一种无监督单视点合成方法及装置
1.本发明涉及深度学习、视点合成领域,尤其涉及一种无监督单视点合成方法及装置。
背景技术:
2.随着多视点视频技术的快速发展,自由视点显示逐渐获得了研究者的关注。自由视点显示因其能够提供沉浸式的视觉体验,广泛应用于元宇宙和虚拟现实等领域。在实际应用中,为了获得高质量的自由视点显示,通常需要从不同的位姿获取大量的视图。然而,部署多个相机拍摄不同位姿的视图所需成本较大,高质量的自由视点显示面临着挑战。视点合成技术能够在给定有限数量源视图的条件下合成其他任意位姿处的目标视图,已成为当前自由视点显示领域的研究热点。
3.近些年,得益于卷积神经网络强大的特征表示能力,基于深度学习的有监督视点合成方法已取得显著进展。liu等人提出一种几何感知的视点合成网络来合成目标视图。wiles等人通过学习不同位姿间的点云转换来合成目标视图。kyle等人设计了一种瓶颈转换网络学习3d空间转换以合成目标视图。然而,上述方法通常依赖昂贵的标签来监督视图转换的学习过程。不同于有监督的方法,无监督视点合成方法能够在无需标签监督的条件下学习不同位姿间的视图转换。因此,研究无监督视点合成方法具有十分重要的意义和实用价值。
4.对于无监督视点合成,nicolai等人利用多个源视图作为网络的输入以获得位于基准位姿处的物体表示,然后基于此物体表示分别重建输入的多个源视图,最终利用合成的源视图与真实源视图之间的重建误差来约束网络的训练。
5.尽管上述方法能够以无监督地方式训练视点合成网络,但是其依然需要多个源视图来感知不同视图间的空间转换关系,这极大地限制了视点合成方法在仅有单个源视图存在条件下的应用。因此,研究如何仅利用单个源视图训练视图合成网络的无监督单视点合成方法是至关重要的。当前无监督视点合成方法需要多个源视图来学习不同位姿间的视图转换,其极大地限制了无监督视点合成方法在仅有单个源视图存在条件下的应用。
技术实现要素:
6.本发明提供了一种无监督单视点合成方法及装置,本发明仅利用单个源视图作为输入,设计了基于风格引导和先验蒸馏的无监督单视点合成方法以合成任意目标位姿处的视图,以仅利用单个源视图学习视图间的转换,详见下文描述:
7.一种无监督单视点合成方法,其特征在于,所述方法包括:
8.构建一由风格嵌入策略、3d旋转操作和视图映射操作组成的风格引导视图合成模型,真实源视图is、源位姿ps以及高斯噪声gn作为输入来合成源视图以学习视图转换,然后从学习的视图转换中合成任意目标位姿处的伪目标视图
9.构建一由体积生成模块、3d旋转操作和视图映射操作组成的先验蒸馏视图合成模
型,真实源视图is、源位姿ps以及任意目标位姿p
t
作为输入,以合成任意目标位姿p
t
处的最终目标视图
10.基于所述风格引导视图合成模型和先验蒸馏视图合成模型,构建总损失函数,基于所述总损失函数对所述风格引导视图合成模型和先验蒸馏视图合成模型进行训练,进而对目标视图进行合成。
11.其中,所述风格嵌入策略包含:风格生成部分和风格操控部分,风格生成部分将真实源视图is作为输入,提取源视图的风格矢量s,如下:
12.s=o
sgm
(is)
13.其中,o
sgm
表示风格生成部分,其包含六个堆叠的2d卷积层和四个堆叠的1d卷积层;
14.将高斯噪声gn和风格矢量s作为风格操控部分的输入,以生成内在表示vr,如下:
[0015]vr
=o
smm
(gn,s)
[0016]
其中,o
smm
表示风格操控部分,包含一个2d风格操控单元和一个3d风格操控单元。
[0017]
进一步地,
[0018]
所述2d风格操控单元采用具有跳跃连接的编码器-解码器的网络结构,编码器网络由八个2d卷积层和四个自适应实例归一化层组成,其中,每两个2d卷积层后堆叠一个自适应实例归一化层以在2d空间中将风格矢量s嵌入到高斯噪声gn中;解码器网络由六个堆叠的2d卷积层组成;
[0019]
