基于Raft的冷数据存储方法
基于raft的冷数据存储方法
技术领域
1.本发明涉及存储技术领域,更具体的说是涉及一种基于raft的冷数据存储方法。
背景技术:
2.数据量的激增促进了信息存储领域的发展,同时也带来了新的挑战。这些数据按照访问频率大致可分为两类:经常访问的数据和不经常访问的数据,经常访问的数据被称为热数据,不经常访问的数据被称为冷数据。其中热数据只占比20%以下,因而大量数据都是冷数据,如果无差别的存储冷热数据,必然会浪费资源。此外,在大规模数据存储的时候,往往无法仅仅依靠单机设备完成存储,因为单机性能、存储容量、可靠性、可用性不能达到行业标准,所以通常需要成百上千个机器组成存储集群来存储数据,因此很多公司和单位开始研发和运用分布式存储技术。
3.纠删码技术是一种数据冗余容错机制,具备数据冗余度低、容错能力又足够高等特点。在分布式存储系统中,为了高可靠、高存储空间利用率地存储冷数据,越来越多的场景开始引入这种技术。采用纠删码存储技术可以将原来需要存储的完整数据分成很多片段并编码成一些奇偶校验片段,然后每个机器只存储其中的一个片段从而缩小占用的存储空间,进而带来存储成本和网络流量上的收益。但是分布式系统中依然存在纠删码技术无法解决的共识问题。
4.paxos和raft等共识协议可以用于解决该问题,从而提供高可用和高可靠的存储服务,因而被广泛部署在工业应用中。这种共识协议将用户数据转换为日志命令条目,然后将它们复制到不同的服务器中,最后用户数据被冗余地存储在集群中的所有服务器上,从而保证这些用户数据免受服务器故障或数据损坏的影响。但是paxos和raft使用副本形式的数据冗余机制来帮助系统容忍故障,该机制花费大量空间来存储冗余数据,并且将副本数据复制到其他服务器也带来了很多网络流量开销。例如,在一个有n=(2f+1)个服务器的集群中,采用副本冗余容忍故障的共识算法可能会导致大约是原始数据量n倍的网络和存储开销。
5.为了将冷数据以纠删码冗余形式存储在分布式集群中,并解决其中的共识问题,现有两种方法被广泛使用:异步或同步。例如对于异步存储方法,数据会通过比如raft、paxos这样的共识协议或者其他能解决共识问题的方法先以副本形式存储在集群中,稍后再异步进行纠删编码过程,虽然存储完成后副本数据会被清除以提高存储空间利用效率,但是这些中间副本数据不可避免地会导致额外的存储设备io和网络流量。对于同步存储方法,数据在写入时会立即被编码,因此存储过程中不会出现中间副本数据,但是同步存储方式要求在返回客户端成功前所有数据片段和校验片段都被成功写入存储集群中,因此,任何由服务器或网络故障引起的编码片段丢失都会很快干扰写入过程,这往往需要在系统设计中附加额外机制来解决。
6.因此,如何节省冷数据存储过程中的存储空间和网络流量开销,提高该过程的效率是本领域技术人员亟需解决的技术问题。
技术实现要素:
7.有鉴于此,本发明提供了一种基于raft的冷数据存储方法,提升了冷数据存储过程中的存储效率、空间和网络带宽利用率。
8.为了实现上述目的,本发明提供如下技术方案:
9.一种基于raft的冷数据存储方法,包括以下步骤:
10.在分布式集群中构建多个ecraft组,所述ecraft组的组内成员通过选举得到每个ecraft组的领导者;
11.所述领导者在组内周期性地发送心跳,并根据心跳信息预测组内成员状态;
12.客户端写入请求到达后,基于负载情况选择合适的ecraft组处理所述写入请求;
13.被选择ecraft组的领导者将所述写入请求中包含的数据进行纠删编码,并根据预测的组内成员状态生成并分发日志条目;
14.所述领导者通过状态机清理冗余数据并通过心跳同步更新组内成员的相关数据,最终将数据以纠删码片段的形式存储在所述分布式集群中。
15.上述技术方案达到的技术效果为:在共识协议raft的基础上提出ecraft,改变raft的选举和提交条件,使用更优化的自适应数据冗余方式,增加了状态机数据清理机制,并使用multi-ecraft的机制解决单机性能瓶颈问题。
16.可选的,所述在分布式集群中构建多个ecraft组,具体包括以下步骤:
17.采用l台服务器组成multi-ecraft集群,每台服务器包含若干个工作存储设备和备用存储设备;
18.在每台服务器上均匀选取n块型号相同或者容量差值在预设范围内的工作存储设备并组合得到一个ecraft组;其中,所选取工作存储设备数量总和为n=2f+1=k+m,k表示存储设备存储数据片段的数量、m表示存储设备存储校验片段的数量、k》m;
