基于隐私安全计算平台的专病数据库构建方法及装置
1.本技术涉及计算机技术领域,具体涉及一种基于隐私安全计算平台的专病数据库构建方法及装置。
背景技术:
2.传统的医疗统计方式需要从院内系统或平台中将原始数据导出平台外利用自行开发或第三方开发的模型进行计算,这样做会造成原始数据离开平台,而平台失去对于这部分数据的安全和权益保护。如果这个第三方未经平台授权将数据作为其他用途,或者擅自将数据发送给其他人使用,都可能会造成患者个人信息泄露,有损患者利益,违反相关法律法规,带来灾难性的后果。
技术实现要素:
3.为此,本技术提供一种基于隐私安全计算平台的专病数据库构建方法及装置,以解决现有技术存在的医疗统计方式需要从院内系统或平台中将原始数据导出平台外利用自行开发或第三方开发的模型进行计算的问题。
4.为了实现上述目的,本技术提供如下技术方案:
5.第一方面,一种基于隐私安全计算平台的专病数据库构建方法,应用于隐私安全计算平台,包括:
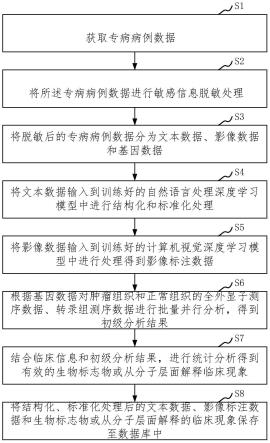
6.获取专病病例数据;
7.将所述专病病例数据进行敏感信息脱敏处理;
8.将脱敏后的专病病例数据分为文本数据、影像数据和基因数据;
9.将文本数据输入到训练好的自然语言处理深度学习模型中进行结构化和标准化处理;
10.将影像数据输入到训练好的计算机视觉深度学习模型中进行处理得到影像标注数据;
11.根据基因数据对肿瘤组织和正常组织的全外显子测序数据、转录组测序数据进行批量并行分析,得到初级分析结果;
12.结合临床信息和初级分析结果,进行统计分析得到有效的生物标志物或从分子层面解释临床现象;
13.将结构化、标准化处理后的文本数据、影像标注数据和生物标志物或从分子层面解释的临床现象保存至数据库中。
14.进一步的,所述结构化和标准化处理具体为:将文本数据分解为医学事件矢量。
15.进一步的,所述自然语言处理深度学习模型包括双向长短时记忆网络模型、条件随机场模型、transforme模型、bert模型和gpt-3模型。
16.进一步的,所述计算机视觉深度学习模型包括卷积神经网络模型、自编码器模型、yolo模型或ssd模型。
17.进一步的,所述统计分析包括差异检验和关联分析。
18.进一步的,所述影像数据包括pacs系统影像数据和病理系统影像数据。
19.进一步的,所述初级分析结果包括基因的突变信息、表达量信息和免疫细胞浸润得分。
20.第二方面,一种基于隐私安全计算平台的专病数据库构建装置,包括:
21.专病病例数据获取模块,用于获取专病病例数据;
22.脱敏处理模块,用于将所述专病病例数据进行敏感信息脱敏处理;
23.分类模块,用于将脱敏后的专病病例数据分为文本数据、影像数据和基因数据;
24.文本处理模块,用于将文本数据输入到训练好的自然语言处理深度学习模型中进行结构化和标准化处理;
25.影像数据处理模块,用于将影像数据输入到训练好的计算机视觉深度学习模型中进行处理得到影像标注数据;
26.基因数据处理模块,用于根据基因数据对肿瘤组织和正常组织的全外显子测序数据、转录组测序数据进行批量并行分析,得到初级分析结果;
27.结合临床信息和初级分析结果,进行统计分析得到有效的生物标志物或从分子层面解释临床现象;
28.数据库模块,用于将结构化、标准化处理后的文本数据、影像标注数据和生物标志物或从分子层面解释的临床现象保存至数据库中。
29.第三方面,一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现基于隐私安全计算平台的专病数据库构建方法的步骤。
30.第四方面,一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现基于隐私安全计算平台的专病数据库构建方法的步骤。
