基于岩石参数和测井数据驱动的相渗曲线预测方法与流程
本发明涉及油田开发数据挖掘,特别是涉及到一种基于岩石参数和测井数据驱动的相渗曲线预测方法。
背景技术:
1、相对渗透率曲线简称相渗曲线,是开展新老区综合研究工作不可或缺的资料。它能够综合反映流体在多孔介质中的流动规律,对于油藏开发方案设计、数值模拟、储集层剩余油评价、水淹层级别划分以及油田动态分析研究具有不可替代的作用。主力老油田经过几十年的开采,逐步进入高含水后期、特高含水期,准确认识储层流体分布状况,刻画剩余油的分布规律,是高含水油田进行调整挖潜、提高注水采收率的基础和关键。
2、目前获取油水相渗曲线的主要途径是室内实验,但是由于取芯资料有限,实验费用昂贵,相渗曲线非常有限。以至数值模拟研究中,往往采用一条区块平均油水相对渗透率曲线,或根据流体特征分区采用多条平均油水相对渗透率曲线,甚至借用其它区块的相渗曲线。实际油藏由于注入水的不断冲刷,储层微观结构等发生很大变化,油藏非均质性日益严重,不同区域渗流特性存在较大差异,难以利用一条或多条平均油水相对渗透率曲线来模拟区域大、非均质性强的实际油藏渗流特征,也无法精确描述剩余油分布状况,这是造成目前数值模拟结果与矿场认识存在差异的主要原因之一。因此,针对没有开展相渗实验的井,在精度满足工程应用需求的前提下,以更低廉更高效的技术获取相对渗透率曲线资料,具有紧迫的现实意义。
3、在申请号:cn201810505945.7的中国专利申请中,涉及到一种油藏相渗曲线模型及相渗曲线计算方法,包括一种油藏相渗曲线模型和油藏相渗曲线计算方法。模型包括gml模型和gbl模型,模型获取方法依次包括以下步骤:(1)将实验测试所得相渗曲线和gml模型、gbl模型进行拟合,得到多组β、γ和m的参数值。(2)确定模型中各参数的平均值。将步骤1拟合得到的多组β、γ等参数值求取平均值,得到通用模型参数,将通用模型参数代入模型中,得到通用模型并验证通用模型的拟合度。(3)获取油藏相渗曲线模型。将步骤2得到的β、γ等参数的通用模型参数值代入gml模型和gbl模型中,计算得到油藏相渗曲线模型。(4)根据步骤(3)所得通用模型计算得到油藏相渗曲线。
4、在申请号:cn202111400726.0的中国专利申请中,涉及到一种基于机器学习的相渗曲线预测方法及系统,通过以测井曲线数据作为输入,将含水饱和度的端点值作为输出,建立第一相渗曲线起始点模型;以测井曲线数据和第一相渗曲线起始点模型输出的预测含水饱和度起始值作为输入,以不同含水饱和度下的相对渗透率为输出,建立第一相对渗透率模型,最终获得相渗曲线深度学习分析综合预测方法,从而将控制机制和参数隐含到模型中,无需建立相对渗透率数学模型、模拟非线性控制机制,提高了获取相渗曲线的效率,降低了相渗曲线预测成本,提高了预测精度,并为人工智能应用于反演和成像问题提供可行性验证和技术支撑,从而作为相对渗透率预测的有效工具。
