自监督三维显微图像去噪方法和系统
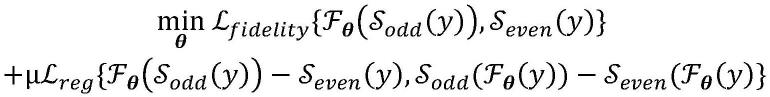
1.本技术大体上涉及荧光显微图像去噪方法和系统、特别是基于自监督学习的三维显微图像去噪方法和系统。
背景技术:
2.荧光显微成像是研究细胞生物学、发育生物学、神经科学等生命科学领域的重要工具。针对当前的荧光显微成像技术来讲,成像的速度、时程和信噪比之间相互制约,其主要原因在于:要想提高成像速度,就需要缩短光学成像系统的相机的曝光时间,这会导致在有限的曝光时间内捕捉到的有效荧光信号更少,进而造成所获取的荧光图像的信噪比降低;要想提高成像时程,就需要降低光学成像系统的荧光激发装置的激发功率,这会减少生物样本被激发出来的荧光光子数,也降低所获取的荧光图像的信噪比。
3.虽然已有研究发现,基于有监督学习的深度神经网络可以将低信噪比显微成像数据恢复为对应的高信噪比数据,从而提升荧光显微成像的成像速度和时程,但此类有监督学习的深度神经网络在使用之前都必须采集足够多的有监督荧光图像训练集(即针对一生物样本需要采集若干该生物样本的高、低信噪比荧光图像数据对)。然而,在大多数荧光显微成像实验中,针对同一生物样本、特别是针对自身不断高速运动的活体生物样本采集高、低信噪比荧光图像数据对是一项耗时、耗力、甚至是无法完成的任务,这是因为如果活体生物样本本身运动速度很快的话,研究人员很难采集到生物结构形态完全一致的高、低信噪比荧光图像对,以供有监督学习的深度神经网络用。也就是说,现有的有监督学习去噪神经网络方法在大多数高速动态的活体生物结构的荧光显微成像观测中并不适用。
技术实现要素:
4.为解决上述问题,本技术旨在提出基于自监督学习的三维显微图像去噪方案,以使得无需像有监督学习去噪神经网络那样必须额外针对待去噪生物样本采集若干高、低信噪比荧光图像数据对,而仅需使用待去噪图像自身就可以实现去噪神经网络的训练和去噪处理,因此可以在几乎没有额外成本的条件下实现对现有的荧光显微成像系统进行改进,以提升三维显微图像数据的信噪比,从而延长活体生物样本的荧光显微成像的成像速度和时程。
5.根据本技术的一个方面,提供了一种自监督三维显微图像去噪方法,其在荧光显微成像系统中使用,所述荧光显微成像系统包括探测物镜,所述自监督三维显微图像去噪方法包括:
6.提供自监督三维显微图像去噪系统,所述自监督三维显微图像去噪系统包括计算机可读存储介质,其中存储有能够由计算机调用执行的去噪神经网络模型;
7.利用所述荧光显微成像系统的探测物镜采集体现生物样本、特别是活体生物样本的三维显微图像体栈;
8.使用所采集的荧光图像体栈对所述去噪神经网络模型进行自监督训练;
9.在所述去噪神经网络模型已经训练完毕的情况下,利用去噪神经网络模型对所采集的同一荧光图像体栈进行图像去噪处理。
10.可选地,所述荧光图像体栈由多个荧光图像层组成,相邻的荧光图像层之间沿着探测物镜的光轴方向的采样间距至少小于探测物镜的轴向分辨率的一半,即满足奈奎斯特采样定律。
11.可选地,所述自监督训练包括:
12.对所述荧光图像体栈进行数据扩增以获得n个尺寸为n
x
×
ny×
nz的扩增图像体栈,其中n为大于1的整数,x、y、z分别代表空间直角坐标系的三个轴x、y、z并且z轴与探测物镜的光轴重合或平行,尺寸的定义为x轴方向的像素数
×
y轴方向的像素数
×
z轴方向的图像层数,并且nz为偶数;
13.从所述n个扩增图像体栈中抽取m个扩增图像体栈,其中所述m为小于或等于n的整数;
14.在去噪神经网络模型的训练的每次迭代中,从所述m个扩增图像体栈中的每个扩增图像体栈中沿着z轴方向提取序号为奇数的图像层组成第一奇数层图像子体栈以及提取序号为偶数的图像层组成第一偶数层图像子体栈,以所述第一奇数层图像子体栈作为网络输入,以所述第一偶数层图像子体栈作为监督,基于预定的训练损失函数对所述去噪神经网络模型进行训练。
