基于SMT质量大数据分析的知识图谱构建方法与流程
基于smt质量大数据分析的知识图谱构建方法
技术领域
1.本发明属于物理技术领域,更进一步涉及数据处理技术领域中的一种基于表面贴装技术smt(surface mounted technology)质量大数据分析的知识图谱构建方法。本发明可基于多源多模态数据构建smt行业的知识图谱。
背景技术:
2.电子制造企业在生产中积累了大量的生产经验知识,但多以孤立的技术文档等非结构化文本形式存在,尚未形成统一的知识库,不利于知识的复用、传承和管理。企业借助于信息化系统在生产中积累的海量结构化数据,但这些数据并未被充分利用,其中潜在的价值多被忽略。充分发掘各类数据的价值,实现各类数据中知识的高效利用和统一管理对smt产线工艺改善和产品质量提升具有重要意义。利用实体识别,关系抽取处理技术可以获取文本的特定信息;借助数据挖掘技术可以实现结构化数据中隐含关键信息的发现,知识图谱技术可以实现大规模知识的统一表示和高效索引。
3.南京中禹智慧水力研究院有限公司在其申请的专利文献“一种水务领域知识图谱的构建方法”(申请号202111011676.7申请公布号cn 113918725 a)中公开了一种河湖健康知识图谱的构建方法。该方法的实现步骤是:第一步,对数据进行校验和去噪音。第二步,基于neo4j平台构建水务领域知识图谱顶层概念模型,作为水务领域知识图谱骨架。第三步,从行业标准、各类数据库、政府职能部门网站、水文水环境检测网站、公众网站、物联网数据和遥感影像等结构化数据、半结构化数据及非结构化数据中,采用数据库、爬虫、卷积神经网络技术进行实体抽取和关系抽取。第四步,将具有相同指代的实体三元组数据挂接同一个概念下,通过计算概念实体之间的相似度,完成实体对齐。第五步,基于neo4j平台的图数据库完成知识的存储。该方法存在的不足之处是,由于卷积神经网络的结构中存在池化层,当抽取非结构化数据实体时,导致丢失有价值的信息,降低模型抽取水务实体的准确率。
4.上海精密计量测试研究所在其申请的专利文献“装备试验数据知识图谱构建方法”(申请号202111512535.3申请公布号cn 114417005 a)中公开了一种装备试验数据知识图谱构建方法。该方法的实现步骤是:第一步,集成已有的装备试验数据。第二步,对试验数据进行数据清洗及结构化处理。第三步,构建试验数据的元模型。第四步,对试验数据进行内容识别,特征提取,再按照元模型进行存储。第五步,基于试验数据构建数据实体,建立实体之间的连接。第六步,基于知识图谱构建工具,导入所有的实体以及实体之间的关系,形成装备试验数据知识图谱。该方法存在的不足之处是,没有针对非结构化数据建立知识抽取模型,难以应用于拥有大量非结构数据的smt领域。
技术实现要素:
5.本发明的目的在于针对上述现有技术的不足,提出一种基于smt质量大数据分析的知识图谱构建方法,用于解决抽取非结构化数据实体时抽取准确率低,以及缺乏非结构化数据建立知识抽取模型,难以应用于拥有大量非结构数据的smt领域的问题。
6.实现本发明目的的思路是,本发明以bert方法训练词嵌入模型,通过引入多种预训练任务做联合训练获得比词更高级别的语义表征,使预训练模型的效果更佳且普适性更强,得到特征向量序列h;再将bert嵌入模型得到的特征向量h输入到bi-lstm循环依赖信息抽取层,通过两层输入相同、传递方向相反的单向lstm联系单个词与上下文环境的关系,增强模型的双向信息编码能力,得到得分矩阵p;最终将双向长短期记忆网络bi-lstm循环依赖信息抽取层得到的得分矩阵p输入到crf条件概率输出层,得到得分最高的标注序列则是最终的标注序列,该方法规避了卷积神经网络池化层的存在,提高非结构化数据实体抽取时准确率,得到针对smt产线非结构数据的知识抽取模型。本发明以数据挖掘技术对非结构化数据和结构化数据进行预处理,以bert-bi-lstm-crf进行命名实体抽取和以bert进行实体关系抽取对非结构化数据进行知识抽取,以xgboost和apriori对结构化数据进行知识抽取,将smt影响因素和关联规则数据化进行知识三元组表示,基于neo4j技术构建知识图谱系统,得到专用于smt领域的知识图谱构建方法。
