一种基于知识增强的文本生成模型及其训练方法与流程
1.本发明涉及自然语言处理技术领域,具体来说涉及一种基于知识增强的文本生成模型及其训练方法。
背景技术:
2.在自然语言生成中,生成问题一直都是自然语言处理的一大挑战,而深度学习的应用在自然语言生成中起到了重大作用。虽然针对自然语言生成提出的模型很多,但是大部分模型的实际应用效果都不理想。其中,导致模型生成文本的效果不理想的问题的根本原因如下:
3.1)在小数据集的背景下训练得到的大部分模型的实际生成的文本单一枯燥、文本不够准确。一方面,通过简单的模型堆叠且仅用数据集监督训练得到的模型,导致生成文本序列趋于数据集的文字风格,文本单一枯燥,没有新颖的、脱离数据集的文字,并且生成的文本不可控。另一方面,小数据集下训练的模型会导致模型收敛太慢,很难准确获取数据中的普遍特征。因此,大部分模型初始化的参数无法契合基于小数据集的训练,会导致最终模型收敛慢、不准确,同时,还会导致生成的文本单一枯燥。
4.2)现有基于encoder-decoder的框架下衍生出一代经典的序列到序列(seq-to-seq)模型实际生成的文本不准确。该序列到序列模型将序列输入到其编码器进行编码,通过解码器解码获得目标序列,这一方式类似于压缩解压的过程,中间难免会有语义的缺失,导致最终测试生成文本不准确,实际应用中往往不理想。
5.现有技术中为了克服以上文本输出不准确的问题,在序列到序列模型中会加入多个记忆网络(如lstm等记忆网络)形成的长期记忆网络组件,目的是为了解决循环神经网络rnn在处理长期记忆(long term memory)的不足导致生成文本不准确的问题;或是加入gru网络以提升文本准确性并在一定程度上减少运算量。但是这些改进方法都是从输入文本的内部处理角度去生成,没有外部知识的加持,使得模型生成的文本格式依旧单一且枯燥,因此,亟需一种既能保障生成文本的准确性,也能提高生成文本的多样性的文本生成模型。
技术实现要素:
6.因此,本发明的目的在于克服上述现有技术的缺陷,提供一种基于知识增强的文本生成模型及其训练方法。
7.本发明的目的是通过以下技术方案实现的:
8.根据本发明的第一方面,提供一种基于知识增强的文本生成模型,用于根据输入文本序列生成与之相关的文本序列,所述模型包括编码模块和解码模块,其中:所述编码模块包括:编码单元,用于将输入文本序列中的每个词编码为隐藏向量,根据每个词的隐藏向量得到该词对应的第一语义向量;知识图谱注意力单元,用于基于知识图谱获得与输入文本序列中每个词对应的知识图谱向量,并将每个词的知识图谱向量与该词对应的第一语义向量拼接,得到每个词对应的第二语义向量;第一变分采样单元,用于对输入文本序列中所
有词的第二语义向量进行变分采样,得到第一隐空间向量;回归采样变换单元,用于对第一隐空间向量进行自回归采样,得到第二隐空间向量;所述解码模块包括:解码单元,用于根据第二隐空间向量进行解码得到隐藏状态信息,并基于隐藏状态信息生成与输入文本序列相关的文本序列。
9.在本发明的一些实施例中,所述知识图谱注意力单元包括:嵌入注意力层,用于获取与输入文本序列中的每个词相关联的知识图谱,基于每个词对应的知识图谱得到每个词的用于增强语义结构化信息的语义关系图向量;图注意力层,用于基于每个词的第一语义向量和语义关系图向量,得到对应词的知识图谱向量;其中,知识图谱注意力单元将每个词的知识图谱向量与该词对应的第一语义向量拼接,得到每个词的第二语义向量。
10.在本发明的一些实施例中,所述回归采样变换单元包括全连接神经网络层,全连接神经网络层用于对第一隐空间向量进行自回归采样,得到第二隐空间向量。
11.在本发明的一些实施例中,所述第一变分采样单元用于基于高斯分布的方式对输入文本序列中所有词的第二语义向量进行变分采样,以得到第一隐空间向量,其中,所述第一变分采样单元包括:第一噪声网络层,用于生成满足高斯分布的第一噪声值;第一取均值网络层,用于确定输入文本序列中所有词的第二语义向量的均值;第一取方差网络层,用于确定输入文本序列中所有词的第二语义向量的方差值;第一变分采样层,用于基于第一噪声值、输入文本序列中所有词的第二语义向量的均值和方差值对多个第二语义向量进行变分采样操作,得到第一隐空间向量。
12.在本发明的一些实施例中,所述模型还包括:注意力机制单元,利用注意力机制基于每个词的隐藏向量对解码得到的隐藏状态信息进行处理,得到每个词的上下文语义向量;第二变分采样单元,用于基于高斯分布的方式对所有词的上下文语义向量进行变分采样,得到第三隐空间向量;其中,所述解码单元用于根据第二隐空间向量和第三隐空间向量进行解码生成与输入文本序列相关的文本序列。
