基于自集成模块的NERF新视角合成模型的实现方法
基于自集成模块的nerf新视角合成模型的实现方法
技术领域
1.本发明提出了一种基于自集成模块的nerf新视角合成模型的实现方法。
背景技术:
2.新的视图合成可以分为基于图像的方法、基于学习的方法和基于几何的方法。基于图像的方法在观测帧中扭曲和混合相关斑块,基于质量的测量生成新的视图。基于学习的方法通过神经网络和其他的启发式来预测混合权重和视图依赖的效应。深度学习也促进了从单一图像中预测新视图的方法,但它们通常需要大量的数据来训练。与基于图像和基于学习的方法不同,基于几何的方法首先重建一个三维模型,并从目标姿态渲染图像。例如,aliev等人将多分辨率特征分配给点云,然后进行神经渲染;thies等人将神经纹理存储在三维网格上,然后用传统的图形管道渲染新的视图。其他几何表示包括多平面图像、体素网格、深度和分层深度。这些方法,虽然产生了相对高质量的结果,但离散表示需要丰富的数据和内存,而渲染的分辨率也受到重建几何图形的精度的限制。
3.隐式神经表示已经证明了它在表示形状和场景方面的有效性,这通常利用多层感知器(mlps)来编码有符号的距离场signed distance fields、占用occupanc或体积密度volume density。与可微渲染一起,这些方法可以重建对象和场景的几何形状和外观。其中,神经辐射场(nerf)在合成给定一组姿态输入图像的静态场景的新视图方面取得了显著的效果。nerf的关键思想是利用mlp构造一个连续的辐射场,并通过可微体积渲染来获得图像,因此,优化过程可以通过最小化光度损失photometric loss来实现,出现了越来越多的nerf扩展,例如:没有输入摄像机姿态的重建、建模非刚性场景non-rigid scenes、无界场景unbounded scenes和对象类别object categories。nerf也被研究为能够重新激活、generation、editing和3d重建。
4.另外mip-nerf也考虑了nerf的解决问题。他们表明,在不同分辨率下呈现的nerf将引入混叠伪影,并通过提出一个集成的位置编码,使锥形而不是单点来解决它。然而,mip-nerf只考虑具有低采样分辨率的渲染,目前还没有任何工作来研究如何提高nerf的分辨率。
5.本发明的工作也与图像的超分辨率有关。经典的单图像超分辨率(sisr)方法利用先验,如图像统计或梯度。基于cnn的方法旨在通过最小化sr图像和地面真相之间的均方误差来学习cnn中hr和lr图像之间的关系。生成对抗网络(gans)在超分辨率中也很流行,它通过对抗学习产生高分辨率的细节。这些方法大多从大规模的数据集或现有的高分辨率和低分辨率的训练对中获得知识。此外,这些基于二维图像的方法,特别是基于gan的方法没有考虑到视图的一致性,对于新的视图合成是次优的。
6.现有的方法将补丁匹配patch-match、特征提取或注意力的hr引用和lr输入之间的对应关系进行匹配。受他们作品的启发,我们还致力于从给定的参考图像中学习hr细节。然而,这些方法大多基于参考超解析super-resolve一个sr输入,而我们的方法可以通过一个参考图像从所有新视图中细化细节。
技术实现要素:
7.本发明的目的是针对现有技术的不足,提供一种基于自集成模块的nerf新视角合成模型的实现方法。本发明开发了一个新的基于自集成模块的nerf神经辐射场,提出了一种新的自集成模块,以重建高质量的新视角图像。该自集成模块主要用于测试阶段,在测试阶段使用重建效果更好的图像。通过在nerf作者开源的数据集上进行大量测试,证明了该基于自集成模块的nerf神经渲染场有比原始nerf更加强大的重建能力。
8.本发明解决其技术问题所采用的技术方案如下:
9.步骤1:选择图像数据
10.选择nerf作者在google drive中开源的训练数据,其中训练数据包括生成的乐高数据和场景数据,且乐高数据和场景数据分别存储在两个文件夹;
11.步骤2:构建基于自集成模块的nerf新视角合成模型。
12.进一步的,步骤2具体实现如下:
13.2-1.获取nerf的场景表征;
14.2-2.基于场景表征的体素渲染;
15.2-3.构建自集成模块。
16.进一步的,步骤2-1具体实现如下:
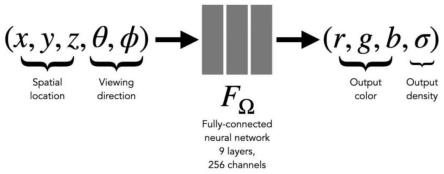
17.mlp的输入是源图像对应的三维空间坐标和视角输出是(r,g,b,σ),在得到场景表征(r,g,b,σ)后,渲染出射线对应的图片;其中,(x,y,z)表示三维空间坐标,表示视角;(r,g,b)表示rgb颜色值,σ表示体素密度。
18.进一步的,步骤2-2具体实现如下:
19.2-2-1.对一条射线采样64个点,每个采样点对应着一个经过mlp得到每个采样点的场景表征(r,g,b,σ);
20.2-2-2.使用经典的渲染公式对射线进行渲染,得到该射线对应像素的颜色值c(r),具体渲染过程如下:
[0021][0022]
其中,r(t)是射线的公式,t的取值范围是从近端点tn和远端点tf,也就是积分的上下限;σ(r(t))是射线在点t的体素密度,由mlp预测的结果得到;c(r(t),d)是射线在点t的rgb颜色值,由mlp的预测结果得到,其中符号d是射线o+td中的方向向量;t(t)是射线在点t的透光率,由体素密度σ(r(t))积分得到,具体公式是的透光率,由体素密度σ(r(t))积分得到,具体公式是利用mlp的预测结果求解图片中某个像素点的rgb颜色值;
[0023]
2-2-3.选择l1损失,即均方差损失函数,具体如下:
[0024]
l1=(rgb
nerf-rgb
groundtruth
)2[0025]
其中,rgb
nerf
是利用nerf对于特定视角的场景渲染出的图片的rgb颜色值,rgb
groundtruth
是对应于该视角的真实图片的rgb颜色值。
[0026]
进一步的,步骤2-3具体实现如下。
[0027]
自集成模块设定训练8个完全独立的模型,分别对于同一个数据集进行3d重建,将同一个物体或者同一个场景隐式地存储在不同模型的不同参数中。
[0028]
进一步的,每个模型训练20000个epoch后,分别对同一场景的同一视角进行3d重建,得到该视角相应的渲染后的rgb颜色值。
[0029]
进一步的,计算渲染后rgb颜色值与真实图片的rgb颜色值(grountruth)的损失,并将该损失转换成为psnr。
[0030]
进一步的,对8个完全独立模型得到的渲染后的rgb颜色值进行平均,得到目标视角下重建的最终rgb颜色值。
[0031]
进一步的,每个完全独立模型都重复步骤1和2的操作,对同一个数据集中同一场景的不同视角进行渲染得到rgb颜色值。
[0032]
进一步的,自集成模块主要体现在模型测试阶段。
[0033]
本发明有益效果实现如下:
[0034]
本发明是基于nerf对模型进行的自集成处理。本发明自集成模块能够更好地提取图片的纹理特征,从而提高了重建的精度。本发明将自集成模块添加到nerf神经辐射场中,可以提高输出图像的峰值信噪比,提高图像质量。具体来说,本发明在原始nerf上训练模型,在这些测试数据集上测试了模型,并将做过自集成后的结果与nerf和nerf变型进行比较,发现本发明提出的自集成具有很好的重建效果。数据集rain100l的峰值信噪比从25.73提高到26.73。这些现象反映了我们提出的自集成模块对于3d新视角重建效果增强,可以更好地还原场景的具体细节。
附图说明
[0035]
图1是基于自集成模块的nerf新视角合成模型mlp预测示意图。
[0036]
图2是基于自集成模块的nerf新视角合成模型渲染和loss构建示意图。
[0037]
图3是自集成模块的nerf新视角合成模型效果图。
具体实施方式
[0038]
下面结合附图对本发明作进一步说明。
[0039]
如图1-3所示,基于自集成模块的nerf新视角合成模型的实现方法,具体实现步骤如下:
[0040]
步骤1:选择图像数据
[0041]
选择nerf作者在google drive中开源的训练数据,其中训练数据包括生成的乐高数据和场景数据,且乐高数据和场景数据分别存储在两个文件夹。以场景数据据中的“hot dog”这一类为例,其包含“train/val/test”文件夹,以及三个包含每个图片拍摄时的相机姿态的json文件。具体在读入过程中,由“load_blender_data”的函数根据上述的json文件读入image,transform_matrix等信息。
[0042]
实施例1:
[0043]
本发明实验中,使用了4096条射线的批量大小,在粗体积中,每条射线在nc=64个坐标处采样,在细体积中,每条射线在nf=128个附加坐标处采样。使用adam优化器,其学习
率从5
×
10-4
开始并指数衰减至5
×
10-5
在优化过程中(其他adam超参数保留为默认值β1=0.9、β2=0.999)。单个场景的优化通常需要大约100
–
300k
次迭代才能在单个nvidia v100 gpu上收敛(大约1
–
2天)。
[0044]
步骤2:构建基于自集成模块的nerf新视角合成模型;
[0045]
2-1.获取nerf的场景表征
[0046]
nerf采用的是基于体素的表征方式,用mlp进行拟合。如图1所示。
[0047]