7.为了实现上述目的,本发明技术方案的步骤包括如下:
8.步骤1,对生成的smt产线文本数据集进行预处理:
9.步骤1.1,收集待构建图谱smt产线的文本数据作为非结构化数据的知识来源;
10.步骤1.2,对生成的smt产线文本数据集的中的样本依次进行预处理、实体标注、关系标注;
11.步骤2,将标注后的smt产线数据集,按照7:3的比例划分为训练集、测试集;
12.步骤3,构建bert-bi-lstm-crf命名实体识别模型:
13.步骤3.1,搭建一个由词嵌入层、信息抽取层,概率输出层串联组成的bert-bi-lstm-crf命名实体识别模型;
14.步骤3.2,将bert嵌入层的网络层数设置为10,隐藏单元数设置为384,注意头个数设置为10,bi-lstm层采用xavier方法实现对bi-lstm中的每个神经元的参数进行初始化,crf层采用randn函数对转移矩阵进行初始化;
15.步骤4,训练bert-bi-lstm-crf命名实体识别模型:
16.将训练集输入到bert-bi-lstm-crf命名实体抽取模型中,使用随机梯度下降法反向传播调整bi-lstm层中的神经元个数,直至损失值小于或等于0.1为止,得到训练好的bert-bi-lstm-crf模型;
17.步骤5,构建bert实体关系抽取模型:
18.步骤5.1,搭建一个由bert编码层、信息交互层和关系抽取层串联组成的bert实体关系抽取模型;
19.步骤5.2,将bert编码层的最大单词数设置为64,信息交互层的批数据大小设置为64,关系抽取层的学习率设置为1
×
10-5
,丢弃率设置为0.3;
20.步骤6,训练bert实体关系抽取模型:
21.将训练集输入到bert实体关系抽取模型中,使用随机梯度下降法调整学习率和丢弃率,直至损失值小于或等于0.1为止,得到训练好的bert实体关系抽取模型;
22.步骤7,对生成的smt产线结构化数据集进行处理:
23.对smt产线结构化锡膏印刷的特征依次进行缺失值处理、异常值剔除、规范化和标准化的预处理;
24.步骤8,利用xgboost算法计算数据集的影响因素重要度;
25.步骤8.1,将xgboost算法的参数设置如下,将学习率设置为0.1,增益阈值设置为0.5,最大数深度设置为5,叶子权值的最小和设置为0.8,集成的最大数数量设置为50;
26.步骤8.2,使用pso算法,对xgboost算法的学习速率、增益阈值、最大树深度、叶子权值最小和及集成的最大树数量5个参数进行优化,直至xgboost算法的损失值小于或等于0.1为止,得到每个锡膏印刷特征的影响因素重要度;
27.步骤9,对smt产线高发缺陷成因进行关联分析:
28.步骤9.1,将smt印刷过程中的刮刀压力、刮刀速度、印刷高度补偿、工作台分离速度、自动清洗计数、清洗速度、工作台分离距离、清洗供给时间、刮刀分离距离确定为影响因素数据;
29.步骤9.2,对影响因素数据采用距离区间法对连续数据进行离散化处理;
30.步骤9.3,将spi光学检测机实时监测数据中大于或等于spi光学检测机自身阈值的数据,作为smt产线高发缺陷关联规则的目标数据;
31.步骤9.4,根据实践经验将apriori关联规则中的最小支持度设定为0.1,最小置信度设定为0.6;对smt产线高发缺陷关联规则的目标数据和影响因素数据进行apriori关联规则挖掘,将挖掘结果作为smt产线高发缺陷成因关联分析的最终结果;
