一种基于知识图谱语义嵌入的旅游景点推荐方法
1.本发明属于知识图谱和推荐系统领域,具体涉及一种基于知识图谱语义嵌入的旅游景点推荐方法。
背景技术:
2.推荐系统是近年来数据挖掘和信息检索领域的研究热点,在电子商务、电影、音乐、社交网络、阅读等方面都有很广泛的应用。在实际场景中,推荐系统的训练需要的数据来源于用户的点击、收藏、点赞、关注等行为,这些数据往往会使推荐系统面临数据稀疏性问题、冷启动问题、新物品问题、新用户问题、缺少用户评论问题等。
3.目前主流推荐方法有:基于内容的推荐、协同过滤推荐、基于关联规则推荐;其中基于内容的推荐能根据用户的兴趣和行为进行推荐,但是要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,需要进行特征交互操作,并且用户的偏好必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况;协同过滤推荐将用户与商品结合形成一个共现矩阵,矩阵中的值表示用户的评分,该方法使推荐系统有较好的可解释性,但由于数据量过大通常会导致共现矩阵很大,进而需要消耗大量的内存,同时共现矩阵会很稀疏,造成计算机资源的浪费;基于关联规则是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则挖掘可以发现不同商品在销售过程中的相关性,但是算法的第一步关联规则的发现最为关键且最耗时,是算法的瓶颈,但可以离线进行。
4.针对以上主流推荐方法中存在数据运算量大,使得需要消耗大量的内存,造成资源浪费,且推荐结果不精确的问题,继续要一种新的推荐方法。
技术实现要素:
5.为解决以上现有技术存在的问题,本发明提出了一种基于知识图谱语义嵌入的旅游景点推荐方法,该方法包括:
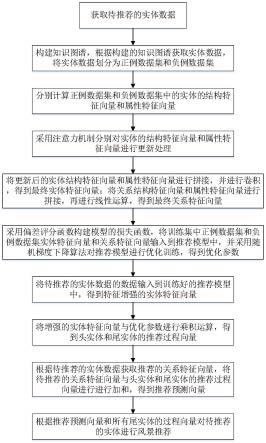
6.s1:获取待推荐的实体数据;所述实体数据包括实体的属性、实体与实体之间的关系属性,其中实体包括头实体和尾实体;
7.s2:构建知识图谱,根据构建的知识图谱获取实体数据,将实体实体数据划分为训练集,将训练集中的实体数据划分为正例数据集和负例数据集;
8.s3:分别计算正例数据集和负例数据集中的实体的结构特征向量和属性特征向量;
9.s4:采用注意力机制分别对实体的结构特征向量和属性特征向量进行更新处理;
10.s5:将更新后的实体结构特征向量和属性特征向量进行拼接,对拼接后的实体向量进行卷积,得到最终实体特征向量;将关系结构特征向量和属性特征向量进行拼接,对拼接后的向量进行线性运算,得到最终关系特征向量;
11.s6:采用偏差评分函数构建模型的损失函数,将训练集中正例数据集和负例数据集实体特征向量和关系特征向量输入到推荐模型中,并采用随机梯度下降算法对推荐模型
进行优化训练,得到优化参数;
12.s7:将待推荐的实体数据的数据输入到训练好的推荐模型中,得到特征增强的实体特征向量;
13.s8:将增强的实体特征向量与优化参数进行乘积运算,得到头实体和尾实体的推荐过程向量;
14.s9:根据待推荐的实体数据获取推荐的关系特征向量,将待推荐的关系特征向量与头实体和尾实体的推荐过程向量进行进行加和,得到推荐预测向量;
15.s10:根据推荐预测向量和所有尾实体的过程向量对待推荐的实体进行风景推荐。
16.优选的,采用注意力机制分别对实体的结构特征向量和属性特征向量进行更新处理的过程包括:对实体的结构特征向量进行更新包括将实体结构嵌入作为结构注意力机制层的输入,通过实体的上下文节点计算出注意力分数,根据注意力分数对结构特征向量进行更新;对属性特征向量进行更新包括:将实体属性嵌入和关系属性嵌入作为属性注意力机制层的输入,计算出头实体与尾实体的增强属性特征向量,根据增强属性特征向量对属性特征向量进行更新。
17.进一步的,对实体的结构特征向量进行更新的公式为:
[0018][0019][0020]
σ(s)=sigmoid(w1s+b1)
[0021]
其中,dn表示一个实体节点的邻居节点集合,αi表示第i个节点的注意力分数,σ(
·
)表示sigmoid函数,w1表示权重参数,b1表示偏置。
[0022]
进一步的,尾实体的属性特征计算公式与头实体的属性特征计算公式相似;其中尾实体的属性特征计算公式为:
[0023][0024][0025]
