一种乳腺超声影像组学的超高维特征数据相关性分析方法与流程
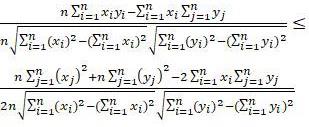
1.本发明涉及乳腺超声影像组学数据分析领域,主要涉及一种乳腺超声影像组学的超高维特征数据相关性分析方法。
背景技术:
2.2012年,lambin等人首次提出了影像组学的概念,影像组学技术是指从医学影像中高通量地提取大量定量特征,结合大数据分析算法,挖掘用以解析临床信息最有价值的特征,来辅助疾病的诊断、治疗及预后评估的技术。影像组学提出以来,在预防危险疾病、辅助诊断和预测病人预后等方面得到广泛的应用。随后,学者们不断对影像组学技术进行拓展与完善,通过上千个高维度特征数据更全面的量化、表征肿瘤的生物学特点。
3.影像组学的过程主要分为三个步骤:首先,对图像做分割处理;然后,提取图像特征,生成量化数据;最后,构建数学模型分析特征数据,从而实现分类及预测。
4.在提取图像特征的过程中,以pyradiomics工具为例,使用wavelet滤波器作为提取特征前图像处理的滤波方法。医学影像的灰度图将产生4种不同的滤波方式(lh、hl、hh、ll)。每种滤波方式使用14个一阶统计量。每一张影像则会产生4*14=56个特征。对上述方法加上24个灰度共生矩阵特征特征,同时使用原始图像(不使用滤波器)做特征提取,则会产生(1+4)*(14+24)=190个特征。如果组合使用不同的滤波器算法和特征技术,则会产生m*n个维度的特征(m为滤波方式的个数,n为提取特征的个数)。
5.乳腺超声影像组学的超高维特征数据中存在的冗余特征会使得预测模型构建不准确。因此,分析各个特征之间的相关性不仅能够发现各项特征之间存在的关联,还可以选择合适有效的特征用以提高算法在诊断中的准确率。
6.随着时间的推移,影像数据也在不断增多。单机环境下利用皮尔逊相关系数处理海量超高维度特征数据之间的相关性,容易产生大量消耗cpu和内存资源的情况,甚至会发生内存溢出的现象,例如在处理医学研究中的乳腺肿瘤影像特征数据时,采用400条包含465维特征的数据。在计算100条数据后,时间花费将近两个小时,并且发生了内存溢出的情况。
7.为了解决大数据环境下数据在单机上处理速度慢、易造成内存溢出的的问题,基于google公司提出的gfs和mapreduce思想的hadoop分布式数据处理平台被广泛应用。hadoop包含三个部分:1.hdfs分布式存储架构,用以分布式存储海量数据;2.mapreduce并行计算框架,用以在各个存储节点处理数据;3.yarn分布式资源管理框架,用以各个节点分配cpu和内存等计算资源。
8.为了提高利用皮尔逊相关系数分析海量超高维度特征数据相关性的计算效率。本发明提出了一种乳腺超声影像组学的超高维特征数据相关性分析方法。通过采用分布式的方式,减少了单个节点下cpu和内存资源的消耗。为了进一步提升相关性分析的效率,采用估算的方式,减少了各个计算节点所产生的中间结果,以减少数据在传输过程中所造成的i/o消耗。
技术实现要素:
9.本发明提供一种乳腺超声影像组学的超高维特征数据相关性分析方法,采用估算和分布式任务相互配合的方法,可以解决现有技术中分析海量超高维特征数据相关性的问题,处理步骤如下。
10.s1: 使用labelme工具对乳腺肿瘤超声影像做感兴趣区域的标注并生成json文件,将其处理生成掩膜图。
11.s2: 将pyradiomics工具中的first order statistics features、shape features (2d)和gray level co-occurrence matrix (glcm)等七大类提取特征算法与original、wavelet和log等滤波器技术组合,提取步骤s1中感兴趣区域的特征,生成超高维影像特征数据。随着图像数量的增多,从而产生海量超高维影像特征数据。
12.s3: 将海量超高维影像特征数据按照节点存储块的大小做水平分割,并存储在分布式文件系统中。假设有三个计算节点,给定乳腺超声影像的海量超高维度特征数据d,每条数据对象包含个特征(s≥2)。数据被均匀划分为并存储在每个节点。(数据也可以不被等分存储在各个计算结点,|d|为数据集中的总条数),每个节点的部分数据包含s个特征。
13.s4: 各个计算节点按行读取其对应数据块中的每条数据,分别计算每个数据块中各个特征的和()及其特征的平方和()。其中t=,为数据集中第k条数据的第i个特征,1≤i≤s,1≤k≤t。
14.s5: 对所有数据求和计算,其中m=|d|,为数据集中第k条数据的第i个特征,1≤i≤s, 1≤k≤m。假设数据集中的两个特征列x和y(、),n表示数据集中的总条数,表示数据集中第i条数据的x特征,根据皮尔逊相关系数公式(公式1),可做如下变形:
ꢀꢀ
(1)替换上式中的和,其中:
整理上式并替换和,其中,整理最终皮尔逊相关公式如公式2所示:终皮尔逊相关公式如公式2所示:
ꢀꢀꢀ
(2)分布式下估算皮尔逊相关系数主要利用基本不等式原理,对于每个特征(例如x,y两个特征列)只需要在各个节点之间传输这四个数据(n》0为数据条数)。如果是m(m2)维特征数据,每个节点只需要输出2m个数据,减少了任意两个维度数据乘积所产生的个数据。其估算公式如下。
15.给定阈值
ℇ
,为无误差未知的皮尔逊相关系数值,为估算皮尔逊相关系数,始终大于等于(当两个特征数据一致重合时取等号)。其计算会产生以下两种结果。
16.结果1:当,则,两个特征之间不属于高相关。
17.结果2:当,且,无法判断与之间的关系,此时计算出这两个特征的均值和标准差然后执行步骤s6。
18.在不用计算出真实的皮尔逊相关系数值情况下,可以采用估算的形式得出结果1中真实的皮尔逊相关系数与的关系。首先给出三个前提条件:条件1:给定两个特征序列和,n(n》0)表示数据条数,对应第i(1≤i≤n)条数据对象的x和y的两个特征取值;条件2:基本不等式,;条件3:数据的标准差一定大于0。
19.当i=1时:。则。
20.当i=2时:。则。
21.
