一种用于神经网络推理加速的低功耗浮点乘累加运算方法
1.本公开属于处理器和计算技术领域,特别涉及一种用于神经网络推理加速的低功耗浮点乘累加运算方法。
背景技术:
2.随着人工智能算法的突破,以深度卷积神经网络为代表的推理算法广泛应用于各行各业。然而深度卷积神经网络对算力的需求极高,传统的cpu无法提供足够的算力;gpu虽然能够提供足够的算力,但性能功耗比太低,并不是移动端设备的最佳选择。
3.学术界和工业界提出了大量专用的神经网络加速器npu来解决上述问题。深度卷积神经网络对数据精度不敏感,在良好的量化算法支持下,采用定点运算可以在数据动态范围不大的情况下实现接近浮点的精度。npu设计按照运算数据精度可以划分为2种类型:一种是处理浮点数据的神经网络加速器,以英伟达公司的移动端gpu为代表,虽然其网络部署方便,但是功耗指标不理想;另一种是处理定点数据的神经网络加速器,由于采用定点运算代替复杂的浮点运算,其性能功耗比非常高,但是网络部署时必须经过专门的量化过程,且精度和动态范围受限。
4.因此,如何平衡神经网络加速器采用浮点运算的精度优势与采用定点运算的能量优势,是一个亟待解决的关键问题。
技术实现要素:
5.鉴于此,本公开提供了一种用于神经网络推理加速的低功耗浮点乘累加运算方法,其特征在于:
6.通过对输入的浮点数进行预处理,在计算前对小数部分进行舍入并调整其指数位,对可能会被舍入的数据进行预先的舍入和规整,省去对不必要精度的计算。同时,为了累加电路能够快速执行,采用科学技术法表示的指数的小数部分放弃原有的原码表示方法,转而采用补码表示方法。
7.优选的,
8.所述方法的方案1具体为:
9.对于a组数据的指数位序列(n0,n1,...n7),取其中的最大值n=max(n0,n1,...n7),为a组数据的统一指数位。近似后的a组数据用表示,中的每个数据为:
[0010][0011]
其中αi是根据统一的指数位n,将ai向右移位得到的。针对每个ai,需要右移的位数为ηi,而ηi=n-ni;
[0012]
在较为极端的情况下,当ηi≥8时,αi会因为移位变为0;
[0013]
对于每个ai,都有ηi位的数据被直接舍弃;
[0014]
同理,对数组w也做相同处理,近似后的数组为同理,对数组w也做相同处理,近似后的数组为中的每个数据为:
[0015][0016]
其中m=max(m0,m1,...m7),ωi是根据m将wi向右移μi位得到的,其中,μi=m-mi;
[0017]
在转换后,αi和ωi均为8bit整型数据,可以送入mac阵列进行计算;
[0018]
设定点乘法部分得到的结果为
[0019][0020]
对于该公式中的i=1,2...7的8项求和,由于是定点加法,故使用华莱士树加法器和一个定点加法器得到;
[0021]
最后,将小数部分的计算和指数部分的运算处理结合:
[0022]
设定点乘法输出序列为数组则数组中每个数为:
[0023][0024]
由于得到的数组的指数统一,故可以直接使用定点加法器进行加和。设得到的结果为于是有:
[0025][0026]
所述方法仅在一组乘加操作的最后才进行归一化运算,乘法部分和加法部分都可以节省很多资源;
[0027]
所述方法对数据进行了预处理,在两个需要乘积的数组进入乘法阵列前,就确定了各自组的指数。
[0028]
优选的,
[0029]
如果等两个数组进入乘法阵列后,即在同时得到两组数据的指数位信息后,再来共同确定计算结果的指数,这样就可以提高计算结果的精度,具体为:
[0030]
将两数组对应乘积数的指数先相加,找出其中的最大值:
[0031]
n=max(ni)=max(ni+mi)
[0032]
设ni中的最大值为n,n就是最后乘积结果的指数;根据调整后的指数移位时,只对w组的小数wi进行移位,a组数保持不变;设wi需要向左移动的位数为μi,则:
[0033]
μi=n-n
i-mi[0034]
μi得到后,其余后续的操作和上述方案1相同;
[0035]
相比权利要求2,最终得到的近似结果为:
[0036][0037]
