一种积雪深度的反演方法及装置
1.本技术涉及积雪深度监测技术领域,尤其涉及一种积雪深度的反演方法及装置。
背景技术:
2.积雪深度是指积雪的高度,是一个相对的概念,定义为从积雪下垫面到雪层表面的垂直距离,在土壤和大气的能量传输过程中扮演着重要的角色。因此,获取大范围积雪深度的时空分布信息是一项具有重大研究价值的工作,是理解全球气候变化、地表能量平衡、区域水循环的必要前提。
3.微波遥感科学技术的发展为解决传统的积雪观测面临的困难提供了新的手段,伴随着星载卫星的蓬勃发展,为气候、水资源、地球能量平衡的研究提供了广覆盖、长时序的连续观测数据,为我们能获取大尺度、高精度的积雪深度的时空分布信息带来了新的曙光。
4.积雪覆盖地区的微波出辐射主要包括雪层下垫面的背景辐射以及积雪层自身的辐射。被动微波遥感技术监测和反演积雪参数的理论基础主要是积雪的微波辐射特性会随着雪层内部结构(积雪粒径、积雪密度)、积雪深度、积雪温度和液态含水量等参数的变化而变化。研究表明,对于微波低频波段,积雪的辐射信号主要是来自积雪下垫面的背景辐射特性,当温度升高,雪层开始发生融化的时候,因为冰粒子与液态水的介电特性有很大的差异,雪层的辐射信号逐渐增大,此时,积雪辐射观测信号主要是来自积雪层表面的信息,这也就意味着微波信号对于积雪液态含水量非常敏感,在湿雪情况下,观测信号中很难提取到雪层深度的信息。对于微波高频波段,干雪是很强的散射体,其吸收和辐射特性相对较弱,因此积雪介质对于微波高频波段的消光作用(消光系数等于散射系数和吸收系数之和),主要是散射作用为主。因此,随着微波频率的增加,雪层的内散射逐渐增大,传输信号逐渐减小,可用于提取干雪的积雪深度信息。
5.目前,在全球范围内,探测积雪深度信息的算法主要可以总结为以下几种:基于统计回归的半经验算法、同化算法以及基于机器学习的反演算法。基于统计回归的半经验算法假定积雪粒径和积雪密度取固定值或者经验值,没有考虑积雪粒径和积雪密度的时空变化信息,因此会存在明显的季节性反演误差。同化算法比较典型的是欧空局的globsnow北半球积雪产品,该产品考虑了积雪粒径的变化,但是算法中采用经验值,没有考虑积雪密度的时空变化对积雪深度反演带来的影响。机器学习算法可以很好的学习自变量和因变量之间的非线性关系,并进行高效的预测,可以用来进行监测积雪深度信息。
6.机器学习算法具有自适应学习的能力解决非线性问题,但类似于黑箱操作,缺少对积雪属性和物理过程的表达。目前,机器学习算法在区域尺度上得到了相对较好的反演精度。但是,已有的公开的算法,发现关于有效自变量的选择目前还没有详细公开,比如,亮度温度梯度,积雪粒径,积雪密度,森林参数等,如何选择代表性好且相关性低的自变量是目前机器学习面临的一个重要挑战。其次,现有的算法基本上是区域小尺度,雪层的积雪特性参数并不复杂,例如,中国地区雪浅,还没有出现超过60cm以上积雪大粒径情况下的病态反演问题等,因此,在全球大尺度下,机器学习算法还不能有效的反演复杂状态积雪深度,
导致积雪深度的预测效率低,预测精度较低。
技术实现要素:
7.本技术提出一种积雪深度的反演方法及装置,旨在解决现有技术的机器学习算法不能有效反演复杂状态积雪深度,导致积雪深度的预测效率低,预测精度较低的问题。
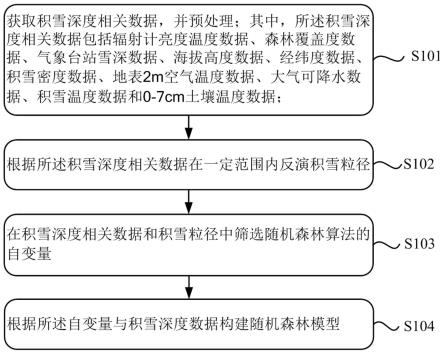
8.本技术实施例提供一种积雪深度的反演方法,包括:获取积雪深度相关数据,并预处理;其中,所述积雪深度相关数据包括辐射计亮度温度数据、森林覆盖度数据、气象台站雪深数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据;根据所述积雪深度相关数据在一定范围内反演积雪粒径;在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量;根据所述自变量与积雪深度数据构建随机森林模型。
9.在一些实施例中,所述在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量,筛选出的自变量包括:积雪粒径、亮温梯度差tbd(18v-37v)、积雪密度、森林覆盖度、海拔高度、经度。
10.在一些实施例中,所述在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量,筛选出的自变量包括:积雪粒径、亮温梯度差tbd(18v-37v)、积雪密度、森林覆盖度、海拔高度、经度和纬度。
