用于芯粒到芯粒互连的总线流水线结构和芯片的制作方法
1.本发明实施例涉及芯片技术,尤其涉及一种用于芯粒到芯粒互连的总线流水线结构和芯片。
背景技术:
2.芯粒(chiplet)片上系统(system on chip,soc)是后摩尔定律时代中芯片设计技术的最新发展。chiplet技术通过使用多个较小的芯粒进行芯片设计,既可以降低制造成本,又可以提高计算性能。
3.基于chiplet设计的芯片性能提升取决于多个芯粒间的芯粒到芯粒(die-to-die)互连设计。并行总线芯粒到芯粒互连是主要选择,它通过跨芯片触发器电路逐个引脚连接总线协议,它提供了两个芯粒之间最短的延迟,还可以通过增加总线宽度扩大带宽。然而,并行总线互连的缺点是增加了制造成本。芯粒互连的凸块间距(bump pitch)比芯片内部的总线互连消耗更多的硅片面积。
4.例如,有机基板封装的bump pitch约为150微米,集成扇出型(integrated fan-out,info)封装的bump pitch约为40微米,硅片上的总线间距小于0.1微米(μm)。以axi一致性扩展(axi coherency extensions,ace)总线监听的128位(bit)高级可拓展接口(advanced extensible interface,axi)总线为例。在芯粒到芯粒的一个方向总共需要大约600个输入/输出(input/output,i/o)信号。如果需要另一个方向,则需要另外一组600个io信号。通过axi/ace总线进行双向通信大约需要1200个io信号。在硅片上,1200个io信号消耗120微米宽的硅片。在info封装上,采用双排凸块排列,这需要24毫米(mm)宽的硅片。在有机基板封装上,采用双排凸块排列需要90毫米宽的硅片,或采用8排凸块排列需要22.5毫米宽的硅片。而为凸块添加的列越多,芯粒到芯粒互连的电气特性劣化就越大。由于总线io信号的必要增加,并行总线芯粒到芯粒互连无法通过增加芯粒的数量来支持更大的性能扩展。
技术实现要素:
5.本发明提供一种用于芯粒到芯粒互连的总线流水线结构和芯片,能够使用较小的实际位宽实现芯粒之间的高有效带宽,且避免了高延迟。
6.第一方面,本发明实施例提供了一种用于芯粒到芯粒互连的总线流水线结构,包括:发送端和接收端;
7.发送端包括发送状态机和n路复用器,接收端包括n路解复用器、至少两个寄存器和接收状态机,n大于或等于2,n路复用器和n路解复用器连接;
8.发送状态机与发送芯粒的发送总线连接且工作于发送芯粒的时钟域,n路复用器工作于n倍发送芯粒的时钟域,接收状态机与接收芯粒的接收总线连接且接收端工作于接收芯粒的时钟域;
9.发送状态机控制n路复用器将来自发送芯粒的数据流发送至n路解复用器,n路解
复用器将接收到的数据流输入至少两个寄存器中处于空闲状态的第一寄存器,第一寄存器将接收到的数据流通过接收状态机输出至接收芯粒;
10.接收状态机确认n路解复用器向第一寄存器发送接收到的数据流之后,向发送状态机发送总线释放标识,接收到总线释放标识的发送状态机在下一个时钟周期控制n路复用器将来自发送芯粒的数据流发送至n路解复用器。
11.在第一方面一种可能的实现方式中,接收状态机通过边带总线向发送状态机发送总线释放标识。
12.在第一方面一种可能的实现方式中,接收状态机还用于当至少两个寄存器均处于非空闲状态时,向发送状态机发送暂缓标识,发送状态机接收到暂缓标识后停止通过n路复用器发送来自发送芯粒的数据流。
13.在第一方面一种可能的实现方式中,接收状态机具体用于当至少两个寄存器均处于非空闲状态时,通过边带总线向发送状态机发送暂缓标识。
14.在第一方面一种可能的实现方式中,总线为数据总线或者命令/地址总线。
15.在第一方面一种可能的实现方式中,总线为数据总线和命令/地址总线;
16.发送芯粒的发送数据总线与接收芯粒的接收数据总线通过总线流水线结构连接,发送芯粒的发送命令/地址总线与接收芯粒的接收命令/地址总线通过总线流水线结构连接。
17.在第一方面一种可能的实现方式中,连接发送芯粒的发送数据总线与接收芯粒的接收数据总线的总线流水线结构的发送状态机接收到暂缓标识后,向连接发送芯粒的发送命令/地址总线与接收芯粒的接收命令/地址总线的总线流水线结构的发送状态机发送暂缓标识。