由此,本公开实现了一种用于神经网络推理加速的低功耗浮点乘累加运算方法,以及一种应用于端侧神经网络推理加速器的矩阵乘累加运算电路。本公开利用乘累加运算的特点,使用消耗资源较少的定点运算资源实现接近浮点运算的精度,从而解决了神经网络推理过程中计算精度与硬件实现复杂度的平衡问题。
附图说明
[0038]
图1是现有技术中浮点数的数据构成的示意图;
[0039]
图2是现有技术中,使用标准浮点乘法器计算的示意图;
[0040]
图3是现有技术中,标准浮点加法器的示意图;
[0041]
图3a是根据现有技术中的方法所实现的一种电路的示意图;
[0042]
图4是本公开一个实施例中,应用的华莱士数加法器示意图;
[0043]
图5是本公开一个实施例中,方案一的计算流程示意图;
[0044]
图6是本公开一个实施例中,方案二的计算流程示意图;
[0045]
图7是本公开一个实施例中,方案一在定点mac阵列中的应用示意图;
[0046]
图8是本公开一个实施例中,方案二在mac阵列中的应用示意图。
具体实施方式
[0047]
为使本公开实施方式的目的、技术方案和优点更加清楚,下面将结合本公开实施方式对本公开实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本公开一部分实施方式,而不是全部的实施方式。基于本公开中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本公开保护的范围。
[0048]
因此,以下对在附图中提供的本公开的实施方式的详细描述并非旨在限制要求保护的本公开的范围,而是仅仅表示本公开的选定实施方式。基于本公开中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本公开保护的范围。
[0049]
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
[0050]
在本公开的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”、“顺时针”、“逆时针”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本公开和简化描述,而不是指示或暗示所指的设备或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本公开的限制。
[0051]
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本公开的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
[0052]
在本公开中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本公开中的具体含义。
[0053]
在本公开中,除非另有明确的规定和限定,第一特征在第二特征之“上”或之“下”可以包括第一和第二特征直接接触,也可以包括第一和第二特征不是直接接触而是通过它们之间的另外的特征接触。而且,第一特征在第二特征“之上”、“上方”和“上面”包括第一特征在第二特征正上方和斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”包括第一特征在第二特征正下方和斜下方,或仅仅表示第一特征水平高度小于第二特征。
[0054]
下面详细描述本公开。
[0055]
1.本公开的总构思在于:
[0056]
本公开公开了一种应用于端侧神经网络推理加速器的矩阵乘累加运算电路,利用乘累加运算的特点,使用消耗资源较少的定点运算资源实现接近浮点运算的精度,从而解决了神经网络推理过程中计算精度与硬件实现复杂度的平衡问题。
[0057]
2.技术方案
[0058]
2.1由来
[0059]
现针对神经网络中最常见的乘累加运算为例进行说明。按照现有技术的传统解决方案,用于进行乘累加的两个浮点数组分别为a和w,以a组数据为例,示例性的,a组数据共包含8个数,且每个数据都是用bf16的格式表示的浮点数。