19.重复以上选取及组合过程,直至ecraft组数量足够或所有服务器上的工作存储设备都被取完,最终得到q个ecraft组。
20.可选的,所述组合得到一个ecraft组,具体包括以下步骤:
21.根据纠删码的配置以及集群的服务器数量计算组内成员的分布;
22.统计集群中的存储设备型号和数量,从型号最多的存储设备开始分组,若同型号的存储设备数量不够,则寻找容量差值在预设范围内的存储设备进行补充;
23.统计集群中的每个服务器上某个型号的存储设备数量;
24.从所述型号存储设备最多的服务器开始选取,依次从对应的服务器上取得相应数量的工作存储设备且每个服务器保留一定比例的备用存储设备未分配;若每个服务器上存储设备充足,则分配成功,组成ecraft组并将所述ecraft组的配置信息加入元数据管理数据库中;
25.若服务器上存储设备不充足,在选择工作存储设备时,所选型号的数量超过所述ecraft组的一半,则选择容量差值在预设范围内的工作存储设备继续组合;若所选型号的数量未超过所述ecraft组的一半,则中断ecraft组的选择,重新选择其他型号的存储设备,统计集群中的每个服务器上重新选择型号的存储设备数量并继续进行ecraft组的组合。
26.可选的,所述ecraft组的组内成员通过选举得到每个ecraft组的领导者,具体包括以下步骤:
27.各个ecraft组独立发起领导者选举,每个组内的所有成员均有随机超时机制,当固定时间内未收到领导者的心跳会超时成为候选者,所述候选者向组内其他成员广播竞选消息;
28.当其他成员收到所述竞选消息后,确认自己的日志和所属任期在所述候选者之前时,会投出赞成票;
29.当组内有k个成员投出赞成票时,所述候选者成为领导者。
30.可选的,所述预测组内成员状态,具体为:
31.所述领导者周期性向组内其他成员发送心跳信息,成员收到心跳信息后完成更新日志操作并返回领导者,所述领导者以最近一次心跳成功响应的成员情况为依据预测组内成员状态。
32.可选的,所述选择合适的ecraft组处理所述写入请求,具体包括以下步骤:
33.判断客户端写入的文件是否存在,若存在则返回所述文件所在ecraft组;若所述ecraft组的执行队列已满,则加入所述ecraft组的等待队列;否则,加入所述ecraft组的执行队列;
34.若客户端写入的文件不存在,则根据各个ecraft组的任务量情况,将所述文件分配至一个任务量最少的ecraft组。
35.可选的,所述生成并分发日志条目,具体包括以下步骤:
36.被选择ecraft组的领导者对写入请求中的数据块进行纠删编码,将所述数据块分成k个大小相同的数据片段,并编码生成m个校验片段;
37.领导者根据预测的组内成员状态决定数据的冗余策略,并将生成的编码片段封装成日志条目分发给组内各个成员,具体为:
38.当所有k+m个成员均被预测为健康时,领导者将所有编码片段分发到对应的成员上,并确保所有片段均已经持久化;
39.当p个成员被预测为无法接收相应片段且p《=m时,领导者将故障成员应保存的编码片段持久化到每一个健康的成员中,且健康成员同时保存自己对应的编码片段;
40.当p个成员被预测为无法接收相应片段且p》m时,采用副本复制的策略,领导者将完整数据封装为日志条目复制到其他成员中,ecraft组中半数以上的成员复制成功后即响应客户端成功;
41.在领导者分发日志的过程中,当ecraft组状态预测错误导致分发日志失败时,领导者重新预测并按照最新的ecraft组状态重新分发;若重发次数大于系统配置参数q,则领导者采用副本复制策略继续重试。
42.可选的,所述方法还包括:
43.若组内成员缺乏已经被领导者提交的日志,则需领导者将所述日志相应的编码片段复制给所述组内成员;
44.若客户端写入请求被领导者成功持久化到组内成员中,则需领导者提交日志并响应客户端成功,完成冷数据存储过程,否则领导者会一直重试直到客户端等待超时。
45.可选的,所述领导者通过状态机清理冗余数据并通过心跳同步更新组内成员的相关数据,具体为:
46.在领导者分发数据的过程中,ecraft组故障的出现导致成员持久化不属于所述成
员的编码片段,当这些编码片段被与之对应的成员重新保存后,领导者进行状态机删除;若ecraft组中的所有成员均为健康的,则最终所有健康成员的状态机中仅保留与自己对应的片段数据。
47.可选的,所述方法还包括:
48.若ecraft组所在工作存储设备已满且已经完成状态机删除,所述ecraft组中所有成员均没有存储不属于与自己对应的编码片段,则所述ecraft组满足存储设备下电条件,集群之后关闭所述ecraft组内所有成员所在工作存储设备的电源。
49.经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于raft的冷数据存储方法,具有以下有益效果:
50.(1)本发明对客户端的请求数据直接进行编码并分发,避免了现有方法中对完整数据的复制与分发,进而带来更低的存储io开销和网络成本;
51.(2)本发明可以达到和异步冷数据存储方式一样的容错能力,且最后状态机中都只有纠删码数据,且本方案没有引入存储中间完整数据的过程,因而存储过程更简单、效率更高;
52.(3)本发明采用multi-ecraft的机制,能合理利用集群中所有服务器的性能,避免领导者所在服务器因任务量大而达到瓶颈,从而影响了整个集群的性能;
53.(4)本发明中ecraft组独立管理,文件被尽量地集中存储,从而方便集群对该组存储设备的上下电、扫描、重构逻辑的管理。
附图说明
54.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
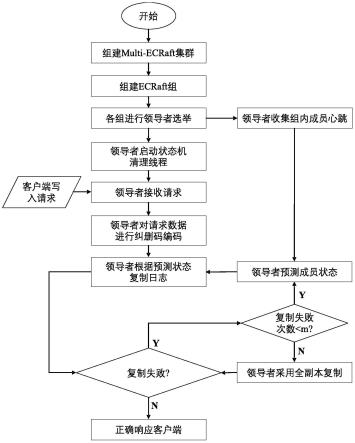
55.图1为基于raft的冷数据存储方法的实现流程图;
56.图2为multi-ecraft架构设计图;
57.图3为编码过程图;
58.图4为自适应的编码片段复制方式图;
59.图5为状态机清理过程图。
具体实施方式
60.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
61.本发明实施例公开了一种基于raft的冷数据存储方法,包括以下步骤:
62.在分布式集群中构建多个ecraft组,ecraft组的组内成员通过选举得到每个ecraft组的领导者;
63.领导者在组内周期性地发送心跳,并根据心跳信息预测组内成员状态;
64.客户端写入请求到达后,基于负载情况选择合适的ecraft组处理写入请求;
65.被选择ecraft组的领导者将写入请求中包含的数据进行纠删编码,并根据预测的组内成员状态生成并分发日志条目;
66.领导者通过状态机清理冗余数据并通过心跳同步更新组内成员的相关数据,最终将数据以纠删码片段的形式存储在所述分布式集群中。
67.接下来,参照图1,对基于raft的冷数据存储方法的实现步骤进行更进一步地分析。
68.步骤1:采用l台服务器组成multi-ecraft集群,每台服务器包含若干个工作存储设备和备用存储设备,具体地,存储设备可以为机械硬盘;参照图2,在本实施例中,使用4台服务器组建集群,每台服务器包含若干块工作硬盘和备用硬盘。
69.步骤2:在每台服务器上均匀选取n块型号相同或者容量性能相似的工作硬盘,需要满足所选取工作硬盘数量总和为n=(2f+1)=(k+m),其中k个硬盘存储数据片段、m个硬盘存储校验片段,k》m;采用(k,m)-rs纠删码配置,rs为reed-solomon码,将这些工作硬盘组合成一个ecraft组,ecraft组的成员可以是一块硬盘、多块硬盘或者一块硬盘的其中一部分,该过程的实施步骤如下:
70.2.1)根据纠删码的配置以及集群的服务器数量计算组内成员的分布;
71.2.2)统计集群中的硬盘型号和数量,从型号最多的硬盘开始分组,若同型号的硬盘数量不够,则寻找容量差值在预设范围内的硬盘进行补充;
72.2.3)统计集群中的每个服务器上某个型号的硬盘数量,如统计结果为m={m1,m2,...,mn},mi表示第i个服务器上该型号硬盘的数量;
73.2.4)将m从大到小的方式排列,依次从对应的服务器上取得相应数量的硬盘,每个服务器会保留一定比例的硬盘未分配;若每个服务器上硬盘充足,则分配成功,执行2.6),否则执行下一步;
74.2.5)在选择工作硬盘时,所选型号的数量一定要占该ecraft组的大多数,若不是,则中断该ecraft组的选择,重新选择其他型号的硬盘,回到步骤2.3);若超过了大多数,但是硬盘数量不够,则选择容量差值在预设范围内型号的硬盘,继续组合;
75.2.6)成功组成ecraft组,将ecraft组的配置信息加入元数据管理数据库中。
76.在本实施例中,n=2、n=6、k=4、m=2,在每台服务器保留2块备用硬盘,ecraft组的成员是一块硬盘;有4个存储服务器,每个服务器上分布2个成员。服务器1上有a型号的硬盘20个,所以服务器1上的硬盘只能分配到9个ecraft组。