所述3d风格操控单元由两个3d卷积层和两个自适应实例归一化层组成,其中,每个3d卷积层后堆叠一个自适应实例归一化层以在3d空间中进一步嵌入风格矢量s。
[0020]
其中,将源视图is作为体积生成模块的输入以生成ps处的3d体积表示vs,基于生成的3d体积表示vs,在源位姿ps和目标位姿p
t
的引导下,使用3d旋转操作和视图映射操作合成最终的目标视图如下:
[0021][0022]
其中,所述训练先验蒸馏视图合成模型的损失函数的如下:
[0023][0024][0025][0026][0027][0028]
其中,为伪目标视图,为最终的目标视图。
[0029]
一种无监督单视点合成装置,所述装置包括:处理器和存储器,所述存储器中存储有程序指令,所述处理器调用存储器中存储的程序指令以使装置执行任一项所述的方法步骤。
[0030]
本发明提供的技术方案的有益效果是:
[0031]
1、本发明通过利用深度学习的特征表达能力,设计了一种风格引导视图合成模型,从而能够在无需标签监督的条件下,构建不同位姿间视图转换以合成任意目标位姿处的视图;
[0032]
2、本发明设计了一种先验蒸馏视图合成模型以学习视图间的直接转换,在提升合成视图质量的同时减少合成过程中的推理时间。
[0033]
3、本发明在仅需单个源视图的条件下获得了与全监督单视点合成方法可比的性能。
附图说明
[0034]
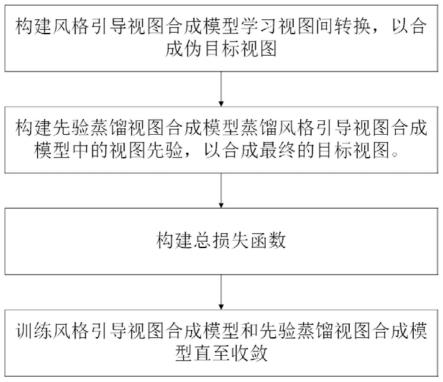
图1为一种无监督单视点合成方法的流程图;
[0035]
图2为本方法与其他方法的对比结果示意图;
[0036]
图3为风格操控的示意图;
[0037]
图4为视图映射操作的示意图;
[0038]
图5为3d旋转操作示意图;
[0039]
图6为体积生成的示意图。
具体实施方式
[0040]
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
[0041]
下面通过实例来说明本发明实施例中无监督单视点合成方法的具体实施方式。
[0042]
一、构建风格引导视图合成模型
[0043]
在仅有单个源视图可用的条件下,无监督单视点合成方法的关键在于如何学习不同位姿间的视图转换。为此,本发明实施例假设了一个参考位姿pr以学习内在表示vr,该内在表示vr能够在参考位姿pr处描述物体。基于此内在表示vr,可以构建参考位姿pr和源位姿ps之间的视图转换以实现无监督单视点合成。
[0044]
为了实现上述目的,本发明实施例设计了风格引导视图合成模型以无监督的方式学习视图转换。
[0045]
本发明实施例利用真实源视图is、源位姿ps以及高斯噪声gn作为风格引导视图合成模型的输入来合成源视图以学习视图转换,然后从学习的视图转换中合成任意目标位姿处的伪目标视图风格引导视图合成模型由风格嵌入策略、3d旋转操作和视图映射操作组成。
[0046]
首先,通过所设计的风格嵌入策略获得物体在参考位姿pr处的内在表示vr。
[0047]
具体而言,所设计的风格嵌入策略包含:风格生成部分和风格操控部分,风格生成部分将真实源视图is作为输入,提取源视图的风格矢量s,公式如下:
[0048]
s=o
sgm
(is)
ꢀꢀꢀ
(1)
[0049]
其中,o
sgm
表示风格生成部分,其包含六个堆叠的2d卷积层和四个堆叠的1d卷积层。
[0050]
然后将高斯噪声gn和风格矢量s作为风格操控部分的输入,以生成内在表示vr,公
式如下:
[0051]vr
=o
smm
(gn,s)
ꢀꢀ
(2)
[0052]
其中,o
smm
表示风格操控部分,如图3所示,其包含一个2d风格操控单元和一个3d风格操控单元。2d风格操控单元采用具有跳跃连接的编码器-解码器的网络结构。编码器网络由八个2d卷积层和四个自适应实例归一化层组成,其中,每两个2d卷积层后堆叠一个自适应实例归一化层以在2d空间中将风格矢量s嵌入到高斯噪声gn中。解码器网络由六个堆叠的2d卷积层组成。3d风格操控单元由两个3d卷积层和两个自适应实例归一化层组成,其中,每个3d卷积层后堆叠一个自适应实例归一化层以在3d空间中进一步嵌入风格矢量s。