[0060]
在a组数据中,第i个数据的符号位记为si,占1bit;指数位记为ni,占8bit;小数位记为mi,占7bit。其中i=0,1,...7。第i个数据的构成如图1所示,在进行乘法计算时,将两个被乘数的符号位做异或运算可以直接得到结果的符号位。所以我们更关心指数和小数部分的运算法则。记a组数据中剔除符号位的第i个数为ai(i=0,1,...7)。
[0061]
浮点数按照表示形式,可以分为规则数、非规则数。他们均可以使用科学计数法进行表示。规则数可以表示为如下形式:
[0062][0063]
非规则数中非无穷数可以表示为如下统一的形式:
[0064][0065]
表示无穷的数需要专门标记。
[0066]
针对a组数据的无符号部分,将会有:
[0067][0068]
在二进制中,底数e=2,也就是将ai向左移ni位。
[0069]
对于w组同理。符号位记为指数位记为mi,小数位记为wi,剔除符号位的数据用wi表示。
[0070][0071]
现今的各种算法中常常会使用到卷积或矩阵乘等运算。通常情况下可以将这些复杂运算细化为大量各式的向量内积运算。如果将a组数据和w组数据均视为向量。现在我们需要计算他们的内积s,也就是对a和w组的数据做乘累加运算。计算结果s的准确结果应为:
[0072][0073]
公式(3)中的是在本文中为了方便数学表示采取的一个符号标记。
[0074][0075]
记a组和w组数据的第i位的符号位的异或结果为于是有于是有符号在这里表示逻辑异或运算。时,说明结果为正,反之,时,结果
为负,
[0076]
2.2通用计算方法
[0077]
如果按照传统标准方法对公式(3)进行实现,按照通用的ieee754标准,需要使用8个浮点乘法器和7个浮点加法器。
[0078]
每个ieee754标准的乘法器如图2所示。两个数的符号部分异或,指数部分加和,小数部分相乘。
[0079]
由于乘积操作可能会产生进位或移位,需要对乘积得到的数进行规整化操作,将其转化为标准浮点数。但该标准浮点数的位宽可能不符合输出要求,还需要对其精度进行舍入操作。然而舍入操作也有可能会产生进位移位,所以,舍入后需要再进行一次规整化。
[0080]
其中,每次规整化还包括“寻找最高有效位(counting leading zero)”、“小数位移位”和“指数位调整移位”三次操作。
[0081]
浮点乘法需要调用1个定点乘法实现小数部分的乘积,需要1个低bit加法器实现指数部分的乘积,需要2组比较器和移位器实现乘积结果的移位与舍入运算。
[0082]
参见图2,其示意了使用标准浮点乘法器计算。
[0083]
使用标准乘法器计算后,得到8个浮点数结果,将这8个数用数组c表示。由于数组c共8个数,全部累加需要使用7次加法。同时得到的数组c的各指数不统一,因此在相加时需要使用浮点加法器。
[0084]
每个浮点加法器的大致流程如图3所示。浮点加法的指数位需要先进行比较,找出其中较大的值,将较大的指数位会被作为预定指数。将较小指数位对应的小数位将会被移位,移位调整至和较大指数位相同,移动位数就是指数差。由此,就能得到两指数位相同的浮点数。这两个数作带符号的定点加法运算。后续操作和浮点乘法类似,还需要执行规整化,舍入,再规整化的操作。浮点加法器需要调用1个比较器和一个1个移位器实现输入数据的整理,调用1个定点加法器实现小数部分的求和运算,调用1个clz逻辑、2组比较器和2个移位器实现数据的归一化与舍入运算。
[0085]
七次累加完成后,可以得到最终结果s。
[0086]
参见图3所示标准浮点加法器,现总结通用计算方法的步骤如下:
[0087]
s100:分别从组a和组w中取出一对浮点数和使用浮点乘法器进行计算,得到浮点数ci。
[0088]
s200:重复s100,直到将组a和组w中的数据全部计算完,得到数组c。在本例中,组中有8个数据,需要重复8次。该8次操作可以是并行发生的,如图2所示。
[0089]
s300:使用浮点加法器将数组c累加,得到计算结果为浮点数s。在本例中,数组c的8个数累加需要进行7次浮点加法操作。