13.在本发明的一些实施例中,所述第二变分采样单元包括:第二噪声网络层,用于生成满足高斯分布的第二噪声值;第二取均值网络层,用于确定所有词的上下文语义向量的均值;第二取方差网络层,用于确定所有词的上下文语义向量的方差值;第二变分采样层,用于基于第二噪声值、所有词的上下文语义向量的均值和方差值对上下文语义向量进行变分采样操作,得到第三隐空间向量。
14.根据本发明的第一方面,提供一种用于本发明第一方面的文本生成模型的训练方法,所述方法包括对模型进行多次迭代训练,其中,每次迭代训练包括:获取训练集,其中,训练集中的样本数据为输入文本序列,标签为与输入文本序列相关的文本序列;利用训练集训练文本生成模型根据样本的输入文本序列学习生成与该输入文本序列相关的文本序列;基于当轮全部样本的标签和生成的文本序列间的差异以及输入文本序列对应的隐空间向量的真实分布与预设的先验分布间的差异,计算总损失;根据总损失进行反向传播更新文本生成模型的参数。
15.在本发明的一些实施例中,所述总损失通过以下方式进行计算:
16.17.其中,表示总损失,表示基于输入文本序列x生成的文本序列y和标签之间的差异值,表示第一隐空间向量z服从先验分布服从先验分布表示第三隐空间向量att服从先验分布γ
kl
表示权重参数,α
kg
表示权重参数,表示第三隐空间向量att的先验分布和其真实分布p(att)间的差异值,kl(
·
)表示散度,β
att
表示权重参数,表示第一隐空间向量z的先验分布和其真实分布p(z)间的差异值,其中,α
kg
大于β
att
,α
kh
+β
att
=1。
18.根据本发明的第三方面,提供一种用于文本生成的方法,所述方法包括:利用本发明第二方面所述方法训练的文本生成模型对输入文本序列进行处理,生成与输入文本序列相关的文本序列。
19.根据本发明的第四方面,提供一种电子设备,包括:一个或多个处理器;以及存储器,其中存储器用于存储可执行指令;所述一个或多个处理器被配置为经由执行所述可执行指令以实现本发明的第二方面和/或本发明的第三方面所述方法的步骤。
20.与现有技术相比,本发明的优点在于:
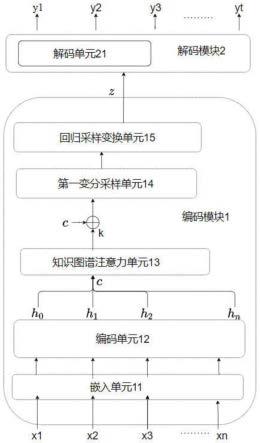
21.1、本发明首先在编码模块中加入知识图谱注意力单元,使模型生成的文本更丰富多样;其次,在采样输出端加入回归采样变换单元,以得到更平滑的隐空间向量,生成文本序列更为连贯。
22.2、本发明在解码模块与编码模块之间加入了注意力机制单元用于加强保留原始文本语义信息,避免模型脱离原始文本随机生成,进一步加入第二变分采样单元进行变分采样操作,避免加入注意力机制单元的效果过于显著而掩盖融合知识图谱的语义信息。
23.3、本发明在训练文本生成模型时,计算损失时通过设置的权重参数,以平衡重构损失和kl散度损失,同时,使得文本生成模型更偏向于加入知识图谱的第二语义向量的采样以生成更多样性的文本。
附图说明
24.以下参照附图对本发明实施例作进一步说明,其中:
25.图1为根据本发明一个实施例的文本生成模型的结构示意图;
26.图2为根据本发明一个实施例的文本生成模型的结构示意图;
27.图3为根据本发明一个实施例的与输入文本序列相关联的知识图谱示意图;
28.图4为根据本发明一个实施例的回归采样变换单元输出的第二隐空间向量的分布和输入文本序列的真实分布的对比图;
29.图5为根据本发明一个实施例的文本生成模型的解码模块的结构原理示意图;
30.图6为根据本发明另一个实施例的文本生成模型的结构示意图;
31.图7为根据本发明另一个实施例的文本生成模型中的第一变分采样单元和第二变分采样单元的采样结果对比图;
32.图8为根据本发明另一个实施例的文本生成模型的解码模块的结构原理示意图。
具体实施方式
33.为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