18.在第一方面一种可能的实现方式中,n路复用器和n路解复用器的位宽均为m,m
×
n大于或等于发送芯粒的发送总线向接收芯粒的接收总线一个时钟周期传输的数据流的长度。
19.在第一方面一种可能的实现方式中,至少两个寄存器为先入先出fifo寄存器。
20.在第一方面一种可能的实现方式中,n路复用器工作于n/2倍发送芯粒的时钟域,n路复用器采用双时钟沿选通处理。
21.第二方面,本技术实施例提供了一种芯片,芯片包括至少两个芯粒,至少两个芯粒中的任意两个芯粒之间通过如第一方面任一种可能的实现方式的用于芯粒到芯粒互连的总线流水线结构连接。
22.本发明实施例提供的用于芯粒到芯粒互连的总线流水线结构和芯片,采用多路复用器和解复用器对,在芯粒之间进行数据传输,实现了芯粒之间的总线流水线互联结构,可以使用较小的实际位宽实现芯粒之间的高有效带宽,且不会存在高延迟。。
附图说明
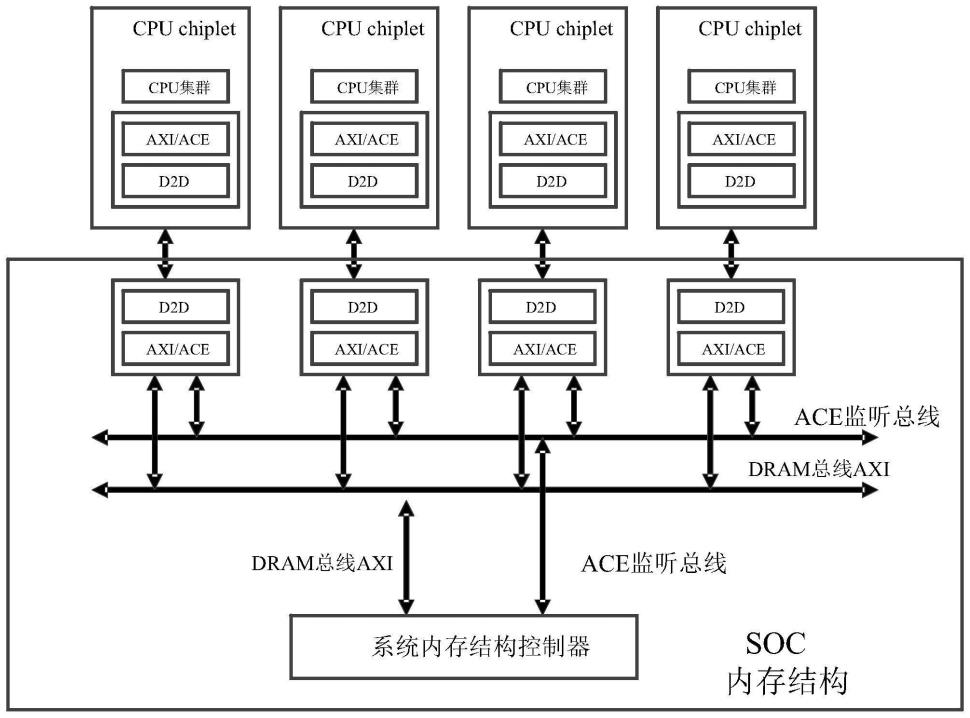
23.图1为通过多个芯粒互联来扩展计算性能的应用场景示意图;
24.图2为没有总线流水线的d2d互连和具有总线流水线的d2d互连的结构示意图;
25.图3为本技术实施例提供的一种用于芯粒到芯粒互连的总线流水线结构的结构示意图;
26.图4为本技术实施例提供的另一种用于芯粒到芯粒互连的总线流水线结构的结构示意图;
27.图5为本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构和芯片中,n路复用器和n路解复用器间传输数据的仿真时序示意图;
28.图6为本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构的完整传输时序示意图;
29.图7为本技术实施例提供的再一种用于芯粒到芯粒互连的总线流水线结构的结构示意图。
具体实施方式
30.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
31.为了解决芯粒间互联使用并行总线连接存在的问题,一种技术是使用多个n路复用器(multiplexer)和多路解复用器(de-multiplexer)对来减少芯粒到芯粒互连中所需的io信号数量。最新的行业趋势是通用chiplet互连快递(universal chiplet interconnect express,ucie)。ucie利用了外围组件告诉互联(peripheral component interconnect express,pcie)成熟的i/o物理层、芯粒到芯粒协议和软件堆栈。ucie能够减少芯粒互连的io信号数量,但它具有延迟长和缺乏总线流水线(bus pipeline)的缺点。这些缺点阻碍了ucie成为通过芯粒设计扩展计算性能的选择。
32.图1为通过多个芯粒互联来扩展计算性能的应用场景示意图,如图1所示,图中示出4个多核中央处理器(central processing unit,cup)集群(cluster)的芯粒(chiplet)连接到系统内存结构控制器(system memory fabric controller)的设计,设计目标是提高4倍的计算性能。为了实现性能的扩展,芯粒到芯粒(die-to-die,d2d)需要将axi/ace总线从chiplet复制到系统内存结构。通过d2d实现快速相应和总线流水线控制的需求。由于类似于pcie/计算高速连接(cxl)的多层协议和数据包格式,ucie的延迟过高。d2d的长延迟会削弱动态随机存取存储器(dynamic random access memory,dram)总线axi(dram bus axi)和ace监听总线(smooping bus ace)。ucle中的2k位(bit)的固定有效负载和512bit或1k bit的典型cpu缓存线大小不同。ucie对固定有效载荷的这种限制阻止了实施总线流水线。因此,内存主控周期可能会超出或低于axi/ace运行周期。当使用ucie时,有效带宽会严重降低其d2d的峰值带宽。这表明需要一条总线流水线来支持可变大小的数据传输。即使系统结构内存由于多个内存主设备的流量冲突而经历长延迟,总线流水线也可以产生高有效带宽。