[0090]
于是,一个如公式(3)的运算,需要使用8个浮点乘法器和7个浮点加法器。若将上述步骤使用电路实现,整体的结构关系如图3a所示。
[0091]
本公开在具体介绍其具体实施例之前,仅粗略介绍现有技术、通用计算方法及其实现,不对现有技术中通用方法的具体电路结构关系描述,仅用于示意而已。重点在于将现有技术与本公开所揭示的方案进行对比。现总结现有技术的通用计算方法所实现的电路的硬件资源消耗如表1所示:
[0092]
表1
[0093][0094]
可以看到,在使用通用方式进如公式(3)类型的计算时,在计算前后会多次对数据进行舍入操作。实际上,该通用方法对可能会舍入的数据仍然进行了标准的高精度计算。此类不必要的计算浪费了大量的硬件资源并占用一定运行时间。
[0095]
2.3快速浮点算法方案一
[0096]
鉴于使用通用方法计算会消耗大量的硬件资源并且拖延运行速度,本公开公开一种节省资源的乘累加器。现针对公式(3)类型的计算,设计了一种简易快速的浮点向量内积的近似计算方法。该方法在硬件上以定点mac阵列(定点累乘加计算阵列)为基础,做出较小的硬件改动,使该阵列能够兼容浮点运算。
[0097]
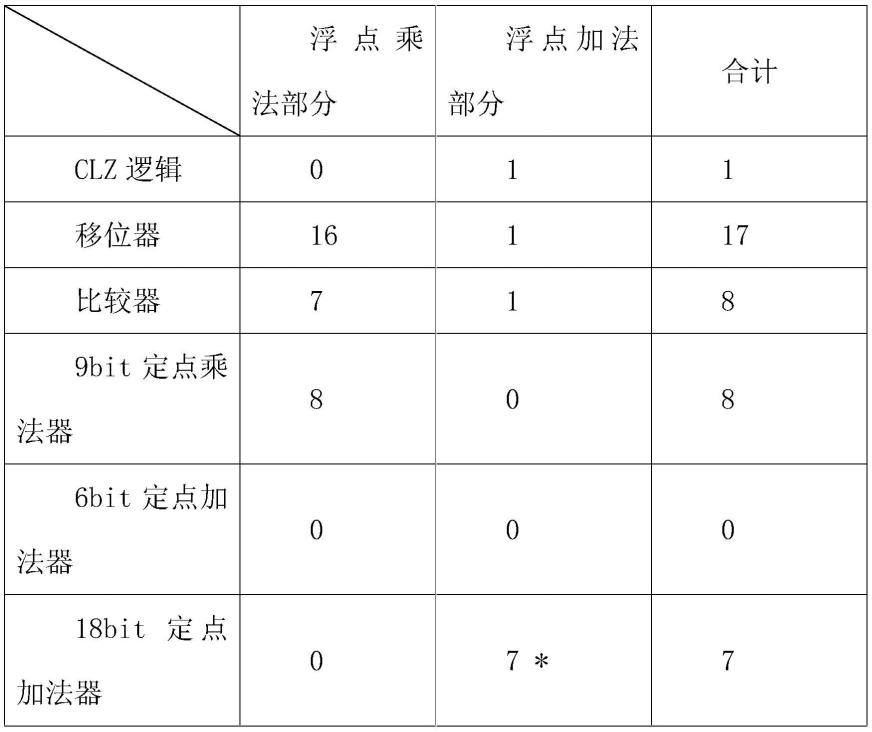
设计的简化算法的关键思路为:通过对输入的浮点数进行预处理,采用补码形式的定点乘累加运算来替代浮点运算,从而实现更高速度、更低功耗的近似浮点运算。在计算前对小数部分进行舍入并调整其指数位,对可能会被舍入的数据进行预先的舍入和规整,省去对不必要的精度数据的计算。同时,为了累加电路能够快速执行,采用科学技术法表示的指数的小数部分放弃原有的原码表示方法,转而采用补码表示方法,从而为实现大规模乘累加运算提供支持。
[0098]
值得注意的是,用于乘累加运算的定点数据采用补码形式,而不采用浮点数据原生的原码形式。这种做法有助于减小定点运算的资源开销,并且具有更大的取指范围。
[0099]
具体操作及方法如下:
[0100]
对于a组数据的指数位序列(n0,n1,...n7),取其中的最大值n=max(n0,n1,...n7),
为a组数据的统一指数位。近似后的a组数据用表示,和的每个数据为:
[0101][0102]
其中αi是根据统一的指数位n,将ai向右移位得到的。针对每个ai,需要右移的位数为ηi,而ηi=n-ni。在较为极端的情况下,当ηi≥8时,αi会因为移位变为0。
[0103]
可以看到,对于每个ai,都有ηi位的数据被直接舍弃。这些被舍弃的位数可能会带来一些精度上的损失,但被舍弃的位数将不会参与到后续的乘积加和等运算,也让我们省略了后续的舍入和规整化等操作。该方法产生的精度损失,会在稍后单独讨论。
[0104]
同理,对数组w也做相同处理,近似后的数组为也做相同处理,近似后的数组为中的每个数据为:
[0105][0106]
其中m=max(m0,m1,...m7),ωi是根据m将wi向右移μi位得到的。其中,μi=m-mi。
[0107]
在转换后,αi和ωi均为8bit整型数据,可以送入mac阵列进行计算。设定点乘法部分得到的结果为
[0108][0109]
然后,对于公式(7)中的i=1,2...7的8项求和。由于是定点加法,可以使用华莱士树加法器和一个定点加法器得到。华莱士树加法器如图4所示,即本例中应用的华莱士数加法器。
[0110]
最后,将小数部分的计算和指数部分的运算处理结合。
[0111]
设定点乘法输出序列为数组则数组中每个数为:
[0112][0113]
由于得到的数组的指数统一,故可以直接使用定点加法器进行加和。设得到的结果为于是有:
[0114][0115]
针对方案一的流程示意图如图5所示:
[0116]
若令两组待处理的浮点数分别为和和综上,现总结方案一的步骤如下:
[0117]
s100:分别取指数位ni和mi中的最大值,得到的最大值分别为n和m。
[0118]
s200:将小数位ai和wi分别进行移位,得到αi和ωi。针对每个ai,需要右移的位数为ηi,而ηi=n-ni。同理,针对每个wi,需要右移的位数为μi,而μi=m-mi。结合s100,可以用式(5)和式(6)表征现阶段结果。
