一种基于多模型学习集成的动态自适应脑机接口解码方法
1.本发明涉及脑机接口、神经信号解码领域,尤其是涉及一种基于多模型学习集成的动态自适应脑机接口解码方法。
背景技术:
2.脑机接口横跨神经科学、认知科学、计算机科学、控制及信息科学与技术、医学等众多学科领域,现已逐步成为具有变革性影响的前沿交叉研究方向,对于人类与社会具有重大研究意义。
3.侵入式运动脑机接口,借助植入在大脑运动皮层中的微电极阵列采集神经信号,并将其解码成运动信号,旨在于大脑和外部设备之间建立一条直接的神经信息交流与控制通道。该技术有望通过神经信号控制外骨骼与电脑光标等设备,恢复瘫痪病人的部分运动功能。
4.在侵入式运动脑机接口系统中,神经解码算法至关重要。研究人员提出了许多从神经信号中解码运动信息的算法,包括集群向量法、最佳线性估计法、递归贝叶斯解码器和深度神经网络等。
5.在这些方法中,卡尔曼滤波器结合了轨迹的变化过程,将其作为先验知识,以获得更准确的预测,因此被广泛应用于在线光标解码和外骨骼控制中,达到最优在线控制性能。
6.当前的侵入式运动脑机接口使用的解码器大多假设神经信号和运动之间有稳定的函数关系,因此使用一个固定的解码模型。然而,在线解码过程中,采集的神经信号偶尔会引入噪声或者干脆消失;同时,由于神经元具有可塑性,大脑活动模式会随时间或不同行为状态发生改变。上述噪声和改变的存在,使得神经信号到运动信号的映射函数不稳定并且随时间持续变化。固定的解码函数会导致不稳定、不准确的解码结果,因此需要每隔一段时间重新训练以维持一定的性能。
7.针对神经信号不稳定性问题提出的解码器可以被分为两类。第一类仍然使用固定模型,依赖于周期性地重新训练或在线逐步更新模型参数维持性能。第二类使用动态模型追踪神经信号的变化,这可以避免重新训练的代价,更适合长期解码任务。但是,这一类方法中,很少有研究直接对神经信号的不稳定性进行建模。有研究使用多模型动态集成的方式,尝试直接建模神经信号的非稳态性,但是其候选模型池的生成较为随机,依赖于模型权重的随机扰动与神经元的随机丢失。
8.因此,如何构建一个有效的候选模型池,并通过多模型集成建模神经信号的动态性,以得到稳定鲁棒的解码性能,是当前运动神经解码领域亟待解决的重要问题。
技术实现要素:
9.本发明提供了一种基于多模型学习集成的动态自适应脑机接口解码方法,通过数据驱动的方式,自主迭代学习模型池中的模型,并使用这些模型替换卡尔曼滤波器中的观测函数,以实现在线动态集成解码器,来更好地适应神经信号的变化。在解码过程中,根据
贝叶斯更新机制,自动选择和结合这些模型,从而大大降低了神经信号不稳定性对解码性能的影响,提高了解码器的鲁棒性。
10.一种基于多模型学习集成的动态自适应脑机接口解码方法,包括以下步骤:
11.(1)获取原始运动神经信号,进行预处理后按比例分成训练集、验证集和测试集;
12.(2)模型池初始设定,具体包括:
13.(2-1)设定模型池中模型的组数及每组内模型的个数;
14.(2-2)设定每个组别的模型类型;
15.(2-3)设定每个模型初始分配数据占全部数据的比例;
16.(2-4)根据设定分配数据的比例,对于每一个组别,从训练集中为组内的所有模型随机分配一批数据;
17.(3)根据分配的数据学习模型,对于每个组别每个模型,使用被分配到的训练样本,学习所设类型的模型;
18.(4)根据学习到的模型重分配数据,具体包括:
19.(4-1)计算每个模型对每个时刻训练样本的拟合误差;
20.(4-2)对于每个组别,计算得到各个时刻使训练样本误差最小的组内模型,并将该时刻数据分配给该模型;
21.(4-3)对于每个模型被分配到的数据,设置一个接受阈值γ,只接受误差小的一部分数据;
