一种业务数据同步到数仓的方法与流程
1.本发明涉及一种数据同步方法,特别是一种业务数据同步到数仓的方法,属于数仓技术领域。
背景技术:
2.在贷款数仓建设过程中,数据最上游的原始业务层数据,我们称为ods数据。ods数据主要有两类:日志数据和业务系统数据。对于日志类数据,由于没有状态,可以通过提供并发的方式来保证ods数据的生产效率。对于业务系统数据,由于其本质上来说是业务过程的变更,存在状态更新的过程,无法简单通过提高并发来达到不变的生产效率。
3.当前日志类数据是通过数据文件同步方式。当前业务系统数据是通过存量数据+增量数据合并的方式生成的,增量数据主要通过数据库的binlog日志(变更日志)采集进入到数仓中。如图2所示,现有技术的业务数据同步过程如下:1、读取各个业务系统的数据库的变更日志到日志交换中心;2、通过kafka软件分发所有订阅了这些数据的数仓;3、通过flink软件实时将kafka上数据库的变更日志数据同步到hive软件中;4、对每张ods表,如果是首次接入,需要先一次性读取全量数据,否则的话,每天基于存量数据和增量数据做delta merge操作,即根据主键去重,按照流水倒序获取记录最终状态并进行增量数据的插入以及存量数据的更新。
4.在上述方案中,最大的瓶颈点在delta merge阶段:用hive sql将全部存量数据读出,然后与增量数据通过唯一键进行合并,保留最新数据,最后再重新写回hive表。ods生产一般比较集中,每个delta merge流程会至少读+写对应的ods表同等量级的数据。delta merge虽然避免了对业务系统的影响,但由于合并过程中要读出全部存量数据再写回最新结果,有较多的io冗余。随着ods的任务数据越来越多,会存在以下几个问题:1. 消耗资源多,2. 数据产出时间不确定,3. 对存储系统压力增大。
技术实现要素:
5.本发明所要解决的技术问题是提供一种业务数据同步到数仓的方法,解决现有技术的不足。
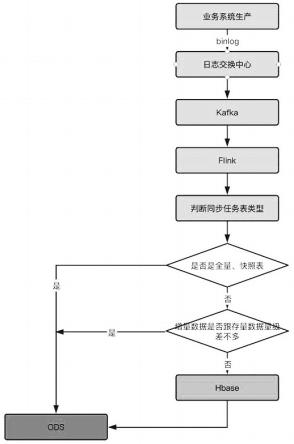
6.为解决上述技术问题,本发明所采用的技术方案是:一种业务数据同步到数仓的方法,其特征在于包含以下步骤:s1、将业务系统生产的binlog日志采集到日志交换中心;s2、日志交换中心采集的数据缓存到kafka软件;s3、通过flink实时获取kafka软件中的数据库的binlog日志数据,并在数据流转到sink组件时进行表类型的判断;s4、判断表类型是否是全量表或快照表,若是,则采用写时merge架构方式,flink直接把数据同步到hive的ods层;
s5、若不是,继续判断增量数据和存量数据的量级,若增量数据的量级远小于存量数据的量级,采用读时merge架构方式,flink把数据同步到hbase中;s6、把hbase中的数据倒入到hive的ods侧,完成整个数据同步。
7.进一步地,所述步骤s1具体为:通过源系统的进程,读取业务系统数据库的binlog日志用以收集变化的数据信息,并判断数据库的binlog日志的变更是否属于被收集对象,然后将其解析到日志交换中心。
8.进一步地,所述步骤s3中表类型判断的过程为:3.1、首先获取数据库中binlog日志的表名;3.2、根据获取的表名去mysql元数据库中查询出对应的ods表名;3.3、根据查询出的对应的ods表直接获取到对应的表类型。
9.进一步地,所述步骤s4中flink直接把数据同步到hive的ods层的具体过程为:flink的sink组件中的数据直接同步到hive的ods层中。
10.进一步地,所述步骤s5中判断增量数据和存量数据的量级的过程为:5.1、存量数据按主键有序存储;5.2、增量数据按照主键有序,直接写入数据集中;5.3、读数据时,对增量数据和存量数据进行归并,得到最终数据集;5.4、当增量数据规模达到一定阈值时,进行一次异步的全量数据merge。
11.进一步地,所述步骤s5中增量数据的量级远小于存量数据的量级的判断过程为:增量数据的量级直接通过统计数据库的binlog日志来获取;存量数据的量级直接通过mysql元数据库查询得到;当增减数据的量级与存量数据的量级的比值小于1/100时,则认为增量数据的量级远小于存量数据的量级。
12.本发明与现有技术相比,具有以下优点和效果:本发明的一种业务数据同步到数仓的方法,使用hbase作为增量数据同步中间存储、定时任务导出hbase数据到hive的方案,对线上业务系统无压力,采用hbase架构低成本实现了mor模型,增量数据生产时延和资源需求大幅度降低,下游作业读数据冗余io影响可控,可以在非生产时间进行数据merge,避免对数据生产的影响,提升资源利用率。
附图说明
13.图1是本发明的一种业务数据同步到数仓的方法的流程图。
14.图2是现有技术的流程图。
具体实施方式
15.为了详细阐述本发明为达到预定技术目的而所采取的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清晰、完整地描述,显然,所描述的实施例仅仅是本发明的部分实施例,而不是全部的实施例,并且,在不付出创造性劳动的前提下,本发明的实施例中的技术手段或技术特征可以替换,下面将参考附图并结合实施例来详细说明本发明。
