一种基于文本聚类的视频弹幕与评论主题融合的方法
1.本发明涉及自然语言处理领域,具体涉及流媒体平台视频弹幕及评论之间的文本聚类以及通过计算主题簇之间的相似度及词与词的相似度实现融合两模型聚类结果的问题。
背景技术:
2.互联网的繁荣发展,人们获取信息及沟通交流的方式不断多元化,也逐渐形成一种新型的社交关系。人们活跃于微信、微博等社交网站,豆瓣、知乎等论坛以及大量流媒体平台源源不断地提供大量可在线或实时观看的音视频,诸如腾讯视频、哔哩哔哩弹幕网、抖音等分别对应长、中、短三种视频类型。用户随时随地可以通过这种平台观看视频、音频、直播,随之而来的还有弹幕、评论等非结构化数据的涌现,人们不再仅仅是简单的接收流媒体所带来的信息,与此同时他们更愿意通过弹幕及评论的方式来输出自己的观点、表达各自的情感。这样的数据也称为用户生成内容,即用户将自己原创的内容通过互联网平台进行展示或者提供给其他用户。这些平台积累了大量用户生成内容,从丰富的文档中自动提取有用的信息许多领域的研究人员的兴趣,特别是自然语言处理领域,诸如情感分析、意见挖掘、舆情分析、主题发现等技术随之产生。弹幕作为一种较为新型的交互行为,文本篇幅较短,能够让正在观看视频的人看见其他人彼时或此刻所发表的关于当前片段的想法,达到增强与其他观影者即时互动的目的。弹幕这一机制最早来源于日本视频网站niconico,哔哩哔哩弹幕网是国内较早采用此模式的流媒体之一,如今几乎所有的国内视频网站都采用了弹幕功能。而评论相比于弹幕而言,篇幅通常更长,也是对整个视频更全面、更概括性的评价,人们通常通过点赞、追评的形式来认同和自己观点一致的评论。弹幕数据以短文本,强用户交互性,实时性的特点促进用户之间的沟通交流,而评论更多是中长文本,总括性来表达用户自身的看法。
3.聚类算法是一种无监督算法,其核心概念是通过把数据划分为几个簇,使簇之间的距离尽可能的答,簇内距离尽可能小。聚类算法种类多样,各具优缺点。本发明采用bertopic模型、基于tf-idf的k-means算法模型分别聚类评论、弹幕文本数据。现有研究大多只着眼于研究弹幕或评论中的单一文本类型,本发明将弹幕及评论两种文本数据通过聚类进行融合,可以更加全面地获取用户对平台及视频的看法,提升服务水平及能力。
技术实现要素:
4.本发明正是针对现有技术中存在的问题,提供一种基于文本聚类的视频弹幕与评论主题融合的方法,该技术方案结合自定义词典及扩展停用词运用bertopic模型改善了文本的聚类效果,并且通过计算主题簇之间的相似度及词与词之间的相似度的方法将弹幕及评论两个聚类模型的结果融合起来,更加全面地获取用户对平台及视频的看法和偏好,有利于提升服务水平及能力。
5.为了实现上述目的,本发明的技术方案如下,基于文本聚类的视频弹幕与评论主
题融合的方法,其特征在于,所述方法包括以下步骤:
6.步骤1:编写python程序爬取视频下方的评论及弹幕的文本内容;
7.步骤2:根据自定义词典及扩展停用词对数据进行预处理;
8.步骤3:运用bertopic模型处理评论数据得到其主题;
9.步骤4:运用基于tf-idf的k-means算法处理弹幕数据得到其主题簇;
10.步骤5:利用衡量主题之间及词与词之间的相似度从而实现“求同存异”的模型融合。
11.步骤5-1:通过计算余弦相似度,求得各个簇代表的词向量之间的相似度,设置相似度阈值,当相似度大于等于阈值时则认为簇之间相似,反之则不同,把被认为相似的簇输入到下一步,同时将与其余任何簇都不同的簇存放在集合c中;
12.步骤5-2:融合相似簇的主题词,首先选取一对相似簇,设置其中一个簇为基准簇,调用synonyms中文近义词工具包把相似簇中各自词输入程序,获得对应词的距离分数,设置距离分数阈值,当距离分数大于等于阈值时则认为两者为近义词,反之则不同,若两词被判断为近义词则只保留基准簇中的该词。若两词不同且不同词出现在基准词中则保留不变,若两词不同且出现在比较簇中则将该词添加到基准簇中。比较完成后将该基准簇存放入集合c中;步骤5-3:将每一对相似簇进行步骤5-2的操作;
13.步骤5-4:输出集合c为对聚类主题进行融合的最终结果。
14.具体如下:
15.步骤1:通过python的爬虫相关库,实现http请求操作,得到服务器响应,获取到网页源代码,分析网页结构,分别提取视频下方的评论及弹幕并保存;
