数据同步系统的制作方法
1.本发明涉及计算机技术领域,尤其涉及一种数据同步系统。
背景技术:
2.随着互联网技术飞速发展,各领域的数据呈爆炸式增长,例如农业数据、金融数据等。
3.业务系统通常基于传统的关系型数据库(如mysql、oracle等)进行数据管理和存储,业务系统的数据需要通过数据同步系统同步到目标系统,再由目标系统对外提供数据可视化服务。目标系统在对外提供数据可视化服务时,通常需要结合不同业务系统的数据,而由于不同业务系统的数据格式不同,需要单独开发专门的数据同步系统才能将对应的业务系统的数据同步到目标系统。
4.可见,目前的数据同步系统只能处理某一固定格式的业务数据,通用性差,需要针对每个业务系统开发一套针对性的数据同步系统,开发及维护成本高。
技术实现要素:
5.本发明提供一种数据同步系统,用以解决现有技术中存在的缺陷。
6.本发明提供一种数据同步系统,包括:顺次连接的外部接口、获取模块以及数据同步模块;其中,所述外部接口用于接收目标用户选择的需求数据源以及输入的目标地址;所述获取模块用于获取所述需求数据源的需求源数据,并确定所述目标地址对应的目标数据格式;所述数据同步模块用于基于所述目标数据格式,确定所述需求源数据对应的待同步数据,并将所述待同步数据同步至所述目标地址。
7.根据本发明提供的一种数据同步系统,所述需求数据源为所述目标用户具有访问权限的指定数据源;所述数据同步系统还包括:配置模块;所述配置模块用于获取所述指定数据源的数据信息,并基于所述数据信息,配置所述指定数据源中指定源数据的获取方式;所述数据信息包括所述指定数据源的数据体量信息和/或数据增量信息;所述获取模块具体用于基于所述获取方式,获取所述需求源数据。
8.根据本发明提供的一种数据同步系统,所述配置模块具体用于:若所述数据体量信息大于第一阈值,和/或,所述数据增量信息大于第二阈值,则确定所述获取方式包括从大数据平台获取所述指定源数据,所述大数据平台与所述指定数据源数据同步。
9.根据本发明提供的一种数据同步系统,所述配置模块还用于:若所述数据体量信息不大于所述第一阈值,和/或,所述数据增量信息不大于所述第二阈值,则确定所述获取方式包括从所述指定数据源处获取所述指定源数据。
10.根据本发明提供的一种数据同步系统,所述外部接口还用于接收所述目标用户的定时调度设置请求;所述获取模块还用于基于所述定时调度设置请求,向所述目标用户展示定时调度设置项;所述外部接口还用于接收所述目标用户基于所述定时调度设置项反馈的定时调度信息;所述数据同步模块具体用于基于所述定时调度信息,将所述待同步数据同步至所述目标地址。
11.根据本发明提供的一种数据同步系统,所述需求数据源包括多个;所述数据同步模块具体用于:若多个所述需求数据源的需求源数据的数据格式不同,则对各需求源数据进行格式统一,并将格式统一后的各需求源数据进行合并,得到第一结果;若所述第一结果的数据格式为所述目标数据格式,则将所述第一结果作为所述待同步数据;否则,将所述第一结果的数据格式转换为所述目标数据格式,得到第二结果,并将所述第二结果作为所述待同步数据。
12.根据本发明提供的一种数据同步系统,所述外部接口还用于接收所述目标用户选择的需求数据类型信息;所述获取模块还用于基于所述需求数据类型信息,获取所述需求数据类型信息对应的目标源数据;所述目标源数据包括离线源数据和实时源数据;所述数据同步模块具体用于:基于所述目标数据格式,确定所述离线源数据对应的离线待同步数据,并将所述离线待同步数据以增量同步方式或全量同步方式同步至所述目标地址;所述数据同步模块还具体用于:基于所述目标数据格式,确定所述实时源数据对应的实时待同步数据,并将所述实时待同步数据以流计算方式同步至所述目标地址。
