一种基于目标检测分组残差结构进行特征提取的方法
1.本发明属于目标检测技术领域,具体涉及一种基于目标检测分组残差结构进行特征提取的方法。
背景技术:
2.在深度学习的发展背景下,卷积神经网络已经得到越来越多的人认同,应用也越来越普遍。基于深度学习的目标检测算法利用卷积神经网络(cnn)自动选取特征,然后再将特征输入到检测器中对目标分类和定位。
3.在目标检测任务中,主干网络位于整个网络的前端,用于提取目标的不同尺度特征。早期基于卷积神经网络的物体检测模型大多使用vgg网络作为骨干网络,通过反复堆叠卷积层和池化层来提高特征提取和语义表达能力。但其层数仅为19层,提取的特征表达能力有限。如果通过堆叠加深网络层数,很容易导致梯度消失或爆炸,从而降低网络的性能。为了解决这个问题,he等人提出了一个跳跃连接残差(resnet50)网络,它将浅层特征信息与后续层相结合,以产生新特征并将其反馈回来。此外,在单阶段目标检测网络yolo v3中,提出了darknet骨干网络结构,该结构结合resnet50的特点,在保证特征超强表达的同时,避免了网络过深带来的梯度问题。
4.resnet50网络是通过堆叠残差单元形成的。在训练过程中,随着网络深度的增加,梯度消失、梯度爆炸、准确率下降等问题会陆续出现,使用残差结构可以有效地解决这些问题。然而,随着网络深度的增加,模型计算量随之增加,卷积核的通道信息也经常未被充分利用。为了提高骨干网络充分提取通道特征信息的能力,本发明提出一种分组残差结构g-resnet50,用于替换初始残差结构,形成骨干增强网络。
技术实现要素:
5.本发明针对现有技术的不足,提供一种基于目标检测分组残差结构进行特征提取的方法,包括以下步骤:
6.步骤1,准备图像数据集用于测试和训练;
7.步骤2,构建基于目标检测分组残差结构的特征提取网络;
8.步骤3,使用训练集图像对基于目标检测分组残差结构的特征提取网络模型进行训练;
9.步骤4,使用步骤3训练好的网络模型对测试集图像进行特征提取。
10.而且,所述步骤1中将所有图像的尺寸调整到512
×
512大小进行多尺度训练,采用数据增强对图像数据集进行一系列操作:随机翻转、padding填充、随机裁剪,归一化处理,图像失真处理。
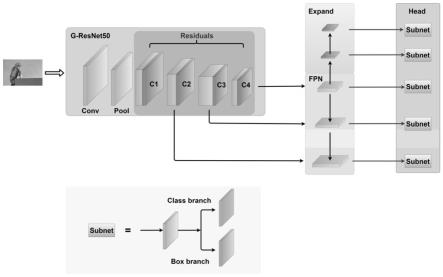
11.而且,所述步骤2中基于目标检测分组残差结构的特征提取网络由backbone、neck和head三部分构成,backbone采用的是本发明提出的g-resnet50骨干网络,用于提取图片的特征,neck结构用于连接backbone和head,用于融合特征,head部分用于物体的检测,实
现目标的分类和回归。
12.特征信息经过g-resnet50骨干网络的卷积和最大池化层后,进入由resnet50原始残差和改进后的新残差构成的残差网络。resnet50骨干网络的分组残差结构new residual将1
×
1卷积后的卷积层分为四个通道组x1、x2、x3、x4,每组的宽、高相同,通道数为输入特征图的1/4,通过分组卷积,x1、x2、x3、x4生成y1、y2、y3、y4。此外,x1和x4的特征信息分别与x2和x3交错生成y2和y3。将两个通道得到的y2、y3通过拼接(concat)进行合并,然后把y1、y2、y3、y4的特征信息通过拼接融合后经过一个1
×
1的卷积进行参数缩减。为了结合残差网络前后的特征信息,令x1和x4经过3
×
3卷积增加通道维数,再与1
×
1卷积后的特征融合,以提高残差网络的特征提取能力。融合后的特征信息经过一个3
×
3深度可分离卷积后与直接输入的特征相加得到最终的特征。
13.neck结构采用了backbone的三个特征图[c2,c3,c4],经过1
×
1卷积后通道都降为256,经过fpn结构进行特征融合,然后fpn经过了两次下采样得到expand结构,最后采用3
×
