一种基于体素的神经隐式表面生成和交互方法
1.本发明涉及计算机视觉和计算机图形学领域,尤其涉及一种基于体素的神经隐式表面生成和交互方法。
背景技术:
2.虚拟内容生成和交互是三维应用的重要组成部分。通常,虚拟内容需要由专业设计师来构建,既复杂又耗时。因此,从多视角图像中自动重建出准确的表面对于虚拟内容生成至关重要,这也是计算机视觉和计算机图形学的重要研究课题。在深度学习时代之前,图像表面重建主要是通过多视图立体几何技术 (mvs),它高度依赖于特征检测和匹配。虽然这些方法在学术界和工业界都比较成熟,但这类方法基于间接的特征匹配与点云表达,使得在重建过程中会产生信息损失。这些损失的信息对重建复杂场景构成挑战。例如,在弱纹理、重复特征或亮度不一致的情况下,难以匹配精确的特征,从而导致生成错误的三维点,最终导致重建的表面出现缺陷。此外,由于网格相应的纹理是单独生成的,而离散的三角形网格和不一致的纹理块通常无法渲染出真实感场景。
3.近两年,出现了使用神经网络表示场景的工作,并迅速成为研究的热点。类似occupancynet和deepsdf这样的工作表明,隐式表面可以通过学习的方式生成,例如符号距离场(sdf)或占用场(occupancy),并将其存储在多层感知器 (mlp)中。这些网络可以从离散的三维点样本中学习连续的场景表示。基于这一发现,dvr和idr将此表示扩展到基于图像的表面重建任务。然而,这些方法只对表面的点学习纹理,在没有足够观察的情况下难以学习到精确的表面。
4.随着基于nerf方法的出现,新颖的视图合成任务有了相当大的改进。 nerf及其延伸方法利用体积渲染的方式学习场景的神经辐射场,取得了明显的进展。然而,这类方法无法精确的重建表面。随后,像neus、unisurf和 volsdf这样的方法提出结合sdf和辐射场来实现表面重建。这些方法可以直接通过多视角图像进行端到端训练,而无需引入额外的表达,从而最大限度地减少信息丢失并得到比传统方法更高的精度。
5.然而,这些方法只用单个网络重建整个空间,由于网络容量有限,无法进行大规模重建。除此之外,场景隐含在网络之中,无法对齐进行交互式的操作,例如场景分割和编辑。
技术实现要素:
6.为了解决以上问题,本发明采用了一种混合架构,该架构由显式体素表示和隐式表面表示组成。这种架构结合了两种表示的优势,它可以显式的操纵场景,并具备隐式的表面和纹理表示能力。本发明所提出的vox-surf,是一种基于体素的神经隐式表面渲染框架,它结合了基于体素的方法和基于图像的隐式表面重建方法,可以用于高效的表面重建和渲染。
7.为了实现上述目的,本发明采用如下技术方案:
8.本发明首先提供了一种基于体素的神经隐式表面生成和交互方法,包括以下步
骤:
9.步骤1:预先将场景划分为多个不重叠的与坐标轴对齐的体素块,并建立起与体素块对应的八叉树结构;将体素块内部的几何和纹理信息以定长的可优化特征向量形式存储在体素块的8个顶点中;
10.步骤2:通过输入多张已知相机位置和朝向的rgb或rgbd图像,生成从相机中心穿过图像上像素的射线,并计算射线与体素块的交集,在射线与体素块交集的区域进行三维点采样,通过三维点坐标获取其所在的体素块的特征向量;并通过几何解析网络获取符号距离场(sdf)和中间信息,再将得到的中间信息通过纹理解析网络获取颜色;
11.步骤3:通过sdf计算三维点对应的空间密度值,再通过体渲染的方式对射线上的颜色进行权重累积,通过体渲染得到预测的射线对应像素的颜色,并与真实的颜色对比,由此优化几何解析网络、纹理解析网络和体素块上的特征向量,并采用渐进式的训练逐步生成场景的神经隐式表面;
12.步骤4:对于步骤3得到的场景的神经隐式表面,其包含几何和纹理信息特征向量的体素块,对体素块进行单独的渲染和交互。
13.进一步的,所述的步骤2中的进行三维点采样,具体为:
14.采用表面感知采样策略对射线上与体素块有交集的区域进行采样,采用过程分为三个步骤:
15.(1)首先在射线上与体素块有交集的区域按照均匀概率采样三维点p并通过特征提取函数获取p的特征向量e,
16.(2)然后利用几何解析网络f