[0053]
最后,通过任意位姿pa的引导,利用3d旋转操作和视图映射操作从此内在表示vr中合成目标视图公式如下:
[0054][0055]
其中,o
p
表示视图映射操作,or表示3d旋转操作。如图4和图5所示,视图映射操作由两个3d卷积层、八个2d卷积层和三个残差块组成,3d旋转操作由一个三线性采样层组成。
[0056]
由于在无监督单视点合成方法中,仅有单个源视图可用来训练网络,因此,输入的真实源视图is应为网络提供监督。为此,风格引导视图合成模型将上述公式中的pa设置为源位姿ps以合成源视图公式如下:
[0057][0058]
本发明实施例采用多个损失函数来约束风格引导视图合成模型获得的合成源视图与真实源视图is之间的一致性以实现无监督单视点合成。
[0059]
首先,使用光度损失l
p
、特征损失lf及形状损失ls分别约束合成源视图和真实源视图is的外观一致性、特征一致性以及形状一致性,公式如下:
[0060][0061][0062][0063]
其中,v表示vgg-19,seg表示计算视图的分割图。
[0064]
此外,为了进一步提高合成视图的质量,本发明实施例还使用相似度损失l
ssim
和对抗损失la来训练网络,公式如下:
[0065][0066][0067]
其中,ssim表示相似度计算,d表示鉴别器,其由六层卷积层组成,e表示数学期望。
[0068]
在仅有单个源视图is存在的条件下,本发明实施例设计了风格引导视图合成模型。首先,为了实现无监督学习,本发明实施例利用公式(4)合成源位姿ps处的视图然后,本发明实施例使用公式(5)和公式(6)来约束合成源视图和真实源视图is之间的一致性以指导风格引导视图合成模型的学习过程。
[0069]
二、构建先验蒸馏视图合成模型
[0070]
由于无监督单视点合成需要生成内在表示vr,然后从此内在表示vr中合成目标位姿p
t
处的目标视图。然而,生成此内在表示vr通常需要耗费额外的推理时间,导致无监督单视点合成方法的实时性较差。为了进一步减少视点合成方法的推理时间以提高该方法的实时性,本发明实施例设计了先验蒸馏视图合成模型使其以直接的方式合成目标视图。
[0071]
先验蒸馏视图合成模型将真实源视图is、源位姿ps以及目标位姿p
t
作为输入,以合成p
t
处的目标视图先验蒸馏视图合成模型包含:体积生成模块、3d旋转操作和视图映射操作。
[0072]
首先,将源视图is作为体积生成模块的输入以生成ps处的3d体积表示vs,基于生成的3d体积表示vs,在源位姿ps和目标位姿p
t
的引导下,使用3d旋转操作和视图映射操作合成最终的目标视图公式如下:
[0073][0074]
其中,o
vgm
表示体积生成模块,如图6所示,其包含七个2d卷积层、三个残差块和两个3d卷积层。
[0075]
由于缺乏真实的目标视图标签,在获得目标视图后,为了学习从源位姿ps到目标位姿p
t
的直接视图转换,本发明实施例首先将风格引导视图合成模型中的pa设置为目标位姿p
t
以合成一个伪目标视图公式如下:
[0076][0077]
然后,为了监督先验蒸馏视图合成模型学习直接的视图转换,本发明实施例采用与风格引导视图合成模型相同的损失函数来约束目标视图和伪目标视图之间的一致性,以训练先验蒸馏视图合成模型,损失函数的公式如下:
[0078][0079][0080][0081][0082][0083]
得益于所设计的先验蒸馏视图合成模型(即公式(7)),本发明实施例能够以更少的推理时间合成高质量的目标视图。
[0084]
三、构建总损失函数
[0085]
为了训练所提出的风格引导视图合成模型,构建了损失函数公式如下:
[0086][0087]
其中,α,β,γ和λ分别设置为1,5,10和0.5。
[0088]
此外,为了训练所提出的先验蒸馏视图合成模型,构建了损失函数公式如