33.本技术实施例提供一种基于n路复用器和多路解复用器对的芯粒到芯粒互联的总线流水线结构。及时系统内从结构在高内存期间由于内存冲突而经历长延迟,芯粒到芯粒之间互联的总线流水线也能够能够维持有效带宽不会降低。
34.为了实现总线流水线结构,需要两个并发的总线协议。一种是命令/地址总线(command/address bus),另一种是数据总线(data bus)。命令/地址总线的总线宽度比数据总线窄。这两种总线之间的总线利用率通常不同,命令/地址总线比数据总线轻得多。命
令/地址总线通常是一个总线周期。数据总线通常在多个突发周期中,例如在4个突发周期或8个突发周期等中。系统内存结构会将地址/命令总线输入到请求的队列列表中,根据其队列列表,可能需要不同的延迟处理来自命令/地址总线的内存请求。在一定的延迟之后,根据来自所有内存主机的内存请求流量,系统架构将响应数据总线上的内存传输。重要的是内存数据总线需要通过总线流水线进行高效操作。图2为没有总线流水线的d2d互连和具有总线流水线的d2d互连的结构示意图。
35.参照图2,其中显示了没有流水线的d2d互联(without pipeline)和具有流水线的d2d互联(with pipeline d2d)之间的内存数据总线效率。图中均以axi写入(axi wt)操作为例,通过axi wt/d2d和d2d/axi wt一对d2d互联向内存写入数据,需要首先进行解码(decode)并通过axi总线发送(axi issue),然后需要经历系统结构延迟(fabric latency),最后会得到存储器响应(memory response)。没有流水线的d2d互连按顺序执行总线周期,无法减轻解码开销和系统内存结构延迟,如图2所示,对于没有流水线的d2d互连,第一个数据发送周期,需要依次执行解码(decode_1)并通过axi总线发送(axi issue_1),然后需要经历系统结构延迟(fabric latency_1),最后会得到存储器响应(memory response_1),在第一个数据发送周期得到存储器相应后,才能进入第二个数据发送周期。然后在第二个数据发送周期,仍然依次执行解码(decode_2)并通过axi总线发送(axi issue_2),然后需要经历系统结构延迟(fabric latency_2),最后会得到存储器响应(memory response_2)。显然,存储器数据总线需要承担延迟和解码时间的开销,这种d2d互联方案,有效带宽会降低。具有流水线的d2d互连可以同时执行总线周期。再如图2所示,对于具有流水线的d2d互连,第一个数据发送周期,需要依次执行解码(decode_1)并通过axi总线发送(axi issue_1),然后需要经历系统结构延迟(fabric latency_1),最后会得到存储器响应(memory response_1),而第二个数据发送周期可以在第一个数据发送周期完成解码(decode_1)并通过axi总线发送(axi issue_1)之后即可执行。显然,具有流水线的d2d互连存储器数据总线解码的开销和系统结构延迟可以得到缓解,并在产生高有效带宽。
36.d2d总线流水线没有被应用的一个根本原因是它使用固定的数据包格式将总线信号从芯粒传输到内存结构或从内存结构传输到芯粒。由于不同的总线带宽和延迟的性质,这会阻止执行并发的地址/命令总线和数据总线。另一个根本原因是,典型的d2d除了物理层外,还承载了数据包传输延迟和数据包接收延迟,以支持d2d适配器层和协议层的操作。因此,很难在短延迟内同时将芯粒上的axi/ace总线转换为系统内存结构上的axi/ace。
37.图3为本技术实施例提供的一种用于芯粒到芯粒互连的总线流水线结构的结构示意图,如图3所示,本实施例提供的用于芯粒到芯粒互连的总线流水线结构包括:
38.发送端31和接收端32。发送端31包括发送状态机311和n路复用器312,接收端32包括n路解复用器321、至少两个寄存器322和接收状态机323,n大于或等于2,n路复用器312和n路解复用器321连接。