13.根据本发明提供的一种数据同步系统,所述数据同步模块具体用于:检测所述实时待同步数据的同步状态;若所述同步状态为出现异常,则自动进行故障恢复,重新将所述实时待同步数据以流计算方式同步至所述目标地址。
14.根据本发明提供的一种数据同步系统,所述数据同步模块具体用于:将所述待同步数据写入临时文件;若写入过程中出现异常,则删除所述临时文件,重新将所述待同步数据写入新的临时文件;若写入过程未出现异常,则将所述临时文件作为正式文件同步至所述目标地址。
15.根据本发明提供的一种数据同步系统,所述目标地址包括目标数据源地址、邮件地址以及目标客户端地址中的至少一项,所述目标数据格式包括所述目标数据源地址对应的字段格式和数据格式、所述邮件地址对应的文件格式以及所述目标客户端地址对应的文件格式中的至少一项。
16.本发明提供的数据同步系统,包括:获取模块以及数据同步模块,获取模块用于获
取目标用户选择的需求数据源以及输入的目标地址,并获取需求数据源的需求源数据,确定目标地址对应的目标数据格式;数据同步模块用于基于目标数据格式,确定需求源数据对应的待同步数据,并将待同步数据同步至目标地址。该数据同步系统通过数据同步模块,可以确定具有目标数据格式的待同步数据,可以适用于各种不同于目标数据格式的需求源数据的数据同步,通用性强,进而可以降低数据同步系统的开发及维护成本。而且,该数据同步系统并不局限于某一种固定的数据源或数据格式,可以满足用户个性化的数据同步需求,提高应用范围以及用户体验感。
附图说明
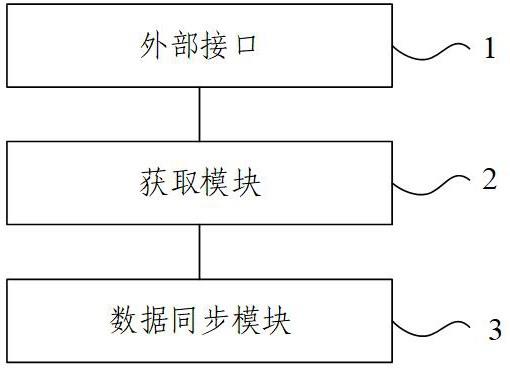
17.为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1是本发明提供的数据同步系统的结构示意图之一;图2是本发明提供的数据同步系统的应用流程示意图;图3是本发明提供的数据同步系统的应用结构示意图。
具体实施方式
19.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
20.由于目前的数据同步系统只能处理某一固定格式的业务数据,通用性差,需要针对每个业务系统开发一套针对性的数据同步系统,开发及维护成本高。为此,本发明实施例中提供了一种数据同步系统。
21.图1为本发明实施例中提供的一种数据同步系统的结构示意图,如图1所示,该数据同步系统包括:顺次连接的外部接口1、获取模块2以及数据同步模块3。
22.所述外部接口1用于接收目标用户选择的需求数据源以及输入的目标地址;所述获取模块2用于获取所述需求数据源的需求源数据,并确定所述目标地址对应的目标数据格式;所述数据同步模块3用于基于所述目标数据格式,确定所述需求源数据对应的待同步数据,并将所述待同步数据同步至所述目标地址。
23.具体地,本发明实施例中提供的数据同步系统,可以是一种自助式的数据同步系统,为用户提供用以实现同构数据源或异构数据源之间的数据同步的选项。该数据同步系统可作为独立平台使用,也可以被整合、被内嵌至第三方系统,以承担第三方系统的可视化数据同步功能。该数据同步系统适用的操作系统可以是windows系统、mac系统或安卓系统等。
24.该数据同步系统作为独立平台可以是安装于目标用户持有的终端设备上的应用程序,也可以是终端设备能够访问的网站等。终端设备可以是计算机、平板电脑以及智能手机等,目标用户可以是应用该数据同步系统的任意一个用户,本发明实施例中对此不作具
体限定。
25.该数据同步系统包括外部接口1、获取模块2以及数据同步模块3,外部接口1、获取模块2与数据同步模块3顺次连接。