π(ah,ar)=tanh(w2ah+ar+b2)
[0026]
其中,en表示一个尾实体对应的头实体集合,α表示在en中头实体的注意力分数,π(
·
)表示激活函数,a
t
表示尾实体的属性特征向量,h表示头实体,r表示关系,ah表示头实体的属性特征向量,ar表示关系的属性特征向量,h
′
表示一个尾实体对应的其中一个头实体,r
′
表示尾实体t与头实体h
′
之间的关系,ah′
表示头实体h
′
的属性特征向量,ar′
表示关系r
′
的属性特征向量,w2表示激活函数中的权重,b2表示激活函数中的偏置。
[0027]
优选的,对拼接向量进行卷积的卷积核大小为f
×i×
o,其中,f表示滤波器的长度,i表示输入向量的大小,o表示输出向量的大小。
[0028]
优选的,对模型的参数进行优化的公式包括:
[0029][0030]
其中,w表示离模型输出最近运算层中的参数,表示损失函数与该运算层参数的梯度,γ表示学习率,w
′
表示更新后的参数。
[0031]
优选的,根据推荐预测向量为待推荐的实体进行推荐的过程包括:将得到的推荐预测向量与尾实体的推荐过程矩阵进行相似度计算,得到推荐预测向量与推荐尾实体的相似度矩阵,对相似度矩阵进行相似度排序,将排名前n项对应的尾实体作为每一个头实体的推荐结果。
[0032]
本发明的有益效果:
[0033]
1)本发明提出一种基于知识图谱语义嵌入的旅游景点推荐方法,该方法能够训练出描述实体(user、item)和关系(评分、点赞等)的embedding,可以整合用户的兴趣、商品和评论的特征。
[0034]
2)本方法在知识图谱的下游任务中使用,将协同过滤中的共现矩阵转换为图模型,让推荐方法保持可解释性的同时,增强了特征的表达效果,能在一定程度上解决冷启动问题。
[0035]
3)本方法在知识图谱的基础上进行,知识图谱中包含实体与关系的语义信息(属性特征)可以直接使用,不需要介入传统的特征交叉过程。
附图说明
[0036]
图1为本发明的基于知识图谱语义嵌入的旅游景点推荐方法整体流程图;
[0037]
图2为本发明的推荐模型的结构示意图;
[0038]
图3为本发明的推荐过程示意图。
具体实施方式
[0039]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0040]
由于推荐模型所需要的数据需要包含用户(user)与商品(item)之间的关系,同时还需要包含相关的特征信息。传统的协同过滤算法中的共现矩阵可以很好的表示user与item之间的关系,将共现矩阵转化为一个二部图表示。因此,本发明以二部图为基础构建的知识图谱,并以构建的知识图谱为基础提出一种基于知识图谱语义嵌入的旅游景点推荐方法。同时,由预训练的词嵌入为模型的embedding层加入实体和关系的语义信息,训练出表示实体和关系的embedding,并用于后续的旅游景点推荐任务。
[0041]
一种基于知识图谱语义嵌入的旅游景点推荐方法的实施方式,该方法包括:
[0042]
s1:获取待推荐的实体数据;所述实体数据包括实体的属性、实体与实体之间的关系属性,其中实体包括头实体和尾实体;
[0043]
s2:构建知识图谱,根据构建的知识图谱获取实体数据,将实体实体数据划分为训练集,将训练集中的实体数据划分为正例数据集和负例数据集;
[0044]
s3:分别计算正例数据集和负例数据集中的实体的结构特征向量和属性特征向量;
[0045]
s4:采用注意力机制分别对实体的结构特征向量和属性特征向量进行更新处理;
[0046]
s5:将更新后的实体结构特征向量和属性特征向量进行拼接,对拼接后的实体向量进行卷积,得到最终实体特征向量;将关系结构特征向量和属性特征向量进行拼接,对拼接后的向量进行线性运算,得到最终关系特征向量;
[0047]
s6:采用偏差评分函数构建模型的损失函数,将训练集中正例数据集和负例数据集实体特征向量和关系特征向量输入到推荐模型中,并采用随机梯度下降算法对推荐模型进行优化训练,得到优化参数;
[0048]
s7:将待推荐的实体数据的数据输入到训练好的推荐模型中,得到特征增强的实体特征向量;
[0049]
s8:将增强的实体特征向量与优化参数进行乘积运算,得到头实体和尾实体的推荐过程向量;
[0050]
s9:根据待推荐的实体数据获取推荐的关系特征向量,将待推荐的关系特征向量与头实体和尾实体的推荐过程向量进行进行加和,得到推荐预测向量;