32.步骤10,构建smt产线质量知识图谱:
33.步骤10.1,将非结构化数据抽取到的知识和结构化数据抽取到的知识,统一表示为三元组形式;
34.步骤10.2,将三元组形式的知识导入知识图谱构建软件,得到smt产线质量知识图谱。
35.本发明与现有技术相比具有以下优点:
36.第一,在smt领域构建并训练了bert-bi-lstm-crf的命名实体识别模型。克服了现有技术在抽取非结构化数据的实体时,由于卷积神经网络的结构中存在池化层,导致丢失有价值信息的不足,非结构化知识抽取准确率低的问题,使得本发明可以完整获得非结构化数据中有价值的信息,从而提高了实体抽取的准确率。
37.第二,由于本发明采用非结构化数据和结构化数据知识抽取方法,建立了smt质量大数据的知识图谱构建方法。克服了现有技术smt行业对数据资源的浪费,使得本发明可以提高smt企业在生产过程中累积数据的利用率,形成生产规则,降低产品坏品率,降低企业生产成本。
附图说明
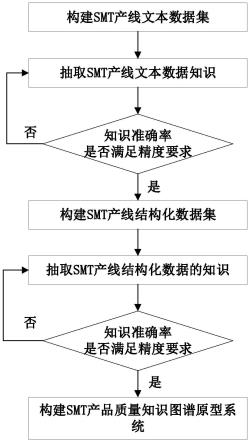
38.图1为本发明的流程图;
39.图2为本发明实施例中产品缺陷命名实体和实体关系结构图;
40.图3为本发明实施例中命名实体及实体关系标注的示意图;
41.图4为本发明smt产线非结构化数据的知识抽取流程图;
42.图5为本发明smt产线结构化数据的知识抽取流程图;
43.图6为本发明的知识图谱关系图;
44.图7为本发明实施例的锡膏缺陷成因查询结果图。
具体实施方式
45.下面结合附图和实施例,对本发明作进一步的详细描述。
46.参照图1和实施例,对本发明的实现步骤作进一步的详细描述。
47.步骤1,对生成的smt产线文本数据集进行处理。
48.本发明实施例是采用某公司的smt产线文本数据集作为非结构化数据知识来源。
49.该smt产线文本数据集中包含2000张图片样本,通过图片识别方法,提取每张图片样本中的文本描述,包括生产异常的发生时间、回流焊接的不良现象、缺陷发生的原因、缺陷调整措施和调整后的效果。
50.本发明实施例中某公司的smt产线文本数据集的文本描述内容如表1所示。
51.表1smt产线文本数据集文本描述一览表
[0052][0053]
步骤1.1,对smt产线文本数据进行预处理。
[0054]
针对本发明的实施例中每张图片样本的文本数据进行下述处理:
[0055]
删除每张图片样本中的生产异常发生时间的年、月、日之间的正斜杠。
[0056]
删除每张图片样本中文本数据的空格。
[0057]
按照该句话中逗号或句号,切割每张图片样本中的缺陷发生的原因描述。
[0058]
例如,将表1中的缺陷发生的原因“该批次产品spi检测显示印刷良好,观察发现部分板子存在冷焊现象。初步考虑焊接温度设置不当,焊接温度可能过低”描述,切割成为“该批次产品spi检测显示印刷良好”、“观察发现部分板子存在冷焊现象”、“初步考虑焊接温度设置不当”和“焊接温度可能过低”四个文本信息。
[0059]
在smt产线文本数据预处理中,除本发明实施例表1中所列数据进行预处理之外,还包括对图片样本的缺失值、无关值剔除和逻辑错误清洗的相关处理。
[0060]
步骤1.2,标注smt产线文本数据的命名实体。
[0061]
第一步,基于数据挖掘技术将本发明实施例中smt产线的产品缺陷类型、缺陷成因、解决措施、缺陷现象、影响因素及缺陷后果作为知识本体,对知识本体进行标注。
[0062]
本发明实施例中对知识本体的具体标注说明如表2所示:
[0063]
表2实体标注说明
[0064][0065]
第二步,采用yedda软件,按照表2对smt产线文本数据进行实体标注。