15.可选地,所述自监督训练包括:
16.对所述荧光图像体栈进行数据扩增以获得n个尺寸为n
x
×
ny×
nz的扩增图像体栈,其中n为大于1的整数,x、y、z分别代表空间直角坐标系的三个轴x、y、z并且z轴与探测物镜的光轴重合或平行,尺寸的定义为x轴方向的像素数
×
y轴方向的像素数
×
z轴方向的图像层数,并且nz为偶数;
17.从所述n个扩增图像体栈中抽取m个扩增图像体栈,其中所述m为小于或等于n的整数;
18.在去噪神经网络模型的训练的每次迭代中,从所述m个扩增图像体栈中的每个扩增图像体栈中沿着z轴方向提取序号为奇数的图像层组成第一奇数层图像子体栈以及提取序号为偶数的图像层组成第一偶数层图像子体栈,以所述第一偶数层图像子体栈作为网络输入,以所述第一奇数层图像子体栈作为监督,基于预定的训练损失函数对所述去噪神经网络模型进行训练。
19.可选地,在训练的每次迭代中,包括:
20.每个扩增图像体栈以无需计算梯度的方式被输入到所述去噪神经网络模型中,得到去噪后的完整图像体栈,并且将所述去噪后的完整图像体栈沿着z轴方向提取序号为奇数的图像层组成第二奇数层图像子体栈以及提取序号为偶数的图像层组成第二偶数层图像子体栈;
21.将相应的第一奇数层图像子体栈输入到所述去噪神经网络模型中,得到去噪后的第一奇数层图像子体栈;
22.以所述去噪后的第一奇数层图像子体栈和所述第一偶数层图像子体栈计算所述训练损失函数的自监督训练保真项;
23.以所述去噪后的第一奇数层图像子体栈、所述第一偶数层图像子体栈、所述第二
奇数层图像子体栈、和所述第二偶数层图像子体栈计算所述训练损失函数的偏差矫正正则项;
24.根据所述训练损失函数进行反向传播和网络权重更新,以完成依次训练迭代。
25.可选地,在训练的每次迭代中,包括:
26.每个扩增图像体栈以无需计算梯度的方式被输入到所述去噪神经网络模型中,得到去噪后的完整图像体栈,并且将所述去噪后的完整图像体栈沿着z轴方向提取序号为奇数的图像层组成第二奇数层图像子体栈以及提取序号为偶数的图像层组成第二偶数层图像子体栈;
27.将相应的第一偶数层图像子体栈输入到所述去噪神经网络模型中,得到去噪后的第一偶数层图像子体栈;
28.以所述去噪后的第一偶数层图像子体栈和所述第一奇数层图像子体栈计算所述训练损失函数的自监督训练保真项;
29.以所述去噪后的第一偶数层图像子体栈、所述第一奇数层图像子体栈、所述第二奇数层图像子体栈、和所述第二偶数层图像子体栈计算所述训练损失函数的偏差矫正正则项;
30.根据所述训练损失函数进行反向传播和网络权重更新,以完成依次训练迭代。
31.可选地,所述去噪神经网络模型包括但不限于u形神经网络模型、残差神经网络模型、残差通道注意力卷积神经网络模型、或傅立叶通道注意力卷积神经网络模型。
32.可选地,所述训练损失函数表示为:
[0033][0034]
其中,为自监督训练保真项,y表述数据扩增后的相应的图像体栈,分别表示奇数层图像子体栈和偶数层图像子体栈,表述神经网络运算,
[0035]
为偏差矫正正则项,其中,μ为偏差矫正正则项的权重。
[0036]
根据本技术的另一个方面,提供了一种自监督三维显微图像去噪系统,其在荧光显微成像系统中使用,所述荧光显微成像系统包括探测物镜,所述自监督三维显微图像去噪系统包括计算机可读存储介质,其中存储有能够由计算机调用执行的去噪神经网络模型以及计算机程序,所述计算机程序被计算机调用执行以完成如下步骤:
[0037]
使用由所述荧光显微成像系统的探测物镜的采集体现生物样本、特别是活体生物样本的三维显微图像体栈对所述去噪神经网络模型进行训练;和