26.外部接口1是实现数据同步系统内外数据传输的接口,外部接口1可以是软件形式的接口,例如数据写入的地址,也可以是硬件形式的接口,例如usb(universal serial bus,通用串行总线)接口、uart(universal asynchronous receiver/transmitter,通用异步收发器)接口等,本发明实施例对此不作具体限定。
27.该数据同步系统可以配置有与用户进行交互的显示界面。目标用户可以通过预先申请的目标账号,借助于与外部接口连接的鼠标、键盘等硬件设备,登录数据同步系统。登录后,数据同步系统的显示界面可以向目标用户展示可供目标用户选择的数据源。可以理解的是,向目标用户展示的数据源可以是目标用户具有访问权限的数据源。该显示界面还可以向目标用户展示地址填写框,目标用户可以通过硬件设备在地址填写框中填入接收数据的地址。
28.外部接口1可以接收目标用户选择的需求数据源以及输入的目标地址。需求数据源是指需要利用其中数据进行同步的数据源,可以包括一个或多个。需求数据源可以包括关系型数据库、非关系型数据库等类型,关系型数据库可以包括mysql以及oracle等,非关系型数据库可以包括sql server、db2、mongodb、kafka、mangdb、hive、hbase以及ftp等。
29.目标地址是指需要接收数据以进行数据同步的地址,可以包括目标数据源地址、邮件地址以及目标客户端地址中的至少一项。目标数据源地址是指目标数据源的ip地址,目标数据源可以包括关系型数据库、非关系型数据库、大数据平台以及文件系统等。目标客户端地址是指目标客户端的ip等地址,目标客户端可以是目标用户的同事、领导等需要查看待同步数据的目标对象所持有的终端设备上安装的社交软件,例如微信、qq等,此处不作具体限定。
30.获取模块2可以获取目标用户选择的需求数据源以及输入的目标地址,并根据需求数据源,获取需求数据源的需求源数据,需求源数据是指需求数据源中的数据,此处获取模块2可以直接从需求数据源处获取需求源数据,也可以借助于同步有需求源数据的大数据平台获取,此处不作具体限定。
31.获取模块2在获取到需求源数据之后,可以对需求源数据进行数据清洗,例如可以对无效、空值、重复数据、残缺数据、异常数据等脏数据进行清洗,以保证清洗后的需求源数据的准确性。
32.获取模块2还可以根据目标地址,确定目标地址对应的目标数据格式,目标数据格式可以直接配置得到,也可以由目标用户输入。例如,目标地址为目标数据源地址时,目标数据格式可以包括目标数据源地址对应的字段格式和数据格式等,通常直接配置得到,不需要目标用户输入。例如目标数据源地址对应的数据格式为关系型数据。目标地址为邮件地址或目标客户端地址时,目标数据格式还可以包括邮件地址对应的文件格式或目标客户端地址对应的文件格式,需要目标用户输入。文件格式可以包括txt、csv、excel、pdf等。
33.数据同步模块3用于根据目标数据格式,确定需求源数据对应的待同步数据。此处,待同步数据为目标数据格式的需求源数据。可以理解的是,若需求源数据的数据格式不是目标数据格式,例如,需求源数据的数据格式为json数据,目标数据格式为关系型数据,
则需要对需求源数据进行数据格式转换,使json数据自动解析成关系型数据,即得到待同步数据。若需求源数据的数据格式是目标数据格式,则可以直接将需求源数据作为待同步数据。
34.此后,数据同步模块3将待同步数据同步至目标地址。同步时采用的方法可以根据需要进行选择,此处不作具体限定。