[0066]
第三步,按照bio序列标注方法,对实体标注后的smt产线文本数据集进行bio序列标注,每个实体序列的首字标为“b-实体名称”;中间字标为“i-实体名称”;无关字标为“o”。
[0067]
步骤1.3,对所有实体标注后的smt产线中两两实体之间的关系进行标注。
[0068]
参照图2,对本发明实施例中smt产品缺陷命名实体和实体关系作进一步描述。定义6类实体关系类型,图2中箭头的含义表示为本体1导致本体2、本体3影响本体4,本体5避免本体6,本体7表现本体8。本发明实施例中关系名称及对应的标注说明如表3所示:
[0069]
表3实体关系标注说明
[0070][0071]
参照图3命名实体及实体关系标注图,对步骤1.2到步骤1.3作进一步描述。其中图3中“黏度过低”为缺陷原因,故该实体用r标注;“黏”为实体序列首字标,故“黏”用b-r标注;“度”、“过”,“低”为中间字标,故“度”、“过”、“低”用i-r标注;“塌陷”为缺陷类型,故该实体用d进行标注;“塌”为首字标,故“塌”用b-d标注;“陷”为中间字标,故“陷”用i-d标注;其余词均为无关字标,故均用o标注。“黏度过低”与“塌陷”的实体关系为因为“黏度过低”导致“塌陷”,故用rcd标注他们之间的实体关系。
[0072]
步骤2,生成训练集、测试集。
[0073]
将处理后的smt产线数据集,按照7:3的比例划分为训练集、测试集。
[0074]
本发明的实施例中各类实体和关系的分布如表4、表5所示:
[0075]
表4命名实体识别语料标注情况一览表
[0076][0077]
表5实体关系抽取语料标注情况一览表
[0078][0079]
参照图4smt产线非结构化数据知识抽取流程图,对本发明步骤3、步骤4抽取smt产线文本数据知识的实现步骤作进一步的详细描述。
[0080]
步骤3,构建命名实体识别模型。
[0081]
构建一个bert-bi-lstm-crf命名实体识别模型,由bert嵌入层,bi-lstm层,crf层串联组成。
[0082]
设置每层的参数如下:将bert嵌入层的网络层数设置为10,隐藏单元数设置为384,注意头个数设置为10。bi-lstm层采用xavier方法实现对bi-lstm中的每个神经元的参数进行初始化;crf层采用randn函数实现对转移矩阵进行初始化。
[0083]
步骤4,训练命名实体识别模型。
[0084]
训练过程为:将训练集输入到bert-bi-lstm-crf命名实体抽取模型中,得到所有命名实体的标注序列,利用误差公式,计算训练集中每个特征向量序列的预测标注序列与训练样本实际标注序列的损失值,将每个特征向量序列的损失值,按照随机梯度下降法,依据所有特征向量序列的损失值,反向传播调整bi-lstm层中的神经元个数,直至损失值小于或等于0.1为止,得到训练好的bert-bi-lstm-crf模型。
[0085]
所述误差公式如下:
[0086][0087]
其中,mse表示为均方误差,n表示为样本的个数,yi表示为训练样本实际标注序列,表示为每个特征向量预测标注序列。
[0088]
本发明实施例中经过模型训练后,参数更新为:对于bert嵌入层,网络层数为12,隐藏单元数为768,注意头个数为12,对于bi-lstm层,bi-lstm的隐藏层数为128,对于crf层,crf层的转移矩阵为:
[0089][0090]
步骤5,构建bert实体关系抽取模型。
[0091]
构建一个bert实体关系抽取模型,由bert编码层,信息交互层,关系抽取层串联组成。
[0092]
设置bert实体关系抽取模型的初始参数如下:将最大单词数设置为64,批数据大小设置为64,学习率设置为1
×
10-5
,丢弃率设置为0.3。
[0093]