11.本技术实施例还提供一种积雪深度的反演装置,包括:数据获取单元,用于获取积雪深度相关数据,并预处理;其中,所述积雪深度相关数据包括辐射计亮度温度数据、森林覆盖度数据、气象台站雪深数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据;积雪粒径计算单元,用于接收所述数据获取单元中所述积雪深度相关数据,并在一定范围内反演积雪粒径;模型训练单元,用于接收数据获取单元中的积雪深度相关数据,以及积雪粒径计算单元输出的积雪粒径,从中筛选随机森林算法的自变量;根据所述自变量与积雪深度数据构建随机森林模型。
12.本技术实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述的积雪深度的反演方法。
13.本技术实施例还提供了一种电子设备,包括存储器,处理器及存储在存储器上并可在处理器运行的计算机程序,所述处理器执行所述计算机程序时实现上述的积雪深度的反演方法。
14.本技术实施例采用下述技术方案:获取积雪深度相关数据,并预处理;其中,所述积雪深度相关数据包括辐射计亮度温度数据、森林覆盖度数据、气象台站雪深数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据;根据所述积雪深度相关数据在一定范围内反演积雪粒径;在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量;
根据所述自变量与积雪深度数据构建随机森林模型。
15.本技术实施例采用的上述至少一个技术方案能够达到以下有益效果:本技术可以更好的学习自变量数据和因变量数据之间的非线性关系,并进行高效的预测,可以用来监测积雪深度信息。本技术实施例基于随机森林算法训练得到的积雪深度预测模型具有高效的运行效率以及较高的预测精度,可以提高反演结果的精度,对积雪深度信息进行高效和精准的预测。
附图说明
16.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:图1为本技术实施例提供的一种积雪深度的反演方法流程图;图2为本技术实施例提供的积雪粒径频率分布图;图3为本技术实施例提供的积雪深度预测模型的10个输入参数与积雪深度的相关性示意图;图4为本技术实施例提供的各参数对于积雪深度的影响程度示意图;图5为本技术实施例提供的考虑积雪粒径和积雪密度的随机森林模型反演精度示意图;图6为本技术实施例提供的一种预测积雪深度的方法流程图;图7为本技术实施例提供的考虑积雪粒径和积雪密度的随机森林反演方法与其他全球雪深数据的精度比较示意图;图8为本技术实施例提供的一种基于随机森林模型的积雪深度反演装置结构示意图;图9为本技术实施例提供的一种电子设备的结构示意图。
具体实施方式
17.为使本技术的目的、技术方案和优点更加清楚,下面将结合本技术具体实施例及相应的附图对本技术技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
18.以下结合附图,详细说明本技术各实施例提供的技术方案。
19.实施例1如图1所示,本技术实施例提供了一种积雪深度的反演方法,该方法包括:s101:获取积雪深度相关数据,并预处理;其中,所述积雪深度相关数据包括辐射计亮度温度数据、森林覆盖度数据、气象台站雪深数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据;可选地,辐射计亮度温度数据采用高性能微波辐射计的微波亮度温度数据。如星载被动微波亮温数据:采用的是搭载于全球环境变化观测卫星(global change observation mission-water 1,gcom-w1)的高性能微波扫描辐射计-2(the advanced microwave scanning radiometer 2,amsr2)的微波亮温数据,数据的空间分辨率为0.25
°
×
0.25
°
。amsr2亮温数据的下载网址为:https://gportal.jaxa.jp/gpr/。
20.可选地,森林覆盖度数据采用modis地表分类数据。地表分类数据采用的是modis的mod12q1数据,使用数据中被广泛应用的igbp类型分类数据,求得微波亮温像元内的森林和水体等下垫面0.25
°
等经纬度格网的覆盖度数据。mod12q1地表分类数据的下载网址为:https://modis.gsfc.nasa.gov/。