16.步骤2:在预处理过程中运用正则表达式匹配文本去除特殊符号、多余空白、转化繁体字,构建自定义词典使词能更准确地划分,使用扩展的停用词表去除文本中无意义或不重要的词。本文根据文本的特性,构建自定义词典。自定义词典中的词语是根据当前流行的网络用语及节目、人物名字人工添加的,例如“前方高能”、“打call”等,停用词是文本中经常出现的一些衔接语句的词或者对分析没有用处的词。本文构建的停用词表融合了中文停用词表、哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词库四个主流词典的所有词并人工添加了部分在视频语境下不太重要的词,运用jieba库进行分词处理;
17.步骤3:由bertopic主题模型处理评论文本,算法大致包括3个阶段:使用bert进行文档嵌入、文档聚类、创建主题表示得到主题簇;
18.步骤3-1:使用bert模型将句子转换,从一组文档中创建文档嵌入。模型是针对多种语言进行的预训练,对于创建文档或句子嵌入都非常有用;
19.步骤3-2:由于聚类算法难以在高维空间中对数据进行聚类。在对文档进行聚类之前,需要降低生成的嵌入的维数。为此,模型使用umap这种创新的降维流形学习算法,可以很好地保留了嵌入的局部和全局结构。umap算法主要包括两阶段。第一阶段构建模糊拓扑,运用最近邻算法对于空间中的每个点xi的k最近邻集合有{x
i1
,x
i2
…
,x
ik
},ρi代表每个点与最近邻集合的最小距离,σi为各点的标准差,p
ij
代表所求概率,根据式(1)-(4)得到ρi、σi以及p
ij
:
20.ρi=min{d(xi,x
ij
)|1≤j≤k,d(xi,x
ij
)>0}
ꢀꢀ
(1)
[0021][0022][0023]
p
ij
=p
i|j
+p
j|i-p
i|j
p
j|i
ꢀꢀ
(4)
[0024]
第二阶段是简单地优化低维表示,使其具有尽可能接近的模糊拓扑表示,如式(5)所示,通常默认的参数a≈1.93,b≈0.79,并将式(6)的交叉熵公式作为代价函数训练;
[0025]qij
=(1+a(y
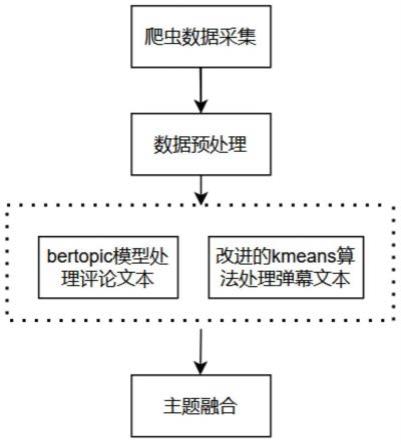
i-yj)
2b
)-1
ꢀꢀ
(5)
[0026][0027]
步骤3-3:使用hdbscan对降维的嵌入进行聚类,运用式(7)衡量点与点之间的距离,运用层次聚类的思想,使用最小生成树构建点与点之间的层次模型,并且为了控制生成的簇不要过小,限制了最小生成树剪枝的最小子树,其分裂度量方式是将每个点的密度度量定义为其中ε是该点和剩余聚类中点之间的最短距离;簇的生成密度定义为λ
birth
是这个簇生成时分裂边的导数,最后一个簇的密度由式(8)求得,通过hdbscan实现最大化簇之间的距离及最小化簇内距离,
[0028]dmreach-k
(a,b)=max{corek(a),corek(b),distance(1,b)}
ꢀꢀꢀꢀ
(7)
[0029][0030]
步骤3-4:使用c-tf-idf对主题进行提取和删减,利用最大边际相关法(mmr)计算查询文本和搜索文档之间的相似度,并对文档进行排序,提高词的连贯性和多样性。c-tf-idf是一种基于类的tf-idf方法,其中c是已识别的聚类。为了探索在模型生成的文档聚类中基于其内容是什么使一个簇不同于另一个簇,模型对tf-idf进行修改,使其允许每个文档聚类即可使用有意义的词,而不是每个单独的文档。当对一组文档应用tf-idf时,是为了比较文档之间单词的重要性。然而若将单个簇中的所有文档视为单个文档,再应用tf-idf,结果将是集群中单词的重要性分数。集群中越重要的单词,就越能代表该主题。c-tf-idf得分越高,其主题越有代表性。c-tf-idf计算得分的公式为式(9)。其中tf
x
表示词x在簇c中出现的频率,f
x
是词x在所有簇中出现的频率,a表示每个簇的平均词汇个数。最大边际相关法计算公式为式(10)。其中q指查询文本,c指搜索文档集合,r为一个已经求得的以相关度为基础的初始集合,di在集合c中,dj在集合r中,argmax表示搜索返回的k个句子的索引。