σ
来计算每个采样点的sdf;通过判断连续2 个三维点的sdf是否沿射线方向从正变为负确定这段区域是否包含表面,并将包含这些点的体素块标记为重要体素;
17.(3)最后,提高重要体素内部的采样概率,并降低其余体素块内的采样概率,在射线上与体素块有交集的区域重采样,但保持总采样点数固定。
18.进一步的,所述的步骤3中的通过体渲染得到预测的射线对应像素的颜色,具体为:
19.采用s-密度函数φs(σ)将三维点p的sdf转换为密度,φs(σ)是关于点p 的符号距离σ的单峰函数,其中
[0020][0021]
是sigmoid函数φs的导数,s是控制分布形状的尺度参数,靠近表面的点的值大于远点的权重;
[0022]
基于φs(σ),定义不透明密度ρ(t)为以下形式
[0023][0024]
由此定义体渲染中的体积密度函数为:
[0025][0026]
定义体渲染中离散累积透射率如下所示:
[0027][0028]
因此,对在射线上的n
p
个三维采样点进行体渲染,可以得到累积的颜色c(r):
[0029][0030]
其中ci为射线上点i的颜色。
[0031]
根据本发明的优选方案,所述的步骤3中的渐进式训练,具体为:
[0032]
渐进式训练为由粗到细的剔除和分解体素块,通过逐步剔除不包含表面的体素块,并通过分解剩余的体素块,获取更精细的表面生成效果;
[0033]
其中,体素块剔除的步骤为:首先在每个体素块内均匀地采样足够的三维点;然后使用几何解析网络f
σ
计算三维点的sdf;为了决定是保留还是剔除该体素块,定义了一个距离阈值τ;
[0034][0035]
这里ki∈{0,1}是一个标志,其中1表示保留体素;
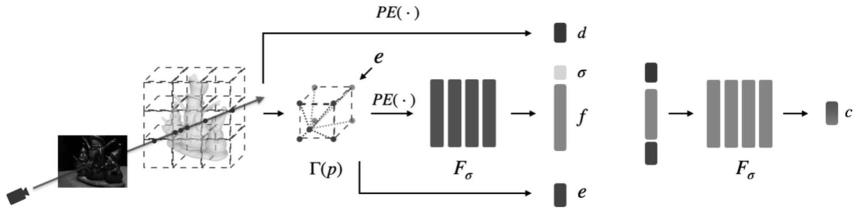
[0036]
体素块分解的步骤为:将剩余的体素块分解为8个子体素块,使用特征检索函数γ计算新生成的子体素块角顶点的特征向量,这些特征向量后续将进行单独优化。
[0037]
现有技术相比,本发明的优势在于:
[0038]
1)本发明提出的三维表达方式名为vox-surf,它通过将场景保存在多个不相交的体素块中,实现对三维场景的划分和存储。vox-surf表达混合了体素表达与神经隐式表面的优势,并可以通过端到端的方式学习。本发明提出的vox-surf 是一种基于体素的神经隐式表面表达,可以从多视角图像中端到端学习。对比现有技术,本发明生成基于体素块的独立几何渲染单元,更适用于场景的交互式编辑。
[0039]
2)本发明使用渐进式训练和表面感知采样策略在提高重建质量的同时不增加内存开销。同时基于ray-aabb相交检测的策略以及使用更小的网络使得本发明的方法较现有方法渲染速度更快。
附图说明
[0040]
图1是本发明的vox-surf的重建流程概括图;
[0041]
图2是本发明的表面感知采样的流程示意图;
[0042]
图3是本发明提出的渐进体素和表面重建训练流程展示示意图;
[0043]
图4是本发明的交互式编辑示意图。
具体实施方式
[0044]
下面结合说明书附图对本发明进行详细说明。本发明中各个实施方式的技术特征在没有相互冲突的前提下,均可进行相应组合。
[0045]
本发明的基于体素的神经隐式表面生成和交互方法包括以下步骤:
[0046]
步骤1:预先将场景划分为多个不重叠的与坐标轴对齐的体素块,并建立起与体素块对应的八叉树结构;将体素块内部的几何和纹理信息以定长的可优化特征向量形式存储
在体素块的8个顶点中;
[0047]
具体的,场景被一组粗体素块划分,每个体素块有8个角顶点,角顶点中,包含编码的几何和纹理信息;此信息由固定长度的可优化特征向量表示,le为特征向量的长度;因此,对于任一体素vi内的任意3d 点相邻的体素块共享4个角顶点的特征向量。
[0048]
步骤2:通过输入多张已知相机位置和朝向的rgb或rgbd图像,生成从相机中心穿过图像上像素的射线,并计算射线与体素块的交集,在射线与体素块交集的区域进行三维点采样,通过三维点坐标获取其所在的体素块的特征向量;并通过几何解析网络获取符号距离场(sdf)和中间信息,再将得到的中间信息通过纹理解析网络获取颜色。
