一种兼容多维度矩阵乘法的运算单元
1.本公开属于处理器和计算技术领域,特别涉及一种兼容多维度矩阵乘法的pe阵列结构、运算单元及其mpu。
背景技术:
2.在现代处理器的算术单元中,矩阵乘法和向量乘矩阵是常见的算术类型,其中方阵乘方阵、向量乘方阵、矩阵乘方阵的运算,则大量出现在神经网络的卷积层和全连接层,因此传统的标量算术单元已经无法满足当今的算力需求。
3.近年来异构处理器越来越成为一种新的趋势,处理器中的mpu(matrix processing unit)则专门用于矩阵乘法和卷积运算。在现代处理器上进行矩阵乘法运算时,可以通过软件显式编程(子字并行、指令集并行、unrolling)以及硬件cache分块技术来提高硬件资源的利用率,缩短矩阵运算的时间,但在计算向量乘矩阵等不对称矩阵相乘时,仍然造成了极大的硬件资源浪费。
技术实现要素:
4.鉴于此,本公开提供了一种兼容多维度矩阵乘法的pe阵列结构,包括:
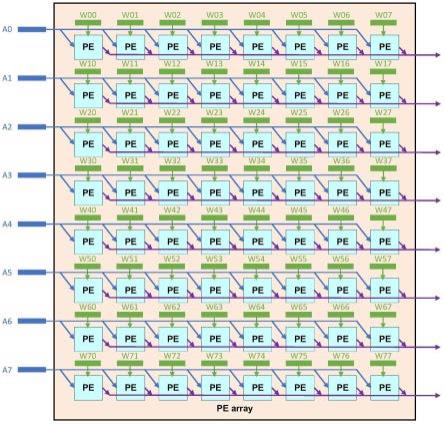
5.64个pe单元,每个pe单元在pe阵列中地址记为(i,j),i表示行,j表示列;
6.pe阵列有两种输入,包括8个a方向输入a0~a7,和64个w方向输入w00~w77;a方向和w方向正交;其中,w00至w07小计8个,w10至w17小计8个,
…
,w70至w77小计8个,从而总计64个w方向输入;
7.a0~a7中每一个都包含8个数,8个数构成一个[1,8]的向量,每个都是一个[1,8]的向量,称作a方向输入;8个a方向输入a0~a7可以相同也可以不同;
[0008]
w00~w77中每一个都包含8个数,8个数构成一个[1,8]的向量,每个都是一个[1,8]的向量,称作w方向输入;对于64个w方向输入w00~w77,各自送入对应位置的pe单元;64个w方向输入w00~w77可以相同也可以不同;
[0009]
对于每个pe单元(processing element),其中:
[0010]
作为pe阵列中的一个基本处理单元,有两个输入(例如一个a方向输入一个w方向输入)、一个输出;
[0011]
以位置(i,j)的pe单元为例,输入为ai和wij,输出记为psum(i,j);
[0012]
一个pe单元1个周期可以完成1个[1,8]
×
[1,8]
t
的向量乘法运算;
[0013]
对于pe阵列第一行的8个pe单元的组合,向量a0横向同时输入到8个pe单元;
[0014]
将pe阵列第一行的向量w00~w07看作一个[8,8]的矩阵的8个列向量,然后分别输入到对应位置的pe单元;
[0015]
pe阵列的一行1个周期可以完成一个[1,8]
×
[8,8]
t
的向量乘矩阵运算;
[0016]
通过对pe阵列中8行向量乘矩阵进行不同的组合,从而实现向量乘矩阵,以及不同维度的矩阵乘矩阵运算。
[0017]
此外,本公开还揭示了一种运算单元,所述运算单元包括前文所述的pe阵列结构。
[0018]
此外,本公开还揭示了一种mpu,其包括前文所述的pe阵列结构,或前文所述的运算单元。
[0019]
优选的,
[0020]
除pe_array即pe阵列结构之外,所述mpu还包括如下模块:control、acc、buf、lm_a即local memory a、lm_w即local memory w;
[0021]
control,用于生成各种控制信号,实现对其余模块的控制;
[0022]
lm_a和lm_w,用于存放a方向和w方向的输入;
[0023]
pe_array,用于实现各种模式下的矩阵运算;
[0024]
acc,用于对pe阵列的输出进行不同时域下的累加;
[0025]
buf,用于存储acc累加后的结果,并且,对未完成的运算还需将结果返回给acc,对已经完成的运算则将结果从mpu输出。
[0026]
当控制信号为第一控制信号时,所述pe阵列结构工作在低功耗模式。
[0027]
优选的,
[0028]
当控制信号为第一控制信号时,所述pe阵列结构工作在高性能模式。
[0029]
优选的,
[0030]
所述pe阵列结构的默认模式为高性能模式。
[0031]
优选的,
[0032]
通过发射不同模式下的控制信号,支持多种维度矩阵乘法运算。
[0033]
优选的,
[0034]
对同一向量乘矩阵运算,所述pe阵列结构能够工作在低功耗或高性能的不同模式下,且默认为高性能模式,模式可切换。
[0035]
由此,本公开提出了一种兼容多维度矩阵乘法的pe阵列结构、运算单元及其mpu。本公开对pe阵列进行了功能扩展设计,其可以通过发射不同模式下的控制信号,支持多种维度矩阵乘法运算,在提高pe阵列的利用率的同时,缩短运算时间,节省数据搬移造成的能耗。此外,本公开对同一向量乘矩阵运算设计了低功耗和高性能两种模式,可根据需要切换,来满足不同应用场景的需求,其默认模式为高性能模式。
[0036]