[0031]
[0032][0033]
步骤4:运用基于tf-idf的k-means算法算法处理弹幕文本,模型采用相对于中心点的距离作为指标,通过不断地迭代将数据分为输入k个类。
[0034]
步骤4-1:使用tf-idf权重的哈希向量化表示,向量化将文本文档集合转换为数字集合特征向量,文档由单词出现来描述,同时完全忽略文档中单词的相对位置信息。tf-idf认为字词的重要性与其在文本中出现的频率成正比,与其在语料库中出现的频率成反比。tf代表词频,词语在文章中出现的次数,见式(11)。idf叫做逆文档频率,见式(12),有些词可能在文本中频繁出现,但并不重要,也即信息量小,如这个、那个这些单词,在语料库中出现的频率也非常大,我们就可以利用这点,降低其权重。tf-idf则是将上面的tf-idf相乘就得到了的综合参数,如式(13)。
[0035][0036][0037]
tf-idf=tf
×
idf
ꢀꢀ
(13)
[0038]
步骤4-2:由于数据维度过高,使用的是svd及正则化处理,svd计算公式为式(14),其中u和v向量都是单位化的向量,u的列向量u1,...,um组成了k空间的一组标准正交基,同样,v的列向量v1,...,vn也组成了k空间的一组标准正交基;
[0039]
m=u∑v
ꢀꢀ
(14)
[0040]
步骤4-3:运用基于tf-idf的k-means算法算法处理降维后的向量,运用肘方法选择最佳簇数在聚类后可以展示每个聚类结果中的一些高频词汇,k-means算法的算法步骤为:
[0041]
1)选择初始化的k个样本作为初始聚类中心;
[0042]
2)针对数据集中每个样本计算它到k个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中;
[0043]
3)针对每个类别重新计算它的聚类中心,即属于该类的所有样本的质心;
[0044]
4)重复上面2、3两步操作,直到聚类中心不再发生变化;
[0045]
步骤5:先计算主题簇之间的相似度再计算词与词之间的相似度,从而实现“求同存异”的模型融合,
[0046]
步骤5-1:根据式(15)计算余弦相似度,式中a、b均代表向量,求得各个簇代表的词向量之间的相似度。设置相似度阈值为a=0.8,当相似度大于等于0.8时则认为簇之间相似,反之则不同。把被认为相似的簇输入到下一步,同时将与其余任何簇都不同的簇存放在集合c中,
[0047][0048]
步骤5-2:融合相似簇的主题词,首先选取一对相似簇,设置其中一个簇为基准簇,调用synonyms中文近义词工具包把相似簇中各自词输入程序,获得对应词的距离分数,设置距离分数阈值为b=0.8,当距离分数大于等于0.8时则认为两者为近义词,反之则不同,若两词被判断为近义词则只保留基准簇中的该词。若两词不同且不同词出现在基准词中则保留不变,若两词不同且出现在比较簇中则将该词添加到基准簇中。比较完成后将该基准簇存放入集合c中,
[0049]
步骤5-3:将每一对相似簇进行步骤5-2的操作,
[0050]
步骤5-4:输出集合c为对聚类主题进行融合的最终结果,
[0051]
另外,本发明提出了一种基于文本聚类的视频弹幕与评论主题融合的系统,所述方法包括数据采集模块、数据预处理模块、聚类模块、模型融合模块,其中,
[0052]
数据采集模块:通过python的爬虫相关库,实现http请求操作,得到服务器响应,获取到网页源代码,分析网页结构,分别采集视频下方的评论及弹幕的原始文本内容并保存。
[0053]
数据预处理模块:运用正则表达式匹配文本去除特殊符号、多余空白、转化繁体字,构建自定义词典实现更加精确地分词,使用扩展的停用词表去除文本中无意义或不重要的词。
[0054]
聚类模块:运用bertopic模型处理评论数据,基于tf-idf的k-means算法算法处理弹幕数据得到各自的主题簇;
[0055]
模型融合模块:根据算法计算主题簇之间的相似度再计算词与词之间的相似度,从而实现“求同存异”的模型融合,并输出结果。
[0056]