[0049]
如图1所示,从相机中心o沿d方向穿过图像上像素的射线定义为r(t)=o+ dt,t为沿射线方向上的深度。每条射线通过ray-aabb相交检测算法求出射线与体素块交点的深度,从而划分出射线上与体素块有交集的区域。
[0050]
在本发明的一个优选实施例中,所述的步骤2中的通过几何解析网络获取符号距离场(sdf)和中间信息,再将得到的中间信息通过纹理解析网络获取颜色,具体为:定义特征提取函数将三维点p映射到长度为le的特征向量特征提取函数通过三线性插值实现,根据p的三维坐标与p所在的体素块中的相对位置,对体素块的8个角顶点所包含的特征向量进行插值,得到p的特征向量。
[0051]
本发明采用多层感知器网络(mlp)来表示几何解析网络f
σ
和纹理解析网络 fc。几何解析网络映射p的特征向量e到它的符号距离场和长度为lf几何特征向量σ的符号表示p是在表面s的内部还是外部。场景的表面s可以通过下式提取
[0052][0053]
其中操作[0]意味着从f
σ
中获取第一个值,在本发明的例子中是位置p的符号距离场σ。三维点p的几何特征向量f、p所在的射线方向d和p的特征向量e连接起来作为纹理解析网络fc的输入,得到p处的颜色c。在实践中,本发明采用nerf方法中提出的位置编码算法pe,在进入几何解析网络网络前对特征向量e进行编码,在进入纹理解析网络前对射线方向d进行编码。
[0054]
在本发明的一个实施例中,本发明提出了表面感知采样策略,对射线上与体素块有交集的区域进行三维点采样。该过程大致可分为三个步骤,如图2所示: (1)首先在射线上与体素块有交集的区域按照均匀概率采样三维点p并通过特征提取函数获取p的特征向量e,(2)然后利用几何解析网络f
σ
来计算每个采样点的sdf。通过判断连续2个三维点的sdf是否沿射线方向从正(外部)变为负(内部)确定这段区域是否包含表面,并将包含这些点的体素块标记为重要体素。(3)最后,提高重要体素内部的采样概率,并降低其余体素块内的采样概率,在射线上与体素块有交集的区域重采样,但保持总采样点数固定。
[0055]
在实践中,根据是否只使用第一个重要体素进一步将重采样分为全表面感知重采样(图2第3张图)和第一表面感知重采样(图2第最后1张图)。当形状不稳定时,使用前者来优化所有可能的表面,并使用后者来优化稳定形状的精细结构。
[0056]
步骤3:通过sdf计算三维点对应的空间密度值,再通过体渲染的方式对射线上的颜色进行权重累积,通过体渲染得到预测的射线对应像素的颜色,并与真实的颜色对比,由此优化几何解析网络、纹理解析网络和体素块上的特征向量,并采用渐进式的训练逐步生成场景的神经隐式表面;
[0057]
步骤3中的通过体渲染得到预测的射线对应像素的颜色,具体为:
[0058]
本发明采用s-密度函数φs(σ)将三维点p的sdf转换为密度,φs(σ)是关于点p的符号距离σ的单峰函数,其中
[0059][0060]
是sigmoid函数φs的导数,s是控制分布形状的尺度参数,靠近表面的点的值大于远点的权重。
[0061]
基于φs(σ),定义不透明密度ρ(t)为以下形式
[0062][0063]
由此定义体渲染中的体积密度函数为:
[0064][0065]
定义体渲染中离散累积透射率如下所示:
[0066][0067]
因此,对在射线上的n
p
个三维采样点进行体渲染,可以得到累积的颜色c(r):
[0068][0069]
其中ci为射线上点i的颜色。
[0070]
所述的步骤3中的渐进式训练,具体为:
[0071]
渐进式训练为由粗到细的剔除和分解体素块,通过逐步剔除不包含表面的体素块,并通过分解剩余的体素块,获取更精细的表面生成效果;
[0072]
体素块剔除步骤为:首先在每个体素块内均匀地采样足够的三维点。然后使用几何解析网络f
σ
计算三维点的sdf。为了决定是保留还是剔除该体素块,本发明定义了一个距离阈值τ。
[0073][0074]
这里ki∈{0,1}是一个标志,表示是否保留体素,其中1表示保留体素。
