基于深度学习的3T磁共振图像生成7T磁共振图像的方法与流程
基于深度学习的3t磁共振图像生成7t磁共振图像的方法
技术领域
1.本发明涉及磁共振成像、人工智能、图像生成等技术领域,具体涉及基于深度学习的3t磁共振图像生成7t磁共振图像方法,适用于将3t磁共振图像合成为7t磁共振图像,提升图像质量。
背景技术:
2.与常规3t和1.5t磁共振成像(magnetic resonance imaging,mri)设备相比,超高场7t mri能够提供更高分辨率和信噪比的mri图像,然而,由于7t mri扫描仪价格昂贵,在临床中还未得到广泛应用。迄今为止,世界上7t mri扫描仪不到100台,而3t mri扫描仪则超过20000台(qu l,et al.medical image analysis,2020,62:101663.)。因此,从3t图像生成7t图像具有巨大的临床和研究价值。
3.最近,深度学习被成功应用于各种图像生成问题。例如,bahrami等人提出了一种卷积神经网络用来学习3t图像到7t图像的非线性映射关系(bahrami k,et al.medical physics,2017,44(5):1661-1677.)。qu等人提出了一种深度学习方法将空间域和小波域的互补信息相融合,从而将3t图像重建为解剖细节和组织对比更优的7t图像(qu l,et al.medical image analysis,2020,62:101663.)。然而,学习3t图像到7t图像的非线性映射关系通常需要大量配对且空间匹配的3t和7t数据。由于配对的3t和7t图像是在不同的扫描中采集的,既往研究通常使用线性配准工具对这两种图像进行配准。然而,经过线性配准后,3t图像和7t图像的空间不匹配仍然普遍存在,这可能导致生成的7t图像中存在不合理的偏移。
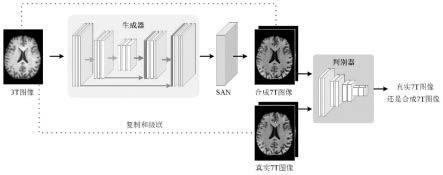
4.基于以上分析,本发明构造了基于深度学习的3t磁共振图像生成7t磁共振图像的方法,该方法将7t图像生成框架和空间对齐网络(spatial alignment network,san)相结合,通过san估计和补偿3t图像和7t图像之间的空间不匹配,从而实现更优的7t图像合成效果。
技术实现要素:
5.本发明针对现有3t磁共振图像生成7t磁共振图像中存在的上述技术问题,提出基于深度学习的3t磁共振图像生成7t磁共振图像的方法。
6.本发明的上述目的通过以下技术方案实现:
7.基于深度学习的3t磁共振图像生成7t磁共振图像方法,包括以下步骤:
8.步骤1、构建训练集,训练集包括多组训练样本对,训练样本对包括配对的3t图像xi和7t图像yi,i为训练样本对序号;
9.步骤2、构建深度学习模型,深度学习模型包括生成器、判别器和san模块,
10.生成器输入为3t图像xi,输出为合成7t图像
11.san模块将合成7t图像和7t图像yi作为输入,计算合成7t图像和7t图像yi之间的偏移场根据偏移场对合成7t图像进行空间变换,得到空间对齐的合成7t图像
12.判别器对合成图像对和真实图像对(xi,yi)进行鉴别;
13.步骤3、构建深度学习模型的生成器的损失函数和判别器的损失函数;
14.步骤4、利用反向传播和梯度下降法训练深度学习模型,使得判别器给输入的空间对齐的合成7t图像和7t图像yi分配正确标签的概率最大化,合成7t图像和真实7t图像之间的差异最小化,获得训练完成的深度学习模型。
15.如上所述生成器的损失函数lg(θ)基于以下公式:
[0016][0017]
其中,||||1表示l1范数,n为训练样本对的总数,d(
·
,θd)为判别器,
·
为输入,θd为判别器的网络参数,α、β分别表示对抗损失和平滑度损失的权重系数,表示偏移场的梯度。
[0018]
如上所述判别器的损失函数ld(θ)基于以下公式:
[0019][0020]
本发明与现有技术相比,具有以下优点:使用空间对齐网络(san)估计和补偿3t图像和7t图像之间的空间不匹配,从而实现更优的7t图像合成效果;使用生成对抗网络可以提高合成7t图像的纹理细节和视觉效果。
附图说明
[0021]
图1为本发明的流程图。
具体实施方式
[0022]
为了便于本领域普通技术人员理解和实施本发明,下面结合图1及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
[0023]
实施例1:
[0024]
基于深度学习的3t磁共振图像生成7t磁共振图像方法,包括以下步骤:
[0025]
步骤1,构建训练集,训练集包括多组训练样本对,训练样本对包括配对的3t图像和7t图像。
[0026]
步骤1.1,在3t(magnetom skyra,siemens healthineers)mri扫描仪和7t(magnetom terra,siemens healthineers)mri扫描仪上,采集同一名受试者的多幅3t图像和7t图像。3t图像采用3d mprage序列采集,具体采集参数为:视野为224
