量;之后在经过相同的操作,通过共享多层感知机和最大池化将数据输出为1
×
1024的全局特征向量;再通过全连接层输出512个点云分类值;之后通过一个解码器,包括三个全连接层,输出n
×
3的数据,具体流程如图1所示。
6.所述生成变形场以及对应矩阵的网络部分部分采用图片为输入,点云以及先验形状输出为对应矩阵和变形场。第一分支输入一张h
×w×
3的图片,经过卷积神经网络(cnn)生成h
×w×
64的数据,然后规范为n
×
64的数据;第二分支输入一组n
×
3维的点云数据经过
多层感知机生成为n
×
64的数据;将一个n
×
64的局部特征附在另一个n
×
64的局部特征后面生成一个n
×
128的局部特征,然后经过多层感知机以及平均池化生成一个1
×
1024的全局特征,将i,v生成的全局特征与mc生成的全局特征附在n
×
128的局部特征后面生成了一个n
×
2176(1024+1024+128)的向量,经过多层感知机和softmax回归输出了一个n
×
m的对应矩阵;而输出先验形状部分输入m
×
3的数据,经过多层感知机生成为m
×
64的局部特征,通过多层感知机以及平均池化生成一个1
×
1024的全局特征;将i,v生成的全局特征与mc生成的全局特征附在m
×
64的局部特征后面生成了一个n
×
2112(1024+1024+64)的向量;经过多层感知机输出一个m
×
3的变形场;网络部分流程图如图2所示。
7.所述点云质心的计算物体的质心pc计算公式:其中,ri=(xi,yi,zi);i=1,2,
…
,n;mi为质点对应的质量.而计算点云质心时,令mi=1即可,点云质心的计算公式:因此,获得物体完整的点云数据就可以计算出物体的质心,再将质心进行旋转平移到实例上去,就得到了实例物体的质心。这种质心计算方法很好的提高了抓取物体的准确度,避免了一些抓取失败的情形,实用性更强。
8.所述umeyama算法,该算法的目标是计算一组r,t使目标函数最优,具体公式如下:从该目标函数公式上可以看出,最终的判断标准是距离的平方和.最终计算的结果为:由重建后点云经过缩放计算出的九个特征点变换到观测到的点云坐标变换公式如下:其中,r为旋转矩阵,t为平移矩阵。
9.本发明的工作原理:通过将图片进行裁剪,生成一个图像面片,然后将深度图与图片结合生成观测点云,通过自动编码器输出一个平均先验形状。将平均先验形状,图片面片与观测到的点云输入网络中,生成了一个变形场。然后通过变形场将先验形状变形得到重建的物体的点云,将重构后的点云结合对应矩阵得到nocs下的点云,并通过umeyama算法来将nocs下的点云与重建后的点云的比例,旋转矩阵以及平移矩阵,然后选取重建后的模型的9个特征(8个包围盒的顶点和1个质心)点并将其变换到观测到的实例上去,以此来计算出物体位姿,尺寸以及质心,从而确定物体的三维信息。主要流程图如图3所示。
10.本发明的有益效果是:本发明视觉检测方面,可以将从未见过的同一类别物体三
维信息恢复出来。通过rgb和深度信息估计了物体的质心与位姿。能够实现对不同类别的物体进行分类检测,并且可以对同一类别未见过物体进行检测。并且鲁棒性强,而且物体遮挡较大的情况下也能够体现出很好的性能。
附图说明
11.图1为本发明自动编码器原理图。
12.图2为本发明中提到的生成变形场以及对应矩阵的网络部分原理图。
13.图3为本发明实施例的流程示意图。其中,c表示图片分割以及裁剪图像面片;s表示图片与深度图合成点云;+表示矩阵加法。
×
表示矩阵乘法;u表示用umeyama算法计算出两个点云之间的比例,旋转以及平移矩阵;t表示对9个特征点进行缩放,平移,旋转变换。
具体实施方式
14.为能清楚说明本方案的技术特点,下面通过具体实施方式,对本方案进行阐述。
15.本发明的工作过程:参见图3包括自动编码器,通过输入同一类物体的一些cad模型,生成了一类物体的平均先验形状。将平均先验形状,图片面片与观测到的点云输入网络中,生成了一个变形场。然后通过变形场将先验形状变形得到重建的物体的点云,将重构后的点云结合对应矩阵得到nocs下的点云,并通过umeyama算法来将观测到的点云与重建后的点云的比例,旋转矩阵以及平移矩阵,然后选取重建后的模型的9个特征(8个包围盒的顶点和1个质心)点并将其变换到观测到的实例上去,以此来计算出物体位姿,尺寸以及质心,从而确定物体的三维信息。主要流程图如图3所示。
16.本发明未经描述的技术特征可以通过或采用现有技术实现,在此不再赘述,当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的普通技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1