相比软件显式编程需要程序员具备一定的底层硬件知识,从硬件层面对pe阵列结构进行设计改进,本公开可以显著提升矩阵乘法的运算效率,减轻程序员编程时的工作量。
附图说明
[0037]
图1是本公开一个实施例中pe阵列结构的示意图;
[0038]
图1a是现有技术传统pe阵列在计算非方阵的矩阵乘法时的示意图;
[0039]
图1b是一行pe阵列输出的时域累加示意图;
[0040]
图1c是一列pe阵列输出的时域累加示意图;
[0041]
图2是本公开一个实施例中[1,8*s]
×
[8*s,8*s]
t
的向量乘矩阵运算的示意图;
[0042]
图3是本公开一个实施例中a[m]与w[m][n]复制方法一(低功耗模式)的示意图;
[0043]
图4是本公开一个实施例中a[m]与w[m][n]复制方法二(高性能模式)的示意图;
[0044]
图5是本公开一个实施例中s=8时,低功耗模式下的a[m]与w[m][n]组合方式,以
及每周期的pe阵列输入的示意图;
[0045]
图6是本公开一个实施例中s=8时,高性能模式下的a[m]与w[m][n]组合方式,以及每周期的pe阵列输入的示意图;
[0046]
图7是本公开一个实施例中标准的pe阵列矩阵乘法的示意图;
[0047]
图8是本公开一个实施例中[1,64]
×
[64,64]
t
向量乘矩阵运算的示意图;
[0048]
图9是本公开一个实施例中[1,64]
×
[64,64]
t
向量乘矩阵运算时按行8等分的示意图;
[0049]
图10是本公开一个实施例中[1,64]
×
[64,64]
t
向量乘矩阵低功耗运算的示意图;
[0050]
图11是本公开一个实施例中,第(k+1)个周期,将w[k]中的8个[8,8]
t
矩阵,分别输入到pe阵列中对应的行;1个周期后得到维度为[1,8]的向量c[k]的示意图;
[0051]
图12是本公开一个实施例中[1,64]
×
[64,64]
t
向量乘矩阵高性能运算的示意图;
[0052]
图13是本公开一个实施例中,第(k+1)个周期将维度为[1,8]的向量a[k]广播到pe阵列的a0~a7,将w中的8个[8,8]矩阵w[i][k](i=0,1,
…
,7),分别输入到pe阵列中的第i行;1个周期后每个pe单元输出1个数,将第i行8个pe的输出拼接成维度为[1,8]的待累加向量的示意图;
[0053]
图14是本公开一个实施例中,[4,16]
×
[16,16]
t
矩阵乘法的示意图;
[0054]
图15是本公开一个实施例中,[4,16]
×
[16,16]
t
矩阵乘法低功耗模式下a和w的拆分组合方式;
[0055]
图16是本公开一个实施例中,pe阵列在进行[4,16]
×
[16,16]
t
向量乘矩阵低功耗运算的第1周期pe阵列示意图;
[0056]
图17是本公开一个实施例中,pe阵列在进行[4,16]
×
[16,16]
t
向量乘矩阵低功耗运算的第2周期,w向输入保持不变时的示意图;
[0057]
图18是本公开一个实施例中,[4,16]
×
[16,16]
t
矩阵乘法高性能模式下a和w的拆分组合方式的示意图;
[0058]
图19是本公开一个实施例中,pe阵列在进行[4,16]
×
[16,16]
t
向量乘矩阵高性能运算的第1周期pe阵列示意图;
[0059]
图20是本公开一个实施例中,pe阵列在进行[4,16]
×
[16,16]
t
向量乘矩阵高性能运算的第2周期,a向输入保持不变,w向输入换为w中第2周期的8个矩阵输入的示意图;
[0060]
图21是本公开一个实施例中,[2,32]
×
[32,32]
t
矩阵乘法的示意图;
[0061]
图22是本公开一个实施例中,[2,32]
×
[32,32]
t
向量乘矩阵低功耗模式下,a和w的拆分组合方式的示意图;
[0062]
图23是本公开一个实施例中,pe阵列在进行[2,32]
×
[32,32]
t
向量乘矩阵高性能运算的第1周期pe阵列示意图;
[0063]
图23a是本公开一个实施例中,[2,32]
×
[32,32]
t
向量乘矩阵高性能模式下,a和w的拆分组合方式的示意图;
[0064]
图23b是本公开一个实施例中,pe阵列在高性能模式下,进行[4,16]
×
[16,16]
t
向量乘矩阵运算时的示意图;
[0065]
图23c是本公开一个实施例中,k=0时,pe阵列在高性能模式下,进行[4,16]
×
[16,16]
t
向量乘矩阵运算时的示意图;
[0066]
图24是本公开一个实施例中mpu的示意图。
具体实施方式
[0067]
为进一步描述本发明,下面结合附图1至图24对其作进一步说明。
[0068]
下文将详细描述本公开的各个实施例。
[0069]
如图1所示,在一个实施例中,本公开揭示了一种兼容多维度矩阵乘法的运算单元,其包括pe阵列,所述pe阵列至少包括64个pe单元组成(优选的,由64个pe单元组成,符合二进制,也是8的倍数),每个pe单元在阵列中地址记为(i,j),i表示行,j表示列;