31.相比现有技术,本技术至少具有以下有益效果:
32.本技术提供了一种基于隐私安全计算平台的专病数据库构建方法及装置,包括:基于原始数据不出域,通过数据与计算协同建立数据价值输出的新方式,实现专病库建设和专病数据安全共享协作地新范式。应用隐私安全计算平台技术构建专病库,动态实现多维度、多模态专病数据全生命周期管理与资产化医疗健康数据管理新范式。应用人工智能前沿技术在数据治理、文本数据结构化、影像数据智能处理等过程中,有助于节约数据治理处理过程的时间,且获得更高质量的标准化、结构化数据。
33.建立专病库数据使用授权机制,以可用可见、可用不可见等方式实现专病数据集的申请使用授权。专病库平台支持第三方应用开放,在专病库临床文本、医学图像、生物信息数据方面,根据具体数据模态及数据处理需要,可自建或使用成熟工作流或应用来处理、分析数据。实现了不同学科领域工作者的协作。在临床文本、医学图像、生物信息数据处理方面,各协作者可以在安全可信的工作空间进行项目协作,从而建立起一种专病数据管理和科研协作的长效安全共享机制,并可不断延伸专病研究能力。
附图说明
34.为了更直观地说明现有技术以及本技术,下面给出几个示例性的附图。应当理解,
附图中所示的具体形状、构造,通常不应视为实现本技术时的限定条件;例如,本领域技术人员基于本技术揭示的技术构思和示例性的附图,有能力对某些单元(部件)的增/减/归属划分、具体形状、位置关系、连接方式、尺寸比例关系等容易作出常规的调整或进一步的优化。
35.图1为本技术实施例一提供的一种基于隐私安全计算平台的专病数据库构建方法流程图;
36.图2为本技术实施例一提供的隐私安全计算平台结构示意图;
37.图3为本技术实施例一提供的专病数据采集、治理、数据安全共享协作生态的结构示意图。
具体实施方式
38.以下结合附图,通过具体实施例对本技术作进一步详述。
39.在本技术的描述中:除非另有说明,“多个”的含义是两个或两个以上。本技术中的术语“第一”、“第二”、“第三”等旨在区别指代的对象,而不具有技术内涵方面的特别意义(例如,不应理解为对重要程度或次序等的强调)。“包括”、“包含”、“具有”等表述方式,同时还意味着“不限于”(某些单元、部件、材料、步骤等)。
40.本技术中所引用的如“上”、“下”、“左”、“右”、“中间”等的用语,通常是为了便于对照附图直观理解,而并非对实际产品中位置关系的绝对限定。在未脱离本技术揭示的技术构思的情况下,这些相对位置关系的改变,当亦视为本技术表述的范畴。
41.隐私安全计算的价值主张是不分享原始数据,通过计算来分享数据的价值。隐私安全计算平台采用的安全架构对数据全生命周期过程中的网络、存储和计算提供全面的安全保障。
42.在网络安全层面,隐私安全计算平台通过网关对外提供注册过的服务。平台注册服务和外部通讯时,需要通过数据服务网关审核、记录和中转,确保数据字段、格式和注册内容完全一致,在一致的基础上中转通讯内容并加以记录存证。另外,所有应用实例内部和对外通讯全部加密,保障网络安全。
43.在存储安全层面,隐私安全计算平台的所有数据都由对应的平台用户对于数据使用进行管理,简称数据所有者。静态数据分块加密,通过密钥管理系统管理数据密钥,只有对应的数据所有者才能够使用数据密钥解密使用原始数据。当一个用户向数据所有者申请使用其数据并获得授权后,系统会产生一个数据密钥的加密副本供该用户使用,在授权时限结束时删除该副本。在平台项目计算过程中的所有中间数据落盘都会加密,杜绝项目之外的任何用户窃取项目机密。
44.在计算安全层面,隐私安全计算平台采用增强的安全容器为应用和系统os之间的提供了额外的隔离和保护。平台为应用实例构建网络隔离的计算环境,保证应用所有的对外注册服务都必须通过平台网关,同时屏蔽其他任何和计算环境之外的通讯。在计算过程中,数据首先加密地传输到安全沙箱,在沙箱内经过解密后并计算,计算完成后会删除所有的计算环境和中间数据,只输出计算结果。如果在硬件层面配有tee硬件,可以进一步降低host os和系统管理员带来的数据安全风险。