步骤6,训练bert实体关系抽取模型。
[0094]
训练过程为:将训练集中的每一个特征向量序列输入到bert实体关系抽取模型中,得到两两命名实体之间的关系向量;利用与步骤4相同的误差公式,计算训练集中每个特征向量序列的预测关系标注序列与训练样本实际关系标注序列的损失值,将每个特征向量序列的损失值,按照随机梯度下降法,依据所有特征向量关系序列的损失值,按照随机梯度下降法调整学习率和丢弃率,直至损失值小于或等于0.1为止,得到训练好的bert模型。
[0095]
本发明实施例中经过模型训练后,bert实体关系抽取模型的最大单词数为128,批数据大小为32,学习率为2
×
10-5
,丢弃率为0.5,迭代次数为10次。
[0096]
步骤7,对smt产线结构化数据集进行处理。
[0097]
本发明实施例是采用某公司的smt产线结构化数据集作为知识来源。该smt结构化数据集包含该公司近一年近一千万条生产数据,数据均为csv结构化数据。
[0098]
本发明实施例中某公司的smt产线结构化数据集的内容如表6所示:其中数据集的特征为刮刀压力、刮刀速度、印刷高度补偿、工作台分离速度、自动清洗计数、清洗速度、工作台分离距离、清洗供给时间、刮刀分离距离;数据集的质量指标为体积、面积、高度、x偏移量和y偏移量。
[0099]
表6smt产线结构化数据集一览表
[0100][0101]
经统计分析得出刮刀压力字段的众数为12,从而用12填充第3条数据中刮刀压力
的缺失值nan。
[0102]
经统计分析得出刮刀速度字段的众数为20,从而用20填充第4条数据中刮刀速度的缺失值nan。
[0103]
经统计分析得出工作台分离速度的众数为0.333,从而以0.333填充第5、第6条数据的工作台分离速度的缺失值nan。
[0104]
利用正态分布和箱型图对所有数据进行异常值检测,检测出第6条数据的体积为异常值,从而删除第6条数据。
[0105]
采用min-max规范化对部分数据进行无量纲处理。min-max规范化通过线性变换将原始数据缩放到[0,1]区间,可表示为公式:
[0106][0107]
其中,x为原始数据,x
min
为x所属列的最小值,x
max
为x所属列的最大值,x
*
为归一化之后的结果。
[0108]
采用z-score对原始数据进行标准化处理,使之呈现正态分布,如公式所示:
[0109][0110]
其中,u为x所属列的均值,σ为x所属列的标准差。
[0111]
经过以上所有处理之后,smt产线结构化数据集如表7所示:
[0112]
表7smt产线结构化数据预处理结果
[0113][0114]
参照图5smt产线结构化数据知识抽取流程图,对本发明步骤8抽取smt产线结构化数据知识的实现步骤作进一步的详细描述。
[0115]
步骤8,设置xgboost质量指标预测模型初始化参数如表8所示。
[0116]
表8xgboost模型关键参数初始化信息表
[0117][0118]
步骤9,优化xgboost质量指标预测模型参数。
[0119]
步骤9.1,将训练集中的特征输入到xgboost质量指标预测模型中,分别输出预测锡膏的质量指标值。
[0120]
步骤9.2,利用与步骤4相同的误差公式,计算训练集中特征的预测质量指标值与训练集实际质量指标值的损失值。
[0121]
步骤9.3,依据步骤9.2的损失值,用pso算法对xgboost模型性能影响较大的5个参数进行优化,直至损失值小于或等于0.1,得到优化好的xgboost质量指标预测模型参数。
[0122]
步骤9.4,利用xgboost算法中的重要度公式,计算数据集中每个锡膏印刷特征的影响因素重要度;xgboost算法的影响因素重要度公式如下式:
[0123][0124]