22.(5)对于每个组别,迭代上述步骤(3)至(4),直到在所有训练样本上的预测误差之和小于一个预设值;使用最后一次迭代后学到的所有模型作为候选模型,构建模型池;
23.(6)使用动态贝叶斯多模型集成框架,根据每一个测试样本的神经信号,估计其对应的运动信号:
24.(6-1)使用上述构建的多个候选模型动态表征状态变量与观测变量之间的关系;其中,状态变量为运动信号,观测变量为神经信号;
25.(6-2)根据贝叶斯模型平均法则动态组合模型池中的候选模型,作为状态空间模型的观测函数;
26.(6-3)应用过程中,利用构建的状态空间模型对待解码的神经信号进行状态估计,估计不同候选模型对应的状态并进行集成,得到解码后的运动信号。
27.步骤(1)中,预处理过程为:从硬件设备中获取原始运动神经信号,选择适合的窗口大小计算神经信号发放率,依据状态标签截取有效数据段,对数据进行标准化和平滑操作,得到经过预处理的运动神经信号。
28.作为优选,可去除范式准备与返回阶段的数据,选择实际操作阶段进行分析。
29.作为优选,标准化和平滑操作,可采用matlab中z-score函数和movmean函数,对运动信号的每一个维度进行标准化和平滑操作,对神经信号的每一个神经元的发放频率进行平滑,具体平滑窗口大小可根据实际需求选择。
30.作为优选,步骤(1)中数据的划分,可以按照6:2:2的比例分为训练集、验证集和测试集。
31.步骤(2)中,模型池初始设定如下:
32.设定模型池中模型的组数为g,第g组的组内模型个数为mg,则模型池内模型总数
为m=m1+m2+
…
mg,任意一个模型表示为
[0033][0034]
作为优选,设定每个组别的模型类型候选包括:线性模型,二次多项式模型,神经网络,可使用矩阵表示各组各模型的类型,p
ij
=1代表线性模型,p
ij
=2代表二次多项式模型,p
ij
=3代表神经网络模型,p
ij
=0代表无模型。
[0035]
设定每个模型初始分配数据占全部训练数据的比例为r
seg
;对于每一个组别,从训练集中为组内的所有模型随机分配一批数据,数据长度为其中t
train
为训练集样本数量;
[0036]
每个模型所分配到的训练数据为其中,表示模型所分配到的运动数据,表示模型所分配到的神经数据,d
x
和dy分别表示运动数据和神经数据的特征维度。
[0037]
步骤(3)中,根据分配的数据学习模型的方式如下:
[0038][0039]
其中,表示独立同分布的观测噪声。
[0040]
作为优选,当模型类型为线性模型时,其表达式为作为优选,当模型类型为线性模型时,其表达式为当模型类型为二次多项式模型时,其表达式为当模型类型为二次多项式模型时,其表达式为当模型类型为神经网络时,其表达式为
[0041]
步骤(4)中,根据学习到的模型重分配数据的方式如下:
[0042]
计算每个模型对每个时刻训练样本的预测:
[0043][0044]
其中,表示由模型所预测的所有运动数据对应的神经数据;表示所有运动数据;n表示独立同分布的观测噪声;
[0045]
计算每个模型在所有时刻的误差:
[0046][0047]
其中,表示所有神经数据;表示与y的误差。
[0048]
作为优选,对每个模型在所有时刻的误差做平滑:
[0049][0050]
其中,表示经过平滑的与y的误差,l
smooth
表示平滑窗口大小。
[0051]
对于每个组别,计算得到各个时刻使训练样本平滑误差最小的组内模型,并将该
时刻数据分配给该模型:
[0052][0053][0054]
其中,表示第g组内各模型的误差,每一行代表一个模型的误差;表示每一时刻的训练数据所选择的模型索引;mg表示第g组内,模型的索引;