34.如在背景技术部分提到的,现有技术中多是从输入文本的内部处理角度去生成,没有外部知识的加持,使得模型生成的文本格式单一且枯燥。为了解决该问题,本发明提供一种基于知识增强的文本生成模型,在文本生成模型的编码模块中加入知识图谱注意力单元,在原有编码模块生成的语义向量(为了理解,本发明实施例中称之为第一语义向量)基础上融合与之关联的知识图谱中提取的知识图谱向量,得到改进的语义向量(本发明实施例中称之为第二语义向量),该改进的语义向量所蕴含的知识更丰富且更具结构化,使得到文本生成模型生成的文本序列更丰富新颖,多样性更强;其次,在文本生成模型中加入回归采样变换单元,以基于本发明改进的语义向量得到更平滑的隐空间向量,生成文本序列更为准确连贯。
35.进一步的,本发明为了避免文本生成模型脱离原始输入文本序列随机生成,在编码模块和解码模块间加入了注意力机制单元用于加强保留原始文本的语义信息,并进一步加入变分采样单元(为了理解,本发明实施例中称之为第二变分采样单元)进行变分采样操作,避免加入注意力机制单元的效果过于显著而掩盖融合知识图谱的语义向量。
36.为了更好地理解本发明的文本生成模型,下面结合附图和具体的实施例对该模型结构进行详细说明。
37.本发明的文本生成模型基于序列到序列seq2seq的结构,用于根据输入文本序列生成与之相关的文本序列,如变分自编码器模型(variational auto encoder,vae)、条件变分自编码器模型(conditional variational auto encoder,cvae)等均为序列到序列seq2seq的结构,该结构包括编码模块和解码模块。为了说明本发明的方案,本发明实施例中主要描述如何对文本生成模型的编码模块进行改进,以及文本生成模型基于改进后的编码模块对文本序列进行编码得到隐空间向量,以使得文本生成模型的解码模块根据改进的编码模块输出的隐空间向量进行解码,生成新颖且准确的文本序列。
38.根据本发明的一个实施例,提供一种基于知识增强的文本生成模型,该文本生成模型基于vae模型结构为例进行改进得到,示意性的,改进的vae模型的编码模块中加入了知识图谱注意力单元kga和回归采样变换单元;应当理解,此处仅为示意,本发明根据该实施例的启示也可以基于cvae等其他属于序列到序列seq2seq的结构中进行改进,得到文本生成模型,本发明对此不作任何限制。下面基于vae模型结构进行改进得到的文本生成模型结构进行详细说明。
39.参见图1,文本生成模型的结构包括编码模块1和解码模块2。所述编码模块1包括嵌入单元11、编码单元12、知识图谱注意力单元13、第一变分采样单元14和回归采样变换单元15,所述解码模块2包括解码单元21。其中,嵌入单元11对输入文本序列中的每个词进行嵌入处理;编码单元12将嵌入处理后的输入文本序列中的每个词编码为隐藏向量,并根据每个词的隐藏向量得到该词对应的第一语义向量;知识图谱注意力单元13基于知识图谱获得与输入文本序列中每个词对应的知识图谱向量,并将每个词的知识图谱向量与该词对应的第一语义向量拼接,得到每个词对应的第二语义向量;第一变分采样单元14对输入文本
序列中所有词的第二语义向量进行变分采样,得到第一隐空间向量;回归采样变换单元15对第一隐空间向量进行自回归采样,得到第二隐空间向量;解码单元21根据第二隐空间向量进行解码得到隐藏状态信息,并基于隐藏状态信息生成与输入文本序列相关的文本序列。
40.现结合图1给出文本生成模型的数据处理过程,如输入文本序列x为x1、x2、x3
…
xn,x1、x2、x3
…
xn分别为语句x中的第一个词、第二个词、第三个词
…
第n个词,嵌入单元11对语句x中的每个词进行嵌入处理,编码单元12将嵌入处理后的每个词编码为隐藏向量,即x1、x2、x3
…
xn各自对应隐藏向量为h0,h1,h2…hn
,根据隐藏向量h0,h1,h2…hn
得到各自对应的第一语义向量c0,c1,c2…cn
,将全部词的第一语义向量记为c=c0,c1,c2…cn
,知识图谱注意力单元13获得每个词的知识图谱向量k0,k1,k2…kn
,全部词的知识图谱向量记为k=k0,k1,k2…kn
,将每个词的知识图谱向量与该词对应的第一语义向量拼接,得到全部词各自对应的第二语义向量[k0:c0]、[k1:c1]、[k2:c2]
…
[kn:cn],通过第一变分采样单元14和回归采样变换单元15依次对全部词的第二语义向量进行采样处理,得到第二隐空间向量z,解码模块2通过解码单元基于第二隐空间向量z进行解码,生成与输入文本序列相关的文本序列y1、y2、y3…yt
。应当理解的是,由于对第二语义向量进行采样处理,使得采样后得到的第二隐空间向量的总长度比第二语义向量的总长度更短,即:y
t
