一种面向三维场景重建的高精度单目深度估计系统及方法
1.本发明涉及图像处理技术领域,尤其涉及一种面向三维场景重建的高精度单目深度估计系统及方法。
背景技术:
2.在计算机视觉中,三维重建是指根据单视图或者多视图的图像重建三维信息的过程。由于单视图的信息不完全,因此三维重建需要利用经验知识。而多视图的三维重建相对比较容易,其方法是先对摄像机进行标定,即计算出摄像机的图象坐标系与世界坐标系的关系。然后利用多个二维图像中的信息重建出三维信息,在这个过程中,如何准确获得深度信息是能否从二维图像重建出三维信息的关键。然而大多数应用场景中,机器往往只有一个摄像机对三维场景图像进行采集。因此,单目深度估计技术在三维场景重建中显得至关重要。
3.单目深度估计技术在许多实时三维场景重建中有着广泛的应用,比如自动驾驶、虚拟现实、增强现实等,因此深度估计的精度与效率都很重要。目前大部分深度估计都是基于二维rgb图像到rgb-d图像的转化估计,虽然有很多设备可以直接获取像素级的地面真值深度,但是这些深度感知设备往往造价昂贵。早期的深度估计算法大多数有监督的,但训练这些算法需要获取成本很高的地面真值。随着计算机算力和深度学习算法挖掘信息能力的增强,单目深度估计的自监督算法在实现上具有了可能性。相比有监督算法,自监督算法不需要地面真值,只需部署普通的单目摄像头即可实现深度估计。需要注意的是,自监督算法虽然不像深度感知设备那样可以获得绝对深度信息,相对的深度信息已经足够感知周围事物的相对位置关系。近年来,自监督方法因其不需要地面真值进行训练,引起了许多关注,并取得了显著的成果。
4.单目深度估计涉及现有的所有密集预测体系结构几乎都是基于卷积网络的,遵循着从编码器到解码器的基本逻辑。大多数自监督单目深度估计的神经网络使用的是u-net架构,编码器和解码器层之间有跳过连接。该架构依然由标准的神经网络组件组成:卷积、加法、求和以及乘法。骨干架构的选择对整个模型的能力有很大的影响,因为在编码器中丢失的任何信息都不可能在编码器中恢复。编码器逐步向下采样提取多尺度特征。下采样可以扩大接收域,将低级特征分组抽象为高级特征,同时保证网络内存和计算需求易于处理。但是上述网络架构会造成特征分辨率和细粒度在模型较深阶段丢失,这对于图像分类任务可能无关紧要,但对于密集预测来说丢失特征和细粒度会造成预测性能的明显下降。
5.现有的深度信息恢复方法还存在以下缺陷:编码器要通过对输入图片进行下采样来增加接收域,但在这个过程中会丢失图像的特征和细节,而这些特征和细节是在解码过程中无法恢复的。图像的边界往往含有丰富的深度信息,但是经过神经网络上采样解码之后这部分信息会有所弱化。性能优良的卷积神经网络解码器往往包含大量参数和浮点运算。
技术实现要素:
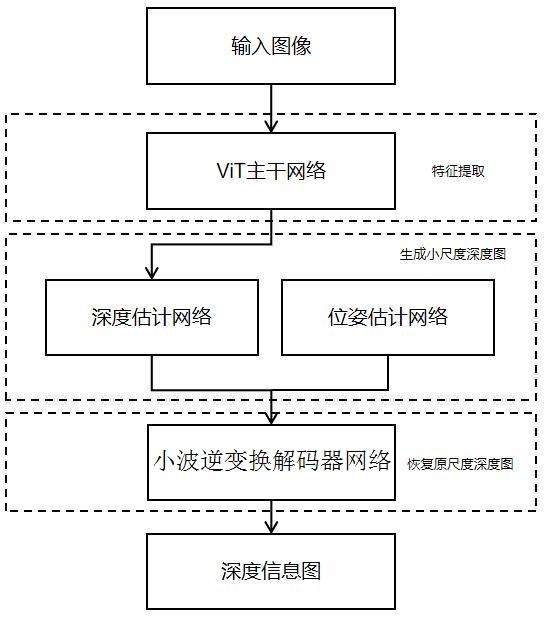
6.为解决上述问题,本发明提供一种面向三维场景重建的高精度单目深度估计系统,包括视觉转换器网络、自监督单目深度估计网络架构、小波逆变换解码器网络,所述视觉转换器网络为vit主干网络,将输入的单幅图片经过vit主干网络的transformer转换器和reassemble重组模块进行特征提取,并将瓶颈尺度的特征图片送入到深度估计网络和位姿估计网络;所述自监督单目深度估计网络架构包括有深度估计网络和位姿估计网络,深度估计网络将接收到的瓶颈尺度的特征图片预测出其的深度信息,位姿估计网络负责计算出前后帧之间的物体运动轨迹;所述小波逆变换解码器网络,将预测出的瓶颈尺度的深度信息图进行小波逆变换不断迭代上采样,最终输出深度信息图。