[0055]
根据每个数据选择的模型,为每个模型(即模型)分配新一轮的训练数据其中表示模型所分配到的运动数据,表示模型所分配到的神经数据,表示第m个模型(即第g组内第mg个模型)所分配到的数据长度。
[0056]
为使得每个模型使用的训练数据具有更高的质量,引入一个接受阈值γ。对于每个模型被分配到的数据,只接受误差较小的前100γ%的数据。因此,最终模型新一轮的训练数据为其中其中表示模型所选择的运动数据,表示模型所选择的神经数据,表示第m个模型所选择的数据长度。
[0057]
步骤(5)中,对于每个组别,迭代过程停止准则为:
[0058]
errorg<βerror
g-1
[0059]
其中,β为预先设定的终止阈值;
[0060]
作为优选,表示该组模型在所有训练数据上的最小误差之和。
[0061]
迭代停止后,构建最终候选模型池
[0062]
步骤(6-1)中,构建的多个候选模型动态表征状态变量与观测变量之间的关系如下:
[0063]
xk=f(x
k-1
)+v
k-1
[0064]
yk=hk(xk)+nk[0065]
其中,k表示离散的时间步长;表示运动数据,即状态变量;表示神经数据,即观测变量;vk、nk表示独立同分布的状态转移噪声和观测噪声;表示k时刻的观测函数由模型池中的模型集成得到,α
k,m
表示每个模型的集成权重。
[0066]
步骤(6-2)中,所述贝叶斯模型平均法则的状态估计如下:
[0067][0068]
式中,是第k时刻选择第m个模型时,状态的后验概率;
是第k时刻选择第m个模型的后验概率,计算公式如下:
[0069][0070]
其中,为第k时刻选择第m个模型的先验概率;pm(yk|y
0:k-1
)为第k时刻选择第m个模型的边缘似然。
[0071]
第k时刻选择第m个模型的先验概率计算公式如下:
[0072][0073]
其中,为第k-1时刻选择第m个模型的概率;α为遗忘因子,0<α<1。
[0074]
第k时刻选择第m个模型的边缘似然计算公式如下:
[0075]
pm(yk|y
0:k-1
)=∫pm(yk|xk)p(xk|y
0:k-1
)dxk[0076]
其中,pm(yk|xk)是关于第m个模型的似然函数。
[0077]
步骤(6-3)中,所述状态估计采用粒子滤波算法,基于粒子计算和
[0078]
步骤(6-3)中,假设此刻为第k个时间步的开始,已知和一个带有权重的粒子集其中ns代表粒子集大小,是权重为的粒子。假设的粒子。假设其中δ(.)代表狄拉克δ函数,下面展示如何使用粒子滤波计算和
[0079]
(6-3-1)基于粒子滤波的首先,从状态转移先验中获得然后根据重要性采样原则,可得:
[0080][0081]
其中,代表当选择第m个模型时,第i个粒子归一化后的重要性权重。
[0082]
(6-3-2)基于粒子滤波的给定首先使用步骤(6-2)中遗忘因子计算的先验概率。在似然pm(yk|y
0:k-1
),m=1,
…
,m已知的情况下,可计算的后验概率在所述步骤3-1中,状态转移先验被用作重要性函数,即q(xk|x
k-1
,y
0:k
)=p(xk|x
k-1
)。因此,xk的分布可由粒子近似得到,即进而可得:
[0083][0084]
值得注意的是,粒子滤波通常有粒子退化问题,经过几次迭代后,只有少量粒子具有较高的权重。因此,采用重采样方法去除权重过小或过大的粒子来减轻粒子退化问题。
[0085]
本发明基于传统状态空间模型以及粒子滤波,提出了一种基于多模型学习集成的动态自适应脑机接口解码方法应用于神经信号解码,在一定程度上减少了因神经信号不稳定性带来的影响。在测试中优于卡尔曼滤波算法,证明了该方法的有效性。