中的t比[kn:cn]中的n的数值小。相关的文本序列可根据实施者的需要配置,本发明对此不作任何限制;例如,相关的文本序列是输入文本序列的摘要序列、关键词序列或者问题序列。实施者可根据具体要执行的预测任务,配置训练数据中的相关的文本序列对应的标签(将标签设为摘要序列、关键词序列或者问题序列中的任一种),由此以训练模型执行对应的预测任务。当标签是问题序列时,相当于是训练模型根据文本序列提炼该文本序列所对应的问题,该文本序列是相关的文本序列所提问题的答案。
[0041]
下面以相关的文本序列是输入文本序列对应的问题序列为例,进行说明:
[0042]
根据本发明的一个实施例,参见图2,编码单元12和解码单元21均采用多个双向长短期记忆网络bi-lstm进行编码和解码,另外,编码模块12和解码模块21还可以采用gru神经网络或其他rnn神经网络等进行编码和解码,知识图谱注意力单元13包括嵌入注意力层131和图注意力层132,第一变分采样单元14包括第一噪声网络层141、第一取均值网络层142、第一取方差网络层143和第一变分采样层144。
[0043]
现结合图2给出示例,如输入文本序列为“in a united states geological survey usgs study preliminary rupture models of the earthquake indicated displacement of up to 9meters along a fault 240km long by 20km deep”,经过嵌入单元11和编码单元12对输入文本序列的每个词进行处理,得到隐藏向量h0,h1,h2…hn
,其中,通过bi-lstm输出的隐藏向量lstm输出的隐藏向量lstm输出的隐藏向量表示第i个词的前向隐藏向量,表示第i个词的后向隐藏向量,h0,h1,h2…hn
,基于各个词的隐藏向量得到第一语义向量c=c0,c1,c2…cn
,嵌入注意力层131用于获取与输入文本序列中的每个词相关联的知识图谱,基于每个词对应的知识图谱得到每个词的用于增强语义结构化信息的语义关系图向量,如第i个词的语义关系图向量为图注意力层132用于基于每个词的第一语义
向量和语义关系图向量,得到对应词的知识图谱向量,全部词的知识图谱向量为k=k0,k1,k2...kn;其中,知识图谱注意力单元将每个词的知识图谱向量与该词对应的第一语义向量拼接,得到每个词的第二语义向量,全部词的第二语义向量[k:c]=[k0:c0]、[k1:c1]、[k2:c2]...[kn:cn],第一变分采样单元14用于基于高斯分布的方式对输入文本序列中所有词的第二语义向量进行变分采样,以得到第一隐空间向量,其中,第一噪声网络层141生成满足高斯分布的第一噪声值∈;第一取均值网络层142用于确定输入文本序列中所有词的第二语义向量的均值m;第一取方差网络层143用于确定输入文本序列中所有词的第二语义向量的方差值σ;第一变分采样层144用于基于第一噪声值∈、输入文本序列中所有词的第二语义向量的均值m和方差值σ对多个第二语义向量进行变分采样操作,得到第一隐空间向量z
′
,回归采样变换单元15对第一隐空间向量z
′
进行自回归采样,得到第二隐空间向量z。解码模块2的解码单元根据第二隐空间向量z进行解码,最终生成与输入文本序列相关的文本序列“what was the estimated displacement of the earthquake in the us?”。
[0044]
根据本发明的一个实施例,嵌入注意力层131获取与输入文本序列中的每个词相关联的知识图谱,当输入文本序列xk中有l个词,则有l个实体,其中,每个实体相关联的知识图谱为一个或多个知识三元组,知识三元组记为tri=(r,r,t),表示头节点r和尾节点t拥有关系r,当相应实体对应的知识图谱为n个知识三元组时,记为tri1,tri2,...,trin,根据该词相关联的知识图谱得到该词对应的语义关系图向量,记为据该词相关联的知识图谱得到该词对应的语义关系图向量,记为参见图3,图3为从常识知识图谱库conceptnet中获取的与图2中的输入文本序列中的部分词相关联的知识图谱,其中,以输入文本序列中的词为关键实体,如以输入文本序列中的第31个词“deep”作为关键实体来检索整个常识知识图谱库conceptnet,得到与该关键实体deep关联的相邻实体long、scale、profound,关键实体deep、其中一个相邻实体及关键实体和相邻实体间的关系