[0038]
在所述去噪神经网络模型已经训练完毕的情况下,利用去噪神经网络模型对所采集的同一荧光图像体栈进行图像去噪处理。
[0039]
可选地,所述荧光图像体栈由多个荧光图像层组成,相邻的荧光图像层之间沿着探测物镜的光轴方向的采样间距至少小于探测物镜的轴向分辨率的一半,即满足奈奎斯特
采样定律。
[0040]
可选地,所述自监督训练包括:
[0041]
对所述荧光图像体栈进行数据扩增以获得n个尺寸为n
x
×
ny×
nz的扩增图像体栈,其中n为大于1的整数,x、y、z分别代表空间直角坐标系的三个轴x、y、z并且z轴与探测物镜的光轴重合或平行,尺寸的定义为x轴方向的像素数
×
y轴方向的像素数
×
z轴方向的图像层数,并且nz为偶数;
[0042]
从所述n个扩增图像体栈中抽取m个扩增图像体栈,其中所述m为小于或等于n的整数;
[0043]
在去噪神经网络模型的训练的每次迭代中,从所述m个扩增图像体栈中的每个扩增图像体栈中沿着z轴方向提取序号为奇数的图像层组成第一奇数层图像子体栈以及提取序号为偶数的图像层组成第一偶数层图像子体栈,以所述第一奇数层图像子体栈作为网络输入,以所述第一偶数层图像子体栈作为监督,基于预定的训练损失函数对所述去噪神经网络模型进行训练。
[0044]
可选地,所述自监督训练包括:
[0045]
对所述荧光图像体栈进行数据扩增以获得n个尺寸为n
x
×
ny×
nz的扩增图像体栈,其中n为大于1的整数,x、y、z分别代表空间直角坐标系的三个轴x、y、z并且z轴与探测物镜的光轴重合或平行,尺寸的定义为x轴方向的像素数
×
y轴方向的像素数
×
z轴方向的图像层数,并且nz为偶数;
[0046]
从所述n个扩增图像体栈中抽取m个扩增图像体栈,其中所述m为小于或等于n的整数;
[0047]
在去噪神经网络模型的训练的每次迭代中,从所述m个扩增图像体栈中的每个扩增图像体栈中沿着z轴方向提取序号为奇数的图像层组成第一奇数层图像子体栈以及提取序号为偶数的图像层组成第一偶数层图像子体栈,以所述第一偶数层图像子体栈作为网络输入,以所述第一奇数层图像子体栈作为监督,基于预定的训练损失函数对所述去噪神经网络模型进行训练。
[0048]
可选地,在训练的每次迭代中,包括:
[0049]
每个扩增图像体栈以无需计算梯度的方式被输入到所述去噪神经网络模型中,得到去噪后的完整图像体栈,并且将所述去噪后的完整图像体栈沿着z轴方向提取序号为奇数的图像层组成第二奇数层图像子体栈以及提取序号为偶数的图像层组成第二偶数层图像子体栈;
[0050]
将相应的第一奇数层图像子体栈输入到所述去噪神经网络模型中,得到去噪后的第一奇数层图像子体栈;
[0051]
以所述去噪后的第一奇数层图像子体栈和所述第一偶数层图像子体栈计算所述训练损失函数的自监督训练保真项;
[0052]
以所述去噪后的第一奇数层图像子体栈、所述第一偶数层图像子体栈、所述第二奇数层图像子体栈、和所述第二偶数层图像子体栈计算所述训练损失函数的偏差矫正正则项;
[0053]
根据所述训练损失函数进行反向传播和网络权重更新,以完成依次训练迭代。
[0054]
可选地,在训练的每次迭代中,包括:
[0055]
每个扩增图像体栈以无需计算梯度的方式被输入到所述去噪神经网络模型中,得到去噪后的完整图像体栈,并且将所述去噪后的完整图像体栈沿着z轴方向提取序号为奇数的图像层组成第二奇数层图像子体栈以及提取序号为偶数的图像层组成第二偶数层图像子体栈;
[0056]
将相应的第一偶数层图像子体栈输入到所述去噪神经网络模型中,得到去噪后的第一偶数层图像子体栈;
[0057]
以所述去噪后的第一偶数层图像子体栈和所述第一奇数层图像子体栈计算所述训练损失函数的自监督训练保真项;
[0058]
