一种基于OCR引擎的智能审单方法及系统与流程
一种基于ocr引擎的智能审单方法及系统
技术领域
1.本发明涉及信息审核技术领域,特别是涉及一种基于ocr引擎的智能审单方法及系统。
背景技术:
2.金融领域里,金单业务和供票业务运营及风险岗位人员在审核贸易背景资料合同时,仅能通过人工肉眼查看影像件,而由于合同内容种类繁多而且内容冗长,审核耗时较长也较容易出现错漏。为此,现有技术公开了一种基于规则引擎和ocr的报账及审核自动化方法,该方法通过引入ocr识别技术,可以快速识别出各类票据信息,并将识别的信息存储至数据库中,再利用预先在规则引擎中配置的校验规则匹配识别的信息,进行自动填写电子单据信息,其虽然可以有效提高单据的审核审核效率和质量,但当同一份材料对应多张图片/pdf时,该方法的识别效率很差,且其仅能针对预设的规则进行固定格式文件的识别,不适用于合同等非固定格式文件。
技术实现要素:
3.本发明为了解决以上至少一种技术缺陷,提供一种基于ocr引擎的智能审单方法及系统,在实现多个图片/pdf的自动合并提高审核效率的同时,实现了对合同印章的识别,适用于合同等非固定格式文件的识别。
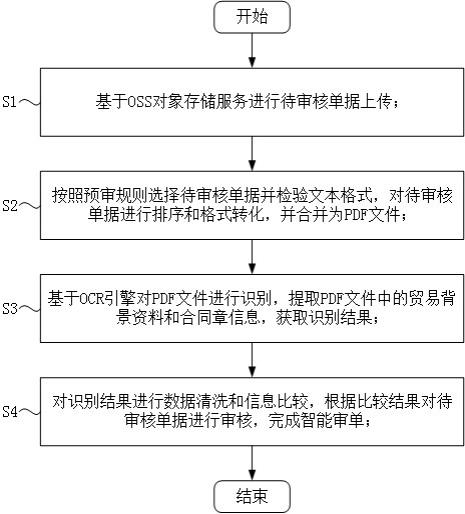
4.为解决上述技术问题,本发明的技术方案如下:一种基于ocr引擎的智能审单方法,包括以下步骤:s1:基于oss对象存储服务进行待审核单据上传;s2:按照预审规则选择待审核单据并检验文本格式,对待审核单据进行排序和格式转化,并合并为pdf文件;s3:基于ocr引擎对pdf文件进行识别,提取pdf文件中的贸易背景资料和合同章内容对应的文本,获取识别结果;s4:对识别结果进行数据清洗和信息比较,根据比较结果对待审核单据进行审核,完成智能审单。
5.上述方案中,oss对象存储服务(object storage service-对象存储服务)作为待审核单据对象存储中心,分离了待审核单据得上传逻辑。待审核单据在对象存储服务中均采用fileid作为命名,其信息存储在文件服务中。将待审核单据上传到oss,则无需通过后端服务,前后端访问文件均可以直接对接oss对象存储服务,大大降低了后端应用服务器的带宽压力。
6.上述方案中,通过pdf合并技术将图片/pdf格式的待审核单据进行自动合并,令整个审单过程无需逐个单据进行审核,可有效提高审核效率;同时,本方案能够将贸易背景资料及合同章内容对应的文本进行识别和提取,实现了对合同印章的识别,适用于合同等非固定格式文件的识别。
7.其中,在所述s2中,所述预审规则为先过滤出待审核单据中带有排序标识的字符,然后对字符转义为数字并根据数字对待审核单据进行排序;所述格式转化过程为:将webp格式文件采用流处理方式转换为png格式并对分辨率进行适应性调整。
8.上述方案中,在需要合并pdf文件时,先按fileid列表把待审核单据逐一下载,遇到webp格式的文件自动采用流处理方式转换为png格式,对于分辨率较大或者较小的图片,会自动压缩或调整分辨率,使调整后的图片更符合后续ocr识别及人工检测的视觉效果;然后采用把图片写入到pdf文件context中的方式将图片合并为pdf文件。由于采用oss存储待审核单据及提供加速下载服务,使得整体文件合并效率非常高,操作响应快,用户体验较好。
9.其中,在所述s3中,ocr引擎使用ctpn算法模型提取出pdf文件中的文本内容,再利用nlp技术对文本内容进行解析,得到贸易背景资料;所述ctpn算法模型包括vgg16网络层、滑动卷积层、循环层、lstm网络层、softmax层和文本生成器;其中,提取出pdf文件中的文本内容的具体过程为:s3a1:读取pdf文件内容并对每一页内容进行拆分,得到多份单页内容;s3a2:将单页内容依次输入vgg16网络层中进行特征提取,生成多份单页内容的特征图;s3a3:利用滑动卷积层对特征图进行多次滑动卷积操作,获取多个特征向量,生成新的特征图;s3a4:利用循环层对新的特征图进行重塑处理,将新的特征图重塑为lstm网络层能够处理的大小,得到重塑特征图;s3a5:利用lstm网络层对重塑特征图进行卷积处理并配置锚点,获取文本位置;s3a6:在softmax层中判断文本位置中是否包含文本,对文本所在的文本位置进行中心坐标修正和高度修正,生成修正结果;s3a7:利用修正结果,由文本生成器将中心坐标、高度相近的文本位置进行合并,构造成为一个文本行;再将多个文本行进行合并,得到pdf文件的文本内容。