当i=n时:。则。
22.对i=1到i=n对应的求和,生成公式3:
ꢀꢀ
(3)根据条件2和条件3,将公式3的左边部分转换为公式2的形式:根据条件2和条件3,将公式3的左边部分转换为公式2的形式:
ꢀꢀ
(4)根据公式4,皮尔逊相关系数真实值:估算值:根据公式4得出,与阈值
ℇ
之间的关系如图2所示,取
ℇ
=0.8。当时,如图2中结果1的情况, 必然小于;当时,如图2中结果2,此时无法判定与之间的关系,此时根据计算这两个特征的均值()和标准差(),执行步骤s6。
23.s6: 各个计算节点得到步骤s5中无法估算相关性的特征的均值和标准差,根据公
式1通过均值和标准差从而计算无法判断的两个特征之间的皮尔逊相关系数,各个计算节点计算t条数据下x和y特征之间的相关性r(t=,1≤i≤t)。
24.s7: 汇总各个节点的数据并求均值得出x、y特征之间的相关性(num为节点的个数,表示第j个节点x、y的特征(1≤j≤num))。
25.本发明提出了一种乳腺超声影像组学的超高维特征数据相关性分析方法,解决了单机环境下分析海量超高维数据分析效率低的问题。本发明只需要将未能够估算的特征执行第二次mapreduce任务,减少了其处理的数据量,其他特征只需要一个mapreduce任务就能够利用估算的方式在不准确求出皮尔逊相关系数的情况下计算其与阈值之间的关系,大大提高了计算效率。
附图说明
26.图1为本发明整体流程图示意图。
27.图2为估算算法中皮尔逊相关系数的估算值、真实值与阈值之间的关系示例图。
28.图3 为第二次mapreduce任务处理流程示意图。
具体实施方式
29.下面结合图1至图3,对本发明的具体实施方式进行介绍。
30.s1: 使用labelme工具对九千张乳腺肿瘤超声影像做感兴趣区域的标注并生成json文件,将其处理生成掩膜图。
31.s2: 使用原始图像和wavelet处理过的图像作为提取特征的影像,然后用pyradiomics工具中的first order statistics features、glcm、glszm、glrlm、ngtdm和gldm共93个特征的提取算法,获取步骤s1中感兴趣区域的特征,生成(4+1)*93=465个特征。
32.s3: 将海量超高维影像特征数据按照节点存储块的大小做水平分割,并存储在分布式文件系统中。假设有三个计算节点,为了表述方便,每条数据对象的特征用表示。数据被均匀划分为并存储在每个节点(|d|为数据总条数,这里共有9000条)。每个节点的有包含465个特征的三千条数据。
33.s4: 各个计算节点按行读取其对应数据块中的每条数据,分别计算每个数据块中各个特征的和()及其特征的平方和()。其中t=,为数据集中第k条数据的第i个特征,1≤i≤465,1≤k≤t。
34.s5: 对所有数据求和计算,其中m=9000,为数据集中第k条数据的第i个特征,1≤i≤465, 1≤k≤m。假设数据集中的两个特征列和,分别用x
和y(、)表示,n表示数据集中的总条数(n=9000),表示数据集中第i条数据的x特征,对于每个特征(例如x,y两个特征列)只需要在各个节点之间传输这四个数据(n》0为数据条数)。
35.给定阈值
ℇ
=0.8,为无误差未知的皮尔逊相关系数值,为估算皮尔逊相关系数。根据公式4得出(当两个特征数据一致重合时取等号),其计算会产生以下两种结果。
36.结果1:当,如图2中结果1的情况, 必然小于,两个特征之间不属于高相关。
37.结果2:当时,如图2中结果2,此时无法判定与之间的关系,此时根据计算这两个特征的均值()和标准差(),执行步骤s6至s7,执行流程如图3所示。
38.s6: 各个计算节点得到步骤s5中无法估算相关性的特征的均值和标准差,根据公式1通过均值和标准差从而计算无法判断的两个特征之间的皮尔逊相关系数,各个计算节点计算t条数据下x和y特征之间的相关性r(t=,1≤i≤t)。
39.s7: 汇总各个节点的数据并求均值得出x、y特征之间的相关性(num为节点的个数,表示第j个节点x、y的特征(1≤j≤num))。
40.本发明提出了一种乳腺超声影像组学的超高维特征数据相关性分析方法,解决了单机环境下分析海量超高维数据分析效率低的问题。本发明只需要将未能够估算的特征执行第二次mapreduce任务,减少了其处理的数据量,其他特征只需要一个mapreduce任务就能够利用估算的方式在不准确求出皮尔逊相关系数的情况下计算其与阈值之间的关系,大大提高了计算效率。
41.以上公开的仅为本发明的具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1