[0051]
s10:根据推荐预测向量和所有尾实体的过程向量对待推荐的实体进行风景推荐。
[0052]
一种基于知识图谱语义嵌入的旅游景点推荐方法的实施方式,如图1所示,该方法包括:
[0053]
s1:从已构建的知识图谱中获取实体数据,获取的实体数据包括实体的结构特征、实体的属性特征、实体与实体之间关系的结构特征以及关系的属性特征;将获取的实体数据划分为训练集和测试集,训练集中的数据划分为正例数据集和负例数据集,训练集用于训练后续的模型;测试集用于对训练后的模型进行测试。其中实体包括user和item。
[0054]
s2:将得到的正例与负例数据输入embedding层,分别得到头实体的结构特征向量和属性特征向量、关系的结构特征向量和属性特征向量、尾实体的结构特征向量和属性特征向量。
[0055]
s3:将得到的实体和关系结构的特征向量与对应属性的特征向量分别作为结构注意力层和属性注意力层的输入,得到实体的结构特征和属性特征增强的特征向量。
[0056]
s4:将s3中得到的实体特征结构特征增强向量和属性特征增强向量分别进行拼接(包括user、item),将关系结构向量和关系属性向量进行拼接。
[0057]
s5:将拼接完成的实体特征向量依次输入到两个一维卷积层中,再通过两个线性层得到最终的实体特征向量;将拼接完成的关系特征向量输入一个线性层中,得到最终的关系特征向量。
[0058]
s6:构建模型的损失函数,构建过程包括将训练集中的正负例数据对应的最终特征向量(包括实体和关系的特征向量)输入偏差评分函数中,将正负例偏差评分函数的结果作为训练模型损失函数的输入,得到损失函数的参数,根据参数构建模型的损失函数。
[0059]
s7:设置模型的周期、训练批次和学习率,根据设置的周期、训练批次、学习率和损失函数采用随机梯度下降算法对模型进行训练,得到模型的最优参数。
[0060]
s8:将训练数据输入到s7中已训练的模型中,得到最终特征增强的实体(包括头尾实体)和最终的关系特征向量(或矩阵);将测试数据集中的数据输入到模型中,选出需要的最终头实体和最终关系的特征向量(或矩阵)。
[0061]
s9:从训练完成的偏差评分函数中提取偏差评分函数中的参数,并将得到的头实体和尾实体的增强特征向量分别与提取到的参数进行乘积运算,乘积的结果表示头实体和尾实体的推荐过程向量。
[0062]
s10:将得到的头实体的推荐过程向量与关系特征向量进行求和,得到的结果为推荐预测向量。
[0063]
s11:将得到的推荐预测向量与尾实体的推荐过程矩阵进行相似度计算,得到推荐预测向量与推荐尾实体的相似度矩阵,将相似度矩阵进行相似度排序,排名前n项对应的尾实体作为每一个头实体的推荐结果。
[0064]
对数据进行获取包括:对知识库中所有实体和关系进行获取,按照相同头实体、相同关系(包括相同语义信息)、不同尾实体划分正例与负例。例如存在三元组《h,r,t》和《h,r,t
′
》,则将这样的三元组两两随机组合构成训练集。
[0065]
计算正例数据集和负例数据集中的实体的结构特征向量和属性特征向量包括:将划分好的正负例数据集输入embedding层,得到user节点、关系(边)、item节点在知识图谱中的结构特征向量,以及相对应的属性(语义)特征向量。上述计算步骤如下:
[0066]
s=x
sws
[0067]
a=xawa[0068]
其中,s表示输出的结构嵌入值,xs表示输入的结构特征,ws表示计算结构嵌入的权重值,a表示输出的属性嵌入值,xa表示输入的属性特征,wa表示计算属性嵌入的权重值。
[0069]
采用注意力机制分别对实体的结构特征向量和属性特征向量进行更新处理的过程包括:对实体的结构特征向量的更新和对属性特征向量的更新。
[0070]
对实体的结构特征向量进行更新包括将实体结构嵌入作为结构注意力机制层的输入,通过实体的上下文节点计算出注意力分数,将一个实体节点的所有邻居节点特征向量与对应的注意力分数相乘求和再与原始结构特征向量求和得到结构注意力层的结果;其计算公式为:
[0071][0072][0073]
σ(s)=sigmoid(w1s+b1)
[0074]
其中,dn表示一个实体节点的邻居节点集合,αi表示第i个节点的注意力分数,σ(
·
)表示sigmoid函数,s表示实体结构特征向量,si表示实体s的第i个邻居实体的结构特征向量,w1表示权重参数,b1表示偏置。