以所述去噪后的第一偶数层图像子体栈、所述第一奇数层图像子体栈、所述第二奇数层图像子体栈、和所述第二偶数层图像子体栈计算所述训练损失函数的偏差矫正正则项;
[0059]
根据所述训练损失函数进行反向传播和网络权重更新,以完成依次训练迭代。
[0060]
可选地,所述去噪神经网络模型包括但不限于u形神经网络模型、残差神经网络模型、残差通道注意力卷积神经网络模型、或傅立叶通道注意力卷积神经网络模型。
[0061]
可选地,所述训练损失函数表示为:
[0062][0063]
其中,为自监督训练保真项,y表述数据扩增后的相应的图像体栈,分别表示奇数层图像子体栈和偶数层图像子体栈,表述神经网络运算,
[0064]
为偏差矫正正则项,其中,μ为偏差矫正正则项的权重。
[0065]
采用本技术的上述技术手段,针对活体生物样本在某些实验条件下难以获取高、低信噪比训练图像对的问题,巧妙地利用了三维数据的空间连续性来进行自监督神经网络训练,从而仅需要使用待去噪的图像数据自身就可以完成去噪神经网络训练,极大地减轻了神经网络训练负担,特别适用于仅可以获得低信噪比的活体生物样本荧光图像的应用场合。
附图说明
[0066]
从下文的详细说明并结合下面的附图将能更全面地理解本技术的原理及各个方面。需要指出的是,各附图的比例出于清楚说明的目的有可能不一样,但这并不会影响对本技术的理解。在附图中:
[0067]
图1示意性示出了一个荧光显微成像系统的基本框图;
[0068]
图2示意性示出了自监督三维显微图像去噪系统或模块的一种示例神经网络架构;
[0069]
图3示意性示出了根据本技术的自监督三维显微图像去噪方法的示例流程图;
[0070]
图4示意性地展示了对根据本技术的自监督三维显微图像去噪系统或模块进行自监督训练的方法示例流程;以及
[0071]
图5示意性示出了与图4相对应的生物试样的荧光图像数据处理效果。
具体实施方式
[0072]
下面结合附图和实施例对本技术作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本技术,而非对本技术的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本技术相关的部分而非全部结构。在本技术实施例中使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本技术。
[0073]
图1示意性示出了一个荧光显微成像系统的基本框图,其大体上包括光学成像系统100以及控制与数据处理系统200。光学成像系统100包括激发光路以及探测光路,其中激发光路包括激发物镜及用于产生激发光的其他光学组件,激发光束可以透过所述激发物镜射出,以便在生物样本上激发出荧光,探测光路包括探测物镜及用于成像的其他光学组件,用于接收和探测所激发出的荧光。本领域技术人员应当清楚,根据荧光显微成像系统的配置,激发物镜与探测物镜可以是同一物镜或者是不同的物镜。在对生物样本、特别是活体生物样本进行三维荧光显微成像时,沿着探测物镜的光轴方向、即轴向连续扫描采样多层荧光图像,这样每完成一次扫描采样,所获取的多层荧光图像构成一个荧光图像体栈。
[0074]