5、在申请号:cn202010552061.4的中国专利申请中,涉及到一种基于机器学习算法实现相渗曲线仿真预测的新方法。所述方法包括:储层相渗影响因素初步确定;原始数据的融合预处理;筛选、组合储层相渗仿真主要影响因素,确定特征集合;基于预处理数据集,建立独立的训练集和验证集;确定预测算法;生成每一个含水饱和度条件下储层相渗曲线预测模型,校验,汇总,即得。该发明实现油田每口井目标井段渗曲线的实时生成,使其成为获取储层相渗这一物性数据的必备路径。实现储层渗透性变化预测,准确反映储层现状。推广应用于油藏工程和油藏数值模拟的研究中,有效提升地质研究精度和效率。
6、以上现有技术均与本发明有较大区别,未能解决我们想要解决的技术问题,为此我们发明了一种新的基于岩石参数和测井数据驱动的相渗曲线预测方法。
技术实现思路
1、本发明的目的是提供一种通过岩石参数或测井曲线预测相渗曲线,实现无相渗实验测量条件下,准确高效的获取相渗曲线数据的基于岩石参数和测井数据驱动的相渗曲线预测方法。
2、本发明的目的可通过如下技术措施来实现:基于岩石参数和测井数据驱动的相渗曲线预测方法,该基于岩石参数和测井数据驱动的相渗曲线预测方法包括:
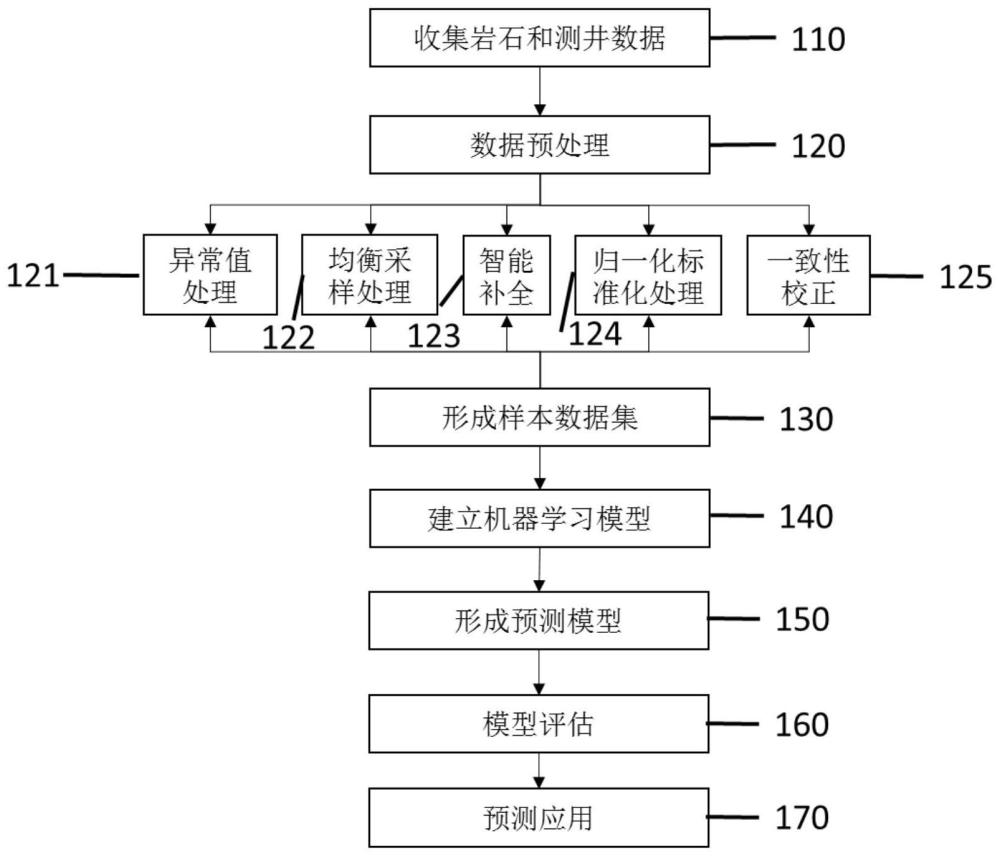
3、步骤1、收集岩石和测井数据;
4、步骤2、进行数据预处理;
5、步骤3、建立样本数据集;
6、步骤4、建立机器学习模型,对样本进行训练;
7、步骤5,形成预测模型,并对模型进行评估。
8、本发明的目的还可通过如下技术措施来实现:
9、在步骤1中,岩石参数包括空气渗透率,孔隙度这些常规的岩石参数数据;测井数据包括测井曲线井径(cal)、密度(den)、声波时差(ac)、电阻率(r25)、自然电位(sp)、感应电导率(cond)、伽马(gr)。
10、步骤2包括:
11、步骤21,进行岩石样本特征异常值及离群值检查及处理;
12、步骤22,进行岩石样本特征的不平衡数据检查及处理;
13、步骤23,将测井曲线进行智能补全;
14、步骤24,进行岩石样本特征的标准化、归一化处理;
15、步骤25,进行测井曲线一致性校正。
16、在步骤21中,采用聚类和异常值点检测方法进行特征异常值检查。
17、在步骤21中,采用聚类进行特征异常值检查时,用kmeans(k均值)聚类将训练样本分成若干个簇,如果某一个簇里的样本数很少,而且簇质心和其他所有的簇都很远,那么这个簇里面的样本极有可能是异常特征样本了,这样在后续使用中可以将其从训练集过滤掉。
18、在步骤21中,采用异常值点检测方法进行特征异常值检查时,使用iforest(孤立森林异常检测算法)或者one class svm(单分类支持向量机异常检测算法),使用异常点检测的机器学习算法来过滤所有的异常点。
19、在步骤22中,采用权重法和采样法对岩石样本特征的不平衡数据进行检查及处理。
20、在步骤22中,采用权重法对岩石样本特征的不平衡数据进行检查及处理时,对训练集里的每个类别加一个分类权重;如果该类别的样本数多,那么它的权重就低,反之则权重就高;如果需要更精细,则对每个样本加样本权重,思路和类别权重也是一样,即样本数多的类别样本权重低,反之样本权重高。
