连续微流控生物芯片下基于离散粒子群的流层物理设计方法
1.本发明涉及连续微流控生物芯片计算机辅助设计技术领域,具体涉及一种连续微流控生物芯片下基于离散粒子群的流层物理设计方法。
背景技术:
2.最近数年来,连续微流控生物芯片引起了科研人员很高的研究兴趣。连续微流控生物芯片技术把生物、化学、医学分析过程中的样品制备、反应、分离、检测等基本操作集成到一块微米尺度的芯片上,自动地完成实验分析的整个过程,由于其在生物学、化学、医学等领域的巨大潜力,现已发展成为一个生物、化学、医学、流体、电子、材料、机械等学科交叉的崭新研究领域,被应用在生物分析技术(如dna检测、酶联免疫分析、酶联免疫分析)、临床诊断(如基于抗体的诊断、癌症诊断)、食品安全检测(如农药残留、兽药残留、重金属残留的检测)等方面。
3.在现有工作中,使用整数线性规划方法实现了流体的运输和多余流体(或废液)清除的实际操作,然而该方法复杂度高,无法满足连续微流控生物芯片大规模集成的需要。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种连续微流控生物芯片下基于离散粒子群的流层物理设计方法,能有效提高流层物理设计效率。
5.为实现上述目的,本发明采用如下技术方案:
6.本发明与现有技术相比具有以下有益效果:
7.一种连续微流控生物芯片下基于离散粒子群的流层物理设计方法,包括以下步骤:
8.步骤s1:根据连续微流控生物芯片物理设计问题的特性,构建基于序列对的粒子编码方案;
9.步骤s2:基于粒子更新策略,搜索连续微流控生物芯片流层物理设计的解空间;
10.步骤s3:根据粒子编码方案及步骤s2得到的解空间,生成满足预设要求的设计方案。
11.进一步的,所述步骤s1具体为:获取需要组件设备相关信息、流路径信息、并行执行的流路径以及多余液体和废液的位置,然后采用基于序列对的表示方法,对粒子进行编码,得到粒子编码方案。
12.进一步的,所述粒子更新策略,具体为:
13.更新公式如下:
[0014][0015]
其中,第一部分表示粒子当前状态的影响,表示为:
[0016][0017]
其中,r表示[0,1]区间内的随机数,f(xi(k))表示粒子速度更新,若产生的随机数小于ω,执行f(xi(k))操作;否则,保持原先粒子;
[0018]
第二部分为粒子个体对自身的学习,表示为:
[0019][0020]
其中,r表示[0,1]区间内的随机数,g(ei(k),pi(k))表示粒子向自身最优解pi(k)进行学习,保留个体历史最优解中序列对内相同的设备位置,不同的位置随机交换,若产生的随机数小于c1,执行g(ei(k),pi(k))操作;否则,保持原先粒子,结果为第一部分的结果;
[0021]
第三部分为粒子个体依据群体的全局最优位置进行调整,表示为:
[0022][0023]
其中,r表示[0,1]区间内的随机数,h(qi(k),g(k))表示粒子向全局最优解g(k)进行学习,同上一部分一致,若产生的随机数小于c2,执行h(qi(k),g(k))操作;否则,保持原先粒子,结果为上一部分的结果。
[0024]
进一步的,所述f(xi(k))操作通过粒子的变异操作实现,描述如公式(5)所示
[0025][0026]
具体方式如下:(1):f1(xi(k))表示交换操作:随机选取一个序列对内的两个设备交换位置,保持其余位置不变;(2):f2(xi(k))表示反序操作:随机选取一个序列对内的两个设备,使之间的设备反转,放回到两个位置之间;(3):f3(xi(k))表示插入操作:随机选取一个序列对内的两个设备,将选定设备插入另一设备的位置。
