基于体感控制的多层界面与信息可视化呈现方法及系统与流程
1.本技术涉及ar显示的领域,尤其是涉及一种基于体感控制的多层界面与信息可视化呈现方法及系统。
背景技术:
2.目前已经有多款ar眼镜可以实现将语音或其他声音信息翻译为文本、图形并显示在用户眼前,听力障碍的人可通过ar眼镜实现与他人的交流。
3.但目前ar眼镜的显示范围有限,通常只有15-50
°
视场角,难以将环境中的全部信息展示出来。
4.对于听力障碍人群大量信息同时被可视化展示时,用户难以定位和阅读自己关注的信息;如果将当前全部可视化的信息拆分为多屏,并使用遥控器/摇杆、按键、触摸屏、触摸板等交互界面进行控制,产品可以在呈现全部可视化信息的同时让用户能够找到自己关注的内容,但这样的操作方式不直观,而且效率较低,当用户找到自己关注的信息时全部的可视化信息已经需要刷新。
技术实现要素:
5.为了便于用户快速直观的定位自己所需要的信息并查看,本技术提供一种基于体感控制的多层界面与信息可视化呈现方法及系统。
6.第一方面,本技术提供一种基于体感控制的多层界面与信息可视化呈现方法,采用如下的技术方案:一种基于体感控制的多层界面与信息可视化呈现方法,该方法包括:获取视外界的声音信息,所述声音信息包括语音信息和非语音信息;根据预设的转化规则将所述声音信息转化为可视化信息;根据预设的定位方式确定每一声音信息的方位信息;根据每一声音的方位信息将每一所述声音信息对应的可视化信息在空间层的预设位置显示,所述空间层固定;获取用户头部的姿态信息,并根据所述姿态信息确定头部朝向的方位信息;记录用户头部朝向每一方向的时间;当所述时间大于预设时间时,调取所述方向对应的可视化信息并在静态层显示,所述静态层随人体头部移动。
7.通过采用上述技术方案,通过获取外界的声音信,获取到外界的声音信息后将外界的声音信息转化为可视化信息,确定每一声音信息的方位信息,并根据方位信息将声音信息对应的可视化信息在空间层的预设位置进行显示,之后获取用户头部的姿态信息,根据姿态信息确定用户头部的朝向,当判断用户头部朝向某一方向超过预设时间时,将该方向对应的可视化信息在静态层显示,显示时,在空间中空间层的深度大于静态层,且空间层固定,静态层在用户眼前显示,且跟随用户头部移动,采用上述方式,便于听力障碍用户快
速直观的定位自己所需要的信息并查看。
8.可选的,所述根据预设的转化规则将所述声音信息转化为可视化信息的方法,具体包括:根据预设的语音识别算法对所述语音信息进行识别,并将所述语音信息转化为文本信息;根据预设的声音识别算法对所述非语音信息进行识别,并将所述非语音信息转化为图片信息。
9.通过采用上述技术方案,语音信息转化为文本信息,将非语音信息转化为图片信息,使得听力障碍的用户能更加直观的了解周围情况,不仅仅只能获取语音信息,对于其他非语音信息同样能通过视觉获取,提高用户的体验感。
10.可选的,所述根据预设的定位方式确定每一声音信息的方位信息的方法,具体包括:获取每一声音信息的声源定位数据;根据所述声源定位数据确定声音信息的方位信息。
11.可选的,所述可视化信息于所述空间层上实时更新显示。
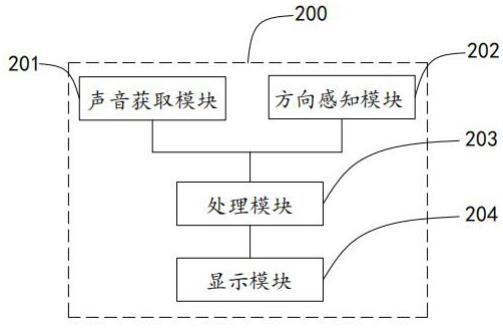