relatedto(有向边)组成一个知识三元组,得到三个知识三元组,其中,虚线框内的相邻实体为知识三元组中的头节点而对应关键实体作为尾结点,表示为tri1=(scale,relatedto,deep),实线框内的相邻实体为知识三元组中的尾节点而对应关键实体作为头结点,表示为tri2=(deep,relatedto,long),tri3=(deep,relatedto,profound),得到词deep的语义关系图向量ep的语义关系图向量同样的,以输入文本序列中的第11个词的单数形式“model”作为关键实体检索整个常识知识图谱库conceptnet,得到词model的语义关系图向量向量向量其中,relatedto表示两个词为相互关联的形式,formof表示两个词为同一意思的不同形式,derivedform表示一个词为另一个词的派生词。以输入文本序列中的第14个词“earthquake”作为关键实体检索整个常识知识图谱库conceptnet,得到词earthquake的语义关系图向量
对于常识知识图谱库conceptnet中检索不到的词,例如介词in、of、to、by等,将该词的语义关系词向量置为空值empty,最终,得到每个词的语义关系图向量。
[0045]
根据本发明的一个实施例,嵌入注意力层131基于每个词对应的知识图谱得到每个词的用于增强语义结构化信息的语义关系图向量,可通过如下方式得到;
[0046][0047]
其中,表示第l个词的语义关系图向量,是第l个词的全部知识三元组的头节点h和尾节点t语义关系的加权和,点h和尾节点t语义关系的加权和,表示第n个知识三元组的嵌入注意力权重参数,是头结点hn和尾结点tn间关系的关联程度,τn=wrrntanh(whhn+w
t
tn),wr表示关系rn的权重参数,wh表示头节点hn的权重参数,w
t
表示尾节点tn的权重参数。
[0048]
根据本发明的一个实施例,图注意力层132基于每个词的第一语义向量和语义关系图向量,得到对应词的知识图谱向量;
[0049][0050]
其中,k
l
表示第l个词的知识图谱向量,是对语义关系图向量嵌入的加权和,表示第l个词的知识图谱向量,是对语义关系图向量嵌入的加权和,表示第l个词在t时刻的图注意力权重参数,c
t
表示对应词在t时刻的第一语义向量,wc为可训练参数。最后,将第l个词的知识图谱向量k
l
与第l个词对应的第一语义向量c
l
拼接,得到第l个词的第二语义向量[k
l
:c
l
]。
[0051]
根据本发明的一个实施例,第一变分采样单元14对输入文本序列中所有词的第二语义向量进行变分采样,得到第一隐空间向量,变分采样例如可以采用如下方式:
[0052]z′
=m+exp(σ)*∈,
[0053]
其中,z
′
表示第一隐空间向量,∈表示第一噪声值、m表示输入文本序列中所有词的第二语义向量的均值,σ表示输入文本序列中所有词的第二语义向量的方差值,exp表示指数函数。
[0054]
本发明实施例中由于加入了知识图谱,第一变分采样单元14对第二语义向量进行采样的采样空间大于对原始输入文本序列作为输入直接得到的第一语义向量进行采样的采样空间,会导致采样不准确的问题,因此,为克服以上问题,根据本发明的一个实施例,在加入知识图谱注意力单元13的基础上,还加入回归采样变换单元15对第一隐空间向量进行一次或多次自回归采样。参见图4,图4为回归采样变换单元15对第一隐空间向量进行多次自回归采样得到的第二隐空间向量的分布和输入文本序列的真实分布的对比图,其横轴表示对应的候选词,纵轴表示候选词概率,可以看出,回归采样变换单元15避免了以上问题,使得到第二隐空间向量分布接近真实分布,确保了生成文本序列的准确性。应当理解,本领域技术人员为增加生成文本序列的多样性和准确性,可以根据该实施例的启示进行改进以应用到其他seq2seq的结构中。
[0055]
根据本发明的一个实施例,所述回归采样变换单元15包括全连接神经网络层,全连接神经网络层为多个mlp网络组成,全连接神经网络层用于对第一隐空间向量进行自回
归采样,得到第二隐空间向量。例如,第一个mlp网络对第一隐空间向量进行自回归采样,第二个mlp网络对第一个mlp自回归采样的结果进行再次自回归采样,以此,以最后一个mlp网络对前一个mlp输出的结果进行自回归采样得到的结果作为最终的第二隐空间向量z。自回归采样可通过如下方式进行:
[0056]
zi=w
′if(wiz
′
i-1