[0075]
体素块分解步骤为:将剩余的体素块分解为8个子体素块,使用特征检索函数γ计算新生成的子体素块角顶点的特征向量,这些特征向量后续将进行单独优化。
[0076]
每次体素块剔除和分解后的效果如图3左边4张图所示,最终生成的表面和纹理如图3右边2张图所示。
[0077]
为了优化特征向量、几何解析网络和纹理解析网络,本发明利用了以下损失函数。
对于每条射线,首先计算射线的累积颜色c(r),然后与真实颜色计算l1损失。
[0078][0079]
为了约束sdf,本发明还在采样三维点p上添加了eikonal损失项,该项通过约束相邻采样点的法向量,维护sdf的稳定性。
[0080][0081]
最终用到的损失函数为
[0082][0083]
如果输入有深度信息。本发明则额外使用基于占用场的深度损失。
[0084]
占用场定义为
[0085]
occ(t)=sigmoid(-scale
·fσ
(γ(r(t)))[0])
[0086]
由于占用场的梯度只在表面s附近达到峰值。因此,本发明将带有深度信息的射线r(t)分成三个区间,对应的损失不同:
[0087][0088]
对于给定深度之前的点,δt是一个小噪声容忍深度范围。本发明总是假设这些点在表面之外。
[0089][0090]
对于给定深度的点,本发明总是假设这些点在表面内。在实验中发现,即使在射线与多个表面相交的情况下,只要进行足够的观察,这种损失仍然有效。
[0091][0092]
对于之间的点,本发明认为这些点在表面上,因此直约束sdf为0。
[0093]
最后,总深度损失是上述三种损失的组合:
[0094][0095]
步骤4:对于步骤3得到的场景的神经隐式表面,其包含几何和纹理信息特征向量的体素块,对体素块进行单独的渲染和交互。所述的步骤4中的单独的渲染和交互,具体为:步骤3中训练好的体素块每一个都可视为一个独立的几何单元,通过改动体素块位置,大小,朝向等性质,直接对场景进行交互式编辑,提高交互的自由度,并通过步骤3中的体渲染直接生成当前视角下的真实的纹理效果。
[0096]
实施例
[0097]
本发明在两种不同类型的数据集上进行了实验,分别为小场景物体数据集 dtu和室内场景数据集scannet。对于dtu数据集,本发明首先在体素大小为 0.8的单位立方体内
生成初始体素块和相应的八叉树。每50,000次迭代采用一次体素块剔除,并分别在20,000、50,000、100,000、20,000、300,000次迭代处进体素块分解,剔除阈值为0.01。在第二次分割之前,采用均匀体素采样,在第二次到第四次分割时,使用全表面感知体素重采样策略。第四次分割后,使用第一表面感知体素重采样以继续细化细节。体素嵌入长度为16,几何解析网络为一个4层mlp,每层有128个隐藏单元,而纹理解析网络是一个4层 mlp,每层有128个隐藏单元。在输入提取器之前,在体素特征上用了6个频率的位置编码,在射线方向上用了8个频率的位置编码。本发明对比了 colmap,dvr,idr以及目前精度最高的neus方法,采用了chamfer衡量指标评估真实三维模型和重建三维模型的精度,本发明的平均精度高于neus以及 idr。
[0098]
对于scannet数据集,本发明采用了带深度的数据进行训练,首先将所有深度观测值反向投影到三维点中,然后使用0.4的初始体素大小对这些点进行体素化。由于rgb-d传感器仅在一定距离内准确,将最大深度范围限制为5.0以减少噪声样本。本发明还在训练过程中逐步分解和剔除体素两次,使最小体素大小为0.1。本发明对比了colmap以及tsdf方法,本发明对比了chamfer 指标和f-score指标,结果明显优于传统的tsdf方法。
[0099]
本发明可运用于场景和物体的编辑,如图4所示,通过修改本方法中的体素单元,对齐进行复制,局部缩放,分割等操作,即可以直接渲染出对应的真实感场景。
[0100]
以上列举的仅是本发明的具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1