21.可选地,气象台站雪深数据主要包括中国气象局提供的积雪站点数据和美国国家海洋和大气管理局公开免费共享的全球历史气象网每日数据集(global historical climatology network, ghcn)。ghcn数据下载网址:http://www.ncdc.noaa.gov/oa/climate/ghcn-daily。中国气象局的气象台站数据需要在官网进行提交申请,数据下载网站为:http://data.cma.cn/。
22.可选地,海拔高度数据采用的美国海洋和大气局提供的空间分辨率为1km全球海拔高度数据,首先要对数据进行取平均求得微波像元对应的0.25
°
等经纬度分辨率的格网数据。海拔高度数据的下载网址为https://www.ngdc.noaa.gov/mgg/topo/gltiles.html。
23.可选地,采用era5再分析数据集,其中包括积雪密度数据、2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据。era5是ecmwf发布的第五代全球大气再分析数据集,从发布以来被当作是era-interim的继承者。该数据集的时间跨度为1979年1月至今,数据集持续性更新,与实时大约相差1-2个月的时间,空间分辨率为0.25
°×
0.25
°
,时间分辨率为每小时。era5产品的免费下载网站为:https://cds.climate.copernicus.eu。
24.s102:根据所述积雪深度相关数据在一定范围内反演积雪粒径;可选地,所述反演积雪粒径是基于积雪辐射传输模型进行反演。
25.在一实施例中,积雪粒径的反演是基于积雪辐射传输模型(microwave emission model of layered snowpacks
ꢀ‑ꢀ
with improved born approximation, memls-iba)进行的。通过构建代价函数,利用迭代优化算法反演积雪粒径,当模拟的亮温与辐射计观测亮温误差最小时,输出积雪粒径的最优结果,其中,代价函数如下所示:其中,表示辐射传输模型模拟的亮温,表示辐射计观测亮温,是小括号内参数的函数,具体的,为积雪粒径,sd表示气象台站雪深数据插值得到的空间背景初始雪深,表示积雪密度,tg表示0-7cm土壤温度,ts表示积雪温度,表示大气可降水和森林覆盖度等参数。表示模型模拟的亮温与辐射计观测亮温的标准差。n=3,分别表示18.7ghz垂直极化通道、36.5ghz垂直极化通道以及18.7ghz和36.5ghz的垂直极化亮温差三个通道的结果。积雪粒径从0.05到0.5之间变化以0.001的步长变化,当代价函数最小时输出积雪粒径的反演结果。详细的过程可参考专利申请(zl202110099758.5 一种提取积雪层相关长度的方法)。
26.s103:在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量;
在一些实施例中,10个待选择的输入参数与积雪深度的相关性如图3所示。
27.在辐射计亮度温度数据中,对比了10.65ghz、18.7ghz、36.5ghz和89ghz微波频率,通过亮温梯度差(temperature brightness difference, tbd,简称亮温差)的形式研究和雪深的相关程度,即,tbd(10v-37v)表示的是10.65ghz与36.5ghz的垂直极化通道的亮温差,tbd(18v-37v)表示的是18.7ghz与36.5ghz的垂直极化通道的亮温差,tbd(10v-89v)表示的是10.65ghz与89ghz的垂直极化通道的亮温差,tbd(18v-89v)表示的是18.7ghz与89ghz的垂直极化通道的亮温差。其中,10.65ghz波长较长、穿透能力强,包含了更多的土壤的背景信息,89ghz波长较短、穿透能力较弱,基本上对20cm以上的积雪深度并不敏感。
28.如图3所示,4个亮温梯度差参数tbd之间的相关性很高,大于0.85,根据测试发现相关性高的自变量会造成数据的冗余,进而影响积雪深度反演的精度,因此,剔除了相关性高的参数,选择了亮温梯度差tbd(18v-37v)。
29.如图2所示为积雪粒径频率分布图,经过对气象台站对应的积雪粒径参数进行统计,积雪粒径频率分布情况如图2所示。
30.各参数对积雪深度影响的重要性排序如图4所示。