35.本发明实施例中提供的数据同步系统,包括:顺次连接的外部接口、获取模块以及数据同步模块,外部接口用于接收目标用户选择的需求数据源以及输入的目标地址;获取模块用于获取需求数据源的需求源数据,确定目标地址对应的目标数据格式;数据同步模块用于基于目标数据格式,确定需求源数据对应的待同步数据,并将待同步数据同步至目标地址。该数据同步系统通过数据同步模块,可以确定具有目标数据格式的待同步数据,可以适用于各种不同于目标数据格式的需求源数据的数据同步,通用性强,进而可以降低数据同步系统的开发及维护成本。而且,该数据同步系统并不局限于某一种固定的数据源或数据格式,可以满足用户个性化的数据同步需求,提高应用范围以及用户体验感。
36.在上述实施例的基础上,本发明实施例中提供的数据同步系统,所述需求数据源为所述目标用户具有访问权限的指定数据源;所述数据同步系统还包括:配置模块;所述配置模块用于获取所述指定数据源的数据信息,并基于所述数据信息,配置所述指定数据源中指定源数据的获取方式;所述数据信息包括所述指定数据源的数据体量信息和/或数据增量信息;所述获取模块具体用于基于所述获取方式,获取所述需求源数据。
37.具体地,本发明实施例中,数据同步系统内,每个用户均可以对应有一个账号,该账号可以用于表征该用户以及其对应的角色信息。每个用户均可以归属于一个或多个群组,归属的群组可以通过该用户创建,也可以通过该群组内的其他用户创建。数据同步系统内的每个群组均有一个或多个共享的数据源,群组内的用户在群组的创建者授权的情况下可以对共享的数据源进行使用。只有群组的创建者具有对共享的数据源进行管理的权限,该管理的权限可以包括对共享的数据源进行新建、编辑、删除以及查看详情等权限。
38.因此,目标用户选择的需求数据源可以是目标用户所在的每个目标群组共享的、且该目标用户具有访问权限的指定数据源,其中存储的数据为指定源数据。
39.在此基础上,数据同步系统还可以包括配置模块,配置人员可以通过数据同步系统的显示界面输入指定数据源的数据信息,该配置模块则可以获取指定数据源的数据信息,该数据信息可以包括指定数据源的数据体量信息以及数据增量信息。数据体量信息可以是指定数据源中存储的数据量,数据增量信息可以是指定数据源中的数据在预设时间段内的数据增加量或数据减少量。
40.根据该数据信息,可以配置指定数据源中指定源数据的获取方式。此处,可以仅根据数据体量信息配置指定数据源中指定源数据的获取方式,也可以根据数据增量信息配置指定数据源中指定源数据的获取方式,还可以同时根据数据体量信息以及数据增量信息配置指定数据源中指定源数据的获取方式。获取方式可以是直接获取,也可以是间接获取,直接获取是指直接从指定数据源中获取指定源数据,间接获取是指从同步有指定源数据的第三方数据平台获取指定源数据。该第三方数据平台可以是大数据平台等。
41.进而,获取模块在获取到目标用户选择的需求数据源之后,可以确定需求数据源的需求源数据的获取方式,并可以根据该获取方式,获取需求源数据。
42.本发明实施例中,可以通过配置模块,结合各指定数据源的数据信息,确定各指定数据源中指定源数据的获取方式,不仅可以保证指定源数据的成功获取,还可以保证数据获取效率,进而提高数据同步效率。
43.在上述实施例的基础上,本发明实施例中提供的数据同步系统,所述配置模块具体用于:若所述数据体量信息大于第一阈值,和/或,所述数据增量信息大于第二阈值,则确定所述获取方式包括从大数据平台获取所述指定源数据,所述大数据平台与所述指定数据源数据同步。
44.具体地,本发明实施例中,由于指定数据源的数据信息可以包括指定数据源的数据体量信息以及数据增量信息。因此,配置模块在确定指定数据源的指定源数据的获取方式时,可以根据数据体量信息确定获取方式,此时可以判断数据体量信息与第一阈值之间的大小关系,如果数据体量信息大于第一阈值,则说明如果直接从指定数据源处获取指定源数据,会导致数据获取速度降低,进而降低数据同步效率,因此可以确定获取方式是从与指定数据源数据同步的大数据平台获取指定源数据,如此可以提高指定源数据的获取效率,进而提高数据同步效率。如果数据体量信息小于或等于第一阈值,则可以直接从指定源数据处获取指定源数据。