[0119]
s300:直接将n和m相加,得到计算结果的指数位。
[0120]
s400:将每对αi和ωi都进行定点乘法操作,得到αiωi。将每对符号位和都做异或运算,得到此时得到式(7)中结果
[0121]
s500:将送入华莱士树加法器计算得到计算结果的小数位和符号位。由此,结合s300中得到的指数位,得到最终结果为浮点数即式(9)中结果。
[0122]
其中s100和s200可以被看做预处理部分,可以在数据送入计算单元pe前执行。而其余步骤则必须放在pe计算单元中执行。
[0123]
s400到s500为定点累乘加运算步骤。而s300为定点累乘加需要额外集成的步骤。
[0124]
2.4快速浮点算法方案二
[0125]
方案一是对数据进行了预处理,在两个需要乘积的数组进入乘法阵列前,就确定了各自组的指数。如果等两个数组进入乘法阵列后,即在同时得到两组数据的指数位信息后,再来共同确定计算结果的指数,这样就可以提高计算结果的精度。
[0126]
具体做法为:
[0127]
将两数组对应乘积数的指数先相加,找出其中的最大值。
[0128]
n=max(ni)=max(ni+mi)
ꢀꢀ
(10)
[0129]
设ni中的最大值为n,n就是最后乘积结果的指数。根据调整后的指数移位时,只对w组的小数wi进行移位,a组数保持不变。设wi需要向左移动的位数为μi,则:
[0130]
μi=n-n
i-miꢀꢀ
(11)
[0131]
其余部分的方法操作和方案一相同,得到的近似结果为:
[0132][0133]
方案二的计算流程示意图如图6所示:
[0134]
若令两组待处理的浮点数分别为和和综上,现总结方案二的步骤如下:
[0135]
s100:将两组数据的指数位ni和mi对应相加得到ni,再求ni的最大值,得到n。n直接作为计算结果的指数位。
[0136]
s200:将小数位wi进行移位,得到ωi。针对每个wi,需要右移的位数为μi,而μi=n-mi。对小数位ai不做移位处理。
[0137]
s300:将每对ai和ωi都进行定点乘法操作,得到aiωi。将每对符号位和都做异或运算,得到
[0138]
s400:将送入华莱士树加法器计算得到计算结果的小数位和符号位。由此,结合s300中得到的指数位,得到最终结果为浮点数即式(12)中结果。
[0139]
方案二中不存在预处理部分,所有步骤则必须放在pe计算单元中执行。本方案中s300和s400与方案一中s400到s500相同,可看作定点累乘加步骤。若以定点累成加单元作为扩展,在方案二中s100和s200需要被集成到计算单元中。
[0140]
3其他实施例
[0141]
需要说明的是,本公开的设计思路为,针对已有的定点乘累加mac阵列,扩展部分硬件并修改,使其能够完成浮点运算。使用本公开得到的浮点运算电路,与定点乘累加运算电路高度复用,在保证损失精度较小的前提下,可以高效的完成浮点运算。
[0142]
3.1方案一在定点mac阵列中的应用
[0143]
本方法中所使用的的运算资源与定点累加器mac阵列中的所使用的运算资源高度重合。如图7所示,绿色部分是定点mac阵列中以及使用的运算资源。在图7中可以看到,用于处理浮点数据的附加运算单元大多在预处理部分执行,故不需要对定点mac阵列做过多的修改。针对每一对执行浮点累乘加的数组,只需要在mac阵列中增加指数加和单元即可。
[0144]
如图7所示,使用方案一对mac阵列扩展,得到浮点运算电路。
[0145]
图7各模块功能及连接方式介绍如下:
[0146]
连接方式:
[0147]
实线单箭头:表示向后传递一个多比特数据。示例:
→
[0148]
空心粗箭头:表示向后传递一组多比特数据。示例:
[0149]
本例中,一组数据有i=8个,用角标的形式表示。如ni表示一组n
0,1,2...7
一组共8个数据。
[0150]