10.其中,在所述s3中,所述nlp技术包括look-up层、bilstm层、crf层和filtrate层;利用nlp技术对文本内容进行解析,得到贸易背景资料的过程具体为:s3b1:利用look-up层将文本内容中的每一个单词映射为一个词向量,得到多个词向量;s3b2:bilstm层通过学习文本内容中上下文的信息,输出每个词向量对应于每个标签的得分概率;s3b3:将bilstm层的输出作为crf层的输入,通过学习标签之间的顺序依赖信息,得到每个词向量预测的序列标注;s3b4:利用filtrate层对每个词向量预测的序列标注进行处理,将无效标注进行过滤,并将有效标注归并到一个结果集输出,即得到贸易背景资料。
11.上述方案中,所述词向量对应于每个标签是根据实际需要进行预先设置的,而crf层可以有效学习到标签之间的顺序依赖信息,形成每个词向量预测的序列标注。
12.其中,在所述s3中,ocr引擎提取pdf文件中的合同章内容对应的文本过程具体为:s3c1:对s3a1中得到的多份单页内容分别进行印章识别,得到包含印章的单页内
容;s3c2:基于三阶贝塞尔曲线算法对包含印章的单页内容进行处理,剪裁处印章中环形文字区块;s3c3:将环形文字区块中的所有曲形文本拉直成水平文本行图片;s3c4:利用卷积层对水平文本行图片进行图像特征提取,得到图像特征;s3c5:通过循环层对图像特征进行序列建模,对图像特征的特征表征进行改善;s3c6:将特征表征改善后的图像特征进行线性分类,通过ctc解码获得最终的识别结果,得到合同章内容对应的文本。
13.上述方案中,可以将贸易背景资料进行提取并进行审核,对明显不符合规定的贸易背景资料进行提示,加快审批效率;在识别到贸易背景资料后,自动将其中的关键信息高亮加粗显示,方便审核人员快速定位找到有效信息,并根据审核清单逐项自动做出判断,有效避免人工审核出现遗漏,提升审核效率以提升工作人员的审核效率。
14.本方案还提出一种基于ocr引擎的智能审单系统,包括金单前端单元、单据合并单元、ocr合同识别服务单元、智能审单单元;其中:所述金单前端单元基于oss对象存储服务将待审核单据进行上传;所述单据合并单元用于按照预审规则选择待审核单据并检验文本格式,对待审核单据进行排序和格式转化,并合并为pdf文件;所述ocr合同识别服务单元基于ocr引擎对pdf文件进行识别,提取pdf文件中的贸易背景资料和合同章内容对应的文本,获取识别结果;所述智能审单单元对识别结果进行数据清洗和信息比较,根据比较结果对待审核单据进行审核,完成智能审单。
15.其中,在所述单据合并单元中,所述预审规则为先过滤出待审核单据中带有排序标识的字符,然后对字符转义为数字并根据数字对待审核单据进行排序;所述格式转化过程为:将webp格式文件采用流处理方式转换为png格式并对分辨率进行适应性调整。
16.其中,在所述ocr合同识别服务单元中内置有ocr引擎,ocr引擎使用ctpn算法模型提取出pdf文件中的文本内容,再利用nlp技术对文本内容进行解析,得到贸易背景资料;所述ctpn算法模型包括vgg16网络层、滑动卷积层、循环层、lstm网络层、softmax层和文本生成器;其中,所述ocr合同识别服务单元提取出pdf文件中的文本内容的具体过程为:s3a1:读取pdf文件内容并对每一页内容进行拆分,得到多份单页内容;s3a2:将单页内容依次输入vgg16网络层中进行特征提取,生成多份单页内容的特征图;s3a3:利用滑动卷积层对特征图进行多次滑动卷积操作,获取多个特征向量,生成新的特征图;s3a4:利用循环层对新的特征图进行重塑处理,将新的特征图重塑为lstm网络层能够处理的大小,得到重塑特征图;s3a5:利用lstm网络层对重塑特征图进行卷积处理并配置锚点,获取文本位置;s3a6:在softmax层中判断文本位置中是否包含文本,对文本所在的文本位置进行中心坐标修正和高度修正,生成修正结果;s3a7:利用修正结果,由文本生成器将中心坐标、高度相近的文本位置进行合并,