本发明与现有技术相比,具有如下的优点和有益效果:本发明编写爬虫程序爬取视频下方评论及弹幕原始文本,结合自定义词典及扩展停用词运用bertopic模型改善了文本的聚类效果,并且通过计算主题簇之间的相似度及词与词之间的相似度的方法将弹幕及评论两个聚类模型的结果融合起来。弹幕数据以短文本,强用户交互性、实时性、信息量少的特点促进用户之间的沟通交流,而评论更多是中长文本,总括性来表达用户自身的看法。评论相比于弹幕而言,篇幅通常更长,也是对整个视频更全面、更概括性的评价,人们通常通过点赞、追评的形式来认同和自己观点一致的评论。将两者结合分析能够更加全面地获取用户对平台及视频的看法和偏好,可以学习到更丰富层次的语义信息,有利于提升服务水平及能力。
附图说明
[0057]
图1是本发明的基于文本聚类的视频弹幕与评论主题融合的方法具体流程示意图;
[0058]
图2是本发明的基于文本聚类的视频弹幕与评论主题融合的方法的bertopic模型
结构示意图;
[0059]
图3是本发明的基于文本聚类的视频弹幕与评论主题融合的方法的融合算法示意图;
[0060]
图4是本发明的基于文本聚类的视频弹幕与评论主题融合的系统的模块结构示意图。
具体实施方式
[0061]
为了加深对本发明的理解,下面结合附图对本实施例做详细的说明。
[0062]
实施例1:参见图1-图4,为使本发明的上述目的、技术方案和优点更加清楚明白,下面结合实施例和附图对本发明的具体实施方式做详细的说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。基于本发明中的实施例,本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的保护的范围。
[0063]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少-一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在
‑‑
个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。同时在本发明的描述中,需要说明的是,术语中的“上、下、内和外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一、第二或第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。本发明中除非另有明确的规定和限定,术语“安装、相连、连接”应做广义理解,例如:可以是固定连接、可拆卸连接或一体式连接;同样可以是机械连接、电连接或直接连接,也可以通过中间媒介间接相连,也可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
[0064]
实施例1:
[0065]
基于文本聚类的视频弹幕与评论主题融合的方法,如图1的流程示意图所示,根据本发明具体实例基于文本聚类的视频弹幕与评论主题融合的方法包括如下步骤:
[0066]
(1)执行本发明的方法,首先执行步骤1,获取待分析的视频下方的原始弹幕及评论文本。本实施例爬取了2020年哔哩哔哩弹幕网跨年演唱会视频下方的弹幕及评论,其中弹幕数量为245611条,评论数量为28371条,
[0067]
(2)其次,执行步骤2,对获取的数据集做文本预处理操作,运用正则表达式匹配文本去除特殊符号、多余空白、转化繁体字,构建自定义词典使词能更准确地划分,使用扩展的停用词表去除文本中无意义或不重要的词。本文根据文本的特性,构建自定义词典。自定
义词典中的词语是根据当前流行的网络用语及节目、人物名字人工添加的,例如“前方高能”、“打call”等。停用词是文本中经常出现的一些衔接语句的词或者对分析没有用处的词。本文构建的停用词表融合了中文停用词表、哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词库四个主流词典的所有词并人工添加了部分在视频语境下不太重要的词,运用jieba库进行分词处理,
[0068]
(3)文本集处理好后,执行步骤3及步骤4,分别用bertopic模型、基于tf-idf的k-means算法模型对处理后的评论文本、弹幕文本进行聚类建模。评论文本聚类最佳簇数自动生成,弹幕文本最佳簇数根据肘方法来选择。此实施例中评论文本聚类模型的最佳簇数为4,弹幕文本选择簇数为8,
