基于集成随机配置神经网络的人体姿态与动作识别方法
1.本发明涉及机器学习技术领域,尤其是涉及基于集成随机配置神经网络的人体姿态与动作识别方法。
背景技术:
2.近年来,随着随机权神经网络的不断发展,wang等提出的随机配置网络 (stochastic configuration network,scn)由于其特有的学习机制,在快速学习的情况下,很好的保证了网络较高的逼近性能和分类性能,并因此得到了广泛应用。但当scn模型应用于大数据集时,随着隐藏层节点数量的增多求解最后输出权重时,运用最小二乘方法计算大型线性方程组的伪逆矩阵十分困难,需要占用的电脑内存和运算时间都十分高。而通常为了精准识别人体行为动作,会尽可能用多传感器设备同时以高频率采集人体行为活动数据,因此运用单个scn 模型来作为人体姿态和动作识别的分类器模型难以取得理想的识别效果。
技术实现要素:
3.本发明方案利用bagging算法对采集数据进行预处理,利用scn网络设计基分类器,最后通过对基分类器的预测结果进行汇总得到识别结果,以提高人体姿态与动作识别的准确率以及识别效率。
4.为实现上述目的,本发明提供了如下技术方案,包括如下步骤:
5.s1、将主、辅测量装置分别固定在人体双脚踝外侧;测量装置内均集成有三轴加速度计、三轴陀螺仪和三轴磁力计,且其内传感器以10hz频率采样;主、辅测量装置间通过射频传输数据,并整合后通过蓝牙传输给上位机;
6.s2、上位机将采集数据输入至识别模型内,识别模型将采集数据划分为若干子数据集,每个子数据集对应输入至一个基学习器中;基学习器基于随机配置神经网络子模型搭建,并从时域和频域角度对采集数据进行分析;识别模型依据集成策略对基学习器预测结果进行汇总,并输出识别结果。
7.优选的,基学习器从时域角度对静态行为进行分析,从频域角度对动态行为进行分析。
8.优选的,识别模型基于bagging算法对采集数据进行预处理以及结果汇总; bagging算法基于自助抽样法将采集数据划分为若干子数据集,并依据加权均值法对所有基学习器识别结果进行汇总。
9.本发明采用上述人体姿态与动作识别方法,基学习器集成后具有良好的泛化性能,对人类活动识别准确度达到92.5%以上,取得了与cnn相当的准确率,且计算复杂度和所需时间远低于单个scn、cnn、lstm和svm模型,且不需要使用 gpu进行训练,在大大节省训练时间和算力前提下,取得了理想的识别效果。
附图说明
10.图1为现有技术中scn模型的网络结构示意图;
11.图2为现有技术中自助采样法的集成采样学习示意图;
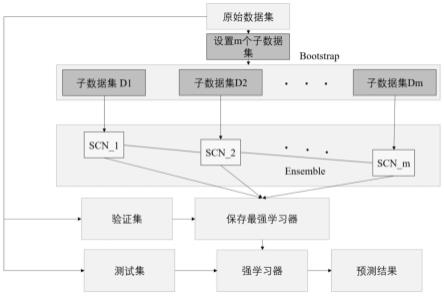
12.图3为本发明中人体姿态与动作识别模型的网络结构示意图;
13.图4为bagging-scn模型的训练集、验证集和测试集结果;
14.图5为scn模型的训练集、验证集和测试集结果;
15.图6为svm模型的训练集、验证集和测试集结果;
16.图7为lstm模型的训练集、验证集和测试集结果;
17.图8为cnn模型的训练集、验证集和测试集结果;
18.图9为本发明中基学习器数量与分类识别准确度的关系图。
具体实施方式
19.以下结合附图和实施例对本发明的技术方案作进一步说明。
20.基于集成随机配置神经网络的人体姿态与动作识别方法,包括如下步骤:
21.s1、基于传感器采集人体活动产生的数据。
22.将主、辅测量装置分别固定在人体双脚踝外侧。测量装置内均集成有三轴加速度计、三轴陀螺仪和三轴磁力计,且其内传感器以10hz频率采样。主、辅测量装置间通过射频传输数据,并整合后通过蓝牙传输给上位机。
23.s2、上位机将采集数据输入至识别模型内进行分析。
24.识别模型基于bagging算法和scn模型设计。
