一种基于风格控制GAN的生成式人脸匿名化方法
一种基于风格控制gan的生成式人脸匿名化方法
技术领域
1.本发明涉及计算机图像生成领域,特别是一种基于风格控制gan的生成式人脸匿名化方法。
背景技术:
2.人脸识别技术作为生物特征识别的重要技术之一,已经进入了大规模应用阶段。个人数据的隐私问题也得到越来越多的关注,针对隐私保护、躲避和攻击人脸识别系统的研究也陆续出现。
3.人脸匿名化技术利用人脸编辑方式来保护照片和视频中某人的身份隐私信息,大大降低了人脸信息泄露或者人脸信息被肆意滥用的风险。人脸隐私保护的传统技术,比如模糊和像素化,可能导致处理的结果不完整或者剥离了人的个性,而且仅仅只去除表情的传统技术也可能导致他人通过其他特征会发现这个人的身份。
4.人脸生成技术在对人脸进行匿名化的方向上获得了较多关注。生成式对抗网络(generative adversarial network)目前有非常多在人脸生成方向上的应用。gan解决了传统技术中处理结果不完整以及剥离人的个性的问题。因为gans根本没有使用受试者的原始面孔,所以能有效消除这一风险。并且gans还可以在高分辨率下重现面部表情,为重现用户个性提供了解决方案。
5.近年来,人脸匿名化技术已经取得了一些成果,在文献《deepprivacy:a generative adversarial network for face anonymization》中,等人从新的、更有挑战的角度欺骗人脸识别系统:在不改变原来的数据分布的前提下把人脸匿名化,模型的输出还是一张逼真的人脸,姿态和背景也和原图相同,但完全无法识别出原来的人脸身份。但是,上述方法仍存在不足:1)模型的搭建需要人工收集众多的人脸图片数据集,收集数据集时有可能侵犯他人的人脸隐私。2)在实时过程中(例如视频会议、视频通话)进行人脸的匿名化对光照有一定的要求。
技术实现要素:
6.本发明的目的是提供一种基于风格控制gan的生成式人脸匿名化方法。
7.实现本发明目的的技术方案如下:
8.一种基于风格控制gan的生成式人脸匿名化方法,包括:
9.步骤1,使用stylegan2生成虚拟人脸数据集;
10.步骤2,对虚拟人脸数据集中的虚拟人脸图片进行频域模糊检测,删除模糊的虚拟人脸图片,重组虚拟人脸数据集;
11.步骤3,将重组后的虚拟人脸数据集输入deepfacelive框架,得到人脸匿名化模型;
12.步骤4,将待匿名化的人脸图像输入人脸匿名化模型,得到匿名化后的人脸图像;
13.所述步骤2,对虚拟人脸数据集中的虚拟人脸图片进行频域模糊检测,具体为:
14.2.1将虚拟人脸图片划分为n个分块;
15.2.2对第i个分块进行dct变换,得到该分块的dct矩阵;
16.2.3计算dct矩阵的高频信号之和wi;
17.2.4计算wi与该分块的高频阈值ωi的偏离度di;
18.2.5计算虚拟人脸图片n个分块的偏离度di之和d;如d《0,则该虚拟人脸图片为模糊的虚拟人脸图片。
19.进一步的技术方案,设定所述分块的高频阈值ωi的方法为:
20.2.4.1选取多张正常生成的虚拟人脸图片;
21.2.4.2使用步骤2.1-2.3相同的方法,得到正常生成的虚拟人脸图片第i个分块的高频信号之和w
′i;
22.2.4.3求取选取的正常生成的虚拟人脸图片的w
′i的均值μi,令μi为第i个分块的高频阈值ωi。
23.进一步的技术方案,步骤4中,所述待匿名化的人脸图像为:对真实人脸图片或者真实人脸视频帧的亮度进行自适应的gamma校正预处理,得到待匿名化的人脸图像。
24.相对于现有技术,本发明的有益效果在于,
25.1、使用stylegan2生成的虚拟人脸数据集减少了涉及人脸隐私的可能性,提高了人脸隐私保障。并且,对虚拟人脸图片进行频域模糊检测,可以检测出生成效果较差、五官扭曲模糊的虚拟人脸图片并进行排除,完善了虚拟人脸数据集。
26.2、对真实人脸图片或者摄像头采集的真实人脸视频帧,进行人脸亮度重映射的人脸光照预处理,减少了匿名化模型对光线较暗或较亮的人脸图片产生的匿名肤色误差。
附图说明
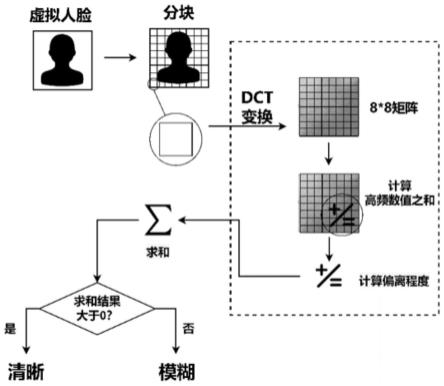
27.图1为频域模糊检测示意图。
28.图2为自适应亮度重映射示意图。
具体实施方式
29.下面结合附图和具体实施例对本发明进一步说明。
30.本发明提供了一种基于风格控制gan的生成式人脸匿名化方法。首先使用stylegan2(style-based generative adversarial networks,基于样式的生成对抗网络)并通过频域模糊检测生成虚拟人脸数据集;再将虚拟人脸数据集输入deepfacelive(深度实时人脸)框架进行人脸匿名化;进行自适应亮度重映射并通过虚拟摄像头得到实时的人脸匿名效果。
