一种提高神经网络MAC使用率的多层级联结构
一种提高神经网络mac使用率的多层级联结构
技术领域
1.本公开属于人工智能技术领域,特别涉及一种提高神经网络mac使用率的多层级联结构。
背景技术:
2.衡量神经网络计算速度时,内存使用开销(memory access cost,mac)是一项重要指标。而神经网络运算(如卷积或池化)需要进行大量对主存储器的访存,访存的数据往往是以向量、张量的形式进行存储的。这就导致在目前主流计算架构(如现有cpu、gpu或npu或任何架构的处理器)中处理这类运算,主存储器的访存会占用大量时间。然而,在神经网络计算中,层与层之间数据有紧密的联系(上层计算的输出即为下层的输入)。若只计算一层就访存一次主存储器,无疑是低效的。现有计算架构中缺乏针对这类计算灵活高效的数据存取控制能力,因此面临着内存使用效率低下的问题,从而导致严重的性能瓶颈。
技术实现要素:
3.鉴于此,本公开提供了一种提高神经网络内存使用开销mac使用率的多层级联结构,其对处理器内用于存储特征图feature map的块存储器block memory分区,将其作为多层神经网络中不同层的数据存储区域,其中,将所述块存储器block memory至少划分为三个区域,用于存储多层神经网络的特征图feature map,所述三个区域分别为输入层、中间层和输出层,所述中间层为一层或多层。
4.换言之,由于中间层可以是多层,那么本公开实质上是将所述块存储器block memory至少划分为三个区域,用于存储多层神经网络中输入层、中间层和输出层的特征图feature map。
5.优选的,
6.所述块存储器block memory是片上大容量、大位宽存储器,用于神经网络计算。
7.优选的,
8.所述块存储器block memory的最小单位为位宽为64、深度为512的双口sram,并将其组合为多存储体bank,用于存储特征图feature map,权重weight和偏置bias。
9.优选的,
10.所述块存储器block memory采用现场可编程逻辑门阵列fpga片上的静态随机存取存储器sram。
11.优选的,
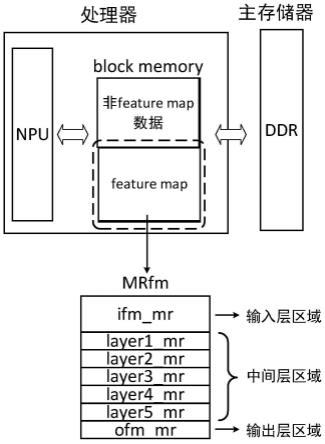
12.将所述块存储器block memory划分为七个区域,用于存储多层神经网络的特征图feature map。
13.优选的,
14.所述七个区域分别是存储输入图像或输入层特征图feature map的ifm_mr分区,存储中间层特征图feature map的layer1_mr分区、layer2_mr分区、layer3_mr分区、
layer4_mr分区、layer5_mr分区,以及存储输出层特征图feature map的ofm_mr分区。
15.优选的,
16.处理器进行计算时,首先访问主存储器ddr获得输入图像或输入层特征图feature map,将其存储在ifm_mr分区,作为多层神经网络的输入层交给npu计算;多层神经网络的输入层计算结束后,npu会将结果存在layer1_mr分区~layer5_mr 5个分区中,作为中间层输入;而中间层会继续利用layer1_mr分区~layer5_mr 5个分区中的其他区域来存储计算结果,同时也是下一个中间层的输入;直到多层神经网络计算结束,最终计算结果将会被存入ofm_mr分区,之后被存储进主存储器ddr。
17.优选的,
18.在处理器内部利用神经网络计算单元npu处理级联的多层神经网络或包含分支结构的神经网络构建模块。
19.优选的,
20.所述包含分支结构的神经网络构建模块包括resnet中的bottleneck unit和shufflenet中的shufflenet unit。
21.优选的,
22.所述块存储器block memory为任意大小。
23.通过上述技术方案,层间级联极大地提高了神经网络mac利用率,能高效访存主存储器。该设计对于解决神经网络计算访存效率低这一性能瓶颈具有十分重要的意义。
附图说明
24.图1是本公开一个实施例中所提供的一种提高神经网络内存使用开销mac使用率的多层级联结构图;
25.图2是本公开一个实施例中mrfm分区示意图;
26.图3是本公开一个实施例中神经网络计算存储结构示意图;
27.图4是本公开一个实施例中mrfm具体结构示意图;
28.图5是本公开一个实施例中一个包含conv和pooling的简单神经网络模块示意图;
29.图6是本公开一个实施例中级联的多层神经网络的具体实现过程图;
30.图7是本公开一个实施例中shufflenet unit构建模块示意图;
31.图8是本公开一个实施例中shufflenet unit构建模块的具体实现过程图;
32.图9是本公开一个实施例中bottleneck residual block构建模块示意图;
33.图10是本公开一个实施例中bottleneck residual block构建模块的具体实现过程图。
具体实施方式
34.参见图1,在一个实施例中,其公开了一种提高神经网络内存使用开销mac使用率的多层级联结构,通过对处理器内用于存储特征图feature map的块存储器block memory分区,将其作为多层神经网络中不同层的数据存储区域,其中,将所述块存储器block memory至少划分为三个区域,用于存储多层神经网络的特征图feature map,所述三个区域分别为输入层、中间层和输出层,所述中间层为一层或多层。