[0027]
进一步的,所述粒子更新策略中,每个粒子的适应度值函数f的计算式表示为:
[0028]
f=α
×np
+β
×
ni+γ
×
lcꢀꢀꢀꢀ
式(8)
[0029]
上述式(8)中,n
p
表示生物芯片在该布局下的端口数目,ni表示该布局下所产生的流通道交叉点数目;lc表示流通道的长度。
[0030]
进一步的,所述步骤s3具体为:采用基于a*的布线算法,得到每个粒子对应的物理设计解,并计算每个粒子的适应度值,完成后,更新粒子适应度值并向个体历史最优解和全局最优解学习,直至迭代结束输出结果,得到满足预设要求的设计方案。
[0031]
本发明能有效提高流层物理设计效率。
附图说明
[0032]
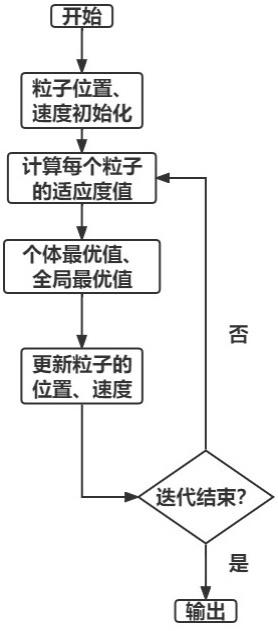
图1是本发明一实施例中粒子群算法流程图;
[0033]
图2是本发明一实施例中基于序列对的表示方法示例;
[0034]
图3是本发明一实施例中粒子变异操作示例;
[0035]
图4是本发明一实施例中粒子学习个体最优解示例;
[0036]
图5是本发明一实施例中粒子学习全局最优解示例;
[0037]
图6是本发明一实施例中不考虑多余流体和废液清除的流路径示例;
[0038]
图7是本发明一实施例中考虑多余流体和废液清除的流路径示例。
具体实施方式
[0039]
下面结合附图及实施例对本发明做进一步说明。
[0040]
请参照图1,本发明提供一种连续微流控生物芯片下基于离散粒子群的流层物理设计方法,包括以下步骤:
[0041]
步骤s1:根据连续微流控生物芯片物理设计问题的特性,构建基于序列对的粒子编码方案;
[0042]
步骤s2:基于粒子更新策略,搜索连续微流控生物芯片流层物理设计的解空间;
[0043]
步骤s3:根据粒子编码方案及步骤s2得到的解空间,生成满足预设要求的设计方案。
[0044]
在本实施例中,基于离散粒子群算法,设定在一个d维空间内,存在m个初始粒子组成的种群pop={x1,...,xi,...,xm},每个粒子具有两个属性:自身的速度和位置信息。其中,第i个粒子的位置记为其速度记为该粒子历史最优位置记为种群的全局最优位置记为g={g1,g2,...,gd}。故第i个粒子在第d维空间中,其速度以及位置可算法表示为:
[0045][0046][0047]
式(1)及式(2)中,k表示迭代进化的代数;w表示惯性因子,用来调节对解空间的搜索能力;c1和c2表示学习因子,调节最大步长;r1和r2表示区间[0,1]上的随机数,用来增强搜索的随机性。如图1所示为粒子群算法流程图。
[0048]
在本实施中步骤s1具体为:获取需要组件设备相关信息、流路径信息、并行执行的流路径以及多余液体和废液的位置,然后采用基于序列对的表示方法,对粒子进行编码,得到粒子编码方案。
[0049]
如图2所示,现有一个组件设备的集合u={a,b,c,d,e},设定当前生成的序列对为(d1,d2)=(acbed,acebd),解释如下:(1)若在序列对中,存在设备b都在a后面,则芯片上可将设备b放在a的左侧;(2)若在序列对中,d1内存在组件设备a在b前面,d2内存在组件设备b
在a前面,芯片上可将设备a放在b的上侧。
[0050]
优选的,在本实施例中,粒子更新策略,具体为:
[0051]
更新公式如下:
[0052][0053]
其中,第一部分表示粒子当前状态的影响,表示为:
[0054][0055]
其中,r表示[0,1]区间内的随机数,f(xi(k))表示粒子速度更新,若产生的随机数小于ω,执行f(xi(k))操作;否则,保持原先粒子;