[0070]
pe阵列有两种输入,a0~a7每个都是一个[1,8]的向量,称作a方向输入;w00~w77每个都是一个[1,8]的向量,称作w方向输入,64个输入各自送入对应位置的pe单元;
[0071]
pe阵列(pe array)共有8个a方向输入(a0~a7)和64个w方向输入(w00~w77);a0~a7中每一个都包含8个数(8个数构成一个[1,8]的向量),8个a方向输入(a0~a7)可以相同也可以不同;w00~w77中每一个都包含8个数(8个数构成一个[1,8]的向量),64个w方向输入(w00~w77)可以相同也可以不同;
[0072]
pe单元(processing element)是pe阵列中计算的一个基本处理单元,有两个输入、一个输出,以位置(i,j)的pe单元为例,输入为ai和wij,输出记为psum(i,j);一个pe单元1个周期可以完成1个[1,8]
×
[1,8]
t
的向量乘法运算;
[0073]
以pe阵列第一行的8个pe单元的组合为例,向量a0横向同时输入到8个pe单元;可以将pe阵列第一行的向量w00~w07看作一个[8,8]的矩阵的8个列向量,然后分别输入到对应位置的pe单元;pe阵列的一行1个周期可以完成一个[1,8]
×
[8,8]
t
的向量乘矩阵运算。
[0074]
本公开通过对pe阵列中8行向量乘矩阵进行不同的组合,从而实现向量乘矩阵,以及不同维度的矩阵乘矩阵运算。
[0075]
本领域技术人员知晓:传统pe阵列的w方向输入只有64个数,每一列8个pe单元的w方向输入相同。相比于现有技术,本公开的每个pe单元的w向输入各不相同,当设置pe阵列的每一列的8个pe单元w向输入相同时,即可以完成传统pe阵列的所有功能。传统pe阵列在计算非方阵的矩阵乘法时,会有大量硬件资源的闲置,如图1a所示,在进行向量乘矩阵运算时,pe阵列每一周期仅能计算1组[1,8]
×
[8,8]
t
运算,此时仅一行pe单元处于工作状态,算力仅为pe阵列峰值算力的1/8。
[0076]
下面详述本公开的pe阵列及其输入数据的拆分组合方法:
[0077]
本公开的pe阵列增加了56单位存储资源(w方向输入的数据),假设输入数据每个数的大小为1byte,即增加了448byte的存储空间;pe阵列每行中的8个pe单元可以完成一个[1,8]
×
[8,8]
t
的向量乘矩阵运算,通过控制8行不同的输入组合,可以完成不同维度的矩阵乘法运算以及向量乘矩阵运算,在进行向量乘矩阵运算时,pe阵列每1个周期能计算8组各不相同的[1,8]
×
[8,8]
t
运算,通过对pe阵列的输出进行时域累加可以完成多维度矩阵乘法运算。
[0078]
通过acc(accumulation)单元可以实现pe阵列输出的时域累加,如图1b所示,一行pe阵列输出的时域累加需要1个向量加法器;acc单元包含8个向量加法器,分别对8行pe单元的输出进行时域累加;pe阵列每列中的8个pe单元可以完成一个[1,64]
×
[8,64]
t
的向量乘矩阵运算,通过控制8列不同的输入组合,可以完成不同维度的矩阵乘法运算以及向量乘
矩阵运算,在进行向量乘矩阵运算时,pe阵列每1个周期能计算8组各不相同的[1,64]
×
[8,64]
t
运算,通过对pe阵列的输出进行空域加和可以完成多维度矩阵乘法运算;
[0079]
通过pe阵列内部加法器可以实现pe阵列输出的空域加和,如图1c所示,一列pe单元输出的空域加和需要7个向量加法器,通过使能其中指定的加法器,可以对指定的pe单元输出进行加和;pe阵列包含8*7个加法器,分别对8列pe单元的输出进行空域加和;
[0080]
在进行任意维度的矩阵乘法运算时,基于控制信号对输入数据进行拆分组合,分时输入到指定pe单元,可使得pe阵列中64个pe单元均处于工作状态,理论上本公开的pe阵列对任意维度的矩阵乘法运算均可保持峰值算力。
[0081]
下面更详细地介绍输入数据的拆分组合方法:
[0082]
对于一个任意的向量乘矩阵,均可以进行补零扩展为[1,8*s]
×
[8*s,8*s]
t
的形式(s为正整数),以[1,30]
×
[28,30]
t
为例,补零扩展后可按[1,32]
×
[32,32]
t
方式运算;
[0083]
如图2所示为[1,8*s]
×
[8*s,8*s]
t
的向量乘矩阵运算;
[0084]
将向量a拆分为s个[1,8]的向量(8个数),记其中一个为a[m];将矩阵w拆分为s*s个[8,8]的矩阵,记其中一个为w[m][n],m表示行,n表示列;pe阵列的一行1个周期刚好可以完成一个a[m]
×
w[m][n]的向量乘矩阵运算;整个pe阵列1个周期刚好可以完成8个a[m]
×
w[m][n]
t
的向量乘矩阵运算;
[0085]
因此,要完成一个[1,8*s]
×
[8*s,8*s]
t
向量乘矩阵运算,就是要将一个个a[m]
×