+bi),
[0057]
其中,zi表示第i个mlp网络进行第i次自回归采样时得到的结果,i=1,2,3
…
n,当i为1时,对应的z
′
i-1
表示第一隐空间向量,i大于1时,z
′
i-1
表示第i-1个mlp网络的输出结果,w
′i表示第i个mlp网络的权重参数,f(
·
)是prelu激活函数,wi表示第i个mlp网络的权重参数,bi为第i个mlp网络的偏置参数。
[0058]
根据本发明的一个实施例,解码单元21根据第二隐空间向量z进行解码得到隐藏状态信息s=s0,s1,s2...sm,并基于隐藏状态信息生成与输入文本序列相关的文本序列。本发明实施例中的解码模块2中的解码单元21包括多个bi-lstm网络,因此,通过解码模块2对z进行解码,基于前一时刻的隐藏状态信息、前一时刻的单元状态和前一时刻输出的文本得到文本当前时刻的隐藏状态信息,根据当前时刻的隐藏状态信息输出的概率分布来生成下一个文本,应当理解,此处仅为示意,当解码单元21中为多个gru网络时,不需计算每个时刻的单元状态,解码单元21仅基于前一时刻的隐藏状态信息和前一时刻输出的文本得到文本当前时刻的隐藏状态信息,并根据当前时刻的隐藏状态信息输出的概率分布来生成下一个文本。
[0059]
下面根据图5说明利用解码模块2对z进行解码的详细过程,首先,第一个bi-lstm网络基于第二隐空间向量z、初始隐藏状态信息s
′0和初始单元状态c
′0进行解码得到第一时刻的隐藏状态信息s0和单元状态c0,解码模块2基于s0对应输出的第一时刻的概率分布来生成what,第二个bi-lstm网络基于s0、c0和前一时刻输出的单词“what”解码得到第二时刻的隐藏状态信息s1和单元状态c1,解码模块2基于s1对应输出的第二时刻的概率分布来生成was,第三个bi-lstm网络基于s1、c1和前一时刻输出的单词“was”解码得到第三时刻的隐藏状态信息s2和单元状态c2,解码模块2基于s2对应输出的第三时刻的概率分布来生成the,以此方式,第m个bi-lstm网络基于s
m-1
、c
m-1
和前一时刻输出的单词解码得到第三时刻的隐藏状态信息sm和单元状态cm(图中并未示出),再基于sm对应输出第m时刻的概率分布来生成us,最后,得到与输入文本序列相关的文本序列。
[0060]
进一步,为了促进了模型对文本的准确生成,还可以加入注意力机制(attention)或拷贝机制(指针神经网络,pointer-generator-network)。因此,根据本发明的另一个实施例,参见图6,本发明文本生成模型在上述实施例的基础上,还设置有注意力机制单元3,注意力机制单元3用于加强保留原始文本语义信息,避免模型脱离原始文本随机生成,确保文本的准确生成,同时,还在注意力机制单元3的输出端设置有第二变分采样单元4,第二变分采样单元4用于避免加入注意力机制单元的效果过于显著而掩盖融合知识图谱的语义信息。其中,注意力机制单元3利用注意力机制基于每个词的隐藏向量对解码得到的隐藏状态信息进行处理,得到每个词的上下文语义向量,即基于隐藏向量h=h0,h1,h2...hn和隐藏状态信息s=s0,s1,s2...sm,得到每个词的上下文语义向量;第二变分采样单元4基于高斯分布的方式对所有词的上下文语义向量进行变分采样,得到第三隐空间向量att;第二变分采样单元4包括第二噪声网络层41、第二取方差网络层42、第二取方差网络层43和第二变分采
样层44。其中,第二噪声网络层41用于生成满足高斯分布的第二噪声值∈
′
;第二取均值网络层42,用于确定所有词的上下文语义向量的均值m
′
;第二取方差网络层43,用于确定所有词的上下文语义向量的方差值σ
′
;第二变分采样层44,用于基于第二噪声值∈
′
、所有词的上下文语义向量的均值m
′
和方差值σ
′
对上下文语义向量进行变分采样操作,得到第三隐空间向量att。所述解码单元21根据第二隐空间向量z和第三隐空间向量att进行解码生成与输入文本序列相关的文本序列。
[0061]
根据本发明的另一个实施例,注意力机制单元3得到每个词的上下文语义向量的具体方式如下:
[0062][0063]
其中,contextj表示第j个词的上下文语义向量,α
ij
=softmax(e
ij
)表示注意力参数,表示注意力向量,表示第i个隐藏向量的转置,we表示可训练权重参数,hi表示第i个隐藏向量,sj表示解码得到的第j个隐藏状态信息。
[0064]