16.如图1所示,本发明的一种业务数据同步到数仓的方法,包含以下步骤:
s1、将业务系统生产的binlog日志采集到日志交换中心。
17.通过源系统的进程,读取业务系统数据库的binlog日志用以收集变化的数据信息,并判断数据库的binlog日志的变更是否属于被收集对象,然后将其解析到日志交换中心。
18.s2、日志交换中心采集的数据缓存到kafka软件。
19.kafka是由apache软件基金会开发的一个开源流处理平台,由scala和java编写。kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
20.s3、通过flink实时获取kafka软件中的数据库的binlog日志数据,并在数据流转到sink组件时进行表类型的判断。
21.flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。flink 不仅可以运行在包括 yarn、 mesos、kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。
22.步骤s3中表类型判断的过程为:3.1、首先获取数据库中binlog日志的表名;3.2、根据获取的表名去mysql元数据库中查询出对应的ods表名;3.3、根据查询出的对应的ods表直接获取到对应的表类型。
23.s4、判断表类型是否是全量表或快照表,若是,则采用写时merge架构方式,flink直接把数据同步到hive的ods层。
24.步骤s4中flink直接把数据同步到hive的ods层的具体过程为:flink的sink组件中的数据直接同步到hive的ods层中。
25.s5、若不是,继续判断增量数据和存量数据的量级,若增量数据的量级远小于存量数据的量级,采用读时merge架构方式,flink把数据同步到hbase中。
26.步骤s5中判断增量数据和存量数据的量级的过程为:5.1、存量数据按主键有序存储;5.2、增量数据按照主键有序,直接写入数据集中;5.3、读数据时,对增量数据和存量数据进行归并,得到最终数据集;5.4、当增量数据规模达到一定阈值时,进行一次异步的全量数据merge。
27.步骤s5中增量数据的量级远小于存量数据的量级的判断过程为:增量数据的量级直接通过统计数据库的binlog日志来获取;存量数据的量级直接通过mysql元数据库查询得到;当增减数据的量级与存量数据的量级的比值小于1/100时,则认为增量数据的量级远小于存量数据的量级。
28.s6、把hbase中的数据倒入到hive的ods侧,完成整个数据同步。
29.hive没有主键概念;该特性使hive数据集不具备update+insert、delete、多版本高并发控制,进而导致任何有主键数据同步到hive或在hive中建模,都无法明确变更的集合,进而无法构建增量数据生产链路。
30.hbase作为一个开源的nosql数据库,运行于hdfs文件系统之上,生产中主要为hadoop提供类似大表查询的服务。
31.hdfs文件不支持修改;该特性导致了基于hadoop的大数据生态无法通过常规数据库的b+树数据结构覆盖写的方式处理数据,必须基于增量+存量进行合并过程产生最终数据集。
32.delta merge过程的本质是写时合并,即cow(copy on write),与此对应的,在hbase中,使用的是读时合并,即mor(merge on read)的方案。
33.读时合并在读数据时产生冗余io,规模等于增量数据。
34.读时合并异步合并时会有io冗余,规模等于增量+全量数据,但由于累计增量数据达到阈值才会触发,因此产生同等规模冗余io频率小于写时合并。
35.使用hbase作为增量数据同步中间存储,定时任务导出hbase数据到hive的方案,该方案优点如下:1. 对线上业务系统无压力;2. 使用hbase架构低成本实现了mor模型;3. 增量数据生产时延和资源需求大幅降低;4. 下游作业读数据冗余io影响可控;5. 可以在非生产时间进行数据merge,避免对数据生产的影响,提升资源利用率。
36.mor适合增量数据远小于存量数据的数据集,但在增量数据跟存量数据量级差不多或者在全量表、快照表的情况下,效率并没有得到提升,反而有所降低。
37.以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容做出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案内容,依据本发明的技术实质,在本发明的精神和原则之内,对以上实施例所作的任何简单的修改、等同替换与改进等,均仍属于本发明技术方案的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1