35.在这个实施例中,一种提高神经网络mac使用率的多层级联结构(以下简称层间级联),通过对处理器内用于存储feature map的block memory分区,将其作为多层神经网络中不同层的数据存储区域。进行神经网络计算时,首先从主存储器获取输入层数据,充分利用block memory分区,作为不同层计算结果的区域。从而实现只从主存储器中读取一层输入数据,就能在处理器内部利用神经网络计算单元(neural network processing,npu)处理级联的多层神经网络或包含分支结构的神经网络构建模块(如resnet中的bottleneck unit,shufflenet中的shufflenet unit),一次计算时仅有输入层和输出层与主存储器有访存交互。
36.层间级联是一种block memory分区设计,可以针对具体问题安排更灵活更细化的分区方案。例如,增减中间层区域个数,灵活设置各区域的地址空间。
37.在另一个实施例中,所述块存储器block memory是片上大容量、大位宽存储器,用于神经网络计算。
38.就该实施例而言,本block memory设计还可用于存储任何大位宽,大体量的片上数据,不局限于神经网络计算。
39.在另一个实施例中,所述块存储器block memory的最小单位为位宽为64、深度为512的双口sram,并将其组合为多bank,用于存储feature map,weight和bias。
40.就该实施例而言,以64x512 sram作为最小单位的block memory,可以以不同的形式组合,实现多样的神经网络存储结构。
41.在另一个实施例中,所述块存储器block memory采用现场可编程逻辑门阵列fpga片上的静态随机存取存储器sram。
42.就该实施例而言,本设计中处理器内部的block memory采用fpga片上的sram实现。简单地来说片上sram是fpga中固定的具有存储功能的硬核。片上sram有着较大的存储空间,适合于存储大位宽数据,如神经网络计算中需要用到的参数,feature map,weight和bias等等。采用片上sram作为处理器内部的block memory,能够有效利用fpga片上资源。
43.在另一个实施例中,将所述块存储器block memory划分为七个区域,用于存储多层神经网络的feature map。
44.在另一个实施例中,所述七个区域分别是存储输入图像或输入层feature map的ifm_mr分区,存储中间层feature map的layer1_mr分区、layer2_mr分区、layer3_mr分区、layer4_mr分区、layer5_mr分区,以及存储输出层feature map的ofm_mr分区。
45.就该实施例而言,如图2所示,层间级联设计将处理器内部的用于存储神经网络feature map的block memory(mrfm,matrix registers for feature map)划分为7个区域,用于存储多层神经网络的feature map。其中各区域的功能描述如表1所示。
46.分区功能ifm_mr存储输入图片或输入层feature maplayer1_mr存储中间层feature maplayer2_mr存储中间层feature maplayer3_mr存储中间层feature maplayer4_mr存储中间层feature maplayer5_mr存储中间层feature map
ofm_mr存储输出层feature map
47.表1
48.在另一个实施例中,处理器进行计算时,首先访问主存储器ddr获得输入图像或输入层feature map,将其存储在ifm_mr分区,作为多层神经网络的输入层交给npu计算;多层神经网络的输入层计算结束后,npu会将结果存在layer1_mr分区~layer5_mr 5个分区中,作为中间层输入;而中间层会继续利用layer1_mr分区~layer5_mr5个分区中的其他区域来存储计算结果,同时也是下一个中间层的输入;直到多层神经网络计算结束,最终计算结果将会被存入ofm_mr分区,之后被存储进主存储器ddr。
49.就该实施例而言,如图3所示,展示了利用层间级联设计的神经网络计算存储结构。处理器进行计算时,首先访问主存储器获得输入图像或输入feature map,将其存储在mrfm的ifm_mr区域,作为多层神经网络模块的输入层交给npu计算。
50.输入层计算结束后,npu会将结果存在layer1_mr~layer5_mr中的区域,作为中间层输入。而中间层会继续利用layer1_mr~layer5_mr中的其他区域来存储计算结果,同时也是下一个中间层的输入。直到多层神经网络模块计算结束,最终计算结果将会被放入ofm_mr区域,之后被存储进ddr。
51.处理器无法在仅输入神经网络整体输入层时就计算完整个网络(片上存储大小所致),因而每次只处理神经网络的连续几层(或一个网络模块)。神经网络整体的输入层输入的是图像,神经网络中间层作为输入的时候输入的是特征图feature map。所以计算图像刚进入神经网络部分(输入部分)的时候,处理器获得的是图像。而处理下一个部分时,处理器获得的就是输入部分处理好的特征图feature map。