模块介绍:绿色阴影部分:图中绿色部分是已有的定点mac阵列的一个pe计算单元。它可以完成对8个定点数的乘累加操作,输出为一个定点数,代表得到的乘累加结果。一个pe计算单元中包含8个定点乘法器,可以同时完成8对有符号定点数的乘积操作。此外还包括华莱士树加法器和一个定点加法器,用于对乘法器产生的8个乘积数进行快速加和。而mac阵列则是64个这样的pe单元组成的,用于并行快速计算定点的矩阵以及向量乘法运算。
[0151]
max:从传递而来的数据中找出最大值输出。
[0152]
加和:一个定点加法运算。
[0153]
移位:表示将框图左侧的数据向右移位,在右侧将移位后的数据输出,移位的位数从框图上方输入。
[0154]
a&w两组浮点数:整个电路的输入,输入包含两组浮点数和
[0155]
整个电路的输出,表示为一个浮点数同样由小数、浮点和指数部分组成,是公式(3)的近似解。
[0156]
其余字母标识为电路计算的中间变量,参见前文2.3等。
[0157]
预处理部分的两数组移位,指数取最值等操作可以在进入mac阵列之前执行。相较于定点乘累加运算,浮点运算预处理阶段可以被划分为额外的流水线的阶段。这样,浮点运算可以获得和定点运算接近相同的硬件消耗,运算流水以及运算周期。
[0158]
为了利用这样的定点mac阵列完成浮点运算,我们需要对每个pe计算单元做相关修改。
[0159]
方案一如图7所示,在红色虚线左侧的电路可以看作数据预处理电路,它们可以分布在mac阵列之外。而在预处理之后,可以看到相比定点运算,只增加了指数部分的相加操作。所以,mac阵列中的每个pe单元只需要增加指数位的数据端口,并增加一个定点加法器即可。
[0160]
如图所示,在数据进入mac阵列之前,即预处理部分需要增加的电路有:
[0161]
最值寻找:两个取最值操作。在图中,两组数据的该操作用max框格表示。用于在待运算数据的组内,寻找指数最大值,取该最大值为该组数据的统一指数。
[0162]
确定移位数:两组共16个加法器。在图中,两组数据的该操作分别用μ_i和η_i框格表示。用于根据组的统一指数位对数据的小数位进行移位。移位数为统一指数位减去数据原本的指数位。这里使用加法器实现移动位数计算。
[0163]
移位:两组共16个移位操作。用于根据得到的需要的移位数,对数据的小数位进行
移位。
[0164]
由于该方案仅在一组乘加操作的最后才进行归一化运算,乘法部分和加法部分都可以节省很多资源。每个乘法调用2个移位器和1个定点乘法器,整体乘法部分有7个比较器用于选择指数最大的值。加法部分仅在最终结果进行归一化处理。该实现方案的硬件资源消耗情况如下图所示:
[0165]
表2:方案一硬件资源消耗表
[0166][0167]
*由于定点数连加可以采用华莱士树加法器进行化简,其硬件资源和时序小于7个独立的全加器。
[0168]
3.2方案二在定点mac阵列中的应用
[0169]
方案二是在数据均进入mac后,再做量化小数以及指数比较操作,这样得到的结果会精度更高,但需要对定点mac阵列的改动也就更大。如图8所示,图中右下角区域的深色阴影部分为定点mac阵列。如果想要使用方案二在定点mac阵列中,必须对mac阵列做出较大的改动。如图8所示,需要将数据小数移位、指数比较找其最大值等操作全部放在mac阵列当中。
[0170]
方案二的电路结构如图8所示。其大部分具体模块和连接方式的表示在方案一的具体实施例中已经介绍。
[0171]
方案二额外引入的模块有:
[0172]
ni=ni+mi[0173]
定点加和运算,执行计算ni=ni+mi。
[0174]
这样相比方案一的精度会更高,但硬件消耗以及延迟可能会更大。
[0175]
如图所示,使用方案二对mac阵列扩展,得到浮点运算电路。
[0176]
方案二和方案一的不同之处在于,方案二的指数处理部分全部是在pe单元中进行的。于是方案二中没有数据预处理部分,按照方案二设计的pe单元,可以直接对浮点数进行操作。
[0177]
如图,图中的绿色部分和方案一中的相同,是定点mac阵列中的pe单元。由于没有数据预处理部分,额外的浮点处理需要全部被集成到pe单元中。
[0178]
pe单元中需要额外被集成的电路有:
[0179]