12.第二方面,本技术提供一种基于体感控制的多层界面与信息可视化呈现系统,采用如下的技术方案:一种基于体感控制的多层界面与信息可视化呈现系统,包括包括显示模块、声音获取模块、方向感知模块和处理模块;所述声音获取模块用于获取外界的声音信息;所述方向感知模块用于实时检测用户头部的姿态输出姿态信息;所述处理模块用于接收所述声音信息,将所述声音信息转化为可视化信息、获取所述声音信息的声源定位数据,根据所述声源定位数据确定声音信息对应的方位信息、根据声音信息对应的方位信息输出第一显示信号;所述处理模块接收所述姿态信息,根据所述姿态信息确定用户头部朝向的方位信息,并记录朝向每一方向的时间,当所述时间大于预设时间时输出第二显示信号;所述显示模块用于接收所述第一显示信号将所述可视化信息在空间层显示、接收所述第二显示信号将特定的可视化信息在静态层显示。
13.可选的,所述声音获取模块包括多个麦克风,多个所述麦克风成阵列排布。
14.可选的,所述显示模块为近眼显示器。
15.可选的,所述方向感知模块为惯性测量单元。
16.可选的,所述显示模块、声音获取模块、方向感知模块和处理模块集成于ar眼镜内。
17.通过采用上述技术方案,将显示模块、声音获取模块、方向感知模块和处理模块都集成在ar眼镜中便于用户使用。
18.综上所述,本技术包括以下至少一种有益技术效果:1.通过获取外界的声音信,获取到外界的声音信息后将外界的声音信息转化为可视化信息,确定每一声音信息的方位信息,并根据方位信息将声音信息对应的可视化信息在空间层的预设位置进行显示,之后获取用户头部的姿态信息,根据姿态信息确定用户头
部的朝向,当判断用户头部朝向某一方向超过预设时间时,将该方向对应的可视化信息在静态层显示,显示时,在空间中空间层的深度大于静态层,且空间层固定,静态层在用户眼前显示,且跟随用户头部移动,采用上述方式,便于听力障碍用户快速直观的定位自己所需要的信息并查看;2.通过将语音信息转化为文本信息,将非语音信息转化为图片信息,使得听力障碍的用户能更加直观的了解周围情况,不仅仅只能获取语音信息,对于其他非语音信息同样能通过视觉获取,提高用户的体验感;3.通过将显示模块、声音获取模块、方向感知模块和处理模块都集成在ar眼镜中便于用户使用。
附图说明
19.图1是本技术提供的基于体感控制的多层界面与信息可视化呈现系统的结构框图。
20.图2本实施例中空间层与静态层的关系示意图。
21.图3是本技术提供的基于体感控制的多层界面与信息可视化呈现方法的流程图。
22.图4是本实施例具体示例图。
23.附图标记说明:10、空间层;20、静态层;200、ar眼镜;201、声音获取模块;202、方向感知模块;203、处理模块;204、显示模块。
具体实施方式
24.以下结合附图1-4对本技术作进一步详细说明。
25.本技术实施例公开一种基于体感控制的多层界面与信息可视化呈现系统。参照图1,基于体感控制的多层界面与信息可视化呈现系统包括:显示模块204、声音获取模块201、方向感知模块202和处理模块203,声音获取模块201、方向感知模块202和数据处理模块203均与处理模块203连接,本实施例中,显示模块204、声音获取模块201、方向感知模块202和处理模块203均集成在ar眼镜200中,采用上述方式将上述功能模块均集成在ar眼镜200中,便于用户的使用,在其他实施方式中,显示模块204、声音获取模块201、方向感知模块202和处理模块203也可单独设置,在此不做限制。
26.使用时,用户戴上ar眼镜200,声音获取模块201用于实时获取外界声音信息,方向感知模块202用于实时检测用户头部的姿态输出姿态信息,处理模块203用于接收声音信息,将声音信息转化为可视化信息,同时处理模块203还获取声音信息的声源定位数据,并根据声源定位数据确定声音信息的方位信息,并根据声音信息对应的方位信息和初始姿态信息输出第一显示信号,初始姿态信息为开始工作时,方向感知模块获取到的人体头部的姿态信息,显示模块204接收第一显示信号,将声音信息对应的可视化信息显示在空间层10的特定位置,空间层10的显示范围根据声音信息的方位信息确定,空间层10用于实时显示采集到的外界声音信息转化为的可视化信息,且可视化信息根据采集到的声音信息在空间层10上实时更新。