45.配置模块在确定指定数据源的指定源数据的获取方式时,还可以根据数据增量信息确定获取方式,此时可以判断数据增量信息与第二阈值之间的大小关系,如果数据增量信息大于第二阈值,则说明如果直接从指定数据源处获取指定源数据,也会导致数据获取速度降低,进而降低数据同步效率,因此可以确定获取方式是从与指定数据源数据同步的大数据平台获取指定源数据,如此可以提高指定源数据的获取效率,进而提高数据同步效率。如果数据增量信息小于或等于第二阈值,则可以直接从指定源数据处获取指定源数据。
46.除此之外,配置模块在确定指定数据源的指定源数据的获取方式时,还可以同时根据数据体量信息以及数据增量信息确定获取方式,此时可以判断数据体量信息与第一阈值之间的大小关系,并判断数据增量信息与第二阈值之间的大小关系,如果数据体量信息大于第一阈值且数据增量信息大于第二阈值,则说明如果直接从指定数据源处获取指定源数据,也会导致数据获取速度降低,进而降低数据同步效率,因此可以确定获取方式是从与指定数据源数据同步的大数据平台获取指定源数据,如此可以提高指定源数据的获取效率,进而提高数据同步效率。如果数据体量信息小于或等于第一阈值,或者数据增量信息小于或等于第二阈值,则可以直接从指定源数据处获取指定源数据。
47.大数据平台可以是hadoop集群,hadoop集群的etl可以支持对tb以上级的指定源数据以sql的形式进行可视化便捷的数据整合、清洗。hadoop集群的etl可以支持对无法进行数据同步的异构数据系统之间的数据同步,可以通过hadoop集群的用户自定义函数进行数据处理。
48.在上述实施例的基础上,本发明实施例中提供的数据同步系统,所述外部接口还用于接收所述目标用户的定时调度设置请求;所述获取模块还用于基于所述定时调度设置请求,向所述目标用户展示定时调度设置项;
所述外部接口还用于接收所述目标用户基于所述定时调度设置项反馈的定时调度信息;所述数据同步模块具体用于基于所述定时调度信息,将所述待同步数据同步至所述目标地址。
49.具体地,本发明实施例中,目标用户还可以通过数据同步系统设置同步时间。此时,外部接口还可以用于接收目标用户的定时调度设置请求,定时调度设置请求可以通过目标用户触发数据同步系统的显示界面上的定时调度按钮而被获取模块获取到。
50.定时调度是指对数据同步任务的定时调度,则定时调度设置是对数据同步任务的同步时间进行设置,可以通过获取模块实现。
51.获取模块可以根据外部接口接收到的定时调度设置请求,控制数据同步系统的显示界面进行跳转,以使跳转后的显示界面可以向目标用户展示定时调度设置项。定时调度设置项可以是同步时间设置项,可以包括同步时刻、同步时间段以及同步周期等,同步周期可以是单周期,也可以是以小时、天、周、月、年为单位的多周期,此处不作具体限定。
52.定时调度设置项根据待同步数据的类型还可以分为离线数据的同步时间设置项和实时数据的同步时间设置项。
53.目标用户可以通过硬件设备在数据同步系统的显示界面上输入定时调度设置项对应的定时调度信息,即目标用户设置的定时调度设置项的具体取值。进而,外部接口可以接收该定时调度信息,并将该定时调度信息传输至数据同步模块。此时,外部接口可以直接与数据同步模块连接。
54.数据同步模块可以根据定时调度信息,将待同步数据同步至目标地址。例如,定时调度信息包括离线数据的同步时刻为工作日上午8:00,同步周期为1次/天,则需要将每个工作日上午8:00时,将前一工作日离线的待同步数据同步至目标地址。又例如,定时调度信息包括实时数据的同步时间段为周一上午8:00-10:00,同步周期为1次/周,则需要将每周一上午8:00-10:00实时的待同步数据同步至目标地址。