7.一种面向三维场景重建的高精度单目深度估计方法,包括有以下步骤:步骤一, 输入图像,vit主干网络通过将输入的图像分割成所有大小为像素的不重叠的正方形补丁,从图像中提取一个补丁嵌入,这些补丁被展成向量,并使用线性投影单独嵌入;将单独嵌入到特征空间的图像补丁,或者从图像中提取的深度特征,称之为标记;转化器使用串联的多头自注意转换标记集合,标记彼此关联以转换表示;步骤二,标记通过多个转换器传递,将经过转换器的每组标记重新组合成各种分辨率下的类似图像的特征表示;步骤三,然后基于深度估计网络和位姿估计网络,通过预测vit架构的瓶颈尺度上的粗略估计,重建一个深度估计信息图;步骤四,最后通过小波逆变换解码器网络利用预测其小波高频系数图进行小波逆变换迭代上采样并完善这个深度估计信息图,得到最终的深度信息图。
8.进一步改进在于,所述步骤一vit主干网络的编码器在所有转换器阶段都保持初始嵌入的空间分辨率。
9.进一步改进在于,所述步骤一在初始嵌入后的每一阶段,转换器都有一个全局的接受域。
10.进一步改进在于,所述步骤三估计深度估计网络用于从单幅图像中预测场景中物体之间的相对深度信息,位姿估计网络用于预测两个视图或视频两帧之间的物体相对运动关系。
11.进一步改进在于,所述深度估计网络和位姿估计网络为自监督单目深度估计的网络架构,自监督单目深度估计训练过程如下:给定目标图像和源图像,联合训练系统预测目标图像的密集深度图和目标到原图像的相对相机姿态,然后构造光度重投影损失函数如下: ,其中表示光度重建误差,是l1和结构相似度(ssim)损失的加权组合,定义为:
其中是根据目标图像的深度扭曲到目标坐标系的源图像,取;ssim定量比较两张图片的相似性:,是转换函数,将目标图像的像素映射到源图像上, ,而是局部亚可微的双线性采样算子;k为相机内参,假设它固定不变;边缘平滑损失函数为:,其中是平均归一化深度。
12.进一步改进在于,为进一步保证深度预测的一致性,在基础自监督损失函数的基础上引入了尺度一致损失:,其中表示将源图像深度图根据相机姿态向目标深度图扭曲投影后,再将像素网格对齐至的深度图;总损失函数l的计算公式如下 ,的作用是充当掩模,来判断重投影的光度误差是否小于原光度误差;若小于,则为1;反之为0;而参数为0.001。
13.本发明的有益效果:本发明在编码器处通过引入vision transformers,vit主干网络代替卷积网络作为密集预测的主干架构,以恒定的和相对较高的分辨率处理表示,并在每个阶段都有一个全局的接受域,以减少卷积网络中下采样过程中的信息丢失,从而获取图像更多的细节特征和感受野。在解码器处通过利用小波变换来捕获深度图中深度不同的平坦区域之间的深度“跳跃”,这些“跳跃”可以很好地在高频分量中捕获,从而达到强化深度信息图边缘的效果。而且高频分量是稀疏的,因此计算只需集中在某些边缘区域,从而节省网络的运算量。总之,通过对vit和小波变换的引入,能够在不使得网络计算更复杂的前提下,又兼顾单目深度估计网络模型对全局特征和局部边缘特征的提取,提高单目深度估计的精度。
14.本发明通过提升网络模型对全局特征和局部边缘特征的提取,提高现有自监督单目深度估计方法的精度。
15.本发明用vit主干网络代替传统卷积网络的编码器,以获得更多的细节特征和全局感受野,从而增强模型的全局特征提取能力,提高单目深度估计的精度。
16.本发明解码时仅在瓶颈尺度上进行深度估计,输出深度图,并利用稀疏小波逆变换迭代上采样输出深度信息图,从而强化深度信息图的边缘信息,提高单目深度估计网络的精度。
17.本发明稀疏小波变换减少了解码时的计算量,提高单目深度估计网络的效率。
18.本发明在原有monodepth2损失函数的基础上,引入尺度一致性损失来进行更加严格的约束。
附图说明