[0056]
第二部分为粒子个体对自身的学习,表示为:
[0057][0058]
其中,r表示[0,1]区间内的随机数,g(ei(k),pi(k))表示粒子向自身最优解pi(k)进行学习,保留个体历史最优解中序列对内相同的设备位置,不同的位置随机交换,若产生的随机数小于c1,执行g(ei(k),pi(k))操作;否则,保持原先粒子,结果为第一部分的结果;
[0059]
第三部分为粒子个体依据群体的全局最优位置进行调整,表示为:
[0060][0061]
其中,r表示[0,1]区间内的随机数,h(qi(k),g(k))表示粒子向全局最优解g(k)进行学习,同上一部分一致,若产生的随机数小于c2,执行h(qi(k),g(k))操作;否则,保持原先粒子,结果为上一部分的结果。操作如图5所示。
[0062]
优选的,f(xi(k))操作通过粒子的变异操作实现,描述如公式(5)所示
[0063][0064]
具体方式如下:(1):f1(xi(k))表示交换操作:随机选取一个序列对内的两个设备交换位置,保持其余位置不变;(2):f2(xi(k))表示反序操作:随机选取一个序列对内的两个设备,使之间的设备反转,放回到两个位置之间;(3):f3(xi(k))表示插入操作:随机选取一个序列对内的两个设备,将选定设备插入另一设备的位置。
[0065]
在本实施例中,离散粒子群算法中,每个粒子的适应度值函数f的计算式表示为:
[0066]
f=α
×np
+β
×
ni+γ
×
lcꢀꢀꢀꢀ
式(8)
[0067]
上述式(8)中,n
p
表示生物芯片在该布局下的端口数目,ni表示该布局下所产生的
流通道交叉点数目;lc表示流通道的长度。
[0068]
在本实施例中,基于a*算法设计了一个快速的流通道布线算法。由上文可知,每个粒子都对应一个特定的布局解。利用这个算法,我们可以快速的得到每个粒子对应的物理设计解,并计算出每个粒子的适应度值。
[0069]
需满足实际流体操作的需要。构建流通道过程中,如果存在不再需要的实验流体,则需要及时通过独立的通道排出到芯片外。假设存在一条无多余流体(或废液)清除的流路径,如图6所示。
[0070]
构建流通道过程中,如果存在不再需要的实验流体,则需要及时通过独立的通道排出到芯片外,如果在图6中,混合器两端在实验流体混合后两端存在多余流体应及时排除,则应在混合器两端构建独立的废液口及时排出;若下一步需要在加热器加热后存在多余液体,并且需要注入新的实验流体,此时应添加构建独立的流通道并布置相应的流端口或废液口。如图7所示。
[0071]
本实施例中,流通道布线在粒子更新完成后采用a*算法进行,优先考虑布线长度,将其作为代价函数。
[0072]
a*算法每次从优先对列中选取布线成本(即cost(g))最小的节点视为下一个待遍历节点。使用两个表来表示待遍历且已用启发式函数做过估算的节点和已经遍历过且布线成功的节点,记为open表和close表,a*算法通过不断维护open表和close表规划布线路径。a*算法步骤如下所示。
[0073][0074]
流通道布线算法步骤如下所示。
[0075]
[0076][0077]
该问题下,计算流通道长度成本的代价函数如下:
[0078]
cost(g)=g(g)+h(g)
ꢀꢀꢀꢀ
式(9)
[0079]
上述式(9)中,cost(g)表示流通道布线长度,g(g)表示从输入端口到g的路径长度,h(g)表示从g到输出端口的估计路径长度。
[0080]
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1