构造成为一个文本行;再将多个文本行进行合并,得到pdf文件的文本内容。
17.其中,在所述ocr合同识别服务单元中,所述nlp技术包括look-up层、bilstm层、crf层和filtrate层;利用nlp技术对文本内容进行解析,得到贸易背景资料的过程具体为:s3b1:利用look-up层将文本内容中的每一个单词映射为一个词向量,得到多个词向量;s3b2:bilstm层通过学习文本内容中上下文的信息,输出每个词向量对应于每个标签的得分概率;s3b3:将bilstm层的输出作为crf层的输入,通过学习标签之间的顺序依赖信息,得到每个词向量预测的序列标注;s3b4:利用filtrate层对每个词向量预测的序列标注进行处理,将无效标注进行过滤,并将有效标注归并到一个结果集输出,即得到贸易背景资料。
18.其中,在所述ocr合同识别服务单元中,ocr引擎提取pdf文件中的合同章内容对应的文本过程具体为:s3c1:对s3a1中得到的多份单页内容分别进行印章识别,得到包含印章的单页内容;s3c2:基于三阶贝塞尔曲线算法对包含印章的单页内容进行处理,剪裁处印章中环形文字区块;s3c3:将环形文字区块中的所有曲形文本拉直成水平文本行图片;s3c4:利用卷积层对水平文本行图片进行图像特征提取,得到图像特征;s3c5:通过循环层对图像特征进行序列建模,对图像特征的特征表征进行改善;s3c6:将特征表征改善后的图像特征进行线性分类,通过ctc解码获得最终的识别结果,得到合同章内容对应的文本。
19.与现有技术相比,本发明技术方案的有益效果是:本发明提出了一种基于ocr引擎的智能审单方法及系统,通过pdf合并技术将图片/pdf格式的待审核单据进行自动合并,令整个审单过程无需逐个单据进行审核,可有效提高审核效率;本方案能够将贸易背景资料及合同章内容对应的文本进行识别和提取,实现了对合同印章的识别,适用于合同等非固定格式文件的识别。
附图说明
20.图1为本发明所述的一种基于ocr引擎的智能审单方法的流程示意图;图2为本发明所述的一种基于ocr引擎的智能审单系统的内部连接示意图;图3为本发明一实施例中所述的文件上传流程图;图4为本发明一实施例中所述的基于ocr引擎对pdf文件进行识别的流程图;图5为本发明一实施例中所述的ocr识别任务调动流程示意图;图6为本发明一实施例中所述的资源子流程示意图;图7为本发明一实施例中所述的每个资源获取处理用时的流程示意图。
具体实施方式
21.附图仅用于示例性说明,不能理解为对本专利的限制;
本实施例为完整的使用示例,内容较丰富为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
22.下面结合附图和实施例对本发明的技术方案做进一步的说明。
23.实施例1如图1所示,一种基于ocr引擎的智能审单方法,包括以下步骤:s1:基于oss对象存储服务进行待审核单据上传;s2:按照预审规则选择待审核单据并检验文本格式,对待审核单据进行排序和格式转化,并合并为pdf文件;s3:基于ocr引擎对pdf文件进行识别,提取pdf文件中的贸易背景资料和合同章内容对应的文本,获取识别结果;s4:对识别结果进行数据清洗和信息比较,根据比较结果对待审核单据进行审核,完成智能审单。
24.在具体实施过程中,oss对象存储服务作为待审核单据对象存储中心,分离了待审核单据得上传逻辑。待审核单据在对象存储服务中均采用fileid作为命名,其信息存储在文件服务中。将待审核单据上传到oss,则无需通过后端服务,前后端访问文件均可以直接对接oss对象存储服务,大大降低了后端应用服务器的带宽压力。