附图说明
[0086]
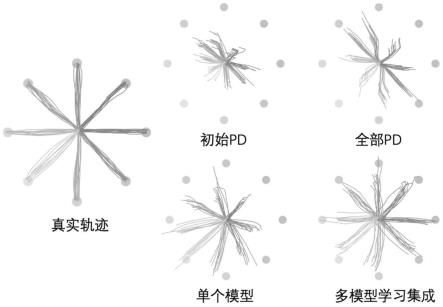
图1为本发明采用的多模型学习集成方法在仿真数据上的解码轨迹与其他方法的对比图;
[0087]
图2为本发明的多模型学习集成方法在训练时不同模型的数据分配情况和在测试时不同模型的权重变化情况;
[0088]
图3为本发明实施例中多模型学习集成方法在猴子避障数据集上使用两个模型分别刻画顺时针trial与逆时针trial的可视化结果。
具体实施方式
[0089]
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
[0090]
本研究采用多个数据集,包括一个仿真数据集,及两个猴子数据集(center-out数据集和避障数据集)。
[0091]
一种基于多模型学习集成的动态自适应脑机接口解码方法,包括以下步骤:
[0092]
(1)运动神经信号预处理:从硬件设备中获取原始运动神经信号,选择适合的窗口大小计算神经信号发放率,依据状态标签截取有效数据段,对数据进行标准化和平滑操作,得到经过预处理的运动和神经信号;将数据按照合理的比例分成训练集、验证集、测试集。
[0093]
具体而言,实验使用neuroport系统(nsp,blackrock microsystems)记录神经信号。神经活动经过放大、数字化后,以30khz的频率进行记录。使用central软件包(blackrock microsystem)将每个经过高通滤波(250hz截止频率)的电极的神经动作电位检测的阈值分别设置为-6.5rms到-5.5rms。在每项日常任务开始时,研究人员会手动对锋电位进行分类,这大约需要25到35分钟。峰值活动被转换为20ms中的发放率,并使用具有450ms窗口的指数平滑函数进行低通滤波。
[0094]
(2)模型池初始设定,具体包括:
[0095]
设定模型池中模型的组数为g,第g组的组内模型个数为mg,则模型池内模型总数为m=m1+m2+
…
mg,任意一个模型可以表示为
[0096][0097]
设定每个组别的模型类型候选包括:线性模型,二次多项式模型,神经网络,可使用矩阵表示各组各模型的类型,p
ij
=1代表线性模型,p
ij
=2代表二次多项式模型,p
ij
=3代表神经网络模型,p
ij
=0代表无模型。
[0098]
在本实例在线实验中,使用4组线性模型,每组分别包含4、6、8、10个线性模型:
[0099][0100]
在本实例离线实验中,使用3组模型,第一组为线性模型,第二组为二次多项式模型,第三组为神经网络模型,每组分别包含5个模型:
[0101][0102]
(3)根据分配的数据学习模型:
[0103][0104]
其中,表示独立同分布的观测噪声。
[0105]
当模型类型为线性模型时,其表达式为当模型类型为二次多项式模型时,其表达式为型为二次多项式模型时,其表达式为当模型类型为神经网络时,其表达式为类型为神经网络时,其表达式为
[0106]
离线实验中,神经网络为多层感知机,其输入层为运动信号的维度,输出层为神经信号的维度,包含一层隐藏层,隐藏层节点数设为50。
[0107]
(4)根据学习到的模型重分配数据,具体包括:
[0108]
计算每个模型对每个时刻训练样本的预测:
[0109][0110]
其中,表示由模型所预测的所有运动数据对应的神经数据;表示所有运动数据;n表示独立同分布的观测噪声。
[0111]
计算每个模型在所有时刻的误差:
[0112][0113]
其中,表示所有神经数据;表示与y的误差。