下:
[0089][0090]
四、训练无监督单视点合成方法的网络
[0091]
无监督单视点合成方法的训练过程分为两个阶段,在第一阶段,训练风格引导视图合成模型,直至收敛;在第二阶段,固定前一阶段模型的参数,训练先验蒸馏视图合成模型,直至收敛。
[0092]
五、根据源位姿ps和目标位姿p
t
的引导,利用源视图is合成目标视图
[0093]
在测试阶段,本发明实施例只采用先验蒸馏视图合成模型进行无监督单视点合成,风格引导视图合成模型并不参与测试过程,本发明实施例与其他方法的对比结果如图2所示。
[0094]
一种无监督单视点合成装置,该装置包括:处理器和存储器,存储器中存储有程序指令,处理器调用存储器中存储的程序指令以使装置执行以下方法步骤:
[0095]
构建一由风格嵌入策略、3d旋转操作和视图映射操作组成的风格引导视图合成模型,真实源视图is、源位姿ps以及高斯噪声gn作为输入来合成源视图以学习视图转换,然后从学习的视图转换中合成任意目标位姿处的伪目标视图
[0096]
构建一由体积生成模块、3d旋转操作和视图映射操作组成的先验蒸馏视图合成模型,真实源视图is、源位姿ps以及任意目标位姿p
t
作为输入,以合成任意目标位姿p
t
处的最终目标视图
[0097]
基于风格引导视图合成模型和先验蒸馏视图合成模型,构建总损失函数,基于总损失函数对风格引导视图合成模型和先验蒸馏视图合成模型进行训练,进而对目标视图进行合成。
[0098]
其中,风格嵌入策略包含:风格生成部分和风格操控部分,风格生成部分将真实源视图is作为输入,提取源视图的风格矢量s,如下:
[0099]
s=o
sgm
(is)
[0100]
其中,o
sgm
表示风格生成部分,其包含六个堆叠的2d卷积层和四个堆叠的1d卷积层;
[0101]
将高斯噪声gn和风格矢量s作为风格操控部分的输入,以生成内在表示vr,如下:
[0102]vr
=o
smm
(gn,s)
[0103]
其中,o
smm
表示风格操控部分,包含一个2d风格操控单元和一个3d风格操控单元。
[0104]
进一步地,
[0105]
2d风格操控单元采用具有跳跃连接的编码器-解码器的网络结构,编码器网络由八个2d卷积层和四个自适应实例归一化层组成,其中,每两个2d卷积层后堆叠一个自适应实例归一化层以在2d空间中将风格矢量s嵌入到高斯噪声gn中;解码器网络由六个堆叠的2d卷积层组成;
[0106]
3d风格操控单元由两个3d卷积层和两个自适应实例归一化层组成,其中,每个3d卷积层后堆叠一个自适应实例归一化层以在3d空间中进一步嵌入风格矢量s。
[0107]
其中,将源视图is作为体积生成模块的输入以生成ps处的3d体积表示vs,基于生成的3d体积表示vs,在源位姿ps和目标位姿p
t
的引导下,使用3d旋转操作和视图映射操作合成
最终的目标视图如下:
[0108][0109]
其中,训练先验蒸馏视图合成模型的损失函数的如下:
[0110][0111][0112][0113][0114][0115]
其中,为伪目标视图,为最终的目标视图。
[0116]
这里需要指出的是,以上实施例中的装置描述是与实施例中的方法描述相对应的,本发明实施例在此不做赘述。
[0117]
上述的处理器和存储器的执行主体可以是计算机、单片机、微控制器等具有计算功能的器件,具体实现时,本发明实施例对执行主体不做限制,根据实际应用中的需要进行选择。
[0118]
存储器和处理器之间通过总线传输数据信号,本发明实施例对此不做赘述。
[0119]
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
[0120]
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0121]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1