mlp的输入是源图像对应的三维空间坐标和视角输出是(r,g,b,σ),分别表示rgb颜色值和体素密度。在得到场景表征(r,g,b,σ)后,渲染出射线对应的图片。其中,(x,y,z)表示三维空间坐标,表示视角;(r,g,b)表示rgb颜色值,σ表示体素密度。
[0048]
由于mlp自身提取高频信息的限制,采用nlp领域中位置编码的技巧,对输入进行位置编码,更容易拟合高频域的函数,提高性能。
[0049]
2-2.基于场景表征的体素渲染
[0050]
体素渲染基于光线投射,在新视角合成任务中被广泛使用。nerf本身就是基于三维体素渲染的方法将场景的表征信息转换成2d图像。如图2所示。
[0051]
2-2-1.首先对一条射线采样64个点,每个采样点对应着一个经过mlp得到每个采样点的场景表征(r,g,b,σ);
[0052]
2-2-2.使用经典的渲染公式对射线进行渲染,得到该射线对应像素的颜色值c(r),具体渲染过程如下:
[0053][0054]
其中,r(t)是射线的公式,t的取值范围是从近端点tn和远端点tf,也就是积分的上下限;σ(r(t))是射线在点t的体素密度,由mlp预测的结果得到;c(r(t),d)是射线在点t的rgb颜色值,由mlp的预测结果得到,其中符号d是射线o+td中的方向向量;t(t)是射线在点t的透光率,由体素密度σ(r(t))积分得到,具体公式是的透光率,由体素密度σ(r(t))积分得到,具体公式是这样我们就利用了mlp的预测结果来求解图片中某个像素点的rgb颜色值。
[0055]
2-2-3.选择l1损失,即均方差损失函数,具体如下:
[0056]
l1 loss=(rgb
nerf-rgb
groundtruth
)2[0057]
其中,rgb
nerf
是利用nerf对于特定视角的场景渲染出的图片颜色信息,rgb
groundtruth
是对应于该视角的真实图片颜色信息。通过梯度计算并利用梯度下降的方法不断优化nerf模型,从而提升nerf渲染图片的质量。
[0058]
2-3.构建自集成模块。
[0059]
自集成模块主要体现在模型测试阶段。如图3所示,自集成模块设定训练8个完全独立的模型,分别对于同一个数据集进行3d重建,将同一个物体或者同一个场景隐式地存储在不同模型的不同参数中。
[0060]
每个模型训练20000个epoch后,分别对同一场景的同一视角进行3d重建,得到该视角相应的渲染后的rgb颜色值。
[0061]
计算渲染后rgb颜色值与真实图片的rgb颜色值(grountruth)的损失,并将该损失转换成为psnr。
[0062]
对8个完全独立模型得到的渲染后的rgb颜色值进行平均,得到目标视角下重建的最终rgb颜色值。这个做法充分的利用了模型自身的随机性,利用集成学习较强的信息融合能力,将各个模型对于同一任务重建结果提取融合,得到令人惊喜的结果。
[0063]
进一步的,本发明每个完全独立模型都重复步骤1和2的操作,对同一个数据集中同一场景的不同视角进行渲染得到rgb颜色值。
[0064]
步骤3所述的算法性能比较
[0065]
在两个物体的合成渲染数据集上进行实验。deepvoxels20数据集包含四个具有简单几何形状的lambertian对象。每个对象从上半球采样的视点中呈现为512
×
512像素。我们渲染每个场景的100个视图作为输入,200个用于测试,所有这些都是800
×
800像素。该方法基于nerf上对模型进行的自集成处理。该框架中的集成模块可以更好地提取图片的纹理特征,从而提高了重建的精度。将该模块添加到nerf神经辐射场中,可以提高输出图像的峰值信噪比,提高图像质量。具体来说,我们在原始nerf上训练模型,并在这些测试数据集上测试了模型,并将我们做过自集成后的结果与nerf和nerf变型进行比较,如表1所示,发现我们提出的自集成具有很好的重建效果。数据集的峰值信噪比从25.7317提高到26.7329,即相比于原始nerf,我们将性能提升了一个百分点左右。尽管只是一个百分点,但是对于原始较高质量图片的优化来说是一个巨大的跨越。目前世界上nerf的变形,例如mip-nerf,只能提升将近0.2个百分点左右。由此反映了我们提出的自集成模块对于3d新视角重建效果增强幅度是相当之大,可以更好地还原场景的具体细节,对于推动3d重建任务技术的进步是一定参考意义的。
[0066]
表1:基于自集成模块的nerf和nerf进行比较
[0067]
methodpsnrssimnerf25.73170.987基于自集成模块的nerf26.73290.992
[0068]
。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1