25.在具体实施过程中,通过pdf合并技术将图片/pdf格式的待审核单据进行自动合并,令整个审单过程无需逐个单据进行审核,可有效提高审核效率;同时,本方案能够将贸易背景资料及合同章内容对应的文本进行识别和提取,实现了对合同印章的识别,适用于合同等非固定格式文件的识别。
26.更具体的,在所述s2中,所述预审规则为先过滤出待审核单据中带有排序标识的字符,然后对字符转义为数字并根据数字对待审核单据进行排序;所述格式转化过程为:将webp格式文件采用流处理方式转换为png格式并对分辨率进行适应性调整。
27.在具体实施过程中,在需要合并pdf文件时,先按fileid列表把待审核单据逐一下载,遇到webp格式的文件自动采用流处理方式转换为png格式,对于分辨率较大或者较小的图片,会自动压缩或调整分辨率,使调整后的图片更符合后续ocr识别及人工检测的视觉效果;然后采用把图片写入到pdf文件context中的方式将图片合并为pdf文件。由于采用oss存储待审核单据及提供加速下载服务,使得整体文件合并效率非常高,操作响应快,用户体验较好。
28.更具体的,在所述s3中,ocr引擎使用ctpn算法模型提取出pdf文件中的文本内容,再利用nlp技术对文本内容进行解析,得到贸易背景资料;所述ctpn算法模型包括vgg16网络层、滑动卷积层、循环层、lstm网络层、softmax层和文本生成器;其中,提取出pdf文件中的文本内容的具体过程为:s3a1:读取pdf文件内容并对每一页内容进行拆分,得到多份单页内容;s3a2:将单页内容依次输入vgg16网络层中进行特征提取,生成多份单页内容的特征图;
s3a3:利用滑动卷积层对特征图进行多次滑动卷积操作,获取多个特征向量,生成新的特征图;s3a4:利用循环层对新的特征图进行重塑处理,将新的特征图重塑为lstm网络层能够处理的大小,得到重塑特征图;s3a5:利用lstm网络层对重塑特征图进行卷积处理并配置锚点,获取文本位置;s3a6:在softmax层中判断文本位置中是否包含文本,对文本所在的文本位置进行中心坐标修正和高度修正,生成修正结果;s3a7:利用修正结果,由文本生成器将中心坐标、高度相近的文本位置进行合并,构造成为一个文本行;再将多个文本行进行合并,得到pdf文件的文本内容。
29.更具体的,在所述s3中,所述nlp技术包括look-up层、bilstm层、crf层和filtrate层;利用nlp技术对文本内容进行解析,得到贸易背景资料的过程具体为:s3b1:利用look-up层将文本内容中的每一个单词映射为一个词向量,得到多个词向量;s3b2:bilstm层通过学习文本内容中上下文的信息,输出每个词向量对应于每个标签的得分概率;s3b3:将bilstm层的输出作为crf层的输入,通过学习标签之间的顺序依赖信息,得到每个词向量预测的序列标注;s3b4:利用filtrate层对每个词向量预测的序列标注进行处理,将无效标注进行过滤,并将有效标注归并到一个结果集输出,即得到贸易背景资料。
30.更具体的,在所述s3中,ocr引擎提取pdf文件中的合同章内容对应的文本过程具体为:s3c1:对s3a1中得到的多份单页内容分别进行印章识别,得到包含印章的单页内容;s3c2:基于三阶贝塞尔曲线算法对包含印章的单页内容进行处理,剪裁处印章中环形文字区块;s3c3:将环形文字区块中的所有曲形文本拉直成水平文本行图片;s3c4:利用卷积层对水平文本行图片进行图像特征提取,得到图像特征;s3c5:通过循环层对图像特征进行序列建模,对图像特征的特征表征进行改善;s3c6:将特征表征改善后的图像特征进行线性分类,通过ctc解码获得最终的识别结果,得到合同章内容对应的文本。
31.在具体实施过程中,可以将贸易背景资料进行提取并进行审核,对明显不符合规定的贸易背景资料进行提示,加快审批效率;在识别到贸易背景资料后,自动将其中的关键信息高亮加粗显示,方便审核人员快速定位找到有效信息,并根据审核清单逐项自动做出判断,有效避免人工审核出现遗漏,提升审核效率以提升工作人员的审核效率。