控制与数据处理系统200主要包括计算机以及相关部件(例如数据存储器等),能够对光学成像系统100的操作进行控制并且能够从光学成像系统100接收图像数据并进行相应后期处理。例如,所获取的荧光图像体栈提供给控制与数据处理系统200,经过一系列数据处理重建为高信噪比三维显微图像。为此目的,控制与数据处理系统200可以包括自监督三维显微图像去噪系统或模块210以及重建系统或模块220。需要指出的是在本技术的范畴内,自监督三维显微图像去噪系统或模块210以及后续图像数据处理系统或模块220可以理解为包括数据存储器、例如计算机可读存储介质,在其中能够存储由计算机、特别是控制与数据处理系统200的计算机调用和运行的程序或子程序和去噪神经网络模型。这些程序或子程序和去噪神经网络模型在由计算机调用执行时能够实现如下所介绍的方法/步骤、特别是自监督三维显微图像去噪方法/步骤。针对程序和/或子程序的具体编程方式不在本技术的讨论之列,本领域技术人员能够以任何熟知的编程软件和/或商用软件来实现相关的功能。因此,本技术的下文在描述相关的系统或模块或方法时应当理解为它们也能够被编写为程序以由计算机调用并执行。
[0075]
本技术的独特之处在于在后续图像数据处理系统或模块220的上游设置自监督三维显微图像去噪系统或模块210。与现有技术的有监督去噪措施不同的是,本技术中的自监督三维显微图像去噪系统或模块210无需利用由多组高、低信噪比荧光图像数据对组成的有监督荧光图像训练集进行训练,而仅需利用对生物样本的一次性连续扫描采样的荧光图像体栈就可以完成训练。此外,自监督三维显微图像去噪系统或模块210主要配置成对由光学成像系统100所采集的体现生物样本、特别是活体生物样本的三维荧光图像体栈利用去噪神经网络进行去噪处理。后续图像数据处理系统或模块220配置成接收由自监督三维显微图像去噪系统或模块210输出的去噪后的荧光图像体栈,并利用合适的算法进行用于实现生物试样三维观测的后续数据处理,例如三维去卷积计算等。
[0076]
本领域技术人员应当清楚,自监督三维显微图像去噪系统或模块210中的去噪神经网络模型可以选用任何一种具有图像处理功能的神经网络架构,包括但不限于u形神经网络模型、残差神经网络模型、残差通道注意力卷积神经网络模型、或傅立叶通道注意力卷积神经网络模型等。
[0077]
图2示意性示出了自监督三维显微图像去噪系统或模块210的一种示例神经网络架构。例如,所述示例神经网络架构包括首尾两个卷积-激活模块以及中间串联的残差模块,残差模块前后也增设一个跳跃链接(skip connection)来提升网络训练的稳定性。每个残差模块内部由原则上应由若干卷积-激活模块、跳跃链接、或通道注意力模块等元素构成,网络结构并非本技术的重点,在此不做过多细节描述,且本领域技术人员可以理解,对网络结构进行部分替换、重新调整不会显著影响其功能,在不脱离本技术构思的情况下,还可以包括更多其他等效的网络结构实施方案。
[0078]
可以理解的是,图2示出的卷积神经网络结构可以有效地提取荧光图像中的生物样本信息,并最终完成对图像进行去噪的任务。但本领域技术人员可以理解,对所述卷积神经网络结构进行部分替换、重新调整并不会显著影响其功能,且所述卷积神经网络结构并非唯一可以实现此目标的网络结构。当然,本领域技术人员应当清楚,任何可以实现此功能的其它合适的网络架构均可作为自监督三维显微图像去噪系统或模块210。
[0079]
图3示意性示出了根据本技术的自监督三维显微图像去噪方法的示例流程图,其中所述方法在上述荧光显微成像系统中使用,并且特别地利用自监督三维显微图像去噪系统或模块210来执行。
[0080]
在步骤s10,利用光学成像系统100,在生物样本、特别是活体生物样本已经受到光激发而产生荧光的前提下,对生物样本、特别是活体生物样本进行一次性连续扫描采样,以获取体现其三维荧光显微图像信息的荧光图像体栈。在本技术的范畴内,一次性连续扫描采样意味着仅固定光学成像系统100的相关成像参数利用其探测物镜对受激发而发出荧光的生物样本进行图像扫描采样。应当清楚的是,所采集的荧光图像体栈由多层(二维)荧光图像组成,并且各个荧光图像层沿着轴向(即沿着探测物镜的光轴方向)的采样间距满足奈奎斯特采样定律,即所述采样间距至少小于探测物镜的轴向分辨率的一半。这样做的原因在于确保(体现所述生物试样的三维荧光显微图像信息的)荧光图像体栈在轴向上的空间连续性,从而确保本技术的自监督三维显微图像去噪方法的可实施性以及有效性。