39.本实施例提供的用于芯粒到芯粒互连的总线流水线结构,提供了基于chiplet架构的芯片内芯粒到芯粒(d2d)的互联,其中芯粒可以为芯片内部实现任意功能的独立部分,例如任意结构的芯粒、系统存储结构(system memory fabric)、soc等。
40.图3示意性地示出本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构,为了进一步说明本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构的原理和功
能,以图4所示更为具体的用于芯粒到芯粒互连的总线流水线结构为例,对本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构进行说明。图4为本技术实施例提供的另一种用于芯粒到芯粒互连的总线流水线结构的结构示意图。
41.图4中以作为发送方的芯粒为任意结构的chiplet,作为接收方的芯粒为系统存储结构,发送方向接收方同时发送axi写入数据总线(axt wt)和axi写入地址/命令总线(axi aw)的数据流为例进行说明。需要说明的是,本实施例提供的用于芯粒到芯粒互连的总线流水线结构可以仅为在发送方和接收方之间传输一条数据流的总线流水线结构。
42.发送状态机411(axi_aw_enc)与发送芯粒的发送总线axi aw连接,发送状态机412(axi_wt_enc)与发送芯粒的发送总线axi wt)连接,且发送状态机411和发送状态机412均工作于发送芯粒的时钟域(1x clock),8路复用器(8-1multiplexer)413工作于n倍发送芯粒的时钟域(图中以8倍时钟为例(8x clock)),8路复用器414工作于8倍发送芯粒的时钟域,接收状态机423(axi_aw_dec)与接收芯粒的接收总线axi aw连接,接收状态机426(axi_wt_dec)与接收芯粒的接收总线axi wt)连接,且接收端工作于接收芯粒的时钟域(接收端的8路解复用器(1-8de-multiplexer)421、8路解复用器424、两个寄存器422、寄存器425、接收状态机423、接收状态机426均工作于接收芯粒的时钟域,即1x clock)。
43.发送状态机411控制8路复用器413将来自发送芯粒的数据流发送至8路解复用器421,8路解复用器421将接收到的数据流输入至少两个寄存器422中处于空闲状态的第一寄存器422(图中仅示出一个寄存器422),第一寄存器422将接收到的数据流通过接收状态机423输出至接收芯粒。其中,对于地址/命令总线(axi aw),由于每个周期的数据量较小,寄存器422也可以为1个。
44.接收状态机423确认8路解复用器421向第一寄存器422发送接收到的数据流之后,向发送状态机411发送总线释放标识(awready),接收到总线释放标识的发送状态机411在下一个时钟周期控制8路复用器413将来自发送芯粒的数据流发送至8路解复用器421。
45.8路复用器413工作于8倍发送芯粒的时钟域,那么在发送芯粒的一个时钟周期内,8路复用器413就能够传输8倍于8路复用器413位宽的数据。一个总线流水线结构中的8路复用器413和8路解复用器421为一对,具有相同的复用通路数量。一对8路复用器413和8路解复用器421能够实现在一个时钟周期内进行地址/命令总线的传输。8路复用器413和8路解复用器421具有相同的位宽,且该位宽根据需要传输的数据流的长度确定。具体地,一对n路复用器和n路解复用器的位宽均为m,m
×
n大于或等于发送芯粒的发送总线向接收芯粒的接收总线一个时钟周期传输的数据流的长度。例如axi aw总线,需要在一个时钟周期内传输48bit的数据,在发送方可以使用位宽为6bit的8路复用器(8-1multiplexer)413,相应地,在接收方,使用位宽为6bit的8路解复用器(1-8de-multiplexer)421。这样就可以实现在一个时钟周期内从发送方向接收方的数据流传输,而在这里,8路复用器413和8路解复用器412的位宽仅为6bit,也即可以仅使用6bit的位宽实现48bit数据流的传输。8路解复用器421接收到48bit的数据流后,需要先将数据流写入第一寄存器422。第一寄存器422工作于接收方的时钟域,那么第一寄存器422可以在接收方的时钟周期将存储的数据发送给接收方,接收方仍然在自己的时钟域中进行数据接收。其中,对于地址/命令总线(axi aw),由于每个周期的数据量较小,第一寄存器422也可以为1个。