19.图1是本发明的估计系统的结构示意图。
20.图2是本发明的vit主干网络图。
21.图3是本发明的vit网络中reassemble模块结构图。
22.图4是本发明的小波逆变换解码器结构图。
23.图5是本发明深度预测网络图。
24.图6是本发明位姿预测网络图。
具体实施方式
25.为了加深对本发明的理解,下面将结合实施例对本发明作进一步的详述,本实施例仅用于解释本发明,并不构成对本发明保护范围的限定。
26.如图1所示,本实施例提供一种面向三维场景重建的高精度单目深度估计系统,包括视觉转换器网络、自监督单目深度估计网络架构、小波逆变换解码器网络,所述视觉转换器网络为vit主干网络,将输入的单幅图片经过vit主干网络的transformer转换器和reassemble重组模块进行特征提取,并将瓶颈尺度的特征图片送入到深度估计网络和位姿估计网络;所述自监督单目深度估计网络架构包括有深度估计网络和位姿估计网络,深度估计网络将接收到的瓶颈尺度的特征图片预测出其的深度信息,位姿估计网络负责计算出前后帧之间的物体运动轨迹;所述小波逆变换解码器网络,将预测出的瓶颈尺度的深度信息图进行小波逆变换不断迭代上采样,最终输出深度信息图。
27.本实施例还提供一种面向三维场景重建的高精度单目深度估计方法,包括有以下步骤:s1,在保持密集预测的编码器-解码器结构的基础上,将vit作为主干网络;输入图像,vit主干网络通过将输入的图像分割成所有大小为像素的不重叠的正方形补丁,从图像中提取一个补丁嵌入,这些补丁被展成向量,并使用线性投影单独嵌入;将单独嵌入到特征空间的图像补丁,或者从图像中提取的深度特征,称之为标记;转化器使用串联的多头自注意转换标记集合,标记彼此关联以转换表示;对具体应用来说,重要的是,转换器在所有
计算中维护的标记的数量。由于标记与图像补丁具有一对一的对应关系,这意味着vit编码器在所有转换器阶段都保持初始嵌入的空间分辨率。此外,多头自注意力本质上是一个全局的操作,因为每一个标记都可以关注并影响每一个其他标记。因此,在初始嵌入后的每一阶段,转换器都有一个全局的接受域。
28.与大多数传统的u-net卷积网络不同,本发明选择使用视觉转换器作为主干网络。如图2所示,vit主干网络将图片分割成大小为像素的不重叠的正方形小块,称之为补丁。通过提取不重叠的补丁,然后对它们的平面化表示进行线性投影。经过线性投影后的补丁,变为具有特征映射的像素特征的标记。图像嵌入通过位置嵌入进行增强,并加入了与补丁无关的读出标记,标记通过多个转换器模块传递。我们将不同阶段的标记重新组合成不同分辨率的类似图像的表示。在本发明中,我们主要选择了原输入图片的1/2、1/4、1/8、1/16尺度作为重组的分辨率。vit网络中reassemble模块结构图如图3所示,标记以输入图像的1/s的空间分辨率重组成特征映射。这里我们将补丁大小都设置为。转换器的层数也可以根据自己需要设置,这里我们设置为12层。
29.s2,标记通过多个转换器传递,将经过转换器的每组标记重新组合成各种分辨率下的类似图像的特征表示;s3,然后基于深度估计网络和位姿估计网络,通过预测vit架构的瓶颈尺度上的粗略估计,重建一个深度估计信息图;估计深度估计网络用于从单幅图像中预测场景中物体之间的相对深度信息,位姿估计网络用于预测两个视图或视频两帧之间的物体相对运动关系。
30.自监督单目深度估计的网络架构包括深度预测网络和位姿预测网络,前者用于从单幅图像中预测场景中物体之间的相对深度信息,后者用于预测两个视图或视频两帧之间的物体相对运动关系。深度预测网络如图5所示,位姿预测网络如图6所示。