其中,scorei表示数据集中第i个锡膏印刷特征的影响因素重要度,g
l
表示xgboost算法中所有左叶子节点一阶导数之和,gr表示xgboost算法中所有右叶子节点一阶导数之和,h
l
表示xgboost算法中所有左叶子节点二阶导数之和,hr表示xgboost算法中所有右叶子节点二阶导数之和,ρ和γ表示使xgboost算法的损失函数达到最小时的正则化参数。
[0125]
本发明的实施例中xgboost待优化参数的取值区间如表9所示:
[0126]
表9xgboost模型待优化参数区间
[0127][0128]
本实施例中xgboost质量预测模型参数优化后如表10所示:
[0129]
表10xgboost模型关键参数优化后信息
[0130][0131]
本实施例中各个特征的影响因素重要度如表11所示:
[0132]
表11锡膏印刷质量影响因素重要度分析结果
[0133][0134][0135]
步骤10,smt产线高发缺陷成因关联分析。
[0136]
第一步,根据spi光学检测机自身的检测阈值,将spi光学检测机实时检测得到的锡膏高度偏高、锡膏体积大、锡膏面积大、无锡高、x正偏移、y正偏移的缺陷确定为关联目标数据,将smt印刷过程中的刮刀压力、刮刀速度、印刷高度补偿、工作台分离速度、自动清洗计数、清洗速度、工作台分离距离、清洗供给时间、刮刀分离距离作为影响因素数据。对影响因素数据采用距离区间法对连续数据进行离散化处理。
[0137]
第二步,根据实践经验人为设定最小支持度为0.1,最小置信度为0.6。
[0138]
第三步,对关联目标数据和影响因素数据进行apriori关联规则挖掘,将apriori关联规则挖掘的输出结果作为smt产线高发缺陷成因关联分析得到最终结果。
[0139]
本实施例中挖掘出的规则如表12所示:
[0140]
表12smt产品高发缺陷成因关联规则
[0141][0142]
对上表作进一步描述为:工作台印刷高度补偿为c1时,会导致锡膏高度偏高这一规则的支持度为0.357,置信度为0.919,刮刀压力为a2时,会导致锡膏高度偏高这一规则的支持度为0.259,置信度为0.668。
[0143]
步骤11,存储与查询知识。
[0144]
步骤11.1,按照三元组的形式来表示非结构化数据抽取的知识和结构化数据抽取到的知识;每个实体按照《实体,属性名称,属性值》形式的三元组进行存储,实体与实体之间是通过关系建立连接,保持连接的两个实体之间具有数据描述的一致性,并确保可以满足《实体1,关系,实体2》形式的三元组。
[0145]
本实施例中三元组表示为:
[0146]
《调整钢网开口,避免,桥连》
[0147]
《钢网开口过大,导致,桥连》
[0148]
步骤11.2,基于neo4j存储知识。将抽取到的知识统一表示之后,导入neo4j,构建smt产线质量知识图谱。
[0149]
参照图6的知识图谱关系图,对步骤11.2作进一步描述。图6中的每一个圆圈代表一个实体,实体与实体之间的箭头表示二者存在关系。例如“锡珠—导致—pcb脏污”。
[0150]
步骤11.3,采用cypher语句实现数据的高效检索。
[0151]
本发明实施例中查询锡珠现象的成因,对应的cypher语句为:“match(reason:reason)
‑‑
(defect:defect)where defect.name="锡珠"return reason,defect”。结合图7的查询结果,对知识图谱数据的高效检索作进一步描述。图7中每一个圆圈代表一个实体,实体与实体之间的箭头表示二者存在关系。例如“加热过快会导致锡珠”,“焊盘氧化会导致锡珠”,“焊膏过厚会导致锡珠”。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1