27.处理模块203还用于接收姿态信息,确定用户头部的朝向的方位信息,同时处理模块203还会实时记录时间,当用户头部朝向某一方向的时间超过预设时间时,此时处理模块
203输出第二显示信号,显示模块204接收第二显示信号,将用户头部的朝向的方位信息上的可视化信息,调取至静态层20显示。
28.本实施例中,空间层10相对用户为固定显示界面,静态层20为移动显示界面,静态层20跟随用户的头部移动,实时显示在用户眼前。在空间上,空间层10的深度大于静态层20的深度,空间层10的显示界面的面积大于静态层20显示界面的面积,空间层10与静态层20的关系如图2所示。为了实现空间层10的固定,处理模块203实时接收姿态信息并判断当前姿态信息和初始姿态信息的变化,当用户头部朝特定方向转动一定角度时,处理模块204控制空间层10向相反方向转动一定角度,实时在用户眼前显示空间层10中相对应的部分,从而为用户提供转动头部也可观察一个相对自己静止的大屏幕的体验。上述保持空间层10相对用户为固定显示界面为本领域技术人员公知技术手段在此不详细多赘述。
29.本实施例中,声音获取模块201为包括多个麦克风,多个麦克风组成采集阵列,能周期性采集外界声音,同时便于根据多个麦克风的拾音差异确定声源定位数据,从而便于处理模块203根据声源定位数据确定声音信息的方位信息;方向感知模块202优选为惯性测量单元,惯性测量单元包括3轴陀螺仪和3轴加速度计,为本领域常规的检测设备,在此不做过多赘述。惯性测量单元可以采集用户头部的俯仰角、偏航角和翻滚角,显示模块204为近眼显示器,近眼显示器204可基于光波导或自由曲面或激光投影任意一种显示方案,在此不做限制,近眼显示器204能够以一定的刷新率显示文字,图像处理模块203可为服务器、mcu等具有数据处理功能的设备,在此不做限制。
30.采用上述方案,当听力障碍的用于使用该ar眼镜200时,将外界的声音信息转化为眼镜可见的可视化信息,为听力障碍的用户提供了便利,同时空间层10和静态层20的显示方式便于用户快速直观的定位自己所需要的信息并查看,提高用户的使用体验。
31.本技术实施例还公开一种基于体感控制的多层界面与信息可视化呈现方法。该方法应用于上述基于体感控制的多层界面与信息可视化呈现系统中,参照图3,基于体感控制的多层界面与信息可视化呈现方法包括:s101:获取视外界的声音信息。
32.具体的,声音信息包括语音信息和非语音信息,语音信息即为人的说话声,非语音信息为警报、鸣笛、动物叫声、敲门声等,通过设置在ar眼镜200内的多个麦克风实时采集外界环境的声音信息,并将采集到的声音信息传输至处理模块203。
33.s102:根据预设的转化规则将声音信息转化为可视化信息。
34.具体的,在对语音信息进行转化时采用预设的自动语音识别算法,将语音信息转化为可视化的文本信息,听力障碍用户可通过视觉观察得知外界人员在说什么;在对非语音信息进行转化时首先采用预设的声音识别算法识别,非语音信息对应的物体,并将其转化为可视化的图片信息,如识别到非语音信息为汽车鸣笛声,将其转化为汽车图片进行显示,使得听力障碍人员可以知道有车辆经过。本实施例中预设的自动化语音识别算法基于隐马尔可夫模型实现,预设的声音识别算法通过基于深度卷积神经网络的算法模型实现,均为本领域技术人员公知的技术手段,在此不做过多赘述。