52.如此可以充分利用block memory来计算具有多层神经网络的模块,减少了对主存储器的访存,极大地提高了神经网络mac利用率。
53.神经网络整体的输入层输入的是图像,神经网络中间层作为输入的时候输入的是特征图feature map。处理器无法在仅输入神经网络整体输入层时就计算完整个网络(片上存储大小所致),因而每次只处理神经网络的连续几层(网络模块)。所以图像刚进入神经网络(输入模块)的时候,处理器获得的是图像。而处理下一个模块时,处理器获得的就是输入模块处理好的特征图feature map。以此类推直到本次神经网络计算结束。
54.在另一个实施例中,在处理器内部利用神经网络计算单元npu处理级联的多层神经网络或包含分支结构的神经网络构建模块。
55.在另一个实施例中,所述包含分支结构的神经网络构建模块包括resnet中的bottleneck unit和shufflenet中的shufflenet unit。
56.就该实施例而言,所述包含分支结构的神经网络构建模块包括但不限于上述提到的resnet中的bottleneck unit和shufflenet中的shufflenet unit。
57.在另一个实施例中,所述块存储器block memory为任意大小。
58.就该实施例而言,层间级联不针对特定大小的block memory,可以在任何大小的进行神经网络计算的block memory中采用该设计。
59.在另一个实施例中,mrfm在本设计中用于存储神经网络feature map,具体结构如图4所示。mrfm包含有32个index,分别记为mr0~mr31。每个index是一段位宽为512,深度为128的sram,由两个64x512的最小单位构成。寻址时采用如下约定:mr为16bit的数据,其中,
mr[15:7]为index的编址,mr[6:0]表示每个index内部的编址。
[0060]
在另一个实施例中,图5展示了包含一个conv层和一个pooling层的基础卷积神经网络模块。在本实施例中,仅用到了mrfm中的ifm_mr分区,layer2_mr分区和ofm_mr分区。
[0061]
npu计算该模块时,首先访问主存储器获取输入feature map,并将其存在ifm_mr区域。conv层将ifm_mr区域的数据作为输入开始计算,计算结束后,将计算结果存在layer2_mr区域。然后,pooling层将layer2_mr区域的数据作为输入开始计算,计算结束后,将计算结果存在ofm_mr区域。最后处理器将ofm_mr区域的feature map,也就是该神经网络模块的输出结果存储到主存储器上。具体过程如图6所示。
[0062]
在另一个实施例中,图7展示了shufflenet v2网络结构中的一种构建模块,该模块有两个分支。右分支包含三层神经网络计算,方便起见,将三层运算分别简称为ra,rb,rc。左分支包含两层神经网络计算,同样简称为lb,lc。两个分支计算结果经过拼接,channel shuffle之后成为模块的最终输出。
[0063]
npu计算该模块时,首先访问主存储器获取输入feature map,将其存在ifm_mr区域。两个分支可以交织地利用layer1_mr~layer5_mr区域分别作为自己中间层的计算结果。如ra和rb的结果存储在layer1_mr和layer3_mr,lb的结果存储在layer2_mr。最终lc和rc的结果经过npu的channel shuffle后,放入ofm_mr区域,之后存储到主存储器中。具体过程如图8所示。
[0064]
在另一个实施例中,展示了bottleneck residual block构建模块的具体实现。
[0065]
图9展示了resnet网络结构中的一种构建模块,该模块有两个分支。右分支包含三层神经网络计算,方便起见,将三层运算分别简称为ra,rb,rc。左分支为直连。两个分支计算结果经过相加后成为模块的最终输出。
[0066]
对于该实施例而言,若划分为7个区域,则计算时不会用到layer4,layer5区域,如此便不能充分利用mrfm的存储空间。所以针对这一实施例,可将分区减小为5个,去除layer4,layer5区域。
[0067]
npu计算该模块时,首先访问主存储器获取输入feature map,将其存在ifm_mr区域。ra,rb和rc的结果存储在layer1_mr,layer2_mr和layer3_mr。最终rc和ifm经过相加后后,放入ofm_mr区域,之后存储到主存储器中。具体过程如图10所示。
[0068]
尽管以上结合附图对本公开的实施方案进行了描述,但本公开并不局限于上述的具体实施方案和应用领域,上述的具体实施方案仅仅是示意性的、指导性的,而不是限制性的。本领域的普通技术人员在本说明书的启示下和在不脱离本公开权利要求所保护的范围的情况下,还可以做出很多种的形式,这些均属于本公开保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1