46.相同地,再例如axi wt总线,需要在一个时钟周期内传输128bit数据、16bit字节
掩码(byte mask)和16bit错误校验码(error correcting code,ecc),共计160bit,在发送方可以使用位宽为22bit的8路复用器(8-1multiplexer)414,相应地,在接收方,使用位宽为22bit的8路解复用器(1-8de-multiplexer)424。这样就可以实现在一个时钟周期内从发送方向接收方的数据流传输,而在这里,8路复用器414和8路解复用器424的位宽仅为22bit,最高可以支持176bit的数据流传输,也即可以仅使用22bit的位宽实现160bit数据流的传输。
47.接收状态机423确认8路解复用器421向第一寄存器422发送接收到的数据流之后,无需等待第一寄存器422处理完存储的数据,可以立即向发送状态机411发送总线释放标识(awready),接收到总线释放标识的发送状态机411在下一个时钟周期控制即可继续通过8路复用器413进行数据发送。同样地,接收状态机426确认8路解复用器424向第一寄存器425或第二寄存器426发送接收到的数据流之后,无需等待第一寄存器425或第二寄存器426处理完存储的数据,可以立即向发送状态机412发送总线释放标识(图中未示出),接收到总线释放标识的发送状态机412在下一个时钟周期控制即可继续通过8路复用器414进行数据发送。
48.接收状态机423可以通过边带总线(side band bus)向发送状态机411发送总线释放标识,也即不通过8路复用器413和8路解复用器421之间的连接发送总线释放标识。同样地,接收状态机426可以通过边带总线(side band bus)向发送状态机412发送总线释放标识,也即不通过8路复用器415和8路解复用器425之间的连接发送总线释放标识。
49.在接收端设置至少两个寄存器是由于发送状态机412可以在接收到接收状态机426发送的总线释放标识后,立即通过8路复用器414发送数据,而此时第一寄存器425存储的数据可能还未被处理完,此时8路解复用器424可以将再次接收的数据存储至另一个空闲的第二寄存器427。各寄存器按照接收数据的先后顺序依次向接收方发送数据。一般地,在接收端中设置两个寄存器即可实现数据的持续发送,但接收端中寄存器的数量可以根据实际设计需求确定。
50.接收端32中的至少两个寄存器可以为先入先出(first input first output,fifo)寄存器,即寄存器中存储的数据按照接收的时间先后顺序依次输出。每个寄存器中包括两个存储部分,一部分用于存储该寄存器的可用状态,另一部分用于存储数据。如图4中示出的第一寄存器422,一部分用于存储fifo有效比特(fifo valid bit),另一部分用于存储48bit的aw数据(1
×
48fifo aw)。第一寄存器425,一部分用于存储fifo有效比特(8
×
1fifo valid bit),另一部分用于存储176bit的wt数据(8
×
176fifo wt)。第二寄存器427,一部分用于存储fifo有效比特(8
×
1fifo valid bit),另一部分用于存储176bit的wt数据(8
×
176fifo wt)。另外,位于axi wt总线的寄存器还可以包括存储接收状态机的状态的寄存器空间(fifo wt state machine)。图4中的第一寄存器425和第二寄存器427构成双乒乓fifo(double ping pong fifo)。
51.进一步地,若接收端32中的至少两个寄存器均处于非空闲状态,也即接收端32中的所有寄存器均存储有数据,那么将无法继续接收数据,此时接收状态机426可以向发送状态机412发送暂缓标识(stall),发送状态机412接收到暂缓标识后停止通过8路复用器414发送来自发送芯粒的数据流。接收状态机同样可以通过边带总线(side band bus)向向发送状态机414发送暂缓标识。