[0081]
在步骤s20,利用所采集的荧光图像体栈对自监督三维显微图像去噪系统或模块210进行自监督训练(如下详述)。
[0082]
在步骤s30,利用训练好的自监督三维显微图像去噪系统或模块210对在步骤s10中所采集的荧光图像体栈进行去噪处理。根据本技术,针对同一活体生物样本或者同一类活体生物样本,可以在对自监督三维显微图像去噪系统或模块210训练合格后,后续无需再对所述同一活体生物样本或者所述同一类活体生物样本进行训练即可直接使用进行荧光图像体栈去噪。在一优选的实施例中,针对同一活体生物样本或者同一类活体生物样本所再次采集的荧光图像体栈,仍可以使用本技术的自监督三维显微图像去噪方法,即对已经前一次已经训练好的自监督三维显微图像去噪系统或模块210再次进行训练(系统或模块微调),并且利用再次训练好的自监督三维显微图像去噪系统或模块210对荧光图像体栈进行去噪处理。本领域技术人员应当清楚,这种微调的训练时间将会缩短并且最终的去噪效
果因反复训练而将会更加优异。
[0083]
图4示意性地展示了根据本技术对自监督三维显微图像去噪系统或模块210进行自监督训练的方法示例流程。在本技术的范畴中,自监督训练是与现有技术的有监督训练相对的概念,指的是为了训练神经网络无需额外采集训练集(例如高、低信噪比的荧光图像数据对),而仅仅需要使用待去噪的荧光图像数据本身即可实现神经网络的训练以及后续的去噪处理。
[0084]
首先,在步骤s21,将在步骤s10所采集的荧光图像体栈进行数据扩增。在本技术的范畴中,对图像进行数据扩增是指对图像不实际增加原始数据,而仅仅对图像做一些特定的变换从而创造出更多的图像数据。因此,这里提及的数据扩增的方式包括但不限于:随机剪裁、随机角度旋转、随机反转、随机弹性形变等。例如,针对一个荧光图像体栈中的随机抽取的多个图像层或每个图像层随机进行剪裁、角度旋转、反转、弹性形变等变换。
[0085]
因此,在步骤s21中,荧光图像体栈被数据扩增为n个尺寸为n
x
×
ny×
nz的图像体栈,其中n为大于1的整数,x、y、z分别代表空间直角坐标系的三个轴x、y、z并且z轴与探测物镜的光轴重合或平行,尺寸的定义为x轴方向的像素数
×
y轴方向的像素数
×
z轴方向的图像层数,因此n
x
×
ny不会大于在步骤s10所采集的荧光图像体栈的任何一个图像层的xy尺寸,并且nz取偶数。
[0086]
在步骤s22中,从n个数据扩增后的图像体栈随机选取m个图像体栈,其中m为小于或等于n的整数。
[0087]
在步骤s23中,将m个图像体栈中的每个图像体栈沿着z轴拆分为第一奇数层图像子体栈以及第一偶数层图像子体栈。也就是说,从相应的一个图像体栈(如图5中的区段20.1所示)的所有图像层中,顺序抽取出序号为奇数的图像层组成第一奇数层图像子体栈(如图5中的区段20.2所示),顺序抽取出序号为偶数的图像层组成第一偶数层图像子体栈(如图5中的区段20.3所示)。
[0088]
在步骤s24中,将第一奇数层图像子体栈(如图5中的区段20.2所示)输入自监督三维显微图像去噪系统或模块210的神经网络,得到去噪后的第一奇数层图像子体栈(如图5中的区段20.7所示)。
[0089]
在步骤s25中,将相应的一个图像体栈(如图5中的区段20.1所示)输入自监督三维显微图像去噪系统或模块210的神经网络,得到一个去噪后的完整图像体栈(如图5中的区段20.4所示),在该步骤s25中,去噪的过程无需计算梯度。
[0090]