指数相加:8个定点加发器。在图中用框格ni=ni+mi表示。计算出两组数据中对应数据的指数和。
[0180]
最值寻找:一个取最值操作。在图中该操作用max框格表示。用于在上一步所求的指数和中,寻找出指数最大值,取该最大值为计算结果的指数。
[0181]
确定移位数:一组共8个加法器。在图中,两组数据的该操作分别用μi框格表示。用于根据确定的结果指数位对其中一组数据的小数位进行移位。移位数为结果指数位减去数据原本的指数位。这里使用加法器实现移动位数计算。
[0182]
移位:一组共8个移位操作。用于根据得到的需要的移位数,对数据的小数位进行移位。
[0183]
可以看到,使用方案二设计时,没有预处理部分电路,但每个pe单元的改动较大。
[0184]
与方案一相比,该方案的乘法器部分增加了指数运算用于提高计算精度,另外由于仅对一个乘数进行移位操作,节省了另一个通路上的移位器。该实现方案的硬件资源消耗情况如下图所示:
[0185]
表3:方案二硬件资源消耗表
[0186][0187]
*由于定点数连加可以采用华莱士树加法器进行化简,其硬件资源和时序小于7个独立的全加器。
[0188]
方案二相比方案一,每个pe单元的面积会更大功耗更高,计算精度更高,而无浮点预处理电路。方案二拥有和标准浮点计算电路几乎相同的精度,但若方案二设计和标准浮点计算电路相比较,方案二省略了大量浮点加法器和浮点舍入电路,运行速度更快,功耗更低,并且和定点计算电路高度复用,可扩展性更高。
[0189]
4本公开的可扩展性与应用范围
[0190]
本公开公开的近似计算方法除了可以应用在神经网络卷积运算电路中以外,还可以应用在其他需要多次乘累加的高性能低功耗电路设计中。以大规模非稀疏矩阵乘法为例,大规模矩阵可以将其元素划分成多个8x8的子矩阵。大规模矩阵乘法可以使用子矩阵作为元素进行乘累加运算,从而提高计算能力。
[0191]
本公开公开的近似计算方法主要针对bf16的浮点格式,除此之外,还可以针对fp16,fp32,fp64等浮点格式。以fp16为例进行分析。与bf16相比,fp16的主要区别在于其小数位数共计11位,指数位数共计5bit,其余特性都是一样的,因此,将定点乘累加单元扩充为12位的有符号定点乘累加阵列,将指数相关的计算缩小为5位运算,即可处理fp16格式的乘累加运算方法。
[0192]
本公开公开的近似计算方法主要针对2组8个元素的乘累加电路进行运算,除此之外,还可以针对2组任意多个元素进行优化。比较常见的阵列大小还有12x12,16x16等规模。
[0193]
本公开公开的近似计算方法主要针对乘累加运算进行优化,除此之外,还可以针
对乘累减,乘-max,乘-min等map-reduce结构的计算方式进行优化。以max池化运算为例进行分析,max池化运算不对数据进行求和操作,而是对每一组数据求取最大值操作。因此,仅需要将定点乘累加单元替换成比较操作与选择操作即可实现。
[0194]
此外,本公开还具备如下突出的特点:
[0195]
(1)揭示了一种应用于端侧神经网络推理加速器的矩阵乘累加运算电路,利用乘累加运算的特点,使用消耗资源较少的定点运算资源实现接近浮点运算的精度,从而解决了神经网络推理过程中计算精度与硬件实现复杂度的平衡问题;
[0196]
(2)针对神经网络数据特点,采用补码+指数形式表示浮点数,而不是采用传统的原码+指数形式表示浮点数的方法,为大规模累加运算提供支持;
[0197]
(3)利用乘累加算法的固定模式,乘法结束后不直接进行归一化运算,而是等待最终求和后统一进行归一化运算,从而大幅度化简乘累加电路的资源消耗。
[0198]
尽管以上结合附图对本公开的实施方案进行了描述,但本公开并不局限于上述的具体实施方案和应用领域,上述的具体实施方案仅仅是示意性的、指导性的,而不是限制性的。本领域的普通技术人员在本说明书的启示下和在不脱离本公开权利要求所保护的范围的情况下,还可以做出很多种的形式,这些均属于本公开保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1