[0075]
如图2所示,采用推荐模型对属性特征向量进行更新包括:将实体属性嵌入和关系属性嵌入作为属性注意力机制层的输入,计算出头实体与尾实体的增强属性特征向量;将该尾实体对应的所有头实体(ah)的特征向量与对应的注意力分数相乘求和再与原始尾实
体的属性征向量进行求和得到尾实体属性特征的计算结果;在头实体的更新过程中,由于关系是从头实体到尾实体的一条有向线段,所以在激活函数中要减去关系属性的embedding,得到结果的过程与尾实体的步骤相同。
[0076]
尾实体的属性特征计算公式为:
[0077][0078][0079]
π(ah,ar)=tanh(w2ah+ar+b2)
[0080]
其中,en表示一个尾实体对应的头实体集合,α表示在en中头实体的注意力分数,π(
·
)表示激活函数,a
t
表示尾实体的属性特征向量,h表示头实体,r表示关系,ah表示头实体的属性特征向量,ar表示关系的属性特征向量,h
′
表示一个尾实体对应的其中一个头实体,r
′
表示尾实体t与头实体h
′
之间的关系,ah′
表示头实体h
′
的属性特征向量,ar′
表示关系r
′
的属性特征向量,w2表示激活函数中的权重,b2表示激活函数中的偏置。
[0081]
头实体的属性特征计算公式:
[0082][0083][0084]
π(a
t
,ar)=tanh(w2a
t-ar+b2)
[0085]
其中,a
′h表示头实体属性特征,a
t
′
表示尾实体t
′
属性特征向量。
[0086]
向量拼接操作包括:将属性特征向量添加到结构特征向量的尾部,这样就构成了表示实体或关系的embedding。具体操作为:
[0087]
v=concat(s
′
,a
′
)
[0088]
上述公式中,concat(
·
)表示向量拼接函数,s
′
是增强的结构特征,a
′
是增强的属性特征,v是拼接后的特征向量,用于表示实体或关系的特征。
[0089]
对拼接后的向量进行卷积的过程包括:将所有头实体和尾实体的特征向量(矩阵)分别输入两个一维卷积层中,该过程用于过滤噪声,同时降低特征向量的维度,便于模型的训练,同时增强特征向量的表达效果,卷积核可表示为f
×i×
o,其中f表示滤波器的长度,i表示输入向量的大小,o表示输出向量的大小。由于关系特征向量没有经过增强,因此最后使用线性层进行降维操作,得到最后的关系特征向量。
[0090]
得到评分偏差函数和损失函数具体过程包括:将得到的user和item的特征向量分别输入到两个线性层中,此过程是使user和item特征向量的维度与关系特征向量维度相同,计算结果将用于后续的偏差评分操作,偏差评分计算方法为:
[0091][0092]
上述公式中,g(h,r,t)表示偏差评分函数,wh,w
t
是两个线性算子,v
′h,v
′r分别表
示头实体和尾实体的特征向量,v
′
t
是关系的特征向量,将以上线性运算的结果取欧式范数再平方,得到结果作为偏差评分。
[0093]
将正负例数据集分别得到的偏差评分的结果作为损失函数的输入,损失函数为:
[0094][0095]
上述公式中,d表示训练数据集,h,r分别表示头实体和关系,t是正例中的尾实体,t’是负例中的尾实体,σ(
·
)表示sigmoid函数。
[0096]
对推荐模型进行训练的过程包括:将得到的损失函数通过随机梯度下降算法进行模型优化,通过计算损失函数与模型中每一层参数之间的梯度,并根据一个学习率来更新每一层的参数值。具体步骤包括:
[0097][0098]
其中,w表示离模型输出最近运算层中的参数,表示损失函数与该运算层参数的梯度,γ表示学习率,w
′
表示更新后的参数。后续运算层的参数可通过链式法则求出对应的梯度,并进行参数的更新。在规定周期和训练批次下进行参数的跟新迭代,最终完成模型训练。
[0099]
步骤s8中获取特征向量(或矩阵)的步骤,具体包括:将所有训练集的数据输入模型,得到所有实体和关系增强特征向量(或矩阵),得到的特征矩阵包括:v
′h,v
′r,v
′
t
。再通过测试集得到所需的头实体和关系的特征向量(或矩阵)。
[0100]
获取推荐过程向量的过程包括:获取评分偏差函数中的参数wh和w
t
,将测试的user和所有item分别与wh、w
t
进行乘积运算,之后得到推荐过程向量(或矩阵):vu,vi。具体步骤包括:
[0101][0102][0103]
上述公式中,表示测试集中所有user的特征向量,表示所有item的特征向量,此过程是为了将user与item的特征向量维度转换为与关系特征向量维度相同。
[0104]
获取推荐预测向量过程包括:将得到的推荐过程向量(或矩阵)与指定的关系特征向量进行相加得到推荐预测向量(或矩阵),其表达式为:
[0105]
pi=vu+v
′r[0106]
其中,将vu所有向量与指定关系的特征向量v
′r进行求和得到推荐预测向量(或矩阵)。
[0107]
如图3所示,根据推荐预测向量为待推荐的实体进行推荐的过程包括:将得到的推荐预测矩阵与item的推荐过程矩阵进行相似度运算,最后进行相似度排序,排序较高的进行推荐。相似度计算包括:
[0108]
d=sim(pi,vi)
[0109]
在上述公式中,d表示相似度,sim(
·
)表示相似度函数,完成相似度计算后,进行
相似度排序,将每一个user对应相似度前n项item作为推荐的结果。
[0110]
本实施例将结合已构建知识图谱对本发明进一步的说明,本实施例使用旅游景点知识图谱进行说明,实施例包含20517个user节点,569个景点节点(即item节点)。
[0111]
s11:对知识库中所有实体和关系进行获取,将其中节点出度为1的user数据剔除(15344个节点),按照相同头实体、相同关系(包括相同语义信息)、不同尾实体划分正例与负例,最后选择节点出度为2的user数据(2530个节点)和评分类型为“好评”、评分为“5分”的关系作为测试集数据,其余数据作为训练集(5173个节点)。
[0112]
s21:将划分好的正负例数据集输入embedding层,得到user节点、关系(边)、景点节点在知识图谱中的结构特征向量,以及相对应的属性(语义)特征向量。
[0113]
user中包含的属性特征有姓名、性别、年龄,景点中包含的属性特征有地址、综合评分,relation中包括的属性特征有评分类型、评分。获取属性特征过程如下:
[0114][0115]
上式中a
i,j
表示第i个实体或关系中的第j个属性,将每一个实体或关系中的所有属性求和后取平均值得到的结果作为实体或关系的属性特征。
[0116]
s31:将s21得到的实体和关系结构特征向量与其对应的属性特征向量分别输入结构注意力机制层和属性注意力机制层得到实体的增强结构向量和增强属性向量。
[0117]
s41:将s31得到的实体增强结构特征向量和属性特征向量输入拼接层,得到实体的特征向量。由于关系的结构特征和属性特征不需要经过注意力机制层,因此将关系的结构特征与属性特征直接拼接得到关系的特征向量。
[0118]
s51:将s41得到的实体特征向量分别输入一维卷积层中,得到实体最终的增强特征向量,同时,将关系特征向量输入线性层中,得到最终的关系特征向量。
[0119]
s61:将s51得到的特征向量输入评分偏差函数中,并根据s11中划分的正负例三元组,将对应的偏差评分值输入损失函数中,计算出损失函数值,用于模型优化。
[0120]
s71:使用sgd算法对损失函数中的模型参数进行优化,并设置训练的epoch为500,batch_size(训练批次)为64,learning_rate(学习率)为0.01。
[0121]
s81:完成模型训练,将训练集中的所有数据(实体、关系)输入模型,得到最终实体和关系对应的特征向量。通过测试user和指定的关系的特征向量(或矩阵)。
[0122]
s91:将所有测试的头实体和所有尾实体与评分偏差函数中头实体与尾实体对应的参数进行乘积运算得到测试user和所有景点的推荐过程向量,并用于后续的推荐操作。
[0123]
s101:将s91得到的user推荐过程向量和指定关系特征向量输入pi=vu+v
′r中,得到推荐预测向量(或矩阵)。
[0124]
s111:将s101中得到的推荐预测向量(或矩阵)与所有景点的推荐过程向量进行相似度计算。最后对得到的相似度向量或矩阵并进行相似度从高到低排序,排序前n个景点作为对应用户的推荐结果。
[0125]
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明
的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1