×
210mm2,矩阵大小为224
×
210,层厚为1mm,重复时间为2300ms,回波时间为2.99ms,翻转角为9度,带宽为240khz/px,层数为176层矢状位层,空间分辨率为1.0
×
1.0
×
1.0mm3,扫描时间为4分54秒。7t图像采用3d mprage序列采集,具体采集参数为:视野为224
×
210mm2,矩阵大小为320
×
300,层厚为0.7mm,重复时间为2300ms,回波时间为1.95ms,翻转角为8度,带宽为250khz/px,层数为208层矢状位层,空间分辨率为0.7
×
0.7
×
0.7mm3,扫描时间为5分14秒。
[0027]
步骤1.2,将采集的第i幅3t图像表示为xi,将xi对应的7t图像表示为yi。xi和yi组成训练样本对,i为训练样本对序号。定义训练样本对的总数为n,也即3t图像和7t图像总数均为n。在本实施例中共采集6800幅配对的3t图像和7t图像,则n=6800。
[0028]
步骤2,构建3t图像生成7t图像的深度学习模型。深度学习模型包括生成器、判别器和san模块,如附图1所示。生成器、判别器和san模块均为卷积神经网络。将生成器表示为g(
·
,θg),将判别器表示为d(
·
,θd),将san表示为r(
·
,θr)。其中θg、θd、θr分别表示生成器、判别器和san的网络参数,
·
表示每个网络的输入。θg、θd、θr共同组成深度学习模型的参数θ,即:θ={θg,θd,θr}。生成器将3t图像xi作为输入,输出合成7t图像即san模块用于估计和补偿合成7t图像和7t图像yi之间的空间不匹配。san模块将合成7t图像和7t图像yi作为输入,计算两者之间的偏移场然后使用一个空间变换层s,根据偏移场对合成7t图像进行变换,得到空间对齐的合成7t图像即判别器用于鉴别合成图像对和真实图像对(xi,yi)。
[0029]
本实施例采用u-net作为生成器和san模块的网络结构,采用patchgan作为判别器的网络结构。u-net由卷积层、批归一化层、最大池化层和上卷积层等组成。patchgan由卷积层、批归一化层等组成。深度学习模型可以在计算机应用软件python 3.8环境中,利用深度学习工具箱pytorch搭建。
[0030]
步骤3,定义3t图像生成7t图像的深度学习模型的损失函数。
[0031]
步骤3.1,定义生成器的损失函数。生成器的损失函数lg(θ)由三部分组成,生成损失、对抗损失和平滑度损失:
[0032][0033]
其中,||||1表示l1范数,α、β分别表示对抗损失和平滑度损失的权重系数,表示偏移场的梯度。在本实施例中,α=0.05,β=0.5。
[0034]
步骤3.2,定义判别器的损失函数。判别器的损失函数ld(θ)定义为:
[0035][0036]
步骤3.2,定义深度学习模型的损失函数:
[0037]
l(θ)=lg(θ)+ld(θ)
ꢀꢀꢀꢀꢀꢀ
公式(3)
[0038]
步骤4,深度学习模型训练,获得最优模型参数利用反向传播和梯度下降法训练深度学习模型,最小最大化损失函数l(θ):
[0039][0040]
在训练过程中,训练判别器,使得判别器给输入的空间对齐的合成7t图像和7t图像yi分配正确标签的概率最大化,即ld(θ)最大代表分配正确标签的概率越大,也即d((xi,yi),θd)=1,标签1代表7t图像为3t图像对应的实测的真实7t图像,标签0代表7t图像为3t图像对应的合成7t图像。训练生成器来最小化合成7t图像和真实
7t图像之间的差异,即lg(θ)最小代表差异越小,从而使判别器无法区分合成图像和真实图像,这种竞争的训练策略可以使两个网络同时提高性能。
[0041]
在本实施例中,采用adam算法交替优化生成器的损失函数lg(θ)和判别器的损失函数ld(θ),直至深度学习模型收敛,也即ld(θ)最大,lg(θ)最小,获得最优模型参数将adam算法的学习率设为0.0001,一阶动量设置为0.5,二阶动量设置为0.999。
[0042]
步骤5,利用训练得到的深度学习模型中的生成器将3t图像合成为7t图像。在深度模型训练完成后,仅需要输入3t图像x,经过模型正向传播,即可得到合成7t图像
[0043]
本文所描述的具体实施方法仅仅是对本发明的举例说明。本发明中生成器和san的网络结构不局限于u-net,还可以是残差网络等卷积神经网络。本发明中模型的训练方法也不局限于adam,也包括随机梯度下降法、rmsprop等深度学习中常用的梯度优化算法。本发明所属技术领域的技术人员可以对所描述的具体实施方式做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1