w[m][n]
t
按不同时域、空域均匀分布在pe阵列上;
[0086]
在矩阵乘法运算中,影响pe阵列时钟频率的关键路径为每1个周期完成一次“乘、加”运算的时间,即1个周期内要完成的向量乘法运算和向量加法运算的时间。
[0087]
此外,本公开对a[m]与w[m][n]组合方式主要有两种,第一种侧重于低功耗,读取一次数据后,尽可能复用,减少数据搬移带来的能耗;第二种侧重于高性能,尽可能缩短数据在pe阵列中的运算时间,将与向量乘法无关的运算(比如累加)放在外部acc单元处理,从而提高时钟频率;对于维度不超过[8,8]的矩阵乘法,该类运算1个周期即可完成计算,不涉及减少数据搬移的问题,也不涉及在acc单元对pe阵列运算结果进行不同时域累加的问题,因此该类矩阵乘法的高性能模式和低功耗模式一致;
[0088]
(1)当s=1,2,4时,原始输入数据过少,无法充分利用pe阵列带宽,因此本公开的pe阵列通过对a向输入或w向输入进行广播,来提高pe阵列的利用率,缩短运算时间;
[0089]
如图3所示为a[m]与w[m][n]复制方法一(低功耗),将原始a向输入(a[0]~a[s-1])复制8/s份,每份为1组,每组共有8*s个数;将原始w向输入按每8列一组划分,共s组,每组共有64*s个数;因此,pe阵列的s行1个周期可以完成1组a向输入和1组w向输入的向量乘矩阵运算,整个pe阵列可以完成8/s组这样的运算,共需s个周期完成所有运算。
[0090]
如图4所示为a[m]与w[m][n]复制方法二(高性能),将复制方法一中的a向输入转置得到s个[1,8*8/s]向量,每行为1组,每组共有8*8/s个数;将原始w向输入按每8行一组划分,共s组,每组共有64*s个数;因此,pe阵列的8/s行1个周期可以完成1组a向输入和1组w向输入的向量乘矩阵运算,整个pe阵列可以完成s组这样的运算,共需s个周期完成所有运算。
[0091]
(2)如图5所示为s=8时,低功耗模式下的a[m]与w[m][n]组合方式,以及每周期的pe阵列输入:
[0092]
第1个周期,从a中顺序取8个向量(a[0]~a[7]),分别作为pe阵列a0~a7的输入,
保持a向输入8个周期不变;第k个周期,从w中按列顺序取8个矩阵(w[k][0]~w[k][7]),分别作为pe阵列8行的w向输入;
[0093]
8个周期后完成所有与a[0]~a[7]相关的运算;
[0094]
如图6所示为s=8时,高性能模式下的a[m]与w[m][n]组合方式,以及每周期的pe阵列输入:
[0095]
第(k+1)个周期输入a中第k个向量a[k],广播到pe阵列的a0~a7,从w中按行顺序取8个矩阵(w[0][k]~w[7][k]),分别作为pe阵列8行的w向输入;8个周期后完成所有关于a的运算;
[0096]
(3)当s=3,5,6,7时,可以将a向输入和w向输入分别扩展为s=4,8的形式,然后按照(1)(2)中的规则进行运算;
[0097]
(4)当s》8时,将a分为s/8段,将w分为s*s/8块,然后将拆分后的a和w按照s=8时的运算规则进行运算。
[0098]
下面结合其他实施例进行描述:
[0099]
示例1:[8,8]
×
[8,8]
t
矩阵乘法运算
[0100]
[8,8]
×
[8,8]
t
矩阵乘法常见于神经网络卷积运算中,如图7所示是标准的pe阵列矩阵乘法,矩阵a是a0~a7的输入数据,a维度为[8,8],将其按行八等分为a[0]~a[7],每个都是一个[1,8]的向量,将其中一个记作a[i];
[0101]
矩阵w是w00~w77的输入数据,w维度为[8,8],将其按列八等分为w[0]~w[7],每个都是一个[1,8]的向量,将其中一个记作w[j];
[0102]
矩阵c是输出数据,c维度为[8,8],c在位置(i,j)处的值记作c[i][j];
[0103]
本公开的pe阵列在进行[8,8]
×
[8,8]
t
向量乘矩阵运算时,数据输入方式和计算步骤如下:
[0104]
(1)将a[0]~a[7]分别输入到pe阵列的a0~a7,即pe阵列每行的8个pe单元a方向输入均相同;将w[0]~w[7]分别输入到pe阵列的wi0~ai7,即pe阵列每列的8个pe单元的w方向输入均相同;
[0105]
(2)每个pe单元的输出为:
[0106]
psum(i,j)=a[i]
×
w[j]
[0107]
易知c[i][j]的值即为psum(i,j);
[0108]
(3)1个周期后运算得到c[0][0]~c[7][7],完成[8,8]
×
[8,8]
t
=[8,8]的乘矩阵计算。
[0109]
对于同样仅需要1个周期即可完成的矩阵乘法运算(矩阵维度不超过[8,8]的矩阵乘法),a方向输入的数据和w方向输入的数据均仅用于1个周期的运算,因此,该类运算高性能模式和低功耗模式的运算一致,不做区分。
[0110]
示例2:[1,64]
×
[64,64]
t