77.步骤3:重复步骤2的过程,直至所有服务器上的工作硬盘都被取完,最终得到q个ecraft组,每个组的成员表示为s=(s1,s2...si...sn)。
78.在本实施例中,参照图2,q=3,这3组ecraft硬盘均匀分布在4台服务器中,组内成员表示为s=(s1,s2,s3,s4,s5,s6)。
79.步骤4:各个ecraft组独立发起领导者选举,每个ecraft组内的所有成员均有随机超时机制,当一段时间未收到领导者的心跳会超时成为候选者,随后候选者向组内其他成员广播竞选消息;当其他成员收到该消息后,如果发现自己的日志和所属任期不比该候选者的新,就会投出赞成票;当候选者收到k个赞同响应后(包括自己投的赞成票),该候选者成为该组的领导者。
80.在本实施例中,追随者成为候选者后,向其他成员发布竞选信息,因为自己也会投一票,所以当自己收集到3个其他成员的赞同票后,就会成为领导者。
81.步骤5:领导者周期性向组内其他成员发送心跳信息,成员随即会做出响应。当领导者确认收到了某个成员的心跳回应后,即认为该成员是健康的。领导者会维系一个动态变化的健康成员列表,记录此时刻领导者认为是健康的成员,此列表就是预测的组内成员状态u。
82.在本实施例中,如果领导者可以收到组中所有成员的心跳回应,那么它预测的组内成员状态u=(s1,s2,s3,s4,s5,s6)。
83.步骤6:客户端写入请求w到达,集群会根据负载情况选择ecraft组处理该请求,具体为:
84.6.1)判断客户端写入的文件是否存在,若存在则返回该文件所在ecraft组;
85.6.2)若该ecraft组的执行队列已满,则加入该ecraft组的等待队列;否则,加入其执行队列;
86.6.3)若客户端写入的文件不存在,则根据各个ecraft组的任务量情况,为其分配一个任务量最少的ecraft组。
87.在本实施例中,ecraft组执行队列的长度为100。
88.步骤7:被选择ecraft组的领导者先将该请求包含的数据进行纠删编码,过程参见图3,将数据分割为k个大小相同的数据片段d=(d1,d2,...,dk),对d进行rs编码后生成m个校验片段q=(q1,q2,...,qm),这些片段组合为f=(f1,f2,...,f
k+m
)=(d1,d2,...,dk,q1,q2,...,qm)。时期和索引是协议需要的元信息,领导者分发的日志包含数据或校验片段、时期、索引。
89.在本实施例中,集群维护每个ecraft组的负载列表,每次选择负载最少的ecraft组服务客户端请求,领导者将数据分割为4个大小相同的数据片段d=(d1,d2,d3,d4),对d进行rs编码后产生2个校验数据片段q=(q1,q2),这些片段组合为f=(f1,f2,...,f6)=(d1,d2,d3,d4,q1,q2),每条日志都由片段、时期和索引组成。
90.步骤8:领导者根据预测的组内成员状态生成并分发日志条目,存在下面四种情况:
91.8.1)所有成员s=(s1,s2...si...sn)都在领导者的健康列表中,领导者将f一一对应的封装到(k+m)个不同的日志l=(l1,l2,...lk...l
k+m
)中,其中(l1,l2,...lk)一一对应的包含(d1,d2,...,dk),(l
k+1
...l
k+m
)一一对应的包含(q1,q2,...,qm)。l和s之间也是一一对应的,即除了自己以外,领导者将l1发给s1、l2发给s2,以此类推,l
k+m
发给sn。当所有成员s持久化对应的日志后,领导者即可提交日志l。
92.8.2)se=(s
e1
,s
e2
,...,s
ep
)成员被领导者预测是故障的,其中p《=m,那么领导者分发给剩余健康成员的日志li不仅要包括与其对应的片段fi,还需包括se应该保存的片段fe=(f
e1
,f
e2
,...,f
ep
),即li=(fi,f
e1
,f
e2
,...,f
ep
),其中i表示某个健康的成员。所有剩余健康成员持久化了这些片段后,领导者即可提交该日志。
93.8.3)se=(s
e1
,s
e2
,...,s
ep
)成员被领导者预测是故障的,其中p》m,采用副本复制的策略,副本复制策略中领导者将客户端完整数据封装为日志条目复制到其他健康成员中,当组中半数以上的成员持久化了该日志后,领导者即可提交该日志。副本复制的详细过
程同raft,不再赘述。
