一种基于机器视觉的井下人员不安全行为快速分析与识别方法
1.本发明属于煤矿井下安全工程技术领域,尤其涉及一种基于机器视觉的井下人员不安全行为快速分析与识别方法。
背景技术:
2.作为煤炭资源产量大国和消耗大国,煤炭在火力发电、生活燃料、工业制造等方面需求极大。随着煤炭需求量的不断增加,即使较之以前的传统采煤作业方式更加的智能化,井下工作人员更少,但由于人的主观因素仍然避免不了一些人为事故的发生。人的主观因素可以理解为人的不安全行为,据统计发现,当前大多数煤矿事故的发生是由人的不安全行为引起的。人的主观性经常会导致自己的行为违背安全准则,工人经常会为了节省时间而去做出乘坐皮带、攀爬护栏等危险行为,而矿井下面光线阴暗,环境复杂,井下人员的稍不注意就会酿成难以挽回的损失。因此,降低由人的不安全行为造成的不必要的事故损失刻不容缓。
3.随着计算机技术、自动化技术的发展,研究人员为了对井下人员的不安全行为进行检测,将监控设备和传感设备引入到安全生产领域,从而对井下情况进行判断分析。然而,就监控设备而言只能对井下人员的行为起到录像的作用,无法针对工人的行为情况进行检测报警;而传感设备对环境要求较高,准确度不够理想。对于煤矿井下场景而言,实时性和准确度尤为重要,因此,传统的监控录像设备以及识别精度较低的设备不能满足实时检测报警的要求。
4.通过比较,发现针对不安全行为识别的方法主要存在以下缺陷:
5.1、传统监控设备无法做到监控分析和检测报警同时进行;
6.2、井下环境较为复杂,受环境因素影响较大;
7.3、现有的井下人员识别系统较为单一,只能对一种或一类行为进行识别。
8.为此,设计一种快速高效的基于图像识别和人体姿态估计技术的井下人员不安全行为的分析判断方法对煤矿行业来说显得尤为重要。
技术实现要素:
9.本发明要解决的技术问题是设计一种基于机器视觉的井下人员不安全行为快速分析与识别方法及应用,能够对井下人员的多种不安全行为进行检测报警,并具有一定的时效性与鲁棒性,受环境因素干扰较小。
10.为解决上述技术问题,本发明的基于机器视觉的井下人员不安全行为快速分析与识别方法包括如下步骤:
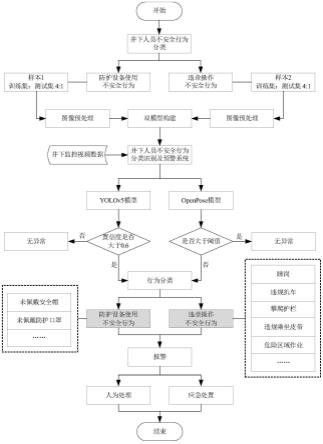
11.步骤1:对井下人员不安全行为进行分类,分为防护设备使用不安全行为和违章操作不安全行为,防护设备使用不安全行为包括未佩戴安全帽和未佩戴防护口罩等,违章操作不安全行为包括睡岗、攀爬护栏、违规扒车、违规乘坐皮带和危险区域作业等;
12.步骤2:收集并建立不安全行为数据集,依据防护设备使用不安全行为和违章操作不安全行为分类标准分为数据集一和数据集二,并把每个数据集按比例划分为训练集和测试集;
13.步骤3:分别将数据集一和数据集二两个数据集进行图像预处理,图像预处理包括去雾、降噪、平滑和锐化的过程,使图像轮廓清晰、目标特征突出;
14.步骤4:构建井下人员不安全行为分类识别及预警双模型系统,yolov5模型用于识别及预警防护设备使用不安全行为,openpose模型用于识别及预警违章操作不安全行为;
15.步骤5:通过智能摄像机和网络通信系统将井下监控视频数据上传到井下人员不安全行为分类识别及预警双模型系统;
16.步骤6:系统对上传的井下数据进行图像预处理优化,yolov5模型和openpose模型根据其图像中的目标特征进行识别和分类,其中,yolov5模型根据得出的置信度是否大于0.6来判断是否属于不安全行为,openpose模型根据计算得出的关节点的距离是否大于阈值来判断是否属于不安全行为;
17.步骤7:若系统判断为不安全行为则根据实际情况进行报警,若不安全行为属于防护设备使用不安全行为则进行人为处理方式进行提示,若不安全行为属于违章操作不安全行为则系统优先进行自动应急处置,对井下人员进行报警提示。
18.进一步的,yolov5模型包括目标识别模块、判决模块和行为分类模块,yolov5模型识别过程包括如下步骤:
19.步骤1:建立包含所需要识别的井下人员防护设备使用不安全行为的数据集一,数据集一包括是否佩戴安全帽和防护口罩两类行为,然后将数据集一以4:1的比例划分为训练集和测试集;
20.步骤2:将训练集和测试集进行图像预处理,图像预处理过程包括去雾、降噪、平滑和锐化的过程,目的是增强图像中的有用信息,如目标轮廓、特征等,进而提取训练集中预处理后的井下人员防护设备使用不安全行为图像中的行为特征,生成原始特征图;
21.步骤3:将原始的特征图输入已经优化后的yolov5目标检测模型;
22.步骤4:使用yolov5目标检测模型识别检测矿井视频中井下人员的防护设备使用不安全行为。
23.进一步的,yolov5模型识别井下人员防护设备使用不安全行为包括如下步骤:
24.步骤1:输入原始特征图;
25.步骤2:对原始特征图进行图像分割,得到像素尺寸为原始特征图尺寸一半的新特征图;
26.步骤3:通过yolov5算法计算新特征图的置信度;其中,置信度是判断不安全行为分类的一个重要标准,置信度越低,则说明与训练的模型里面的不安全行为重合度较低,并无异常;若置信度越高,则表明与训练的模型里面的不安全行为重合度较高;
27.步骤4:将得出的新特征图的置信度输入判决模块,根据锚框上方的提示词进行判断属于哪一种不安全行为。
28.进一步的,步骤3中优化后的yolov5目标检测模型获取方法具体为:
29.将新建立的数据集一分成训练集和测试集,使用labelimg软件进行目标标注;
30.将预处理后的训练集中的图像输入到yolov5网络中,通过随机缩放、裁减、排布的
方式进行拼接,可以大大丰富检测数据集,也增强了对远处的小目标的特征提取能力;
31.yolov5算法针对输入的不同的训练集类型选择不同类型的锚框,每次训练时,都会自适应的计算不同类型训练集的最佳锚框值;
32.yolov5算法对letterbox函数进行了修改,将图片缩放进行了改进,使得原始特征图自适应添加的黑边更少,推理检测速度获得提升,效果更加明显;
33.yolov5采用了c3net和focus两种核心网络,其中c3net采用了两种结构,c3_x结构应用于backbone主干网络,另一种c3_1结构则应用于neck中,增强了网络特征融合的能力;focus结构将输入的原始尺寸640
×
640
×
3像素的图像采取切片操作,先切割为像素尺寸为320
×
320
×
12的特征图,再经过一次64个卷积核的卷积操作,最终得到像素尺寸只有原始特征图一半尺寸的新特征图,进而获取每一张图像的置信度以供后续的测试集进行验证。
34.进一步的,openpose模型包括姿态估计模块、判决模块和动作分类模块,openpose模型识别过程包括如下步骤:
35.步骤1:建立包含所需要识别的井下人员违章操作不安全行为的数据集二,数据集二中主要包括睡岗、攀爬护栏、违规扒车、违规乘坐皮带和危险区域作业等不安全行为,然后将数据集二以4:1的比例划分为训练集和测试集;
36.步骤2:将训练集和测试集进行图像预处理,图像预处理过程包括去雾、降噪、平滑和锐化的过程,使图像轮廓清晰、目标特征突出,进而提取训练集中预处理后的井下人员违章操作不安全行为图像中的行为特征,生成原始特征图;
37.步骤3:将原始特征图输入openpose神经网络模型;
38.步骤4:使用openpose神经网络模型识别矿井视频中井下人员违章操作不安全行为。
39.进一步的,openpose模型识别井下人员违章操作不安全行为包括如下步骤:
40.步骤1:在姿态估计模块中输入原始特征图;
41.步骤2:用vgg-19网络对原始特征图进行特征提取,获取新特征图;
42.步骤3:对新特征图进行关节点检测,并进行有效的连接,获得人体骨骼图,以及骨骼图关节点的连接点的信息;