52.进一步地,当芯粒之间的互联同时传输数据总线和命令/地址总线时,也即发送芯粒的发送数据总线与接收芯粒的接收数据总线通过总线流水线结构连接,发送芯粒的发送命令/地址总线与接收芯粒的接收命令/地址总线通过总线流水线结构连接。由于数据总线并不是每个时钟周期均有数据传输,且一次传输的数据量要大于地址/命令总线传输的数据量,那么连接发送芯粒的发送数据总线与接收芯粒的接收数据总线的总线流水线结构的发送状态机412接收到暂缓标识后,可以向连接发送芯粒的发送命令/地址总线与接收芯粒的接收命令/地址总线的总线流水线结构的发送状态机411发送暂缓标识(to_stall)。
53.另外,由于时钟频率越高设计难度越高,n路复用器可以工作于n/2倍发送芯粒的时钟域,此时n路复用器采用双时钟沿选通(double clock data strobe)处理。也即n路复用器在时钟周期的每个上升沿和下降沿均进行相应处理,这样可以降低n路复用器所使用的时钟的频率。
54.图5为本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构和芯片中,n路复用器和n路解复用器间传输数据的仿真时序示意图,其中用于芯粒到芯粒互连的总线流水线结构如图4所示。
55.图5中的时序显示d2d结构由两个clk1x提供时钟,一个在chiplet(clk1x_chp),另一个在soc(clk1x_soc)。由于在两个不同的物理芯粒上,这两个时钟共享相同的频率但处于不同的时钟相位。在chiplet中,8路复用器在信号“valid_loop_wt”的断言处(assertion)开始传输数据。图5显示8路复用器在第一个时钟发送h'feb378257a89,在第二个时钟发送h'61539576f06,在第三个时钟发送h'32105678fedc。然后n路复用器使用双时钟数据选通,dqs_tx_p以8x时钟切换以将串行数据流传输到8路解复用器。使用来自8路复用器的正向dqs_tx_p选通串行数据,这样8路解复用器执行1到8解复用。在解复用之后,8路解复用器将写入数据信号“d_lp_ar_rdy_1x”置位到fifo。一旦数据存储在fifo中,fifo将在1x时钟到soc的同步阶段断言信号“valid_loop_bk_ar”。这就是8路复用器和多路解复用器如何以最小延迟完成发送和接收序列,包括d2d互连之间的时钟同步,这种d2d的互连不需要任何软件协议。与ucie/pcie/usb操作需要软件协议不同,通过8路复用器和8路解复用器进行传输和接收的延迟很长。
56.图6为本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构的完整传输时序示意图,其中用于芯粒到芯粒互连的总线流水线结构如图4所示。
57.在图6中的“t0”时刻,chiplet作为d2d发送方启动axi写入周期。d2d互连将axi总线协议从chiplet传递到系统内存结构,系统内存结构作为d2d接收方。这可以在如图5所示的短延迟内完成。在图4中,示出了axi总线信号通过两个同时设置的8路复用器/解复用器对传输,即aw(写地址/命令)和wt(写入的数据)。一组传输地址和命令,另一组传输写数据。chiplet写入周期是8个连续时钟的突发传输,没有零等待状态。因此,图6示出了比dqs_tx_axi_aw更长的dqs_tx_axi_wt。
58.在“t0”和“t1”的时序之间,d2d发送方中的6位8路复用器(图4)将地址/命令总线信号传输到6位8路解复用器。并且地址/命令总线信号存储到fifo中以在1x时钟域中同步,以便d2d接收方(图4)中的axi_aw_dec可以获取信号并将axi写入地址/命令断言到系统架构时刻“t1”。在地址/命令总线进行发送和接收的同时,数据总线通过22位路复用器和8路解复用器执行相同的过程。数据总线执行8个连续的128位数据/16位字节掩码/16位ecc的