25.bagging算法基于bootstrap自助抽样法将采集数据划分为若干子数据集,每个子数据集对应输入至一个基学习器中。基学习器基于scn子模型搭建,并从时域和频域角度对采集数据进行分析。时域特征有助于模型识别区分躺、站等静态行为,其包括:最大值、最小值和平均值等,频域特征可用于区分动态和静态行为,其包括:峰度,偏度和向量夹角等。
26.识别模型依据集成策略对基学习器的预测结果进行加权平均,并输出识别结果。
27.一、scn模型建模与bagging算法原理
28.如图1所示,scn模型的建模过程如下:
29.(1)给定一个目标函数f:rd→rm
,假设存在已经建立好l-1层隐藏节点的网络,则网络输出可表示为:
[0030][0031]
式中,wj=[w
j1
,...,w
jd
]
t
,bj=[b
j1
,...,b
jd
]
t
分别为隐含层节点的输入权重和偏置,βj=[β
j1
,...,β
jm
]
t
为隐藏层与输出层之间的输出权重,gj(
·
)代表第j个隐藏节点的激活函数。根据网络输出表达式可以得出网络残差e
l-1
可表示为:
[0032]el-1
=f-f
l-1
=[e
l-1,1
,e
l-1,2
,...,e
l-1,m
]
t
ꢀꢀ
(2)
[0033]
如果||e
l-1
||未能满足理想的tolerance(容错度),则网络会继续从可调区间 [-λ,λ]d和[-λ,λ]内随机生成输入权重w
l
和b
l
生成一个新的隐藏层节点,则目标函数更新为:
[0034]
[0035]
(2)scn算法是根据一个不等式约束来更新增加节点的,例如在增加第l 个节点时,其随机生成的输入权重向量w
l
和偏差b
l
需要满足以下不等式:
[0036][0037]
式中,δ
l
=(1-r-μ
l
)||e
l-1
||2,μ
l
=(1-r)/(l+1),0<r<1,||
·
||表示frobenius范数。
[0038]
(3)计算输出权重:scn最基础的三个版本中,scn-ii算法表现的最好,其输出权重采用最小化全局残差来得到输出权重:
[0039][0040]
式中,
[0041]
求解上式的最小化问题一般采用最小二乘法:
[0042]
β
*
=h
+
t=(hh
t
)-1
ht
ꢀꢀ
(6)
[0043]
式中,h为隐藏层输出:hh
t
代表非奇异矩阵,h=[h1,h2,...,h
l
]
t
,t是根据数据集制作的n
×
m 的样本标签矩阵,n为样本数量,m为分类数量。
[0044]
(4)然后计算第l步的误差e
l
,判断是否小于设定的理想tolerance,如果满足则建模完成,返回最佳的输入输出权重;不满足则继续第二步的过程添加隐藏层节点,直到满足设定的理想tolerance。
[0045]
通过上述步骤scn-ii有着良好的普遍逼近能力,当将scn运用到分类问题时,实际上就是建立一个网络去拟合一个0-1样本标签矩阵t,但由上述步骤可知当样本数量n非常大,和样本种类数量m多时,根据残差最小化求得的伪逆误差较大,计算十分复杂占用计算机资源多,且失去了scn的快速性,因此本方案借助集成算法的思想,对集成scn来处理人体行为活动数据处理分类展开研究。
[0046]
如图2所示,bagging算法计算过程如下:
[0047]
(1)给定包含n个样本的训练数据集,采用bootstrap自助抽样法,随机选取出k个样本放入采样集中。特别的,这里根据训练数据中的各个类别的样本数进行等概率选取,可以增强对类不平衡数据的稳健性。由于大量实验测量设备采用固定频率对人体活动行为数据进行采样,故而像跑这样持续时间较短的数据会偏少,而像躺等行为则偏多,当将这种不平衡数据集放入网络中训练会导致训练好的模型忽略少数类,从而导致对于少数类的分类效果很差。而bootstrap 自助采样法可以在数据预处理阶段,使得各采样子集数据类之间达到平衡,从而提升各子分类器性能。
[0048]