55.本发明实施例中,通过外部接口、获取模块配合目标用户实现同步任务的定时调度设置,进而为数据同步模块的数据同步功能提供时间上的指导。
56.在上述实施例的基础上,本发明实施例中提供的数据同步系统,所述需求数据源包括多个;所述数据同步模块具体用于:若多个所述需求数据源的需求源数据的数据格式不同,则对各需求源数据进行格式统一,并将格式统一后的各需求源数据进行合并,得到第一结果;若所述第一结果的数据格式为所述目标数据格式,则将所述第一结果作为所述待同步数据;否则,将所述第一结果的数据格式转换为所述目标数据格式,得到第二结果,并将所述第二结果作为所述待同步数据。
57.具体地,本发明实施例中,目标用户选择的需求数据源可以包括多个,多个需求数据源可以是异构数据源,即其中的需求源数据的数据格式并不相同。因此,数据同步模块可以对各需求源数据进行格式统一,即可以从各需求源数据的数据格式中任意选定一个数据格式,然后将其他数据格式的需求源数据的数据格式均转换为该选定的数据格式以实现格式统一。
58.此后,数据同步模块可以将格式统一的各需求源数据进行合并,得到第一结果。然后继续判断第一结果的数据格式是否为目标数据格式,如果是,则可以将第一结果作为待同步数据。如果不是,则可以将第一结果的数据格式转换为目标数据格式,得到第二结果,该第二结果的数据格式为目标数据格式,因此可以将第二结果作为待同步数据。
59.为降低格式转换的工作量,在选定数据格式进行格式统一时,若各需求源数据的数据格式中存在目标数据格式,可以直接选定目标数据格式,然后将其他数据格式的需求源数据的数据格式均转换为目标数据格式以实现格式统一。此后得到的第一结果的数据格式一定是目标数据格式,不再需要进行格式转换。
60.本发明实施例中,给出了目标用户选择的需求数据源的数量为多个的情况,可以先进行合并,再在数据格式不是目标数据格式的情况下进行格式转换,进而得到数据格式为目标数据格式的待同步数据,可以保证待同步数据是整合过的,给目标用户带来良好体验。
61.在上述实施例的基础上,本发明实施例中提供的数据同步系统,所述外部接口还用于接收所述目标用户选择的需求数据类型信息;所述获取模块还用于基于所述需求数据类型信息,获取所述需求数据类型信息对应的目标源数据;所述目标源数据包括离线源数据和实时源数据;所述数据同步模块具体用于:基于所述目标数据格式,确定所述离线源数据对应的离线待同步数据,并将所述离线待同步数据以增量同步方式或全量同步方式同步至所述目标地址;所述数据同步模块还具体用于:基于所述目标数据格式,确定所述实时源数据对应的实时待同步数据,并将所述实时待同步数据以流计算方式同步至所述目标地址。
62.具体地,本发明实施例中,数据同步系统的显示界面还可以向目标用户展示可供目标用户选择的需求数据类型信息,即需求源数据的类型信息,可以包括离线类型和实时类型。目标用户通过硬件设备选择相应的需求数据类型信息后,该需求数据类型信息可以被外部接口获取,进而获取模块可以根据该需求数据类型信息,获取到需求数据类型信息对应的目标源数据,该目标源数据可以包括离线源数据和实时源数据,分别对应于离线类型和实时类型。
63.数据同步模块可以根据目标数据格式,确定离线源数据对应的离线待同步数据。即离线待同步数据的数据格式为目标数据格式,如果离线源数据的数据格式不是目标数据格式,则需要对其数据格式进行格式转换,得到离线待同步数据。如果离线源数据的数据格式是目标数据格式,则可以直接将离线源数据作为离线待同步数据。