31.自监督深度估计是一种新的视角合成问题,通过训练一个模型来从源图像的不同视点预测目标图像。利用深度映射作为桥接变量,对图像合成过程进行训练和约束。这样的系统既需要目标图像的深度预测图,又需要一对目标图像和源图像之间的估计相对位姿。
32.具体来说,给定目标图像和源图像,联合训练系统预测目标图像的密集深度图和目标到原图像的相对相机姿态,然后构造光度重投影损失函数如下: ,其中表示光度重建误差。它是l1和结构相似度(ssim)损失的加权组合,定义为:其中是根据目标图像的深度扭曲到目标坐标系的源图像,计算过程中一般取;ssim可以定量比较两张图片的相似性:
,是转换函数,将目标图像的像素映射到源图像上, ,而是局部亚可微的双线性采样算子;k为相机内参,假设它固定不变;边缘平滑损失函数为:,其中是平均归一化深度。
33.为进一步保证深度预测的一致性,基础自监督损失函数的基础上引入了尺度一致损失:其中表示将源图像深度图根据相机姿态向目标深度图扭曲投影后,再将像素网格对齐至的深度图;总损失函数l的计算公式如下 ,的作用是充当掩模,来判断重投影的光度误差是否小于原光度误差;若小于,则为1;反之为0;而参数为0.001。
34.s4,最后通过小波逆变换解码器网络利用预测其小波高频系数图进行小波逆变换迭代上采样并完善这个深度估计信息图,得到最终的深度信息图。如图4所示是小波逆变换解码器网络结构图,在解码器的每个阶段我们预测稀疏小波系数lh、hl、hh。这些从深度图捕获的高频细节,与从前一层解码器获取的低频深度图ll相结合,通过反离散小波变换(idwt)生成一个分辨率为ll二倍的新深度图,这个过程不断迭代直到生成与输入图像相同分辨率的深度图。粗深度估计在输入尺度的1/16处进行,模型依次向前迭代生成了5个深度图集合,比例尺度分别为1/16,1/8,1/4,1/2,1。
35.对于分段平坦的深度图,高频系数图有少量非零值分布在深度边缘。所以在对图像进行全分辨率深度重建时,只需要部分像素位置在每个尺度上预测非零系数的分布值。这些像素位置可利用掩码由上一尺度估计的高频系数映射来确定。这种稀疏化策略能够在减少需要计算输出的像素位置的数量来减少浮点运算的同时,突出深度图的边缘信息。
36.本实施例在编码器处通过引入vision transformers,vit主干网络代替卷积网络作为密集预测的主干架构,以恒定的和相对较高的分辨率处理表示,并在每个阶段都有一个全局的接受域,以减少卷积网络中下采样过程中的信息丢失,从而获取图像更多的细节
特征和感受野。在解码器处通过利用小波变换来捕获深度图中深度不同的平坦区域之间的深度“跳跃”,这些“跳跃”可以很好地在高频分量中捕获,从而达到强化深度信息图边缘的效果。而且高频分量是稀疏的,因此计算只需集中在某些边缘区域,从而节省网络的运算量。总之,通过对vit和小波变换的引入,能够在不使得网络计算更复杂的前提下,又兼顾单目深度估计网络模型对全局特征和局部边缘特征的提取,提高单目深度估计的精度。通过提升网络模型对全局特征和局部边缘特征的提取,提高现有自监督单目深度估计方法的精度。用vit主干网络代替传统卷积网络的编码器,以获得更多的细节特征和全局感受野,从而增强模型的全局特征提取能力,提高单目深度估计的精度。解码时仅在瓶颈尺度上进行深度估计,输出深度图,并利用稀疏小波逆变换迭代上采样输出深度信息图,从而强化深度信息图的边缘信息,提高单目深度估计网络的精度。稀疏小波变换减少了解码时的计算量,提高单目深度估计网络的效率。在原有monodepth2损失函数的基础上,引入尺度一致性损失来进行更加严格的约束。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1