35.s103:根据预设的定位方式确定每一声音信息的方位信息。
36.具体的,通过多个麦克风组成采集阵列周期性对外界声音信息进行采集,处理模块203可根据多个麦克风的拾音差异确定声源定位数据,并根据声源定位数据确定声音信
息的方位信息,上述根据多个麦克风的拾音差异确定声源方位为本领域技术人员公知的技术手段,在此不做详细赘述。
37.s104:根据每一声音的方位信息将每一声音信息对应的可视化信息在空间层10的预设位置显示。
38.具体的,确定声音信息的方位信息后,将声音信息对应的可视化信息根据unity3d的空间坐标系叠加显示在空间层10对应的方位上,采用unity3d的空间坐标系定位空间方向为本领域的常规技术手段,在此不做详细赘述。
39.s105:获取用户头部的姿态信息,并根据姿态信息确定头部朝向的方位信息。
40.具体的,当用户戴上ar眼镜200时,通过设置在ar眼镜200内部的惯性测量单元可以实时感知用户头部的俯仰角、偏航角和翻滚角,并输出至处理模块203,处理模块203根据俯仰角、偏航角和翻滚角可以实时得知用户头部朝向的方位信息。
41.s106:记录用户头部朝向每一方向的时间。
42.s107:当时间大于预设时间时,调取所述方向对应的可视化信息并在静态层20显示。
43.具体的,在步骤s106和步骤s107中,处理模块203根据姿态信息实时确定用户头部朝向的方位信息的同时实时记录用户头部朝向每一方向的时间,当用户头部朝向某一方向的时间超过预设时间时,处理模块203根据用户头部当前朝向的方位信息,确定空间层10上对应该方位信息的可视化信息,并将可视化信息调取至静态层20进行显示。本实施例中,预设时间为人工自行确定存储至处理模块203中。
44.参照图4,例如,当前环境中,在屋内有五人在对话,还有敲门声、下雨声和键盘声,用户戴上ar眼镜200,采集环境中所有的声音信息,并确定每一声音信息的方位信息,将声音信息转化为对应的可视化信息,且在空间成的预设位置进行显示,当用户头部朝向人员1时,在静态层20显示“这次的讨论非常有成果”的文本信息和“门”的图片信息,当用户头部朝向人员2时,在静态层20显示“是的,我们需要多沟通”的文本信息,当用户头部朝向人员3时,静态层20显示“下次把小张也叫上吧”的文本信息以及“键盘”的图像信息,当用户头部朝向人员4时,静态层20显示“我做了一些讨论纪要”的文本信息,当用户头部朝向人员5时,静态层20显示“好的。没问题”的文本信息和“下雨”的图片信息。采用上述方案,使得即使是听力障碍人员也可参加到讨论中,能及时得知每个人在说什么以及外界的其他的声音信息。
45.采用上述方案,通过获取外界的声音信,获取到外界的声音信息后将外界的声音信息转化为可视化信息,确定每一声音信息的方位信息,并根据方位信息将声音信息对应的可视化信息在空间层10的预设位置进行显示,之后获取用户头部的姿态信息,根据姿态信息确定用户头部的朝向,当判断用户头部朝向某一方向超过预设时间时,将该方向对应的可视化信息在静态层20显示,显示时,在空间中空间层10的深度大于静态层20,且空间层10固定,静态层20在用户眼前显示,且跟随用户头部移动,便于听力障碍用户快速直观的定位自己所需要的信息并查看,为听力障碍人员提供了便利。
46.以上均为本技术的较佳实施例,并非依此限制本技术的保护范围,故:凡依本技术的结构、形状、原理所做的等效变化,均应涵盖于本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1