43.步骤4:对人体骨骼图中的有效的关节点的距离进行计算,并与训练的openpose神经网络模型所设定的阈值进行比较和误差分析,该阈值为模型训练时,由人体骨骼图之间的骨骼关键点之间的距离所决定的,主要包括人的头、手、脚等肢体部位的骨骼关键点的信息以及人的位置的信息,根据计算得出的骨骼关节点的距离的阈值大小,由于数据集二主要是不安全行为的数据,因此得出的骨骼关节点的距离的阈值倾向于不安全行为的数值,若阈值小于训练时设定的阈值,则重合度较高,与不安全行为标准接近,判定为违章操作不安全行为,同时根据骨骼关节点的相似度来进行动作分类,最终进行报警提示;若阈值大于训练时所设定的阈值,则说明重合度较低,误差较大,不是异常行为,判定不属于违章操作不安全行为。
44.进一步的,步骤3中,openpose网络分为两个stage,每一个stage又包括两个分支,分别为branch 1和branch 2,其中,特征f输入stage1经过两个分支的处理之后得到s1和l1,而在stage2之后,阶段t网络的输入有s
t-1
,l
t-1
,f,每个阶段的输入为:
[0045][0046][0047]
进一步的,openpose神经网络模型获取方法具体为:
[0048]
步骤1:建立训练集和测试集,并进行图像预处理;
[0049]
步骤2:将预处理后的数据集二进行特征提取,获取原始特征图;
[0050]
步骤3:将原始特征图输入基于openpose算法的神经网络模型对人体骨骼关键点进行识别,该算法采用“自下而上”的人体姿态估计思路,可对人体骨骼的关键点进行识别标记。该算法通过快速计算以一帧w
×
h尺寸的彩色图像输入,然后输出一张具有输入图像中每个井下人员的人体骨骼关键部位的二维坐标图像;
[0051]
步骤4:输入的彩色图像进入vgg-19的前10层网络初始化,同时进行权重微调,获得一组特征映射作为第一阶段的输入;
[0052]
步骤5:将网络分成分支1和分支2,分支1用于置信图s的预测,分支2用于关节点之间的亲和度l的预测;
[0053]
步骤6:获得置信图和亲和度的信息之后,使用偶匹配(bipartite matching)求出part association,将同一个井下人员目标的骨骼关键部位的点相互连接起来,最终生成人体骨架图。
[0054]
进一步的,步骤36中,若为多人检测问题,可转化为二分图匹配问题,设g=(v,e)是一个无向图,若顶点v可分割成两个互不相交的子集(a,b),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in a,j in b),则称图g为一个二分图,使用匈牙利算法求得相连关键点最优匹配,匈牙利算法计算过程为:
[0055][0056]
对于任意的一对关节点位置d
j1
和d
j2
,通过计算pafs的线性积分来表征骨骼点对的相关性,也表征了骨骼点对的置信度,计算过程为:
[0057][0058]
为了快速计算积分,采用均匀采样的方式近似关节点间的相似度,其计算过程为:
[0059]
p(u)=(1-u)d
j1
+ud
j2
。
[0060]
本发明还提供一种基于机器视觉的井下人员不安全行为智能识别及预警系统,运行前述基于机器视觉的井下人员不安全行为快速分析与识别方法,整体架构包括系统应用层、系统处理层、模型检测层、系统分类层及基础环境层;
[0061]
系统应用层主要是地面人员的可视化展示界面,企业负责人和系统管理员可通过视频监控系统、大屏显示系统、网络通信系统、存储备份系统、呼叫中心系统及声光报警系统对井下人员的行为状态一目了然,并且将所有监控数据记录在数据库里面,为计算机学习识别不同环境下的不安全行为不断建立新的数据集;
[0062]
系统处理层包括通过摄像机对井下人员的人员数量、面部状态以及活动轨迹数据进行收集,通过光纤传输到系统处理层;
[0063]
系统处理层将从井下摄像机记录的数据通过计算机对图像进行预处理,预处理主要包括去雾、降噪、平滑及锐化的过程,增强图像的亮度和对比度,使其目标更容易被检测到;
[0064]