31.可选地,在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量,筛选出的自变量包括:积雪粒径、亮温梯度差tbd(18v-37v)、积雪密度、森林覆盖度、海拔高度、经度。
32.进一步,在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量,进一步包括纬度。
33.s104:根据所述自变量与积雪深度数据构建随机森林模型。
34.可选地,所述构建随机森林模型的方法包括:确定随机森林决策树数量;对于每棵决策树,从所述自变量与积雪深度数据中抽取训练集;基于训练集训练决策树,并综合所有决策树的结果得到随机森林模型。
35.在一些实施例中,在随机森林算法的运行过程中,决策树的数量n一般默认取500棵树。输入变量训练集大小定义为m,那么对于每棵决策树,有放回的从训练数据集中随机抽取n个训练样本,要保证n《《m,作为该决策树的训练集。如果输入变量的个数为k,则决策树的每个节点默认值设置为k/3。软件环境为matlab2016a + windows10 + visual studio 2017,随机森林算法工具箱版本为rf_mexstandalone-v0.02。
36.进一步,所述构建随机森林模型的方法进一步包括:按照以下任意一种输入输出关系建立计算模型,使用模型1~7的任意一种预测积雪深度;模型1:输入自变量为亮温梯度差tbd(18v-37v),输出目标为积雪深度;模型2:输入自变量为tbd(18v-37v) 和积雪粒径,输出目标为积雪深度;模型3:输入自变量为tbd(18v-37v)、积雪粒径和积雪密度,输出目标为积雪深度;模型4:输入自变量为tbd(18v-37v)、积雪粒径、积雪密度和森林覆盖度,输出目标为积雪深度;模型5:输入自变量为tbd(18v-37v)、积雪粒径、积雪密度、森林覆盖度和海拔高度,输出目标为积雪深度;模型6:输入自变量为tbd(18v-37v)、积雪粒径、积雪密度、森林覆盖度、海拔高度和经度,输出目标为积雪深度;模型7:输入变量为tbd(18v-37v)、积雪粒径、积雪密度、森林覆盖度、海拔高度、经度和纬度,输出目标为积雪深度。
37.可选地,对比所述随机森林模型的均方根误差、偏差和相关系数,对模型1~7进行优选。优选模型6:输入自变量为tbd(18v-37v)、积雪粒径、积雪密度、森林覆盖度、海拔高度
和经度,输出目标为积雪深度。
38.在一些实施例中,设置了7个不同的测试模型(模型1至模型7),如表1所示。模型1的训练样本包括亮温梯度差tbd(18v-37v),而后的测试模型根据重要性排序依次加入不同的自变量,用以测试最优的自变量组合。训练数据为气象台站2012-2013年以及2013-2014年的随机抽样70%的数据(包含雪深数据),共计560396个样本数据。
39.表1 基于不同自变量的7个随机森林的测试模型在一些实施例中,对比了7个随机森林模型反演精度,结果如图5所示,验证数据包括剩下的30%的数据以及2014-2015雪季及其之后到2020年的数据样本(包含雪深数据),共计2641869个样本数据,均方根误差(root mean square error,rmse)、偏差(bias)、相关系数(correlation coefficient,r)的验证结果如表2所示。
40.表2 考虑积雪粒径和积雪密度的7个随机森林模型验证精度结果从验证结果可以看到,在仅使用亮温梯度差数据时(模型1),反演的均方根误差为38.47cm,相关性较低,相关系数小于0.1。在引入积雪密度和积雪粒径之后,机器学习算法的反演的精度较高,相关性较好,相关系数约为0.92。
41.对于模型2和模型3,引入了积雪粒径和积雪密度之后,均方根误差rmse约为18.6cm,线性拟合的相关性约为0.83。
42.对于模型4,在加入了森林覆盖度数据之后,均方根误差rmse为15.51cm,精度继续提高了3.1cm,线性拟合的相关性约为0.88。说明,在全球范围内,引入由modis地表分类数据计算得到的森林覆盖度信息可以较为有效的提高森林地区的反演精度。
43.对于模型5,继续增加海拔高度数据,均方根误差rmse为12.95cm,精度继续提高了约2.6cm, 线性拟合的相关性约为0.917。
44.对于模型6,继续增加经度数据,均方根误差rmse为12.75cm,精度继续提高了约
0.2cm, 线性拟合的相关性提高至0.921。