3卷积对特征图进行处理,输出5个不同尺寸的特征图,步距为[8,16,32,64,128],通道大小都为256。
[0014]
而且,所述步骤3中训练集图像大小统一为512
×
512,学习率设置为0.001,batch_size大小设置为4,训练次数为12个epoch,并在第8个和第11个epoch时,将学习率降为原来的1/10。
[0015]
与现有技术相比,本发明具有如下优点:
[0016]
对resnet50骨干网络进行改进,引入了分组卷积块,对不同组别之间的特征信息进行融合,提高了特征提取的质量,同时深度可分离卷积的引入较好地控制了参数量。
附图说明
[0017]
图1为发明实施例网络总体结构示意图。
[0018]
图2为发明实施例resnet50及其残差结构示意图。
[0019]
图3为发明实施例g-resnet50及其残差结构示意图。
[0020]
图4发明实施例整体网络检测效果示意图。
具体实施方式
[0021]
本发明提供一种基于目标检测分组残差结构进行特征提取的方法,下面结合附图和实施例对本发明的技术方案作进一步说明。
[0022]
本发明实施例的流程包括以下步骤:
[0023]
步骤1,准备图像数据集用于测试和训练。
[0024]
选用coco 2017数据集,它是一个大型的、丰富的物体检测、分割和字幕数据集,包含80个用于检测的类别,分别为“人”,“自行车”,“汽车”,“摩托车”,“飞机”,“公共汽车”,“火车”,“卡车”,“船”,“交通信号灯”等日常生活中常见个体,包含annotations、test2017、train2017、val2017四个文件,其中train包含118287张图像,val包含5000张图像,test包含28660张图像,annotations为标注类型的集合:object instances,object keypoints和image captions,使用json文件存储。
[0025]
将所有图像的尺寸调整到512
×
512大小进行多尺度训练,采用数据增强对图像数
据集进行一系列操作:随机翻转、padding填充、随机裁剪,归一化处理,图像失真处理。
[0026]
步骤2,构建基于目标检测分组残差结构的特征提取网络。
[0027]
如图1所示,基于目标检测分组残差结构的特征提取网络由backbone、neck和head三部分构成。backbone采用的是本发明提出的g-resnet50骨干网络,用于提取图片的特征,g-resnet50骨干网络输出3个不同尺寸的特征图[c2,c3,c4],步距为[4,8,16],通道大小为[256,512,1024]。图2显示了resnet50的整体结构,特征信息经过卷积和最大池化层后,进入原始残差构成的残差网络。图3即为本发明对resnet50改进后的g-resnet50网络结构,由图中可以看出,特征信息经过卷积和最大池化层后,进入由resnet50原始残差和改进后的新残差构成的残差网络。为了减少模型参数的数量和执行时间,只嵌入四个新残差网络。g-resnet50骨干网络的分组残差结构new residual将1
×
1卷积后的卷积层分为四个通道组,分别用x1、x2、x3、x4表示,每组的宽、高相同,通道数为输入特征图的1/4。通过分组卷积,由x1、x2、x3、x4生成y1、y2、y3、y4。此外,x1和x4的特征信息分别与x2和x3交错生成y2和y3。将两个通道得到的y2、y3通过拼接(concat)进行合并,通过将多个特征通道的特征信息连接在同一个卷积层中,可以融合多个特征通道的特征信息,大大提高通道特征信息的利用率。y1~y4的特征信息通过拼接融合后经过一个1
×
1的卷积进行参数缩减。为了结合残差网络前后的特征信息,令x1和x4经过3
×
3卷积增加通道维数,再与1
×
1卷积后的特征融合,以提高残差网络的特征提取能力。融合后的特征信息经过一个3
×