(2)将取出的k个样本放回到初始训练数据集中,使得下次采样时,该样本仍有可能被选中。这样经过m次随机采样操作,最终得到m个样本的采样集。采样次数应大于n/m,保证所有样本都会被利用进行训练,有的样本会在某些采样子集中重复多次出现,以保证训练出来的基学习器集成后具有良好的泛化性能。
[0049]
(3)按照上述两步操作采样出m个含有k个训练样本的采样集,然后针对每个采样
集训练出一个基学习器,再将这些基学习其进行集成,得到一个有强分类性能的学习器。
[0050]
二、bagging-scn模型构建
[0051]
如图3所示,本方案对上述的scn模型和bagging算法进行结合,设计出 bagging-scn模型。训练集采用bootstrap的方式进行采样,生成m个训练子集,利用不同的训练子集训练生成不同的scn模型,最后将所有基学习器给测试集数据的打分结果求均值,按照均值矩阵最后的结果确定测试集数据的类别。
[0052]
该模型算法描述如下:
[0053]
[0054]
[0055][0056]
三、bagging-scn模型测试model
best
[0057]
实验共采集了三十位受试者顺序进行上楼梯、走、跑、躺、站和下楼梯活动时的运动数据,实验场地为办公楼群室外连廊自然环境,具备上台阶、平坦连廊、下台阶等自然连续室外实验条件。本实验共采集到22060条运动数据。
[0058]
针对自建数据集的仿真实验是在cpu为intel(r)core(tm)i7-9700, 3.00ghz,ram为16gb的硬件平台上采用python3.8软件平台进行。
[0059]
采用bagging-scn、scn、cnn、lstm、svm进行对比实验。其中,基学习器 scn算法训练停止条件为:最大节点数l
max
=2500,tolerance=0.01,权值搜索最大搜索次数t
max
=100,λ=[0.05,5,20,50,100,200,500],不等式约束系数r=[0.9,0.99, 0.999,0.9999,0.99999,0.999999]。bagging-scn初始设置为500个基学习器。
[0060]
将所采集到的数据按照6:2:2划分为训练集、验证集和测试集。五种模型分类识别结果见图4-8以及表1。
[0061]
表1五种模型分类识别结果
[0062][0063]
从实际应用的角度和各模型综合表现来看,bagging-scn分类识别准确度,取得了和cnn相当的效果,且比使用单个scn作为识别模型更加准确。
[0064]
进一步的,本方案还探究基学习器数量与分类识别准确度的关系,结果如图 9所示。实际集成基学习器数量在80个附近时,即开始出现饱和,甚至随着基学习器数量增多,整体集成模型的预测准确率下降。因此,为了找出最优的集成模型和最优的集成学习数量,通过验证集数据在集成模型中的表现,来保存最强的集成学习器,并删除部分冗余或干扰的基学习器,以达到最优的分类效果。
[0065]
针对基于传感器的人体行为识别应用,bagging-scn的表现要优于其他四个模型,
并且根据先验知识对数据进行坏数据剔除和对数据进行人为特征提取,对改善网络分类准确性能还有着可提高空间,可有针对性的对于识别较差的行为姿态数据提取更多特征,来提升最后的识别精度。而对于cnn网络来说,由于其复杂的网络结构,以及庞大的待收敛参数,势必对计算机算力有着更高的要求以及更久的训练拟合时间,没有采用bagging-scn经济和应用范围广,因此应用可穿戴行为数据采集器配合bagging-scn智能行为识别算法具有实用性,且优于现有的神经网络方法。
[0066]
以上是本发明的具体实施方式,但本发明的保护范围不应局限于此。任何熟悉本领域的技术人员在本发明所揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内,因此本发明的保护范围应以权利要求书所限定的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1