模型检测层是系统处理层的核心处理层之一,在系统对输入的图像进行预处理完成后,yolov5模型和openpose模型对输入的图像进行不安全行为检测,通过与预训练的数据库中的数据进行比对分析得出是否存在不安全行为;
[0065]
若系统检测到存在不安全行为,系统分类层作为系统处理层的另一核心处理层,会对其检测到的不安全行为通过置信度、关节点阈值标准来进行不安全行为的判断;
[0066]
基础环境层即井下布控的必备设施,主要包括智能摄像机、环网基站和声光报警器,智能摄像机在分辨率和补光方面有着较高的优势,通过摄像机补光和计算机预处理过程中亮度增强两次处理,图像更加清晰,人物特征更加鲜明;环网基站为井下和地面传输重要信息和数据提供必要的网络环境,同时实时地将数据存储到数据库中,为计算机模型学习不断提供新的数据集;声光报警器则对违章人员进行提示预警。
[0067]
本发明的有益效果:
[0068]
通过对比传统的井下监控技术和传感设备,本发明采用上述技术方案,通过对收集的矿井中井下人员的不安全行为数据集作为初始的数据集,进行筛选,建立一套自制的新的数据集,对不安全行为进行了重新定义,分别是防护设备使用不安全行为和违章操作不安全行为,对人员行为的识别更加准确,范围更加广泛,利用基于优化后的yolov5算法对人的面部进行检测,以及openpose神经网络模型进行人体动作的姿态估计,其中yolov5算法对letterbox函数进行了修改,将图片缩放进行了改进,使得原始特征图自适应添加的黑边更少,推理检测速度获得提升,效果更加明显;openpose神经网络模型采取了“自下而上”的处理方法建立人体位置和人体骨骼关键点的模型,这种处理方法先检测人的手、脚、肩等关键部位,再把检测到的人体骨骼关键点相互连接,最终组合成多人姿态估计图,受环境因素影响更小,对矿工的危险行为更容易判断。该方案通过图像识别和姿态估计相结合,既达到了对于外貌特征的识别,又通过人体骨骼关键点间的差值数据,进而判断人是否存在防护设备使用不安全行为以及违章操作不安全行为;该方案受环境因素影响较小,且识别准确度要高于传统的识别设备,具有较强的时效性和鲁棒性。
附图说明
[0069]
下面结合附图对本发明的具体实施方式做进一步阐明。
[0070]
图1为本发明的基于机器视觉的井下人员不安全行为快速分析与识别方法的流程图;
[0071]
图2为本发明的基于机器视觉的井下人员不安全行为快速分析与识别方法中yolov5模型的流程图;
[0072]
图3为本发明的基于机器视觉的井下人员不安全行为快速分析与识别方法中openpose模型的流程图;
[0073]
图4为yolov5网络部分模块结构图;
[0074]
图5为yolov5网络结构原理图;
[0075]
图6为openpose网络结构原理图;
[0076]
图7为井下人员防护设备使用不安全行为检测结果图;
[0077]
图8(a)为openpose模型识别人体全身骨骼关节点配对连接形成的人体骨骼图;
[0078]
图8(b)为openpose模型检测井下人员是否在危险区域内的效果图;
[0079]
图9为基于视频监测的井下人员不安全行为智能识别及预警系统架构图。
具体实施方式
[0080]
结合图1-图3,本发明的基于机器视觉的井下人员不安全行为快速分析与识别方法包括如下步骤:
[0081]
步骤1:对井下人员不安全行为进行分类,分为防护设备使用不安全行为和违章操作不安全行为,防护设备使用不安全行为包括未佩戴安全帽和未佩戴防护口罩等,违章操作不安全行为包括睡岗、攀爬护栏、违规扒车、违规乘坐皮带和危险区域作业等;
[0082]
步骤2:收集并建立不安全行为数据集,依据防护设备使用不安全行为和违章操作不安全行为分类标准分为数据集一和数据集二,并把每个数据集按比例划分为训练集和测试集;
[0083]
步骤3:分别将数据集一和数据集二两个数据集进行图像预处理,图像预处理包括去雾、降噪、平滑和锐化的过程,使图像轮廓清晰、目标特征突出;
[0084]