45.对于模型7,继续增加纬度数据,精度反而下降, 均方根误差rmse为14.13cm,线性拟合的相关性下降为0.903。
46.研究结果发现,在加入纬度信息之后,精度反而下降了,这并不能说明雪深对于纬度不敏感,而是纬度信息与经度和海拔的相关性高于纬度信息与积雪深度的相关性,因此再加入纬度信息之后,机器学习算法反而由于自变量之间的数据冗余,降低了算法的精度。这也说明,对于机器学习算法,对于目标输出显著相关的自变量的加入并不一定能提高算法的预测精度,因此需要对冗余变量进行剔除,既可以提高运算效率,又可以提高算法的反演精度。
47.通过实施例1可看出,针对积雪粒径和积雪密度变化对积雪深度反演引起的不确定性问题,通过在反演算法中引入积雪密度数据以及基于辐射传输模型优化反演得到的积雪粒径,以及森林覆盖度、海拔高度和经度,发展了辐射传输模型和机器学习相结合的积雪深度反演算法,提高了算法预测精度。
48.实施例2如图6所示,本技术实施例还提供了一种积雪深度的反演方法,将上述实施例中优选模型6用于预测积雪深度。包括:s601:获取辐射计亮度温度数据、森林覆盖度数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据;s602:将所述辐射计亮度温度数据、森林覆盖度数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据输入到预先训练好的积雪深度预测模型中,获得预测的积雪深度数据;其中,所述积雪深度预测模型为基于上述积雪深度的反演方法所确定的随机森林模型6。
49.在一些实施例中,如图7所示,对比了本技术方法与国际上主流的全球积雪深度遥感和再分析产品的精度。
50.对比的积雪深度数据包括:amsr2遥感产品、globsnow3.0同化数据、ear-interim再分析数据、ear5再分析数据和ear5-land再分析数据。利用2012-2020年11月到翌年4月的气象站点数据(共计3059909个样本)对这6种不同的积雪深度算法和产品进行了比较和验证。针对amsr2辐射计的亮温数据,美国宇航局nasa使用经验算法得到积雪深度,这种产品称作积雪深度amsr2遥感产品。globsnow3.0由于只覆盖了北纬地区35度到85度间的范围,并且掩膜掉了山区,并且数据只更新到了2018年4月份,此外,需要剔除掉其产品本身同化的气象站点,最后验证的数据共计1676747个样本;era-interim的产品数据更新截止到2019年,其验证的数据共计2707665个样本。各产品精度比较的结果如图7所示,精度指标结果如表3所示。
51.表3 随机森林反演方法与其他全球雪深数据的比较精度结果
从结果可以看出,整体上本技术发展的反演算法的精度结果最好,其均方根误差rmse为12.75cm,平均偏差分别为-1.66cm,总的相关系数r为0.92。算法整体表现显著优于国际上的其他积雪深度数据集。而amsr2遥感产品整体上呈现出明显的低估现象,总的均方根误差为36.23cm,相关系数仅为0.21; globsnow3.0同化数据整体上也是低估,总的均方根误差为25.31cm,相关系数仅为0.53,由于其优化了积雪粒径并且同化了气象站点数据,其精度要高于amsr2产品;再分析数据era-interim和era5表现类似,整体呈现非常严重的低估现象,总的均方根误差分别为42.34cm和38.22cm,平均偏差分别为-25.29cm和-23.24cm, 相关系数分别为0.08和0.48;再分析数据era5-land产品出现一定的高估现象,总的均方根误差为29.87cm,平均偏差为5.95cm,相关系数为0.64。
52.需要说明的是,实施例1、实施例2所提供方法的各步骤的执行主体均可以是同一设备,或者,该方法也由不同设备作为执行主体。比如,步骤s101和步骤s102的执行主体可以为设备1,步骤s103和步骤s104的执行主体可以为设备2;又比如,步骤s101的执行主体可以为设备1,步骤s102、步骤s103和步骤104的执行主体可以为设备2;等等。
53.实施例3如图8所示,本技术实施例还提供了一种基于随机森林模型的积雪深度反演装置,包括:数据获取单元810,用于获取积雪深度相关数据,并预处理;其中,所述积雪深度相关数据包括辐射计亮度温度数据、森林覆盖度数据、气象台站雪深数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据;积雪粒径计算单元820,用于接收所述数据获取单元810中所述积雪深度相关数据,并在一定范围内反演积雪粒径;模型训练单元830,用于接收数据获取单元810中的积雪深度相关数据,以及积雪粒径计算单元820输出的积雪粒径,从中筛选随机森林算法的自变量;根据所述自变量与积雪深度数据构建随机森林模型。