突发传输,因此,8路复用器和8路解复用器将比图6所示的地址/命令总线花费更长的传输和接收时间。在时刻“t1”,d2d接收方的axi总线断言地址/命令总线和有效的写入数据到系统内存结构。
59.在时刻“t2”,系统内存结构能够接受另一个请求队列,即系统内存结构断言“awready_soc”信号以释放地址/命令总线。然而,由于数据总线中的长延迟,系统内存结构无法响应数据总线。长延迟可能是由各种原因引起的,例如忙于为其他内存主机服务或执行dram刷新周期或只是内存路径的长延迟。因此,系统存储器结构直到时刻“t7”才能响应第一个写入数据。在时刻“t0”和时刻“t7”之间,d2d已经超过了系统内存结构的两个挂起写入周期。在时刻“t2”,d2d接收方的axi总线接收到总线释放信号“awready_soc”。d2d接收方将这个信号通过边带总线而不通过复用器/解复用器对传递给d2d发送方,如图4所示。在图6所示的时刻“t3”,d2d发送方断言总线释放“awready_c”到请求另一个周期的chiplet。这是在d2d发起方通过边带总线接收到总线释放请求“xawready”之后。在时刻“t3”,chiplet还完成了从d2d发起方到d2d接收方的突发数据传输。这与命令/地址总线并发,并以零等待状态执行数据传输。要写入内存结构的数据存储在8x176 fifo_a中,如图4所示。但是,由于系统内存结构中的响应缓慢,d2d接收方axi写入数据总线无法写入系统内存结构。fifo中的这些数据将保持原样,直到d2d接收方axi可以将数据写入内存结构。在这种情况下,fifo a存储数据,如图6所示。“valid_a”标志从0变为254,表示fifo_a存储写入数据。fifo_b中的“valid_b”保持为0,表示fifo_b中没有存储待处理的数据。
60.由于d2d发起方在“t3”释放chiplet总线。在时刻“t4”,chiplet开始请求另一个周期执行,即使前一个周期在d2d接收方fifo_a处未决并且内存结构尚未响应。在“t4”时刻,d2d发起方开始通过8路复用器和8路解复用器的两组并发执行发送和接收。因为fifo_a保留在前一个未决周期,所以d2d接收方中的8路解复用器将使用fifo_b来存储数据。一旦使用了fifo_b,valid_a将不再为“0”。由于两个fifo都被使用,“stall”标志将被置位。并且“stall”通过边带从d2d接收方传递到d2d发起方,而不经过8路复用器/解复用器对。“stall”标志将停止d2d发送方中的状态机以释放总线并处理chiplet中的任何未决周期请求。
61.在时刻“t5”,“停止”标志被断言,直到fifo中的一个为空并且能够从chiplet接收另一个周期请求。在时刻“t6”,axi向内存结构发出新的命令/地址信号。因此,总线对存储器结构有两个未决周期。内存结构没有理由实现大缓冲区大小来从同一个主服务器获取更多请求队列。因此,d2d接收方中的axi总线由于内存结构无法占用更多未决周期而停止。
62.在时刻“t7”,存储器结构准备好响应在较长延迟后存储在fifo_a中的第一个数据。一旦存储器结构开始响应来自d2d fifo_a的未决数据突发周期,它就可以释放总线并接受另一个请求。因此,在时刻“t7”,内存结构响应写入数据突发,同时通过向d2d接收方断言“awready_soc”来释放地址/命令总线。d2d接收方通过边带将“aready_soc”传递给d2d发起方,以请求释放chiplet总线并接受chiplet中的其他未决请求。但是,fifo_a和fifo_b都不是空的。因此,由于两个fifo都不是空的,“停止”标志仍然有效。“stall”标志将屏蔽从d2d接收方断言的“xawready”。
63.chiplet总线将保持未完成状态,直到时刻“t8”。在时刻“t8”,存储器结构完成了来自fifo_a的最后一个数据。因此,在将所有数据刷新到内存结构后,fifo_a为空,“valid_
a”返回0。标志“stall”变为非活动状态,该标志传递给d2d发起程序。一旦d2d发起方接收到不活动的“stall”,d2d发起方就会释放chiplet总线以接受下一个挂起的周期请求(如果有的话)。