[0114]
对每个模型在所有时刻的误差做平滑:
[0115][0116]
其中,表示经过平滑的与y的误差,l
smo
表示平滑窗口大小。
[0117]
在本实例中,平滑窗口大小设置为10个时间步。
[0118]
对于每个组别,计算得到各个时刻使训练样本平滑误差最小的组内模型,并将该时刻数据分配给该模型:
[0119][0120]
[0121]
其中,表示第g组内各模型的误差,每一行代表一个模型的误差;表示每一时刻的训练数据所选择的模型索引;mg表示第g组内,模型的索引。
[0122]
根据每个数据选择的模型,为每个模型(即模型)分配新一轮的训练数据其中表示模型所分配到的运动数据,表示模型所分配到的神经数据,表示第m个模型(即第g组内第mg个模型)所分配到的数据长度。
[0123]
对于每个模型被分配到的数据,只接受误差较小的在前100γ%的数据。因此,最终模型新一轮的训练数据为其中其中表示模型所选择的运动数据,表示模型所选择的神经数据,表示第m个模型所选择的数据长度。
[0124]
在本实例中,模型的接受阈值γ设置为0.3。
[0125]
(5)对于每一组别,所述迭代过程停止准则为:
[0126]
errorg<βerror
g-1
[0127]
其中,β为预先设定的终止阈值,表示该组模型在所有训练数据上的最小误差之和。
[0128]
在本实例中,终止阈值β设为1e-3。
[0129]
迭代停止后,构建最终候选模型池
[0130]
(6)基于动态集成的状态空间模型:
[0131]
(6-1)、扩展的观测模型:对传统状态空间模型进行扩展,使用上述所学习到的一组模型而非一个固定的函数(即候选模型)来动态表征观测变量与状态变量之间的关系。
[0132]
传统的状态空间模型由一个状态转移函数f(
·
)和一个观测函数h(
·
)组成:
[0133]
xk=f(x
k-1
)+v
k-1
[0134]
yk=h(xk)+nk[0135]
其中,k表示离散时间步长;表示运动信号;表示神经信号;vk、nk表示独立同分布的状态转移噪声和观测噪声。
[0136]
在神经解码领域,给定一个神经信号序列y
0:k
,其目标是迭代估计xk的概率密度。当神经信号与运动信号都满足线性高斯的假设时,卡尔曼滤波器可以提供最优解析解。
[0137]
传统状态空间模型的观测函数h(
·
)是事先计算好的,不能适应变化的神经信号。步骤(6)中的观测模型对其进行了改进:允许观测函数在线调整。改进后的状态空间模型表达如下:
[0138]
xk=f(x
k-1
)+v
k-1
[0139]
yk=hk(xk)+nk[0140]
其中,k表示离散的时间步长;表示运动数据,即状态变量;表示神经数据,即观测变量;vk、nk表示独立同分布的状态转移噪声和观测噪声;表示k时刻的观测函数由模型池中的模型集成得到,α
k,m
表示每个模型的集成权重。
[0141]
在模型集中的模型,类似于神经编码器,可以将输入的动力学参数x
t
转换为神经信号y
t
。
[0142]
(6-2)、贝叶斯模型平均法则估计状态:
[0143][0144]
式中,是第k时刻选择第m个模型时,状态的后验概率;是第k时刻选择第m个模型的后验概率,即α
k,m
。
[0145]
第k时刻选择第m个模型的后验概率计算公式如下:
[0146][0147]
其中,为第k时刻选择第m个模型的先验概率;pm(yk|y
0:k-1
)为第k时刻选择第m个模型的边缘似然。
[0148]
第k时刻选择第m个模型的先验概率计算公式如下:
[0149][0150]
其中,为第k-1时刻选择第m个模型的概率;α为遗忘因子,0<α<1。
[0151]