[0069]
表1评论文本聚类主题簇提取结果数据表
[0070] 012345678cluster1某歌手某歌手音乐明星年轻人某歌手回忆杀某乐队流量cluster2拜年祭元旦节舞台节目直播文化交流视频观众第一次cluster3支持感动厉害吹爆卫视一线前沿祝福精彩cluster4辣眼睛举报广告宣传小学生粉丝文化弹幕素质攻击
[0071]
参照表1可以看出,能够看出评论经过模型训练提炼出三个聚类主题簇,每个簇各提取9个关键词,cluster1中出现的大多是歌手明星等词汇,可见晚会音乐、歌手、明星等是吸引年轻人的一个主要因素,因此对于晚会举办平台而言选择合适的歌手明星以及能够勾起观众回忆的音乐是吸引流量的关键。cluster2中出现了“拜年祭”、“元旦节”、“舞台”、“节目”、“直播”、“文化交流”、“第一次”等词,体现在这个晚会的舞台及节目是能够吸引人的。cluster3主要是对晚会的一些夸赞,以及在节日氛围下的祝福。cluster4主要出现的是负面的词汇,其中对于“广告”、“粉丝文化”、“弹幕”的吐槽,值得平台去加强管控。
[0072]
表2弹幕文本聚类主题簇提取结果数据表
[0073][0074]
参照表2可以看出,弹幕经过模型训练提炼出的主题更具自身特色,这是由于弹幕的时效性,更多是对具体节目的详细看法,而评论则通常是对整个视频的总括性描述。其中有8个聚类主题簇,每个簇各提取9个关键词。cluster1主要体现出观看人数众多,很多是在晚会结束后前来观看的。cluster2主要描述对于魔术失败的不满。cluster3主要体现出观众对五月天压轴演出产生青春的感慨。cluster4主要表达对歌手的喜欢,cluster5体现观
众多次观看这个视频,体现对视频的认可。cluster6主要是对方老师演奏乐器的赞扬,称其为“人形唢呐”。cluster7是视频观看者对现场观众的一些评价。cluster8主要体现了节目勾起观看者的青春回忆。
[0075]
(4)最后根据本方法提出的融合方法,先计算主题簇之间的相似度再计算词与词之间的相似度,从而实现“求同存异”的模型融合。根据步骤5中式(15)计算余弦相似度,求得各个簇代表的词向量之间的相似度。设置相似度阈值为0.8,当相似度大于等于0.8时则认为簇之间相似,反之则不同。把被认为相似的簇输入到下一步,同时将与其余任何簇都不同的簇存放在集合c中。融合相似簇的主题词,首先选取一对相似簇,设置其中一个簇为基准簇,调用synonyms中文近义词工具包把相似簇中各自词输入程序,获得对应词的距离分数,设置距离分数阈值为0.8,当距离分数大于等于0.8时则认为两者为近义词,反之则不同。若两词被判断为近义词则只保留基准簇中的该词。若两词不同且不同词出现在基准词中则保留不变,若两词不同且出现在比较簇中则将该词添加到基准簇中。比较完成后将该基准簇存放入集合c中。将每一对相似簇进行前述的比较操作。最后输出集合c为对聚类主题进行融合的最终结果。
[0076]
表3评论及弹幕聚类结果融合结果数据表
[0077] 0123456789cluster1上班摸鱼补课举手下午疯狂六万人两万人四万人-cluster2破案鬼畜倍速第一次失败魔术魔术师小哥观众-cluster3乐器方老师大师老爷子人形唢呐第一次一堆
‑‑
cluster4某歌手某歌手音乐明星年轻人某歌手回忆杀某乐队流量某乐队cluster5拜年祭元旦节舞台节目直播文化交流视频观众第一次-cluster6辣眼睛举报广告宣传小学生粉丝文化弹幕素质攻击-[0078]
参照表3可以看出,结果将弹幕及评论的主题要素做了融合后分为7个主题,诸如观看人数众多、魔术失败、乐器演奏、资深歌手、文化交流、弹幕礼仪等方面,可以更加全面综合且简洁地去分析视频,为流媒体平台及服务提供者提供支持。
[0079]
实施例2:
[0080]
参照图4,为本发明的第二个实施例,该实施例不同于第1个实施例的是,提供了一种基于文本聚类的视频弹幕与评论主题融合的分析系统,包括:
[0081]
数据采集模块,用于采集各大网络视频平台中的评论及弹幕原始文本数据。
[0082]
数据预处理模块连接于数据采集模块,其用于接收数据采集模块的采集数据信息进行预处理,获得原始文本的分词结果。