54.本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
55.因此,本技术还提出一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本技术中任一实施例所述的方法。
56.进一步地,本技术还提出一种电子设备,包括存储器,处理器及存储在存储器上并可在处理器运行的计算机程序,所述处理器执行所述计算机程序时实现如本技术任一实施例所述的方法。
57.实施例4本技术实施例提供了一种电子设备。
58.图9是本技术实施例提供的一种电子设备的结构示意图。如图9所示,本实施例提供了一种电子设备900,其包括:一个或多个处理器920;存储装置910,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器920运行,使得所述一个或多个处理器920实现本技术实施例所提供的积雪深度的反演方法,该方法包括:获取积雪深度相关数据,并预处理;其中,所述积雪深度相关数据包括辐射计亮度温度数据、森林覆盖度数据、气象台站雪深数据、海拔高度数据、经纬度数据、积雪密度数据、地表2m空气温度数据、大气可降水数据、积雪温度数据和0-7cm土壤温度数据;根据所述积雪深度相关数据在一定范围内反演积雪粒径;在积雪深度相关数据和积雪粒径中筛选随机森林算法的自变量;根据所述自变量与积雪深度数据构建随机森林模型。
59.图9显示的电子设备900仅仅是一个示例,不应对本技术实施例的功能和使用范围带来任何限制。
60.如图9所示,该电子设备900包括处理器920、存储装置910、输入装置930和输出装置940;电子设备中处理器920的数量可以是一个或多个,图9中以一个处理器920为例;电子设备中的处理器920、存储装置910、输入装置930和输出装置940可以通过总线或其他方式连接,图9中以通过总线950连接为例。
61.存储装置910作为一种计算机可读存储介质,可用于存储软件程序、计算机可运行程序以及模块单元,如本技术实施例中的积雪深度的反演方法对应的程序指令。
62.存储装置910可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序;存储数据区可存储根据终端的使用所创建的数据等。此外,存储装置910可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实例中,存储装置910可进一步包括相对于处理器920远程设置的存储器,这些远程存储器可以通过网络连接。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
63.输入装置930可用于接收输入的数字、字符信息或语音信息,以及产生与电子设备的用户设置以及功能控制有关的键信号输入。输出装置940可包括显示屏、扬声器等电子设备。
64.本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实
现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
65.这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
66.这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
67.在一个典型的配置中,计算设备包括一个或多个处理器 (cpu)、输入/输出接口、网络接口和内存。内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器 (ram) 和/或非易失性内存等形式,如只读存储器 (rom) 或闪存(flash ram)。内存是计算机可读介质的示例。
68.还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
69.以上所述仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1