32.实施例2更具体的,在实施例1的基础上,本方案还提出一种基于ocr引擎的智能审单系统,具体如图2所示,包括金单前端单元、单据合并单元、ocr合同识别服务单元、智能审单单元;其中:所述金单前端单元基于oss对象存储服务将待审核单据进行上传;
所述单据合并单元用于按照预审规则选择待审核单据并检验文本格式,对待审核单据进行排序和格式转化,并合并为pdf文件;所述ocr合同识别服务单元基于ocr引擎对pdf文件进行识别,提取pdf文件中的贸易背景资料和合同章内容对应的文本,获取识别结果;所述智能审单单元对识别结果进行数据清洗和信息比较,根据比较结果对待审核单据进行审核,完成智能审单。
33.更具体的,在所述单据合并单元中,所述预审规则为先过滤出待审核单据中带有排序标识的字符,然后对字符转义为数字并根据数字对待审核单据进行排序;所述格式转化过程为:将webp格式文件采用流处理方式转换为png格式并对分辨率进行适应性调整。
34.更具体的,在所述ocr合同识别服务单元中内置有ocr引擎,ocr引擎使用ctpn算法模型提取出pdf文件中的文本内容,再利用nlp技术对文本内容进行解析,得到贸易背景资料;所述ctpn算法模型包括vgg16网络层、滑动卷积层、循环层、lstm网络层、softmax层和文本生成器;其中,所述ocr合同识别服务单元提取出pdf文件中的文本内容的具体过程为:s3a1:读取pdf文件内容并对每一页内容进行拆分,得到n份单页内容;s3a2:将n份单页内容依次输入vgg16网络层中进行特征提取,生成多份单页内容的特征图,表示为的特征图,其中c表示通道数,w表示宽度,h表示高度;s3a3:利用滑动卷积层对特征图进行多次滑动卷积操作,获取多个特征向量,生成新的特征图;其中,滑动卷积层先对特征图进行3x3的卷积,再进行im2col操作,即将一个[]矩阵变成一个[]矩阵,其原理是利用了行列式进行等价转换,每次操作都得到一个3x3通道数的特征向量,最后由所有特征向量生成一个新的特征图;s3a4:利用循环层对新的特征图进行重塑处理,将新的特征图重塑为lstm网络层能够处理的大小,得到重塑特征图;s3a5:利用lstm网络层对重塑特征图进行卷积处理并配置锚点,获取文本位置;s3a6:在softmax层中判断文本位置中是否包含文本,对文本所在的文本位置进行中心坐标修正和高度修正,生成修正结果;s3a7:利用修正结果,由文本生成器将中心坐标、高度相近的文本位置进行合并,构造成为一个文本行;再将多个文本行进行合并,得到pdf文件的文本内容。
[0035]
更具体的,在所述ocr合同识别服务单元中,所述nlp技术包括look-up层、bilstm层、crf层和filtrate层;利用nlp技术对文本内容进行解析,得到贸易背景资料的过程具体为:s3b1:利用look-up层将文本内容中的每一个单词映射为一个词向量,得到多个词向量;s3b2:bilstm层通过学习文本内容中上下文的信息,输出每个词向量对应于每个标签的得分概率;s3b3:将bilstm层的输出作为crf层的输入,通过学习标签之间的顺序依赖信息,得到每个词向量预测的序列标注;s3b4:利用filtrate层对每个词向量预测的序列标注进行处理,将无效标注进行过滤,并将有效标注归并到一个结果集输出,即得到贸易背景资料。贸易背景资料包括买
方、卖方、签订日期、有效日期等信息。
[0036]
更具体的,在所述ocr合同识别服务单元中,ocr引擎提取pdf文件中的合同章内容对应的文本过程具体为:s3c1:对s3a1中得到的多份单页内容分别进行印章识别,得到包含印章的单页内容;s3c2:基于三阶贝塞尔曲线算法对包含印章的单页内容进行处理,剪裁处印章中环形文字区块;s3c3:将环形文字区块中的所有曲形文本拉直成水平文本行图片;s3c4:利用卷积层对水平文本行图片进行图像特征提取,得到图像特征;s3c5:通过循环层对图像特征进行序列建模,对图像特征的特征表征进行改善;s3c6:将特征表征改善后的图像特征进行线性分类,通过ctc解码获得最终的识别结果,得到合同章内容对应的文本。
[0037]