45.在数据使用授权机制方面,隐私安全计算平台平台支持“可用可见”、“可用不可
见”等多种数据授权使用方式。在数据“可用不可见”的授权使用方式中,用户必须使用满足“可用不可见”要求的应用来处理数据,在数据使用过程中完全接触不到原始数据,进一步保证数据应用过程中的安全和隐私保护。
46.本技术基于患者主索引信息,建立患者各种维度如电子病历数据(emr)、影像数据、生物信息数据、病理数据等的关联关系,并建立起以患者为中心的专病数据库。
47.实施例一
48.请参阅图1和图2,本实施例提供了一种基于隐私安全计算平台的专病数据库构建方法,应用于隐私安全计算平台,包括:
49.s1:获取专病病例数据;
50.s2:将所述专病病例数据进行敏感信息脱敏处理;
51.s3:将脱敏后的专病病例数据分为文本数据、影像数据和基因数据;
52.s4:将文本数据输入到训练好的自然语言处理深度学习模型中进行结构化和标准化处理;
53.具体的,文本数据一般来自于emr(门急诊病历、住院病历等)、his、检验检查报告如影像检查报告、病理报告等。患者的一诉五史、体格检查和检验检查报告等诸多信息均为自然语言文本,因此计算机分析需要将其中信息分解为细颗粒度的基本单元—医学事件矢量,它包含文字描述、时间、数值和附加描述等信息,表达最小粒度的医学信息,如[2012-01-03,发热,1(表示发生),持续|高热]。上述过程称之为结构化,文字内容转化为结构化后的信息,才能保证计算机真正理解了文本内容,从而为下游数据分析应用提供了良好的数据基础。
[0054]
在医学事件矢量生成的过程中,有一个非常重要的步骤—描述规范化,即用标准的语言描述意义相同的内容。医学文书因其来源、撰写者等不同,内容中的原始文字存在差异,无法直接使用,因此构建“医学普通话”—即标准化术语势在必行。基于umls标准化术语,并结合中国临床医学的习惯进行本地化和扩展,形成一套完备的“标准化词汇字典”—主数据,支持对于常见科研医学概念,注入部位、症状、体征、检验指标、治疗和药品等内容的表达。在主干概念的架构上,再配之以众多的修饰符(modifier)支持更多更丰富更细致的描述。
[0055]
综上所述,文本数据均转换为医学矢量,以备今后科研分析使用。
[0056]
更具体的,结构化和标准化处理需要构建自然语言处理(natural language processing,nlp)深度学习模型进行解决。对于专病医学文本信息抽取(实体识别、关系抽取和事件抽取)、医学术语标准化、医学文本分类、医学句子语义关系判定、医学对话理解与生成多种任务构建不同的nlp模型如双向长短时记忆网络(bi-directional long short term memory,bilstm)、条件随机场(conditional random field,crf)和transformer等模型,以及大型预训练模型bert和gpt-3等模型的使用,并结合其他模态的数据完成相应任务的解决。
[0057]
s5:将影像数据输入到训练好的计算机视觉深度学习模型中进行处理得到影像标注数据;
[0058]
具体的,影像数据一般包括pacs系统影响数据和病理系统影像数据。针对结病种,构建独立的模型预标注信息库,其中包含ai预标注的病灶位置和大小等信息。每条模型预
判信息均记录模型版本信息,确保同一套影像数据可以拥有不同版本模型的多条预标注信息。
[0059]