向量乘矩阵运算
[0111]
针对不同的应用场景需求,本公开设计的硬件结构支持低功耗和高性能两种模式进行向量乘矩阵运算;
[0112]
[1,64]
×
[64,64]
t
向量乘矩阵运算在低功耗模式下,pe阵列一次可以读取8个不同的a向输入,8个周期高度复用,极大减少了向量乘矩阵运算时数据搬移造成的能耗;低功耗模式下pe阵列中需额外增加的8*7个加法器(2输入1输出),用于对pe阵列每周期的运算
结果进行加和;
[0113]
高性能模式下,pe阵列的a向输入和w向输入每周期均不相同,但无需在pe阵列内对每周期运算结果进行加和,运算结果直接输出到外部acc单元;因此,pe阵列可以进行高频运算,而当前周期输出的运算结果经过acc单元累加后,累加结果暂时存储在外部buf单元,等待与下一个周期pe单元的运算结果进行不同时域下的累加。
[0114]
如图8所示,向量a是a0~a7的输入数据,a维度为[1,64],将其八等分为a[0]~a[7],每个都是一个[1,8]的向量,将其中一个记作a[i];
[0115]
矩阵w是w00~w77的输入数据,w维度为[64,64],将其等分为64个[8,8]矩阵,将其中一个记作w[k][i],k表示行,i表示列;
[0116]
向量c为输出,c维度为[1,64],将其八等分,记其中一个为c[k],其维度为[1,8];c[k]中的每一个数记作c[k][j];
[0117]
如图9所示,将w[k][i]按行8等分为w[k][i][0]~w[k][i][7],其中每一行均为[1,8]的向量,将其中一个记作w[k][i][j];
[0118]
低功耗模式:
[0119]
pe阵列第(k+1)个周期需要计算的向量乘矩阵为a[i]
×
w[k][i]
t
,i=0,1,
…
,7;8个周期pe阵列每个周期需要计算的向量乘矩阵如图10所示;
[0120]
本公开的pe阵列在低功耗模式下,进行[1,64]
×
[64,64]
t
向量乘矩阵运算时,数据输入方式和计算步骤如下:
[0121]
(1)第1个周期将a[0]~a[7]分别输入pe阵列的a0~a7后,保持不变(此处节省了7个周期8个[1,8]向量的数据搬移);如图11所示,第(k+1)个周期,将w[k]中的8个[8,8]
t
矩阵,分别输入到pe阵列中对应的行;1个周期后得到维度为[1,8]的向量c[k];
[0122]
(2)以k=0为例,将a[0]~a[7]分别输入pe阵列的a0~a7;将8个w[0][i]分别输入pe阵列中的第i行;
[0123]
(3)每个pe单元的输出为:
[0124]
psum(i,j)=a[i]
×
w[0][i][j]
t
[0125]
(4)对pe阵列8行中具有相同j的psum进行求和,得到8个值;
[0126][0127]
(5)将这8个值进行拼接,得到维度为[1,8]的向量c[0];
[0128]
c[0]={c[0][0],c[0][1],
…
,c[0][j],
…
,c[0][7]}
[0129]
(6)a0~a7的输入保持不变,对w[1]~w[7]重复步骤(2)~(5),8个周期得到c[0]~c[7],完成[1,64]
×
[64,64]
t
=[1,64]的向量乘矩阵计算。
[0130]
高性能模式:
[0131]
pe阵列第(k+1)个周期需要计算的向量乘矩阵为a[k]
×
w[i][k]
t
,i=0,1,
…
,7;8个周期pe阵列每个周期需要计算的向量乘矩阵如图12所示;
[0132]
本公开的pe阵列在高性能模式下,进行[1,64]
×
[64,64]
t
向量乘矩阵运算时,数据输入方式和计算步骤如下:
[0133]
(1)如图13所示,第(k+1)个周期将维度为[1,8]的向量a[k]广播到pe阵列的a0~
a7,将w中的8个[8,8]矩阵w[i][k](i=0,1,
…
,7),分别输入到pe阵列中的第i行;1个周期后每个pe单元输出1个数,将第i行8个pe的输出拼接成维度为[1,8]的待累加向量,记作ck[i];
[0134]
(2)以k=0为例,将a[0]广播到pe阵列的a0~a7;将8个w[i][0]分别输入pe阵列中的第i行;
[0135]
(3)每个pe单元的输出为:
[0136]
psum(i,j)=a[0]
×
w[i][0][j]
t
[0137]
(4)将第i行的8个pe单元的输出psum进行拼接,得到维度为[1,8]的向量,将该向量输入到acc单元进行累加,即与上一周期存储在buf单元中的向量进行加和,累加结果为ck[i],将ck[i]输出到外部buf单元,等待与下一个周期pe阵列的运算结果进行不同时域下的累加;
[0138]
(5)对a[1]~a[7]重复步骤(2)~(4),在acc单元中每个周期都将新得到的ck[i]与上一周期pe单元的输出进行累加:
[0139][0140]
(6)8个周期后,将8个c[i]进行拼接,得到维度为[1,64]的向量c;8个周期完成[1,64]