31.具体实施例如下:
32.a.虚拟人脸生成阶段:
33.步骤1.应用ffhq数据集进行训练,得到理想的基础人脸生成模型model1;参考stylegan2人脸生成器,将设定参数固定在光照、面部表情、角度三个方面;指定随机生成人脸数量n,基础人脸模型model1根据随机人脸数量n随机组合生成面部特征向量vr,并得到随机人脸。
34.步骤2.指定光照、面部表情、角度向量阈值,将阈值输入向量生成器,生成按线性
分布的人脸调节向量vm;与步骤1中的面部特征向量vr结合,生成微调之后的人脸数据集dataset。
35.步骤3.频域模糊检测,如图1所示:
36.3.1设置阈值参数。阈值参数可以根据经验值进行预设,本实施例给出了一种设定阈值参数的方法,可以得到更准确的模糊检测结果。
37.3.1.1输入1000张正常生成的虚拟人脸图片,即没有扭曲模糊的虚拟人脸图片;
38.3.1.2对生成的图片img进行dct变换,生成n个img
dct
,n向下取整,m和n分别为图片img的长和宽;为减少计算,这里使用8*8dct变换;
[0039][0040]
3.1.3计算图片img
dct
矩阵高频信号之和,记为w;每张图片w的值服从正态分布,记1000张图片相同分块i上的img
dct
高频信号之和的均值为μi,标准差为σi,d(x,y)代表了img
dct
对应坐标的数值;由于对dct矩阵而言右下角代表了高频信号,定义8*8dct矩阵右下角坐标(xa,yb),a、b分布在[4,8]之间;
[0041][0042]
3.1.4设定阈值ωi,低于阈值ωi代表高频信号不足,高于等于阈值ωi代表高频信号保存完整;
[0043]
ωi=μi[0044]
3.2对随机人脸数据集dataset中的图片进行人脸提取,得到人脸图片img;
[0045]
3.3将img的分块i进行8*8dct变换,生成img
dct
,并计算高频部分之和,计算其与ωi的偏离程度,得到的结果记为di;
[0046][0047]
3.4将每一个img
dct
记录的结果进行相加,计算结果记为d,若d《0,则代表高频部分缺失,图像模糊;d≥0,代表高频部分保存完整,图像清晰;
[0048][0049]
3.5将图像模糊的人脸图片删除,对每一个数据集dataset中每一张图片进行上述操作,整理生成的新数据集为data
src
。
[0050]
b.匿名化阶段:
[0051]
步骤1.设定目标数据集data
dst
,目标数据集是公开的ffhq数据集;
[0052]
步骤2.将data
src
和data
dst
共同输入到liae架构的神经网络中进行训练,使用了ssim和和mse作为损失函数对生成的图像进行约束;
[0053]
步骤3.生成面部重演图像,将人脸和训练出的重演图像对齐;将得到的脸部区域的颜色转换至与目标图像的面部颜色相一致;然后采用泊松融合得到融合后的图像;
[0054]
步骤4.保存匿名化模型model。
[0055]
c.人脸亮度重映射阶段(如图2所示,以人脸图像为人脸视频帧为例):
[0056]
步骤1.打开摄像头,从摄像头采集视频帧,记为framei,将framei由rgb图像转化为hsi图像,关注图像的i分量,视频帧坐标(x,y)的亮度值为i(x,y);
[0057]
步骤2.计算framei的亮度值的平均值,记为m;使用gamma校正函数f(i),通过自适应的方式计算参数γ;进行gamma校正,校正结果记为revisei;这里设定i分量范围是[0,255],取127作为中间值;
[0058]
f(i)=i
γ
[0059][0060]
步骤3.将校正后的视频帧revisei与原视频帧frame1进行加权融合,设定加权值为β1、β2,最终生成的图像为outputi,β1、β2的结果由自适应变量γ决定;
[0061]
outputi=framei·
β1+revisei·
β2[0062][0063][0064]
步骤4.将outputi传入匿名化模型model中,得到匿名化后的结果。
[0065]
人脸亮度重映射阶段能够减少模型对光线较暗或较亮的人脸图片产生的匿名肤色误差。实际使用时,待匿名化的人脸图像(真实人脸图片或者摄像头采集的真实人脸视频帧)也可以不经过人脸亮度重映射,直接传入匿名化模型model中,得到匿名化后的结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1