步骤4:构建井下人员不安全行为分类识别及预警双模型系统,yolov5模型用于识别及预警防护设备使用不安全行为,openpose模型用于识别及预警违章操作不安全行为;
[0085]
步骤5:通过智能摄像机和网络通信系统将井下监控视频数据上传到井下人员不安全行为分类识别及预警双模型系统;
[0086]
步骤6:系统对上传的井下数据进行图像预处理优化,yolov5模型和openpose模型根据其图像中的目标特征进行识别和分类,其中,yolov5模型根据得出的置信度是否大于0.6来判断是否属于不安全行为,openpose模型根据计算得出的关节点的距离是否大于阈值来判断是否属于不安全行为;
[0087]
步骤7:若系统判断为不安全行为则根据实际情况进行报警,若不安全行为属于防护设备使用不安全行为则进行人为处理方式进行提示,若不安全行为属于违章操作不安全行为则系统优先进行自动应急处置,对井下人员进行报警提示。
[0088]
进一步的,yolov5模型包括目标识别模块、判决模块和行为分类模块,yolov5模型识别过程包括如下步骤:
[0089]
步骤1:建立包含所需要识别的井下人员防护设备使用不安全行为的数据集一,数据集一包括是否佩戴安全帽和防护口罩等不安全行为,然后将数据集一以4:1的比例划分为训练集和测试集;
[0090]
步骤2:将训练集和测试集进行图像预处理,图像预处理过程包括去雾、降噪、平滑和锐化的过程,目的是增强图像中的有用信息,如目标轮廓、特征等,进而提取训练集中预处理后的井下人员防护设备使用不安全行为图像中的行为特征,生成原始特征图;
[0091]
步骤3:将原始的特征图输入已经优化后的yolov5目标检测模型;
[0092]
步骤4:使用yolov5目标检测模型识别检测矿井视频中井下人员的防护设备使用
不安全行为。
[0093]
进一步的,yolov5模型识别井下人员防护设备使用不安全行为包括如下步骤:
[0094]
步骤1:输入原始特征图;
[0095]
步骤2:对原始特征图进行图像分割,得到像素尺寸为原始特征图尺寸一半的新特征图;
[0096]
步骤3:通过yolov5算法计算新特征图的置信度;其中,置信度是判断不安全行为分类的一个重要标准,置信度越低,则说明与训练的模型里面的不安全行为重合度较低,并无异常;若置信度越高,则表明与训练的模型里面的不安全行为重合度较高;
[0097]
步骤4:将得出的新特征图的置信度输入判决模块,根据锚框上方的提示词进行判断属于哪一种不安全行为。
[0098]
yolov5模型对井下人员防护设备使用不安全行为检测结果如图7所示,检测识别两位工作人员未佩戴口罩(no mask),属于防护设备使用不安全行为。
[0099]
精确度(precision)、召回率(recall)、平均准确度(average precision)和均值平均精度(mean average precision,map)是目标检测领域评估训练模型性能和可靠性的常用指标,其中:
[0100]
精确度计算过程为:
[0101]
召回率计算过程为:
[0102]
平均准确度计算过程为:
[0103]
均值平均精度计算过程为:
[0104]
其中,tp指在井下的监控区域内部未佩戴安全帽或防护口罩的人数,并且保证检测结果是正确的;fp指在井下的监控区域内部佩戴安全帽或防护口罩但被检测为未佩戴安全帽或防护口罩的人数;fn指在井下的监控区域内部未佩戴安全帽或防护口罩但被检测为已佩戴安全帽或防护口罩的人数;tn指模型检测结果正确;q为总类别数量。
[0105]
此外,损失函数的选择也会对yolov5模型的收敛效果有较大的影响,在改进yolov5模型的过程中采用giou_loss作为损失函数,从而获得更好的识别效果,损失函数计算过程如下:
[0106][0107]
进一步的,步骤3中优化后的yolov5目标检测模型获取方法具体为:
[0108]
将新建立的数据集一分成训练集和测试集,使用labelimg软件进行目标标注;
[0109]