×
[64,64]
t
=[1,64]的向量乘矩阵计算。
[0141]
示例3:[4,16]
×
[16,16]
t
矩阵乘法运算
[0142]
如图14所示是[4,16]
×
[16,16]
t
矩阵乘法,矩阵a是a0~a7的输入数据,a维度为[4,16],先将其按行四等分为a[0]~a[3],记其中一个为a[m],再将a[m]按列二等分为a[m][0]和a[m][1],其中每个都是一个[1,8]的向量,将其中一个记作a[m][n];
[0143]
矩阵w是w00~w77的输入数据,w维度为[16,16],将其拆分为4个[8,8]的矩阵,其中一个记作w[i][j],i表示行,j表示列;
[0144]
矩阵c为矩阵乘法的输出,其维度和编号与矩阵a一致,图中每个小块都是一个[1,8]的向量,将其中一个记作c[m][n];
[0145]
低功耗模式:
[0146]
pe阵列每周期可以完成8个[1,8]
×
[8,8]
t
的向量乘矩阵运算,如图15所示是低功耗模式下a和w的拆分组合方式;
[0147]
本公开的pe阵列在进行[4,16]
×
[16,16]
t
向量乘矩阵低功耗运算时,数据输入方式和计算步骤如下:
[0148]
(1)第1个周期时,如图16所示,按照图15所示的a和w的拆分组合方法,将a中第1周期的4个[1,8]向量分别输入pe阵列的a0~a7(每个[1,8]向量广播到pe阵列中的2行);将w中的8个[8,8]
t
矩阵,分别输入到pe阵列中w00~w77;1个周期后得到c[0][0]~c[1][1];
[0149]
(2)第2个周期,如图17所示w向输入保持不变(此处节省了1个周期8个[8,8]矩阵数据的搬移),a向输入换为a中第2周期的64个输入;1个周期后得到c[2][0]~c[3][1];
[0150]
(3)每个周期得到的c[m][n]其计算公式为:
[0151][0152]
(4)2个周期后得到完整的输出矩阵c,完成[4,16]
×
[16,16]
t
=[4,16]的矩阵乘法计算。
[0153]
高性能模式:
[0154]
如图18所示是高性能模式下a和w的拆分组合方式;
[0155]
本公开的pe阵列在进行[4,16]
×
[16,16]
t
向量乘矩阵高性能运算时,数据输入方式和计算步骤如下:
[0156]
(1)第1个周期时,如图19所示,按照图18所示,将a中第1周期的8个[1,8]向量分别输入pe阵列的a0~a7;将w中的2个[8,8]矩阵分别输入到pe阵列中w00~w77(每个[8,8]矩阵广播到pe阵列中的4行);1个周期后得到8个[1,8]待累加的向量,记作c`[m][n];
[0157]
(2)第2个周期,如图20所示a向输入保持不变,w向输入换为w中第2周期的8个矩阵输入;1个周期后得到8个[1,8]向量,在acc单元与上1个周期的c`[m][n]累加后,得到所有c[m][n];完成[4,16]
×
[16,16]
t
=[4,16]的矩阵乘法计算。
[0158]
示例4:[2,32]
×
[32,32]
t
矩阵乘法运算
[0159]
如图21所示是[2,32]
×
[32,32]
t
矩阵乘法,矩阵a是a0~a7的输入数据,a维度为[2,32],先将其按行二等分为a[0]、a[1],记其中一个为a[m],再将a[m]按列四等分为a[m][0]~a[m][3],其中每个都是一个[1,8]的向量,将其中一个记作a[m][n];
[0160]
矩阵w是w00~w77的输入数据,w维度为[32,32],将其按行四等分后再按列四等分,拆分为16个[8,8]的矩阵,将其中一个记作w[i][j],i表示行,j表示列;
[0161]
矩阵c为矩阵乘法的输出,其维度和编号与矩阵a一致,图中每个小块都是一个[1,8]的向量,将其中一个记作c[m][n];
[0162]
低功耗模式:
[0163]
pe阵列每周期可以完成8个[1,8]
×
[8,8]
t
向量乘矩阵运算,如图22所示为低功耗模式下a和w的拆分组合方式;
[0164]
本公开的pe阵列在进行[4,16]
×
[16,16]
t
向量乘矩阵运算时,数据输入方式和计算步骤如下:
[0165]
(1)第1个周期时,如图23所示,按照图22所示的a和w的拆分组合方法,将a中第1周期的4个[1,8]向量分别输入pe阵列的a0~a7(每个[1,8]向量广播到pe阵列中的2行);将w中的8个[8,8]矩阵,分别输入到pe阵列中w00~w77;1个周期后得到c[0][0]和c[0][1];
[0166]
(2)第2个周期,w向输入保持不变(此处节省了1个周期8个[8,8]
t
矩阵的数据搬移),a向输入换为a中第2周期的8个[1,8]向量;1个周期后得到c[1][0]和c[1][1];
[0167]
(3)同理,按照图22所示的a和w的拆分组合方法,每个周期得到的c[m][n]其计算公式为:
[0168][0169]
(4)4个周期后得到完整的输出矩阵c,完成[2,32]
×
[32,32]
t
=[2,32]的矩阵乘
法计算。
[0170]
高性能模式:
[0171]
pe阵列第(k+1)个周期需要计算的向量乘矩阵为a[m][k]
×
w[i][k]t(m=0,1;i=0,1,2,3);4个周期pe阵列每个周期需要计算的向量乘矩阵如图23a所示;
[0172]
本公开的pe阵列在高性能模式下,进行[4,16]
×
[16,16]t向量乘矩阵运算时,数据输入方式和计算步骤如下:
[0173]
(1)如图23b所示,第(k+1)个周期将维度为[1,8]的向量a[0][k]广播到pe阵列的a0~a3;同理,将向量a[1][k]广播到pe阵列的a4~a7;将矩阵w[i][k](i=0,1,2,3),输入到pe阵列中的第i行和第i+4行;1个周期后每个pe单元输出1个数,将同一行8个pe的输出拼接成维度为[1,8]的待累加向量,记作ck[m][i];
[0174]
(2)如图23c所示,以k=0为例,将a[0][0]广播到pe阵列的a0~a3;将a[1][0]广播到pe阵列的a4~a7;将4个w[i][0](i=0,1,2,3)分别输入pe阵列中的前4行、后4行;
[0175]
(3)将第(m*4+i)行的8个pe单元的输出psum进行拼接,得到维度为[1,8]的向量,将该向量输入到acc单元进行累加,即与上一周期存储在buf单元中的向量进行加和,累加结果为ck[m][i];
[0176]
(4)将ck[m][i]输出到外部buf单元,等待与下一个周期pe阵列的输出结果进行不同时域下的累加;
[0177]
(5)对a[m][n](m=0,1;n=1,2,3)重复步骤(2)~(4),每周期对pe阵列第(m*4+i)行的输出ck[m][i]在acc单元进行累加,4个周期累加结果为:
[0178][0179]
(6)4个周期后,将4个c[0][i](i=0,1,2,3)进行拼接,得到维度为[1,32]的向量c[0];同理,得到维度为[1,32]的向量c[1];4个周期完成[2,32]
×
[32,32]t=[2,32]的向量乘矩阵计算。
[0180]
本公开的pe阵列可以实现的不同维度的矩阵乘法运算如下表1所示:
[0181]
表1
[0182]
[0183][0184]
本公开的pe阵列除了支持上表所示类型矩阵乘法的运算外,对于任意不为方阵的w向输入,均可将其补零扩展为上表中最接近其大小的方阵;同时,将a向输入补零扩展为相同列宽,以[1,5]
×
[5,
[0185]
6]
t
为例,补零扩展后可按[1,8]
×
[8,8]
t
方式运算;
[0186]
对于任意[n,s]
×
[s,s]
t
矩阵乘法运算,均可拆分为n个[1,s]
×
[s,s]
t
向量乘矩阵运算,最多n*cycle周期(cycle为原向量乘矩阵运算所需周期数)完成矩阵乘法运算。
[0187]
此外,本公开还揭示了所述运算单元,特别是其pe阵列在一个典型的mpu中的应用。进而,本公开还揭示了一种mpu,所述mpu包括所述运算单元。
[0188]
本公开的pe阵列在一个典型的mpu中的布局如图24所示,其中:
[0189]
(1)control主要用来生成各种控制信号,实现对各模块的控制;
[0190]
本发明专利中,工作模式分为高性能模式和低功耗模式,默认模式为高性能模式,control的工作模式信号示例性的通过下表2区分:
[0191]
表2
[0192][0193]
假设两个待相乘矩阵的形式为[m,s]
×
[n,s]t,本发明专利中m、s、n这3个维度可能的取值为1,2,4,8(当维度为3时,可以将原始维度通过补零扩展为维度4的矩阵;当维度为5,6,7时,可以将原始维度通过补零扩展为维度8的矩阵),因此,共有64种矩阵乘法形式,control的矩阵维度信号需要6位来区分表示,参见下表3;
[0194]
表3
[0195][0196]
control的工作模式信号和矩阵维度信号需要传送到lm_a和lm_w,共同确定每周期矩阵a、w数据的取数方式;
[0197]
工作模式信号需要传送到pe_array、acc和buf,用于控制pe单元的输出结果psum进行时域累加或空域加和;
[0198]
矩阵维度信号传送到pe_array、acc和buf,用于确定pe阵列不同维度矩阵乘法运算的周期数,从而判断矩阵乘法运算是否完成,决定buf是否可以向外传出运算结果;
[0199]
(2)lm_a(即local memory a)和lm_w(即local memory w)是大小分别为64byte和512byte的存储资源(假设输入数据每个数的大小为1byte,),主要用于暂时存放a方向的输入和w方向的输入,即两个待乘矩阵a和w的数据;
[0200]
lm_a和lm_w基于control的矩阵维度信号和工作模式信号读取矩阵a和矩阵w中指定的数据,并输入到指定的pe单元;