在本实例中,遗忘因子设置从0.1~0.9不等。当遗忘因子设为0.9时,极大程度上考虑了前向时刻运动状态的影响,因此使得解码出的运动状态更加平滑。
[0152]
第k时刻选择第m个模型的边缘似然计算公式如下:
[0153]
pm(yk|y
0:k-1
)=∫pm(yk|xk)p(xk|y
0:k-1
)dxk[0154]
其中,pm(yk|xk)是关于第m个模型的似然函数。
[0155]
(6-3)、学习候选模型并进行状态估计:使用训练集和验证集得到一组不同的候选模型。可基于粒子滤波算法,在每一个时间步使用加权粒子集为每个候选模型估计运动状态,基于粒子计算和
[0156]
假设此刻为第k个时间步的开始,已知假设此刻为第k个时间步的开始,已知和一个带有权重的粒子集其中ns代表粒子集大小,是权重为的粒子。假设其中δ(.)代表狄拉克δ函数,下面展示如何使用粒子滤波计算和
[0157]
(6-3-1)、基于粒子滤波的
[0158]
首先,从状态转移先验中获得然后根据重要性采样
原则,可得:
[0159][0160]
其中,代表当选择第m个模型时,第i个粒子归一化后的重要性权重。
[0161]
本实例中,采用训练集作为粒子集,避免了随机撒粒子带来的不稳定性。
[0162]
(6-3-2)、基于粒子滤波的
[0163]
给定首先使用步骤(6-2)中遗忘因子计算的先验概率。在似然pm(yk|y
0:k-1
),m=1,
…
,m已知的情况下,可计算的后验概率在所述步骤3-1中,状态转移先验被用作重要性函数,即q(xk|x
k-1
,y
0:k
)=p(xk|x
k-1
)。因此,xk的分布可由粒子近似得到,即进而可得:
[0164][0165]
值得注意的是,粒子滤波通常有粒子退化问题,经过几次迭代后,只有少量粒子具有较高的权重。因此,采用重采样方法去除权重过小或过大的粒子来减轻粒子退化问题。
[0166]
(7)多模型学习集成方法的性能评估:在测试集数据中使用本方法与其他方法对比,评估本方法性能与有效性。
[0167]
本实例采样多个数据集,包括一个仿真数据集,两个猴子数据集(center-out数据集和避障数据集)以及一个临床在线控制数据集。如图1所示,展示了仿真数据集上的解码轨迹。仿真数据使用鼠标绘制运动轨迹,将每一个trial分成三个阶段,每个阶段为每个神经元设定不同的偏好方向(preferred direction,pd),由此生成仿真神经信号。与多模型学习集成方法对比的方法分别是“全部pd”、“初始pd”、“单个模型”。其中,“全部pd”表示使用训练数据的每个trial的全部数据拟合出一个pd,使用群体向量法解码;“初始pd”表示使用训练数据的每个trial的初始一部分数据拟合出一个pd,使用群体向量法解码;“单个模型”表示使用训练数据的每个trial的全部数据拟合出一个线性编码模型,并且使用粒子滤波进行解码。从图1可以看出,本发明的多模型学习集成方法的解码轨迹最接近真实轨迹,表明了该方法的有效性。
[0168]
如图2所示,使用猴子center-out数据集,画出了四个方向各个trial在训练过程中的每个模型所选择的数据情况以及测试过程中每个模型权重的变化情况。可以看到对于相同方向的运动,模型的变化展示出了可重复性,表明多模型学习具有有效性。
[0169]
如图3所示,使用了猴子避障数据集,使用了两个模型。其展示了第一个模型偏好逆时针方向的运动,第二个模型偏好顺时针方向的运动,这从直观上解释了本发明多模型学习集成方法有效的原因。
[0170]
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1