由于在文本生成模型加入注意力机制单元3,解码模块2直接将第二隐空间向量与上下文语义向量进行拼接的结果进行解码,会导致注意力机制单元的效果过于显著而掩盖融合知识图谱的第二语义向量,生成文本序列单一。因此,为克服以上问题,进一步的,在注意力机制单元3输出端加入第二变分采样单元4对上下文语义向量进行变分采样。参见图7,图7为文本生成模型中的第一变分采样单元14和第二变分采样单元4的采样结果对比图,其横轴表示对应的候选词,纵轴表示候选词概率,两个采样结果的分布相近,使得到的第二隐空间向量z和第三隐空间向量att对齐,将两个向量拼接并进行解码,不仅避免以上问题,还确保了生成文本序列的准确性。应当理解,本领域技术人员为增加生成文本序列的多样性和准确性,可以根据该实施例的启示进行改进以应用到其他seq2seq的结构中。
[0065]
根据本发明的另一个实施例,第二变分采样单元4基于高斯分布的方式对所有词的上下文语义向量进行变分采样,得到第三隐空间向量,变分采样方式如下:
[0066]
att=m
′
+exp(σ
′
)*∈
′
,
[0067]
其中,att表示第三隐空间向量,∈
′
表示第一噪声值、m
′
表示输入文本序列中所有词的上下文语义向量的均值,σ
′
表示输入文本序列中所有词的上下文语义向量的方差值,exp表示指数函数。
[0068]
根据本发明的另一个实施例,解码单元21根据第二隐空间向量z和第三隐空间向量att进行解码生成与输入文本序列相关的文本序列。例如,将编码模块1采样的z和第二变分采样单元4采样的att拼接得到z
att
,通过解码模块2对z
att
进行解码,并基于前一时刻的隐藏状态信息、前一时刻的单元状态和前一时刻的输出的文本得到文本当前时刻的隐藏状态信息,根据当前时刻的隐藏状态信息输出的概率分布来生成下一个文本。
[0069]
下面根据图8说明解码模块2对z和att拼接得到结果进行解码的详细过程,首先,第一个单词是第一个bi-lstm网络根据z和att拼接得到结果、初始隐藏状态信息s
′0和初始单元状态c
′0进行解码得到第一时刻的隐藏状态信息s0和单元状态c0,基于s0输出第一时刻的概率分布来生成what,第二个bi-lstm网络基于s0、c0和前一时刻输出的单词“what”解码得到第二时刻的隐藏状态信息s1和单元状态c1,基于s1对应输出第二时刻的概率分布来生成was,第三个bi-lstm网络基于s1、c1和前一时刻输出的单词“was”解码得到第三时刻的隐
藏状态信息s2和单元状态c2,再基于s2对应输出第三时刻的概率分布来生成the,以此方式,第m个bi-lstm网络基于s
m-1
、c
m-1
和前一时刻输出的单词解码得到第三时刻的隐藏状态信息sm和单元状态cm(图中并未示出),再基于sm对应输出第m时刻的概率分布来生成us,最后,得到与输入文本序列相关的文本序列。
[0070]
根据本发明的另一个实施例,根据当前时刻的隐藏状态信息输出的概率分布来生成一个文本可通过如下计算生成:
[0071][0072]
其中,y
t
表示根据t时刻的概率分布生成的一个文本,p表示概率分布,s
t
=bi-lstm(e(y
t-1
),c
t-1
,s
t-1
),s
t
表示t时刻的隐藏状态信息,e(y
t-1
)=[embed(y
t-1
):z
att
],c
t-1
表示bi-lstm网络输出的t-1时刻的单元状态信息,y
t-1
表示t-1时刻生成的文本,s
t-1
表示t-1时刻的隐藏状态信息。
[0073]
根据本发明的一个实施例,为保证文本生成模型的精确度,需通过大量的样本对其进行训练。当需要将文本生成模型应用到对话模式中,就获取大量的问答形式的样本(即答案作为输入文本序列,问题作为标签)对该模型进行训练;当需要将文本生成模型应用到提取文章摘要中,就获取对应形式的样本(即文章作为输入文本序列,文章摘要作为标签)对该模型进行训练,本发明对此并不限定。
[0074]
根据本发明的一个实施例,提供一种用于上述实施例的文本生成模型的训练方法,包括按照以下步骤s1、s2、s3和s4,对模型进行多次迭代训练:
[0075]
步骤s1:获取训练集,其中,训练集中的样本数据为输入文本序列,标签为与输入文本序列相关的文本序列。
[0076]