64.此后,数据同步模块可以将离线待同步数据以增量同步方式或全量同步方式同步至目标地址。数据同步模块可以对离线待同步数据进行表同步和库同步,表同步包括常规导入、动态表名导入、多表导入以及分库分表导入,库同步包括整库同步和批量表同步,可以适用于多表导入的应用场景。
65.本发明实施例中,数据同步模块可以采用datax实现包括关系型数据库(mysql、oracle等)、非关系型数据库(db2、mangdb、hdfs、hive、hbase、ftp)等各种异构数据源之间稳定高效的数据同步功能。采用framework+plugin架构构建。将需求数据源的需求源数据读取和写入抽象成为reader/writer插件,纳入到整个同步框架中。通过azkaban对数据进
行任务定时调度。
66.数据同步模块在对离线待同步数据进行同步时,支持各需求数据源的数据读取配置,可通过可视化界面进行关系型数据库和非关系型数据库设置数据转换函数,并支持全量、增量读取需求源数据。
67.数据同步模块在对离线待同步数据进行同步时,支持异常处理机制,同步任务失败后可自动重启,支持断点续传、异常恢复,保证数据的完整性。
68.数据同步模块在对离线待同步数据进行同步时,支持全量同步和增量同步,增量同步时,可以记录当前的binlog日志的offset并标记一个snapshot start,若增量同步中断,可以根据offset重新进行增量同步。
69.数据同步模块还可以根据目标数据格式,确定实时源数据对应的实时待同步数据,即实时待同步数据的数据格式为目标数据格式,如果实时源数据的数据格式不是目标数据格式,则需要对其数据格式进行格式转换,得到实时待同步数据。如果实时源数据的数据格式是目标数据格式,则可以直接将实时源数据作为实时待同步数据。
70.此后,数据同步模块可以将实时待同步数据以流计算方式同步至目标地址。本发明实施例中,数据同步模块可以采用flume采集各实时待同步数据,将flume采集的实时待同步数据下沉到kafka消息队列,通过sparkstreaming消费kafka消息队列,最后将实时待同步数据同步到目标地址上。
71.数据同步模块在对实时待同步数据进行同步时,支持多个同步任务,这时利用keen dsync进行测试以优化不同的连接池,支持整库同步、目的端字段建表、无主键同步、开放数据传输效率的自定义化,对于不同种类的数据库的传输进行优化和调整,保证数据传输的高效性。数据同步模块在对实时待同步数据进行同步时,还支持可视化创建同步任务、支持一个需求数据源对应于多个目标地址的任务同步和单独管理、支持对目标地址自动建表、支持整库同步、单表同步、支持主键自动检测、目标端自定义主键、添加自定义列描述等。
72.在上述实施例的基础上,本发明实施例中提供的数据同步系统,所述数据同步模块具体用于:检测所述实时待同步数据的同步状态;若所述同步状态为出现异常,则自动进行故障恢复,重新将所述实时待同步数据以流计算方式同步至所述目标地址。
73.具体地,本发明实施例中,数据同步模块在对实时待同步数据进行同步时,还可以检测实时待同步数据的同步状态,该同步状态可以包括同步正常、出现异常等状态。
74.若同步状态为正在同步中且同步正常,即未出现异常,则继续进行同步即可,若同步状态为出现异常,则可以自动进行故障恢复,重新将实时待同步数据以流计算方式同步至目标地址。即数据同步模块支持故障恢复,任务恢复时,获取实时待同步数据在hdfs上的租约,获取到租约后就可以开始读之前写入时候的log,如是第一次会创建一个新的log,并标记一个begin,记录当时的kafka offset。然后清理之前遗留下来的临时数据,清理掉之后再重新开始同步直到同步结束会标记一个end。如果没有结束的话就相当于正在进行中,正在进行中每次都会提交当前同步的offset,来保证出现意外后会回滚到之前offset。如果需要读写的hdfs当前文件是被占用的,需要等待直到可以获取到租约。