更具体的,针对医疗影像数据处理的问题,构建计算机视觉(computer vision,cv)深度学习模型进行解决。在专病领域,通过建立深度学习中卷积神经网络(convolutional neural network,cnn)、自编码器(auto-encoder,ae)等模型,以及基于这些基础模型发展的复杂模型,如yolo,ssd模型等,从传统的医学影像学图像中自动学习、提取和分析与临床终点和病灶相关的影像特征,在图像中进行感兴趣区域(region of interest,roi)或感兴趣体积(volume of interest,voi)的分割配准和预测标记,以完成病灶预标注任务。
[0060]
s6:根据基因数据对肿瘤组织和正常组织的全外显子测序数据、转录组测序数据进行批量并行分析,得到初级分析结果;
[0061]
具体的,基因数据主要以二代测序数据为主;基于业界成熟的商业软件sentieon和其他知名的开源软件如samtools、picard、vep、star、salmon、quantiseq等创建完整的全链条分析流程。从原始数据出发,对肿瘤组织和正常组织的全外显子测序数据、转录组测序数据进行批量并行分析,从而得到基因的突变信息、表达量信息和免疫细胞浸润得分等初级分析结果。
[0062]
s7:结合临床信息和初级分析结果,进行统计分析得到有效的生物标志物或从分子层面解释临床现象;
[0063]
具体的,结合临床信息和初级分析结果,通过r或python等编程语言进行各种探索性的统计分析如差异检验、关联分析等等,最后挖掘出有效的生物标志物或从分子层面解释临床现象。
[0064]
s8:将结构化、标准化处理后的文本数据、影像标注数据和生物标志物或从分子层面解释的临床现象保存至数据库中。
[0065]
本实施例中,无论是基于文本,影像,还是病理数据集进行模型训练时,均需在准备数据过程中尽量达到样本的无偏和均衡,以保证在训练过程中可以学习到弱势类特征。在定义好数据集之后,根据任务的属性选择相应的算法模型来进行模型的训练,如专病领域下文本和病理数据问题下的nlp模型或其影像数据问题下的cv模型,定义任务相关损失函数(loss function),解决适定性问题或过拟合而加入额外信息来进行正则化(regularization),选择合适的优化器(optimizer),进行梯度下降(garident descent)的迭代训练,根据学习率更新模型参数,降低任务loss,以解决任务领域内的无约束优化问题。无论文本,影像还是病理数据任务上,已经有很多较为成熟的模型和方法以供使用,同时在模型训练中遇到的问题可用不同的方法予以解决,迁移学习(transfer learning)用以将其他医学病理领域的任务上学习到的知识或模式应用到专病领域问题中。元学习(meta learning)用以在专病部分问题数据量稀少的情况下进行模型训练,神经网络搜索(nerual architecture search,nas)用以代替人工自动设计出高效的网络结构等。
[0066]
本实施例构建的专病库,采用隐私计算的方式,从医疗信息系统或者外部测序设备采集来的临床文本数据、影像数据、基因组学数据、病理数据等形成以患者为中心的专病数据集,在对专病数据集的数据开展应用协作时,原始数据不离开基于隐私安全计算的专病库平台,支持第三方应用开放,第三方合作者或技术服务方将算法模型或处理方法放入
该平台开展数据与应用的计算,并只输出数据的计算结果部分,即输出数据的价值部分。对专病的数据清洗、治理、ai模型训练、数据分析等科研协作和数据管理均在平台内完成。
[0067]
请参见图3,专病库平台致力于建立应用开放的专病数据采集、治理、数据安全共享协作生态。其中有数据的需求方、服务方、提供方和管理方。平台数据使用授权方式包括可用可见和可用不可见两种方式。医院,科室或医疗组或个人均可以作为各自数据所有者,数据需求方向数据所有者申请授权使用,确保平台用户在数据所有者授权后才能在平台内使用数据。以科研检索为例,不同条件组合查询出不同数据集满足条件的检索结果,平台会给出符合查询条件的数量统计信息和相应字段名,但不可见字段名下具体数据内容。这就是典型的专病数据“可用不可见”场景;若数据使用者向专病库数据所有者申请授权可用可见使用,只有在被授权后,该数据才可看见。