[0201]
(3)pe_array即pe阵列,主要用来实现各种模式下的矩阵运算,基于control的工作模式信号使能pe阵列内部的加法器。默认模式(高性能模式)下,pe单元的输出直接传送到acc单元进行时域累加;低功耗模式下,使能pe阵列内部的加法器进行空域加和,pe阵列的运算结果无需在acc单元进行累加;
[0202]
(4)acc单元主要用于对pe阵列的输出进行不同时域下的累加。在高性能模式下,pe阵列中8行pe单元的输出分别作为acc单元8个加法器的第一个输入;buf单元中存储的8个向量分别作为acc单元8个加法器的第二个输入;最后acc单元将8个加法器的运算结果输入到buf单元;低功耗模式下,acc单元将pe阵列空域加和后的8个向量直接传入buf单元;
[0203]
(5)buf(buffer)单元主要用于暂时存储acc累加后的结果,初始值为0。基于control的工作模式信号,buf单元确定是否将存储的数据输入到acc单元进行累加;高性能模式下,buf单元中存储的值作为acc单元的第二个输入,进行时域累加;低功耗模式下,buf单元不向acc单元传送数据。
[0204]
基于control的矩阵维度信号,可以确定不同维度矩阵乘法运算的周期数,buf单元基于此计数可以判断矩阵乘法运算是否完成,运算完成时,buf单元将存储的数据从mpu中传出。
[0205]
能够理解,正如处理器领域的常用缩写那样,control代表控制模块,pe_array即
pe阵列结构,acc即累加器,buf即缓存。
[0206]
此外,需要说明的是:
[0207]
本公开高性能模式下,pe阵列每1个周期能计算8组各不相同的[1,8]
×
[8,8]
t
运算,通过acc单元实现计算结果的时域累加,因此,矩阵乘法中的加法运算转移到acc单元中,acc单元每个周期进行一次加法运算,从而缩短pe阵列关键路径的时间,提高时钟频率;
[0208]
假设完成一次向量乘法运算(由pe单元完成)的延时为1ns,完成一次向量加法运算的延时为0.3ns,其中,表格所示的示例2、3、4的矩阵运算,在两种模式下的关键路径延时和时钟频率如下表4所示:
[0209]
表4
[0210][0211]
其中,高性能模式下的加法运算在acc单元中进行,而不在pe阵列中进行,故其加法延时不累计在pe阵列关键路径延时中。
[0212]
处理器工作时的主要功耗来源于数据搬移,因此本公开利用空间局部性来提高单次读取数据的利用率,从而有效降低功耗;本公开中,每1个周期w方向输入的数据搬移量要远大于a方向输入的数据搬移量,因此要优先复用w方向输入的数据来降低功耗。
[0213]
本公开低功耗模式下,pe阵列每1个周期能计算8组各不相同的[1,64]
×
[8,64]t运算,基于不同维度矩阵乘法的控制信号使能pe阵列中指定的加法器,可以实现计算结果的空域加和;
[0214]
空域加和可以最大化地复用w方向的输入数据,因此,对于同一矩阵乘法运算,在相同运算周期数下,低功耗模式可以有效减少数据搬移量;空域加和结果传入acc单元不进行累加运算直接传出,进一步减少了功耗;
[0215]
假设输入数据每个数的大小为1byte,一次a方向输入的数据搬移量为64byte,一次w方向输入的数据搬移量为512byte,同样是示例2、3、4的矩阵运算,在两种模式下的数据搬移量如下表5所示:
[0216]
表5
[0217]
[0218]
其中以示例4低功耗模式为例,4*64表示a方向输入数据搬移4个周期,每周期搬移量64byte,2*512表示w方向输入数据搬移2个周期,每周期搬移量512byte。
[0219]
需要强调的是,对于维度不超过[8,8]的矩阵乘法,该类运算1个周期即可完成计算,不涉及减少数据搬移的问题,也不涉及在acc单元对pe阵列运算结果进行不同时域累加的问题,因此该类矩阵乘法的高性能模式和低功耗模式一致。
[0220]
综上所述,本公开具有如下特点:
[0221]
除了可以应用在手机、监控设备、汽车电子等端侧神经网络加速芯片上以外,还可以应用在服务器上的加速板卡;
[0222]
本公开中的pe运算单元可以实现成定点乘累加运算,也可以实现成浮点乘累加运算;
[0223]
本公开本的pe阵列除了支持上64个元素的矩阵乘法的运算以外,还可以支持4
×
4、16
×
16等相似结构的运算,以及4
×
8、8
×
4、8
×
16、16
×
8等矩形矩阵运算。
[0224]
尽管以上结合附图对本公开的实施方案进行了描述,但本公开并不局限于上述的具体实施方案和应用领域,上述的具体实施方案仅仅是示意性的、指导性的,而不是限制性的。本领域的普通技术人员在本说明书的启示下和在不脱离本公开权利要求所保护的范围的情况下,还可以做出很多种的形式,这些均属于本公开保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1