94.8.4)在领导者分发日志的过程中成员状态变化导致分发失败,分发日志前,si成员被预测正常,但是分发日志过程中,si故障导致其无法接收日志,此时,领导者需更新成员状态,并按照最新的成员状态重新分发该日志,重发次数加1。
95.8.4.1)如果重发次数小于等于q(系统配置参数)次,领导者重新执行步骤5所示的分发策略;
96.8.4.2)如果重发次数大于q(系统配置参数)次,领导者执行副本复制策略;在本实施例中,图4展示了5.1和5.2的过程,成员s4被选举为领导者,当所有成员都健康时,条目b在t0时到达,领导者在提交条目b之前,除了自己要持久化条目b和b的编码结果,也就是b1,b2,b3,b4,b5,b6,还需要确认b1,b2,b3,b5,b6分别被s1,s2,s3,s5,s6一一对应的持久化了。在t1时刻,条目c到达,s6发生故障。领导者将每个成员对应的片段和c6存储到s1,s2,s3,s5中。在t2时刻条目d到达,s5和s6发生故障,所以领导者需要将每个成员对应的片段和d5、d6持久化到s1,s2,s3中。
97.步骤9:对于已经被领导者提交的日志,如果组中存在某个成员缺少它们,此时有两种情况:
98.9.1)领导者上存在f=(f1,f2,...,f
k+m
)这些数据的片段形式,它将包含对应片段的日志发送给这个成员即可,比如si中如果缺乏fi,领导者将li发给si;
99.9.2)领导者上只存在副本数据,它先进行纠删码编码过程生成这些片段,随后将对应片段发送给相应成员。
100.步骤10:如果客户端的写入请求w被领导者按照步骤8的方式成功持久化到组内成员中,领导者便可以提交日志并响应客户端成功,否则领导者会一直重试直到客户端等待超时。
101.步骤11:11.2)、11.3)、11.4)复制过程会在s=(s1,s2...si...sn)上持久化了(f
e1
,f
e2
,...,f
ep
)或完整副本数据。状态机清理过程将清理这些数据,该过程不会直接删除日志条目,而是删除状态机中该日志的数据。
102.11.1)领导者靠心跳了解每个成员的日志存储情况,如果它发现s1持久化并应用了l1,s2持久化并应用了l2,以此类推,sn持久化并应用了l
k+m
。它将标记l为可清理的条目,并且更新最大可清理日志索引号为l的索引号;
103.11.2)领导者先根据最大可清理日志索引号清理自己的日志,然后通过心跳告知其他成员自己已经清理日志的最大索引号,其他成员依据此索引号对各自的状态机执行清理,此外领导者可以选择周期性或者手动在系统空闲,比如夜间或者存储容量不足等合适的时机触发状态机清理;
104.11.3)在完成l的状态机清理后,s1的状态机仅留下l1的数据,s2的状态机仅留下l2的数据,以此类推,sn的状态机留下l
k+m
的数据。
105.在本实施例中,参见图5,s4是领导者,采用的纠删码配置是(4,2)-rs。ecraft组内成员s=(s1,s2,s3,s4,s5,s6),条目a的片段已分别被6个成员持久化,而条目b还没有,因为b6没被s6持久化,因此条目a是可清除的,最大可清理日志索引号更新为a的索引号。在对a清除的过程中,s4先删除条目a的其他片段应用到状态机中的数据,只保留f4应用到状态机的数据,随后告知si(1≤i≤n,i≠4)去删除fj(j≠i)应用到状态机的数据。
106.步骤12:如果ecraft组所在硬盘已满,且已经完成步骤11,该ecraft组中所有成员均没有存储不属于它的编码片段,则该ecraft组满足磁盘下电条件,集群之后会关闭该ecraft组内所有成员所在硬盘的电源。
107.本发明对客户端的请求数据直接进行编码并分发,避免了现有方法中对完整数据的复制与分发,进而带来更低的存储io开销和网络成本;可以达到和异步冷数据存储方式一样的容错能力,且最后状态机中都只有纠删码数据,且本方案没有引入存储中间完整数据的过程,因而存储过程更简单、效率更高;采用multi-ecraft的机制,能合理利用集群中所有服务器的性能,避免领导者所在服务器因任务量大而达到瓶颈,从而影响了整个集群的性能;ecraft组独立管理,文件被尽量地集中存储,从而方便集群对该组硬盘的上下电、扫描、重构逻辑的管理。
108.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
109.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1