[0068]
当已经建成了多个基于隐私安全计算的专病库平台后,还可以利用隐私计算的方法,连接多个专病库,用“可用不可见”的方式进行联合建模,既可以扩充样本,也可以扩充特征,以提高模型精度。
[0069]
实施例二
[0070]
本实施例提供一种基于隐私安全计算平台的专病数据库构建装置,包括:
[0071]
专病病例数据获取模块,用于获取专病病例数据;
[0072]
脱敏处理模块,用于将所述专病病例数据进行敏感信息脱敏处理;
[0073]
分类模块,用于将脱敏后的专病病例数据分为文本数据、影像数据和基因数据;
[0074]
文本处理模块,用于将文本数据输入到训练好的自然语言处理深度学习模型中进行结构化和标准化处理;
[0075]
影像数据处理模块,用于将影像数据输入到训练好的计算机视觉深度学习模型中进行处理得到影像标注数据;
[0076]
基因数据处理模块,用于根据基因数据对肿瘤组织和正常组织的全外显子测序数据、转录组测序数据进行批量并行分析,得到初级分析结果;
[0077]
结合临床信息和初级分析结果,进行统计分析得到有效的生物标志物或从分子层面解释临床现象;
[0078]
数据库模块,用于将结构化、标准化处理后的文本数据、影像标注数据和生物标志物或从分子层面解释的临床现象保存至数据库中。
[0079]
实施例三
[0080]
本实施例提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现基于隐私安全计算平台的专病数据库构建方法的步骤。
[0081]
实施例四
[0082]
本实施例提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现基于隐私安全计算平台的专病数据库构建方法的步骤。
[0083]
本技术提供的基于隐私安全计算平台的专病数据库构建方法及装置,基于原始数据不出域,通过数据与计算协同建立数据价值输出的新方式,实现专病库建设和专病数据安全共享协作地新范式。应用隐私安全计算前沿平台软件技术构建专病库,动态实现多维度、多模态专病数据全生命周期管理与资产化医疗健康数据管理新范式。应用人工智能前沿技术在数据治理、文本数据结构化、影像数据智能处理等过程中,有助于节约数据治理处
理过程的时间,且获得更高质量的标准化、结构化数据。建立起专病库数据使用授权机制,以可用可见、可用不可见等方式实现专病数据集的申请使用授权。专病库平台支持第三方应用开放,在专病库临床文本、医学图像、生物信息数据方面,根据具体数据模态及数据处理需要,可自建或使用成熟工作流或应用来处理、分析数据,实现了不同学科领域工作者的协作。在临床文本、医学图像、生物信息数据处理方面,各协作者可以在安全可信的工作空间进行项目协作。从而建立起一种专病数据管理和科研协作的长效安全共享机制,并可不断延伸专病研究能力。
[0084]
以上实施例的各技术特征可以进行任意的组合(只要这些技术特征的组合不存在矛盾),为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述;这些未明确写出的实施例,也都应当认为是本说明书记载的范围。
[0085]
上文中通过一般性说明及具体实施例对本技术作了较为具体和详细的描述。应当理解,基于本技术的技术构思,还可以对这些具体实施例作出若干常规的调整或进一步的创新;但只要未脱离本技术的技术构思,这些常规的调整或进一步的创新得到的技术方案也同样落入本技术的权利要求保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1