将预处理后的训练集中的图像输入到yolov5网络中,通过随机缩放、裁减、排布的方式进行拼接,可以大大丰富检测数据集,也增强了对远处的小目标的特征提取能力;
[0110]
yolov5算法针对输入的不同的训练集类型选择不同类型的锚框,每次训练时,都会自适应的计算不同类型训练集的最佳锚框值;
[0111]
yolov5算法对letterbox函数进行了修改,将图片缩放进行了改进,使得原始特征图自适应添加的黑边更少,推理检测速度获得提升,效果更加明显;
[0112]
结合图4和图5,yolov5采用了c3net和focus两种核心网络,其中c3net采用了两种结构,c3_x结构应用于backbone主干网络,另一种c3_1结构则应用于neck中,增强了网络特征融合的能力;focus结构将输入的原始尺寸640
×
640
×
3像素的图像采取切片操作,先切割为像素尺寸为320
×
320
×
12的特征图,再经过一次64个卷积核的卷积操作,最终得到像素尺寸只有原始特征图一半尺寸的新特征图,进而获取每一张图像的置信度以供后续的测试集进行验证。
[0113]
进一步的,openpose模型包括姿态估计模块、判决模块和动作分类模块,openpose模型识别过程包括如下步骤:
[0114]
步骤1:建立包含所需要识别的井下人员违章操作不安全行为的数据集二,数据集二中主要包括睡岗、攀爬护栏、违规扒车、违规乘坐皮带和危险区域作业等不安全行为,然后将数据集二以4:1的比例划分为训练集和测试集;
[0115]
步骤2:将训练集和测试集进行图像预处理,图像预处理过程包括去雾、降噪、平滑和锐化的过程,使图像轮廓清晰、目标特征突出,进而提取训练集中预处理后的井下人员违章操作不安全行为图像中的行为特征,生成原始特征图;
[0116]
步骤3:将原始特征图输入openpose神经网络模型;
[0117]
步骤4:使用openpose神经网络模型识别矿井视频中井下人员违章操作不安全行为。
[0118]
进一步的,openpose模型识别井下人员违章操作不安全行为包括如下步骤:
[0119]
步骤1:在姿态估计模块中输入原始特征图;
[0120]
步骤2:用vgg-19网络对原始特征图进行特征提取,获取新特征图;
[0121]
步骤3:对新特征图进行关节点检测,并进行有效的连接,获得人体骨骼图,以及骨骼图关节点的连接点的信息;
[0122]
步骤4:对人体骨骼图中的有效的关节点的距离进行计算,并与训练的openpose神经网络模型所设定的阈值进行比较和误差分析,该阈值为模型训练时,由人体骨骼图之间的骨骼关键点之间的距离所决定的,主要包括人的头、手、脚等肢体部位的骨骼关键点的信息以及人的位置的信息,根据计算得出的骨骼关节点的距离的阈值大小,由于数据集二主要是不安全行为的数据,因此得出的骨骼关节点的距离的阈值倾向于不安全行为的数值,若阈值小于训练时设定的阈值,则重合度较高,与不安全行为标准接近,判定为违章操作不安全行为,同时根据骨骼关节点的相似度来进行动作分类,最终进行报警提示;若阈值大于训练时所设定的阈值,则说明重合度较低,误差较大,不是异常行为,判定不属于违章操作不安全行为。
[0123]
如图8(a)所示,将识别的人体最多达18个关节点分别配对连接,即可获得人体骨骼图,图8(b)为井下人员在危险区域内进行活动时检测到的效果。
[0124]
进一步的,结合图6,步骤3中,openpose网络分为两个stage,每一个stage又包括两个分支,分别为branch 1和branch 2,其中,特征f输入stage1经过两个分支的处理之后得到s1和l1,而在stage2之后,阶段t网络的输入有s
t-1
,l
t-1
,f,每个阶段的输入为:
[0125][0126][0127]
进一步的,openpose神经网络模型获取方法具体为:
[0128]
步骤1:建立训练集和测试集,并进行图像预处理;
[0129]
步骤2:将预处理后的数据集二进行特征提取,获取原始特征图;
[0130]