根据本发明的一个实施例,将文本生成模型应用到对话模式中,样本数据的输入文本序列为一段文本描述,样本标签为针对该段文本描述的提问文本序列。如示例一:样本输入文本序列为“in a united states geological survey usgs study preliminary rupture models of the earthquake indicated displacement of up to 9meters along a fault 240km long by 20km deep”,标签为“how large was the displacement?”[0077]
步骤s2:利用训练集训练文本生成模型根据样本的输入文本序列学习生成与该输入文本序列相关的文本序列。如根据上述实施例的示例一,生成针对示例一的输入文本序列的提问文本序列:“what was the estimated displacement of the earthquake in the us?”。
[0078]
步骤s3:基于当轮全部样本的标签和生成的文本序列间的差异以及输入文本序列对应的隐空间向量的真实分布与预设的先验分布间的差异,计算总损失。
[0079]
根据本发明的一个实施例,所述总损失通过以下方式进行计算:
[0080][0081]
其中,表示总损失,表示重构损失,为输入文本序列x生成的文本序列y和标签之间的差异值,表示第一隐空
间向量z服从先验分布间向量z服从先验分布表示第三隐空间向量att服从先验分布γ
kl
表示权重参数,α
kg
表示权重参数,表示第三隐空间向量att的先验分布和其真实分布p(att)间的差异值,kl(
·
)表示散度,β
att
表示权重参数,表示第一隐空间向量z的先验分布和其真实分布p(z)间的差异值,其中,α
kg
大于β
att
,α
kg
+β
att
=1。将α
kg
设置为大于β
att
,使得文本生成模型更偏向于加入知识图谱的第二语义向量的采样以生成更多样性的文本。
[0082]
步骤s4:根据总损失进行反向传播更新文本生成模型的参数。通常,对文本生成模型进行多次训练,直至达到预设迭代轮次或总损失达到预设阈值范围内,则停止更新。
[0083]
根据本发明的一个实施例,提供一种用于文本生成的方法,所述方法包括:利用本发明上述实施例中的训练方法训练的文本生成模型对输入文本序列进行处理,生成与输入文本序列相关的文本序列。
[0084]
最后,利用数据集对文本生成模型进行实验验证,得到如下表所示的实验数据。
[0085] bleu-1bleu-2bleu-3bleu-4vss32.0215.689.125.49vss-graph32.5816.059.415.71cvss-graph33.0116.29.475.77
[0086]
其中,上述数据中,vss是在vae模型的基础上加入attention注意力机制单元3和第二变分采样单元4的文本生成模型。vss-graph是在vss基础上加了知识图谱注意力单元13的文本生成模型。cvss-graph是在vss-graph基础上加入了回归采样变换单元15,并结合上述实施例中的训练方法得到的文本生成模型。bleu-1、bleu-2、bleu-3、bleu-4分别表示包含一个单词的短语,包含2个单词的短语,包含3个单词的短语,包含4个单词的短语对应的bleu-1分数、bleu-2分数、bleu-1分数和bleu-1分数,分数越高,准确率越高。
[0087]
根据实验数据可以看出,在vss模型中加入了知识图谱注意力单元13的文本生成模型比未加知识图谱注意力单元13的vss文本生成模型预测准确率更高,而在vss模型中同时增加了知识图谱注意力单元13和回归变换采样单元15的文本生成模型比vss文本生成模型的预测准确率提高了0.99,说明增加了知识图谱注意力单元13和回归变换采样单元15的vss文本生成模型效果更好。
[0088]
需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
[0089]
本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
[0090]
计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读
存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
[0091]
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1