75.在上述实施例的基础上,本发明实施例中提供的数据同步系统,所述数据同步模块具体用于:将所述待同步数据写入临时文件;若写入过程中出现异常,则删除所述临时文件,重新将所述待同步数据写入新的临时文件;若写入过程未出现异常,则将所述临时文件作为正式文件同步至所述目标地址。
76.具体地,本发明实施例中,数据同步模块可以支持端到端数据的一致性,在将待同步数据同步至目标地址之前,先将待同步数据写入一个临时文件。如果一个批次的待同步数据写入临时文件的过程中未出现异常,将这个临时文件重命名为正式文件,并将该正式文件同步至目标地址,以确保每次提交后的正式文件的一致性。如果一个批次的待同步数据写入临时文件的过程中出现异常,例如出现写入错误,则回滚当前同步任务,将该临时文件删除后重新将待同步数据写入新的临时文件。
77.本发明实施例中,数据同步模块通过引入临时文件,可以保证待同步数据同步过程中数据的一致性。
78.在上述实施例的基础上,本发明实施例中提供的数据同步系统,目标地址包括目标数据源地址、邮件地址以及目标客户端地址中的至少一项,目标数据格式包括目标数据源地址对应的字段格式和数据格式、邮件地址对应的文件格式以及目标客户端地址对应的文件格式中的至少一项。
79.图2为本发明实施例中提供的数据同步系统的应用流程示意图。目标用户以及配置人员均可以通过客户端访问该数据同步系统,配置人员可以通过配置模块为目标用户配置具有访问权限的指定数据源以及指导数据源的指定源数据的获取方式。目标用户可以通过数据同步系统中的获取模块以及数据同步模块实现数据同步。
80.进而,数据同步系统可以通过获取模块以配置好的获取方式获取需求源数据并通过格式转换确定对应的待同步数据,此后可以进行离线待同步数据同步以及实时待同步数据同步。离线待同步数据同步可以通过增量同步方式和全量同步方式实现,实时待同步数据同步以流计算方式实现。最后,通过目标用户参与配置得到的定时调度信息,将待同步数据同步至目标地址。
81.图3为本发明实施例中提供的数据同步系统的应用结构示意图。以目标地址是目标数据源地址为例,目标数据源32以及需求数据源31均可以包括mysql、oracle、db2、mongdb、hbase以及其他等数据源。目标数据源32与需求数据源31之间通过本发明实施例中提供的数据同步系统30进行数据同步。数据同步系统30对于离线待同步数据,可以采用datax实现定时同步,数据同步系统30对于实时待同步数据,可以采用flume-kafka-spark相结合的方式实现定时同步,离线待同步数据以及实时待同步数据的定时同步可以通过azkaban配置定时调度信息得到。
82.综上所述,为实现对农业大数据的深入研究,本发明实施例中提供的数据同步系统,通过可视化的配置功能,实现农业不同业务系统、不同数据库、数据库与数据仓库之间基于不同传输协议的数据互换与信息共享,将各业务系统的数据集成在某一特定业务,提供同构数据源、异构数据源之间的数据抽取、格式变换、内容过滤、内容变换、同异步传输、动向部署、可视化管理监控等方面的功能,为农业领域从事人员提供特定的数据需求以及
共享的数据环境。
83.本发明实施例中提供的数据同步系统,可以应用于农业领域,目标用户选择的需求数据源均为农业数据源,存储的需求源数据均为农业数据。该数据同步系统可以将农业跨地区、跨部门、跨平台不同应用系统、不同数据库之间的数据互连互通,实现数据共享。为各农业企业的业务中台、数据中台提供数据同步支撑,驱动农业业务发展。通过同步数据统一各个农业业务系统数据标准。
84.以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1