在具体实施过程中,本系统结构简单,便于部署,可以很好地将基于ocr引擎的智能审单方法进行应用,利用pdf合并技术将图片/pdf格式的待审核单据进行自动合并,令整个审单过程无需逐个单据进行审核,有效提高审核效率;同时也能够将贸易背景资料及合同章内容对应的文本进行识别和提取,实现了对合同印章的识别,适用于合同等非固定格式文件的识别。
[0038]
实施例3更具体的,本实施例具体构建了一种智能审单系统,除包括金单前端单元、单据合并单元、ocr合同识别服务单元、智能审单单元(tradebgrd单元),还包含了交易核心服务单元(trade单元)和文件服务单元;其中,金单前端单元基于vuejs的微前端框架实现,运行在java虚拟机中,与金单交易核心服务单元交互获取后端数据,用于作为智能审单系统的展示ui;而交易核心服务单元基于java的spring boot开源框架实现,运行在java虚拟机中,与智能审单单元交互获取贸易背景资料识别结果,用于对贸易背景识别结果进行智能化判断并把结果返回前端展示;智能审单单元基于java的spring boot开源框架实现,运行在java虚拟机中,与ocr合同识别服务单元交互异步提交贸易背景合同文件识别任务及获取识别结果,用于对任务状态进行监控及调度(根据机器性能自动安排识别任务)并对识别结果进行数据初步清洗后返回金单交易核心服务单元;ocr合同识别服务单元采用c++编写,运行在docker容器中,提供合同文件内容识别及关键字抽取功能;而文件服务单元基于java的spring boot开源框架实现,其参与整个系统的文件上传、下载的过程。
[0039]
在具体实施过程中,如图3所示的文件上传流程图,首先由金单前端单元发起文件上传流程,到后端gettoken并提交到trade单元中,由trade单元发起到文件服务单元gettoken的任务;当文件服务单元收到gettoken的任务,则向oss对象存储服务发起gettoken的任务,由oss对象存储服务生成token,并将fileid列表依次返回到金单前端单元;金单前端单元利用fileid列表及token上传文件到oss对象存储服务,由oss对象存储服务接收文件并向金单前端单元通知文件服务上传完成的消息,由文件服务单元保存文件名称、大小,确认文件上传完成。
[0040]
上述文件上传流程中,将oss对象存储服务作为待审核单据对象存储中心,分离了待审核单据得上传逻辑。待审核单据在对象存储服务中均采用fileid作为命名,其信息存
储在文件服务中。金单前端单元通过后端获取到访问签名token后,可以直接将待审核单据上传到oss,则无需通过后端服务,前后端访问文件均可以直接对接oss对象存储服务,大大降低了后端应用服务器的带宽压力。
[0041]
更具体的,本系统在实际应用过程中,用户的贸易背景资料存在格式不规范、数据模型不清晰(多张图片对应对个材料)的问题,需要规范化格式并可以把属于一个材料的图片进行合并为一个pdf。图片合并为pdf文件功能包含前后端逻辑,具体为:金单前端单元采用tuploadfilesimple文件上传控件,tuploadfilesimple控件支持批量选择文件并检验文件格式,文件选择后将按照默认规则(先过滤文件名中带有排序标识的字符,然后对字符转义为数字并根据数字顺序进行排序)对文件排序,用户也可以在文件上传完毕后通过在金单前端单元上拖拽文件进行二次排序。tuploadfilesimple控件可以无缝地与系统的后端框架对接,内嵌的排序及拖拽动画效果可以提高使用体验。
[0042]
而在需要合并pdf文件时,先按fileid列表把待审核单据逐一下载,遇到webp格式的文件自动采用流处理方式转换为png格式,对于分辨率较大或者较小的图片,会自动压缩或调整分辨率,使调整后的图片更符合后续ocr识别及人工检测的视觉效果;然后采用把图片写入到pdf文件context中的方式将图片合并为pdf文件。由于采用oss存储待审核单据及提供加速下载服务,使得整体文件合并效率非常高,操作响应快,用户体验较好。
[0043]
更具体的,在ocr合同识别服务单元、智能审单单元中,涉及到一个基于ocr引擎对pdf文件进行识别的流程,具体如图4所示。