3深度可分离卷积后与直接输入的特征相加得到最终的特征。深度可分离卷积是先进行深度卷积,然后进行点卷积,与传统的卷积运算相比,它的参数量和运算成本更低。
[0028]
neck结构用于连接backbone和head,用于融合特征。该结构采用了backbone的三个特征图[c2,c3,c4],经过1
×
1卷积后通道都降为256,经过fpn结构进行特征融合,然后fpn经过了两次下采样得到expand结构,最后采用3
×
3卷积对特征图进行处理,输出5个不同尺寸的特征图,步距为[8,16,32,64,128],通道大小都为256。
[0029]
head部分用于物体的检测,实现目标的分类和回归。
[0030]
步骤3,使用训练集图像对基于目标检测分组残差结构的特征提取网络模型进行训练。
[0031]
训练集图像大小统一为512
×
512,学习率设置为0.001,batch_size大小设置为4,训练次数为12个epoch,并在第8个和第11个epoch时,将学习率降为原来的1/10。
[0032]
步骤4,使用步骤3训练好的网络模型对测试集图像进行特征提取。
[0033]
实验环境:搭建以pytorch1.6、torchvision=0.7.0、cuda10.0、cudnn7.4为深度学习框架的python编译环境,并在平台mmdetection2.6上实现。
[0034]
实验设备:cpu:intel xeon e5-2683 v3@2.00ghz;ram:16gb;graphics card:nvidia gtx 2060super;hard disk:500gb。
[0035]
为了测试g-resnet50结构对检测物体精度的影响,在多个网络上进行了对比实验。实验的评价标准采用平均精度(average-precision,ap),选用ap
50
、ap
75
、aps、apm、ap
l
作为主要评价标准,其中ap
50
,ap
75
指的是取iou阈值大于0.5和大于0.75的检测器的检测结果。aps、apm、ap
l
分别对应小、中、大型目标的检测准确度。实验结果如表1所示。
[0036]
表1 g-resnet50对不同网络的效果
[0037][0038]
表1显示了coco数据集的实验结果。coco数据集的图片数量巨大,种类繁多,大大增加了物体检测的难度。为了让实验更有说服力,选择fcos、atss、foveabox和mgrnet作为对比网络。coco数据集的评价指标为ap、ap
50
、ap
75
、aps、apm、ap
l
。
[0039]
由表1可知,atss的改善效果最为明显,ap增加0.9%,特别是ap
l
增加1.9%。对于fcos,整体提升了0.7个百分点,取得了不错的效果。foveabox的效果较差,增加了0.3个百分点,这与foveabox的正负样本训练策略和损失函数的选择有关。mgrnet的增长并不是特别明显,g-resnet50结构的改进作用有限。然而,在如此高ap的检测网络上,本发明的改进方法仍然有效,充分证明了g-resnet50的有效性。
[0040]
选择一些测试图片来测试最终结果。从图4可以看出,本发明提出的目标检测网络取得了很好的效果。第三张图片中仅有一个物体时,网络可以准确地检测到该物体。其它图片中有多个物体时,也能达到很好的检测效果。对于第一张和第二张图片,当部分物体被遮挡时,仍能准确识别类别。此外,对于小物体和模糊图像,比如第七张图片中的人,第八张图片中车内的人,本发明提出的检测网络也能很好地完成检测任务。但是由于数据集类型有限,难免也会出现一些检测错误,比如第六张图片中的圆形野营帐篷被检测为雨伞。由图4不难看出,本发明提出的网络精准地完成了目标检测的任务,在边缘具有出色的识别效果。
[0041]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1