64.在时刻“t9”,chiplet向d2d接收方发出另一个未决周期请求。d2d接收方将执行相同的操作并将未决数据存储在fifo_a中。内存结构有能力响应fifo_b,而fifo_a接收来自d2d发送方的周期请求。在时刻“t10”,内存结构从fifo_b获取所有数据,它可以释放总线以获取另一个周期请求。内存结构可以继续响应存储在d2d接收方中的fifo_a数据。在时刻“t11”开始响应fifo_a中的数据。
65.只要内存结构能够响应d2d接收方,d2d发送方就可以同时从具有可用fifo的chiplet中获取周期请求。内存结构可以达到图6所示的高有效带宽。
66.基于图3-图6所示实施例,同样可以在axi读取总线使用本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构,如图7所示,图7为本技术实施例提供的再一种用于芯粒到芯粒互连的总线流水线结构的结构示意图。
67.图7与图4的区别在于,图7中示出的是axi读地址总线(axi ar)和axi读数据总线(axi rd)之间连接的芯粒到芯粒互连的总线流水线结构。其中由chiplet方作为发送方通过axi ar总线向soc发送读地址请求,其结构与图4中的axi aw总线上的结构类似。而在axi rd总线,是由soc将chiplet请求的数据发送给chiplet,因此总线流水线是从soc到chiplet的方向,与图4中的axi wt总线上的总线流水线结构类似,但方向相反。同时,图7中也是由axi rd总线上的接收状态机直接向axi ar总线上的发送状态机发送to_stall信息。axi ar总线上的发送状态机还可以向axi rd总线上的接收状态机发送循环请求(cycle rq),询问是否能够在下一周期发送数据。
68.本技术实施例提供的用于芯粒到芯粒互连的总线流水线结构,采用多路复用器和解复用器对,在芯粒之间进行数据传输,实现了芯粒之间的总线流水线互联结构,可以使用较小的实际位宽实现芯粒之间的高有效带宽,且不会存在高延迟。
69.本技术实施例还提供一种芯片,该芯片包括至少两个芯粒,至少两个芯粒中的任意两个芯粒之间通过如图3-图7所示实施例的用于芯粒到芯粒互连的总线流水线结构连接。
70.一般来说,本技术的多种实施例可以在硬件或专用电路、软件、逻辑或其任何组合中实现。例如,一些方面可以被实现在硬件中,而其它方面可以被实现在可以被控制器、微处理器或其它计算装置执行的固件或软件中,尽管本技术不限于此。
71.本技术的实施例可以通过计算机装置的数据处理器执行计算机程序指令来实现,例如在处理器实体中,或者通过硬件,或者通过软件和硬件的组合。计算机程序指令可以是汇编指令、指令集架构(instruction set architecture,isa)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、或者以一种或多种编程语言的任意组合编写的源代码或目标代码。
72.本技术附图中的任何逻辑流程的框图可以表示程序步骤,或者可以表示相互连接的逻辑电路、模块和功能,或者可以表示程序步骤与逻辑电路、模块和功能的组合。计算机程序可以存储在存储器上。存储器可以具有任何适合于本地技术环境的类型并且可以使用任何适合的数据存储技术实现,例如但不限于只读存储器(read-only memory,rom)、随机
访问存储器(random access memory,ram)、光存储器装置和系统(数码多功能光碟(digital video disc,dvd)或光盘((compact disc,cd))等。计算机可读介质可以包括非瞬时性存储介质。数据处理器可以是任何适合于本地技术环境的类型,例如但不限于通用计算机、专用计算机、微处理器、数字信号处理器(digital signal processing,dsp)、专用集成电路(application specific integrated circuit,saic)、可编程逻辑器件(field-programmable gate array,fgpa)以及基于多核处理器架构的处理器。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1