步骤3:将原始特征图输入基于openpose算法的神经网络模型对人体骨骼关键点进行识别,该算法采用“自下而上”的人体姿态估计思路,可对人体骨骼的关键点进行识别标记。该算法通过快速计算以一帧w
×
h尺寸的彩色图像输入,然后输出一张具有输入图像中每个井下人员的人体骨骼关键部位的二维坐标图像;
[0131]
步骤4:输入的彩色图像进入vgg-19的前10层网络初始化,同时进行权重微调,获得一组特征映射作为第一阶段的输入;
[0132]
步骤5:将网络分成分支1和分支2,分支1用于置信图s的预测,分支2用于关节点之间的亲和度l的预测;
[0133]
步骤6:获得置信图和亲和度的信息之后,使用偶匹配(bipartite matching)求出part association,将同一个井下人员目标的骨骼关键部位的点相互连接起来,最终生成人体骨架图。
[0134]
进一步的,步骤36中,若为多人检测问题,可转化为二分图匹配问题,设g=(v,e)是一个无向图,若顶点v可分割成两个互不相交的子集(a,b),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in a,j in b),则称图g为一个二分图,使用匈牙利算法求得相连关键点最优匹配,匈牙利算法计算过程为:
[0135][0136]
对于任意的一对关节点位置d
j1
和d
j2
,通过计算pafs的线性积分来表征骨骼点对的相关性,也表征了骨骼点对的置信度,计算过程为:
[0137][0138]
为了快速计算积分,采用均匀采样的方式近似关节点间的相似度,其计算过程为:
[0139]
p(u)=(1-u)d
j1
+ud
j2
。
[0140]
结合图9,本发明还提供一种基于机器视觉的井下人员不安全行为智能识别及预警系统,运行前述基于机器视觉的井下人员不安全行为快速分析与识别方法,整体架构包括系统应用层、系统处理层、模型检测层、系统分类层及基础环境层;
[0141]
系统应用层主要是地面人员的可视化展示界面,企业负责人和系统管理员可通过视频监控系统、大屏显示系统、网络通信系统、存储备份系统、呼叫中心系统及声光报警系统对井下人员的行为状态一目了然,并且将所有监控数据记录在数据库里面,为计算机学习识别不同环境下的不安全行为不断建立新的数据集;
[0142]
系统处理层包括通过摄像机对井下人员的人员数量、面部状态以及活动轨迹数据进行收集,通过光纤传输到系统处理层;
[0143]
系统处理层将从井下摄像机记录的数据通过计算机对图像进行预处理,预处理主要包括去雾、降噪、平滑及锐化的过程,增强图像的亮度和对比度,使其目标更容易被检测到;
[0144]
模型检测层是系统处理层的核心处理层之一,在系统对输入的图像进行预处理完成后,yolov5模型和openpose模型对输入的图像进行不安全行为检测,通过与预训练的数据库中的数据进行比对分析得出是否存在不安全行为;
[0145]
若系统检测到存在不安全行为,系统分类层作为系统处理层的另一核心处理层,会对其检测到的不安全行为通过置信度、关节点阈值标准来进行不安全行为的判断;
[0146]
基础环境层即井下布控的必备设施,主要包括智能摄像机、环网基站和声光报警器,智能摄像机在分辨率和补光方面有着较高的优势,通过摄像机补光和计算机预处理过程中亮度增强两次处理,图像更加清晰,人物特征更加鲜明;环网基站为井下和地面传输重要信息和数据提供必要的网络环境,同时实时地将数据存储到数据库中,为计算机模型学习不断提供新的数据集;声光报警器则对违章人员进行提示预警。
[0147]
在以上的描述中阐述了很多具体细节以便于充分理解本发明。但是以上描述仅是本发明的较佳实施例而已,本发明能够以很多不同于在此描述的其它方式来实施,因此本发明不受上面公开的具体实施的限制。同时任何熟悉本领域技术人员在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1