在步骤s26中,将步骤s25中得到的去噪后的完整图像体栈以类似于步骤s23中描述的方式沿着z轴拆分为第二奇数层图像子体栈(如图5中的区段20.5所示)以及第二偶数层图像子体栈(如图5中的区段20.6所示)。
[0091]
在步骤s27中,利用去噪后的第一奇数层图像子体栈(如图5中的区段20.7所示)和未去噪的第一偶数层图像子体栈(如图5中的区段20.3所示)计算损失函数中的自监督训练保真项(如下所述)。
[0092]
在步骤s28中,利用去噪后的第一奇数层图像子体栈(如图5中的区段20.7所示)、未去噪的第一偶数层图像子体栈(如图5中的区段20.3所示)、去噪后的第二奇数层图像子体栈(如图5中的区段20.5所示)、和去噪后的第二偶数层图像子体栈(如图5中的区段20.6所示)计算损失函数中的偏差矫正正则项(如下所述)。
[0093]
然后,根据损失函数进行反向传播和网络权重更新,完成一次训练迭代。本领域技术人员应当清楚,针对m个图像体栈中的每个图像体栈相应进行循环演进即可完成神经网络训练。
[0094]
在本技术的实施例中,自监督训练保真项和偏差矫正正则项均使用均方误差(mse),因此整个神经网络的损失函数可以表示为:
[0095][0096]
其中,为自监督训练保真项,y表述数据扩增后的相应的图像体栈,分别表示奇数层图像子体栈和偶数层图像子体栈,表述自监督三维显微图像去噪系统或模块210的神经网络运算。自监督训练保真项可选用均方误差(mse)、平均绝对误差(mae)或者他们二者的加权组合,用于确保网络输出图像的保真度。
[0097]
在上述损失函数中的另一项为偏差矫正正则项,其中,μ为偏差矫正正则项的权重,其余符号的含义与自监督训练保真项中的上述说明相同。偏差矫正正则项同样可选用均方误差(mse)、平均绝对误差(mae)或者他们二者的加权组合,用于抵消保真项中与两项之差的期望不为0对训练过程造成的影响,实际处理中可以起到抵消网络输出图像体栈的轴向偏移、提升输出图像分辨率的效果。
[0098]
或者说,上述整个神经网络的训练损失函数也可以表述为:
[0099][0100]
其中,||
·
||2表示二范数,即均方根运算符,其它符号与如上说明相同。
[0101]
特别地,可由损失函数的公式推导得出所述偏差矫正正则项的期望为0的结论如下:
[0102][0103]
因此,这就可以证明本技术中偏差校正正则项的合理性和有效性。
[0104]
本领域技术人员应当清楚,在图4所示的方法步骤中,涉及奇数层和偶数层的术语可以相应地颠倒,自监督训练过程同样适用。
[0105]
利用本技术的自监督去噪方法或系统,针对活体生物样本在某些实验条件下难以获取高、低信噪比训练图像对的问题,巧妙地利用了三维数据的空间连续性来进行自监督神经网络训练,从而仅需要使用待去噪的图像数据自身就可以完成去噪神经网络训练,极
大地减轻了神经网络训练负担,特别适用于仅可以获得低信噪比活体生物样本的荧光图像的应用场合。此外,本技术的自监督去噪方法或系统也可以方便地对现有的荧光显微成像系统进行升级改造,例如通过软件升级的方式进行升级改造,以使得现有的荧光显微成像系统获得自监督三维荧光图像去噪功能。
[0106]
注意,上述仅为本技术的较佳实施例及所运用技术原理。本领域技术人员会理解,本技术不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本技术的保护范围。因此,虽然通过以上实施例对本技术进行了较为详细的说明,但是本技术不仅仅限于以上实施例,在不脱离本技术构思的情况下,还可以包括更多其他等效实施例,而本技术的范围由所附的权利要求范围决定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1