[0083]
聚类模块与数据预处理模块相连接,其运用bertopic模型处理评论数据,基于tf-idf的k-means算法处理弹幕数据得到各自的主题簇进行分析。
[0084]
模型融合模块与聚类模块相连接,根据算法计算主题簇之间的相似度再计算词与词之间的相似度,从而实现“求同存异”的模型融合,并输出结果。
[0085]
优选的,本实施例还需要说明的是,聚类模块首先分析两个模型的触发场景、输入参数,通过分析触发场景了解系统是主动还是被动的发起方,其基本思路是低耦合、高内聚,对于外部依赖越小越好,以较好的输出反馈。模型融合模块在进行内部处理时需要分析流程的步骤和数据,数据用于驱动支持流程进展,流程用于分析清楚步骤以及每个步骤所需要的数据。应当认识到,本发明的实施例可以由计算机硬件、硬件和软件的组合、或者通
过存储在非暂时性计算机可读存储器中的计算机指令来实现或实施。所述方法可以使用标准编程技术-包括配置有计算机程序的非暂时性计算机可读存储介质在计算机程序中实现,其中如此配置的存储介质使得计算机以特定和预定义的方式操作一一根据在具体实施例中描述的方法和附图。每个程序可以以高级过程或面向对象的编程语言来实现以与计算机系统通信。然而,若需要,该程序可以以汇编或机器语言实现。在任何情况下,该语言可以是编译或解释的语言。此外,为此目的该程序能够在编程的专用集成电路上运行。
[0086]
此外,可按任何合适的顺序来执行本文描述的过程的操作,除非本文另外指示或以其他方式明显地与上下文矛盾。本文描述的过程(或变型和/或其组合)可在配置有可执行指令的一个或多个计算机系统的控制下执行,并且可作为共同地在一个或多个处理器上执行的代码(例如,可执行指令一个或多个计算机程序或一个或多个应用)、由硬件或其组合来实现。所述计算机程序包括可由一个或多个处理器执行的多个指令。
[0087]
进一步,所述方法可以在可操作地连接至合适的任何类型的计算平台中实现,包括但不限于个人电脑、迷你计算机、主框架.工作站、网络或分布式计算环境、单独的或集成的计算机平台、或者与带电粒子工具或其它成像装置通信等等。本发明的各方面可以以存储在非暂时性存储介质或设备上的机器可读代码来实现,无论是可移动的还是集成至计算平台,如硬盘、光学读取和/或写入存储介质、ram、rom等,使得其可由可编程计算机读取,当存储介质或设备由计算机读取时可用于配置和操作计算机以执行在此所描述的过程。此外,机器可读代码,或其部分可以通过有线或无线网络传输。当此类媒体包括结合微处理器或其他数据处理器实现上文所述步骤的指令或程序时,本文所述的发明包括这些和其他不同类型的非暂时性计算机可读存储介质。当根据本发明所述的方法和技术编程时,本发明还包括计算机本身。计算机程序能够应用于输入数据以执行本文所述的功能,从而转换输入数据以生成存储至非易失性存储器的输出数据。输出信息还可以应用于一个或多个输出设备如显示器。在本发明优选的实施例中,转换的数据表示物理和有形的对象,包括显示器上产生的物理和有形对象的特定视觉描绘。
[0088]
如在本技术所使用的,术语“组件”、“模块”、“系统”等等旨在指代计算机相关实体,该计算机相关实体可以是硬件、固件、硬件和软件的结合、软件或者运行中的软件。例如,组件可以是,但不限于是:在处理器上运行的处理、处理器、对象、可执行文件、执行中的线程、程序和/或计算机。作为示例,在计算设备上运行的应用和该计算设备都可以是组件。一个或多个组件可以存在于执行中的过程和/或线程中,并且组件可以位于一个计算机中以及/或者分布在两个或更多个计算机之间。此外,这些组件能够从在其上具有各种数据结构的各种计算机可读介质中执行。这些组件可以通过诸如根据具有一个或多个数据分组的信号,以本地和/或远程过程的方式进行通信。
[0089]
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
[0090]
需要说明的是上述实施例,并非用来限定本发明的保护范围,在上述技术方案的基础上所作出的等同变换或替代均落入本发明权利要求所保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1