21、在步骤22中,采用采样法对岩石样本特征的不平衡数据进行检查及处理时,有两种思路,一种是对类别样本数多的样本做子采样,第二种思路是对类别样本数少的样本做过采样。
22、在步骤23中,通过相关性分析优选目标测井曲线的影响因素,将目标曲线数据与影响因素建立训练样本,采用xgboost(极限梯度提升)机器学习算法建立预测模型,对目标测井曲线进行智能预测补全。
23、在步骤24中,采用最大-最小标准化法和z-score(标准分数)标准化法进行岩石样本特征的标准化、归一化处理。
24、在步骤25中,采用频次直方图法进行测井曲线一致性校正,业务专家选定一个标准层,按照测井值范围划分合适的区间个数,统计所有井该层段的测井数据落在每个区间上的数据点个数,每口井落在哪个区间上最多,区间标准值井数加1,最终标准值井数最多的即为标准范围区间,以该区间平均值为标准值,其它井的数据进行偏移调整。
25、在步骤3中,按照深度对应,建立岩石参数与相渗曲线,岩石加测井数据与相渗曲线的对应关系,形成样本数据集。
26、在步骤4中,分别采用常规人工神经网络、随机森林、adaboost(自适应)、gbdt(梯度提升决策树)、xgboost(极限梯度提升)这些机器学习方法,对样本进行训练。
27、在步骤5中,采用均方误差作为目标优化值,经过反复的参数调优,形成预测模型。
28、在步骤5中,用测试集进行计算,绘制同一口井不同机器学习算法预测的相渗曲线,同时形成mse(均方误差)对比分析表,评价不同机器学习算法的精度。
29、本发明中的基于岩石参数和测井数据驱动的相渗曲线预测方法,借助大数据和数据挖掘技术,通过岩石参数或测井曲线预测相渗曲线,实现无相渗实验测量条件下,准确高效的获取相渗曲线数据。该基于岩石参数和测井数据驱动的相渗曲线预测方法分析不同岩石参数、测井曲线对相渗曲线的敏感性,优选相关性强的特征参数,以已有室内实验的相渗曲线数据为标签,进行数据融合,形成样本数据集;经过标准化、归一化校正,测井曲线补全等数据处理后,形成训练样本;选取多种不同的机器学习算法建立岩石参数与相渗曲线、岩石加测井数据与相渗曲线的预测模型。经比较评估,xgboost算法模型效果最优,精度达到90%以上,能够满足生产应用需求。
30、本发明能够基于测井快速预测所有井层的相渗曲线,由于油田测井曲线基本达到了全覆盖,而相渗曲线实验花费大,相渗实验井占比不到5%。一方面很多油田区块没有相渗曲线,往往借用邻井和相似区块的相渗曲线;另一方面即使研究区块有相渗也只有少数几口井,难以满足精细地质建模的需求。本发明技术成果有效解决了相渗曲线少,油藏模型精细化程度不够,研究精细低的问题。油藏模型精度提高了,开发方案和措施调整更有针对性,必将提高方案产能,创造大量经济效益。
31、相对于传统的经验公式计算相渗曲线,该成果充分利用所有实验数据,发挥大数据的优势,预测精度更高,方法适应性更广。
- 还没有人留言评论。精彩留言会获得点赞!