[0044]
在具体实施过程中,智能审单单元获取oss存储中的pdf文件到ocr合同识别服务单元中,由ocr合同识别服务单元对pdf文件进行识别并返回任务提交成功信息;此时在智能审单单元开启轮询任务完成情况的判断,在ocr合同识别服务单元、智能审单单元交互过程中,由ocr合同识别服务单元返回任务状态给智能审单单元,由智能审单单元判断轮询任务是否完成,若是,则结束该流程;否则,则继续进行轮询任务的完成情况。
[0045]
在具体实施过程中,由于不同的硬件环境,ocr引擎的识别速率并不一样且处于对ocr服务器的保护,需要控制每个ocr服务器同时执行的任务数,因此本系统采用分布式系统架构进行ocr识别任务的调度,其还设计具有优先级调度功能,支持先进先出策略的调度程序,方便对ocr识别任务进行调度。
[0046]
更具体的,先进先出策略的调度程序中的对象包含调度服务、redis两部分,redis用于缓存分布式系统中的任务队列及redis资源锁。调度程序根据redis资源锁判断资源是否处于占用状态,然后根据该资源处理任务平均速率的两倍减去任务已进行的时间统计出预计总需等待的时间,与空闲的资源进行比对,若空闲资源预计所需时间更少,对空闲资源加锁后返回获取到的资源id,若比空闲资源的预计时间还要少,则进行预占用(已在预占用转态的机器不参与比较),在任务结束后直接获取锁并返回资源id。调度服务提供一个释放锁接口,工作线程检测到ocr识别完成后,调用释放锁接口归还资源。如图5所示,具体调度过程为:ocr合同识别服务单元从oss中加载文件并组装ocr识别参数;完成该操作后便可以进行获取资源子流程,获取资源并判断资源的获取情况,若成功获取,则进行ocr识别子流程,完成对于资源的ocr识别,结束操作;若获取失败,则抛出异常,结束操作。
[0047]
如图6所示,所述的资源子流程具体为:先获取所有资源并遍历每个资源配置,对
每个资源,获取处理用时,判断可执行任务列表是否为空,若是,则返回获取资源失败;否则,则返回处理用时最少的资源。
[0048]
如图7所示,所述的对每个资源,获取处理用时的过程具体为:先查询redis资源锁,判断其是否被占用,所述redis资源锁缓存在redis中;若redis资源锁被占用,则查询redis资源预占用锁,判断其是否被预占用,若是,则返回资源已被占用,结束该子流程;若否,则返回资源对应的处理用时的两倍减去锁创建时间,结束该子流程;若redis资源锁未被占用,则返回资源对应的处理用时,结束该子流程。
[0049]
在具体实施过程中,本系统加入调度程序后,使得平均构建用时相对于随机分配资源的情况减少15%,进一步优化ocr服务器的资源使用效率。
[0050]
在具体实施过程中,在ocr合同识别服务单元中,可以将pdf文件转化问纯文字信息,其中采用ctpn算法模型提取出pdf文件中的文本内容,再利用nlp技术对文本内容进行解析,得到贸易背景资料;而对于合同章内容对应的文本的提取过程,其原理则是通过文字旋转特征和坐标等判断分布趋势相同的文字,并将其抽取成一个变量,获取到文字分布特征;接着由文字分布特征不同更准确地识别出合同章上的公司名字和其他附加信息;最后再对识别结果进行持久化保存。
[0051]
在具体实施过程中,在智能审单单元中,其通过查询ocr合同识别服务单元中的识别结果,并对识别结果进行数据清洗,包括如印章数据格式化(去除防伪码、去除地址分布办公室的干扰信息)、买卖双方名称处理(去除回车空格换行符等)、合同日期格式化(不同识别结果时间格式转为:yyyy-mm-dd)和合同金额格式化(单位转化、大写转小写);而智能审单单元进行信息对比的内容具体包括印章与企业名相似度对比、合同日期与开单日期对比、开单方名称与买方名称对比、收单方名称与卖方名称对比、开单金额与合同金额对比、发票金融与合同金融对比等,最后根据比较结果对工单实现智能审核。
[0052]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1